JDK1.8 new features
This paper mainly introduces jdk1 Some new features in version 8 are the author's notes after watching the video for reference only.
jdk1.8. Knowledge points of new features:
1.Lambda expression
2. Functional interface
3. Method reference and constructor call
4.Stream API
5. Default and static methods in the interface
6. New time and date API
In jdk1 8 to optimize the data structure of map sets such as hashMap. Optimization of hashMap data structure
The data structure used in the original hashMap is hash table (array + linked list). The default size of hashMap is 16. It is an array with 0-15 index. How to store elements in it, first call the hashcode of elements
Method, calculate the hash code value and calculate it into the index value of the array through the hash algorithm. If there are no elements at the corresponding index, store it directly. If there are objects, compare their equals method comparison contents
If the content is the same, the latter value will overwrite the value of the previous value. If it is different, at 1.7, the added value will be placed in front to form a linked list and form a collision. In some cases, if the linked list
If it goes on indefinitely, the efficiency is extremely low, and collision can not be avoided
Loading factor: 0.75. When the array capacity reaches 75% of the total capacity, it will be expanded, but collision cannot be avoided
After 1.8, hashmap is implemented in array + linked list + red black tree. When the number of collision elements is greater than 8 & the total capacity is greater than 64, red black tree will be introduced
In addition to adding, the efficiency is higher than that of the linked list. After 1.8, the new elements of the linked list are added to the end
ConcurrentHashMap (lock segmentation mechanism), concurrentlevel, jdk1 8 CAS algorithm is adopted (lock free algorithm, lock segmentation is no longer used), and the use of red black tree is also introduced into array + linked list
1.Lambda expression
A lambda expression is essentially an anonymous inner class or a piece of code that can be passed
Let's first experience the most intuitive advantage of lambda: concise code
//Anonymous Inner Class
Comparator<Integer> cpt = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1,o2);
}
};
TreeSet<Integer> set = new TreeSet<>(cpt);
System.out.println("=========================");
//Using lambda expressions
Comparator<Integer> cpt2 = (x,y) -> Integer.compare(x,y);
TreeSet<Integer> set2 = new TreeSet<>(cpt2);
Only one line of code is needed, which greatly reduces the amount of code!!
In such a scenario, when browsing commodity information in the mall, we often filter and browse conditionally, for example, we should choose the one with red color and price less than 8000 thousand
// The filter color is red
public List<Product> filterProductByColor(List<Product> list){
List<Product> prods = new ArrayList<>();
for (Product product : list){
if ("gules".equals(product.getColor())){
prods.add(product);
}
}
return prods;
}
// Screen those whose price is less than 8000
public List<Product> filterProductByPrice(List<Product> list){
List<Product> prods = new ArrayList<>();
for (Product product : list){
if (product.getPrice() < 8000){
prods.add(product);
}
}
return prods;
}
We found that in fact, the core of these filtering methods is only the condition judgment in the if statement, and the others are template code. Every time you change the requirements, you need to add a new method, and then copy and paste it. Assuming that the filtering method has hundreds of lines, this method is a little clumsy. How to optimize?
Optimization 1: using design patterns
Define a mypredict interface
public interface MyPredicate <T> {
boolean test(T t);
}
If you want to filter products with red color, define a color filter class
public class ColorPredicate implements MyPredicate <Product> {
private static final String RED = "gules";
@Override
public boolean test(Product product) {
return RED.equals(product.getColor());
}
Define the filter method and pass in the filter interface as a parameter, so that the filter method does not need to be modified. When actually calling, you can pass in the specific implementation class.
public List<Product> filterProductByPredicate(List<Product> list,MyPredicate<Product> mp){
List<Product> prods = new ArrayList<>();
for (Product prod : list){
if (mp.test(prod)){
prods.add(prod);
}
}
return prods;
}
For example, if you want to filter goods with a price less than 8000, you can create a new price filter class
public class PricePredicate implements MyPredicate<Product> {
@Override
public boolean test(Product product) {
return product.getPrice() < 8000;
}
}
In this way, some people may say that every time you change the requirements, you need to create an implementation class. It still feels a little cumbersome. Then optimize it again.
Optimization 2: use anonymous inner classes
Define filtering method:
public List<Product> filterProductByPredicate(List<Product> list,MyPredicate<Product> mp){
List<Product> prods = new ArrayList<>();
for (Product prod : list){
if (mp.test(prod)){
prods.add(prod);
}
}
return prods;
}
When calling the filter method:
// Filter by price
public void test2(){
filterProductByPredicate(proList, new MyPredicate<Product>() {
@Override
public boolean test(Product product) {
return product.getPrice() < 8000;
}
});
}
// Filter by color
public void test3(){
filterProductByPredicate(proList, new MyPredicate<Product>() {
@Override
public boolean test(Product product) {
return "gules".equals(product.getColor());
}
});
}
Using anonymous internal classes, you don't need to create an implementation class every time, but implement it directly inside the method. Seeing the anonymous inner class, I can't help thinking of Lambda expressions.
Optimization 3: use lambda expression
Define filtering method:
public List<Product> filterProductByPredicate(List<Product> list,MyPredicate<Product> mp){
List<Product> prods = new ArrayList<>();
for (Product prod : list){
if (mp.test(prod)){
prods.add(prod);
}
}
return prods;
}
Filtering using lambda expressions
@Test
public void test4(){
List<Product> products = filterProductByPredicate(proList, (p) -> p.getPrice() < 8000);
for (Product pro : products){
System.out.println(pro);
}
}
In jdk1 There is also a simpler Stream API in 8
Optimization 4: using Stream API
You don't even need to define a filtering method to operate directly on the collection
// Use jdk1 The Stream API in 8 performs collection operations
@Test
public void test(){
// Filter by price
proList.stream()
.fliter((p) -> p.getPrice() <8000)
.limit(2)
.forEach(System.out::println);
// Filter by color
proList.stream()
.fliter((p) -> "gules".equals(p.getColor()))
.forEach(System.out::println);
// Traversal output product name
proList.stream()
.map(Product::getName)
.forEach(System.out::println);
}
Syntax summary of Lmabda expression: () - > ();
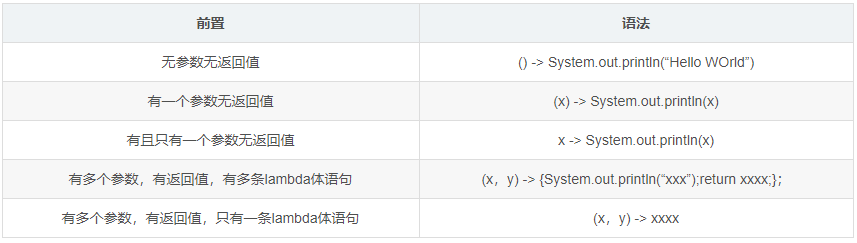
Pithy formula: if there is a provincial parenthesis on the left and right, the type of province is inferred on the left
Note: when there are multiple abstract methods in an interface, if lambda expression is used, the corresponding abstract methods cannot be matched intelligently. Therefore, the concept of functional interface is introduced
2. Functional interface
The functional interface is proposed to provide better support for the use of Lambda expressions.
What is a functional interface?
Simply put, it only defines an interface of an abstract method (except the public method of the Object class), which is a functional interface, and also provides the annotation: @ FunctionalInterface
Four common functional interfaces
(1) Consumer T: consumer interface, with or without return value
@Test
public void test(){
changeStr("hello",(str) -> System.out.println(str));
}
/**
* Consumer<T> Consumer interface
* @param str
* @param con
*/
public void changeStr(String str, Consumer<String> con){
con.accept(str);
}
(2) Supplier T: supply type interface with no parameter and return value
@Test
public void test2(){
String value = getValue(() -> "hello");
System.out.println(value);
}
/**
* Supplier<T> Supply type interface
* @param sup
* @return
*/
public String getValue(Supplier<String> sup){
return sup.get();
}
(3) Function "T,R":: functional interface, with parameters and return values
@Test
public void test3(){
Long result = changeNum(100L, (x) -> x + 200L);
System.out.println(result);
}
/**
* Function<T,R> Functional interface
* @param num
* @param fun
* @return
*/
public Long changeNum(Long num, Function<Long, Long> fun){
return fun.apply(num);
}
(4) Predicate "T": an assertion interface with parameters and return values of boolean type
public void test4(){
boolean result = changeBoolean("hello", (str) -> str.length() > 5);
System.out.println(result);
}
/**
* Predicate<T> Assertive interface
* @param str
* @param pre
* @return
*/
public boolean changeBoolean(String str, Predicate<String> pre){
return pre.test(str);
}
Based on the four core functional interfaces, extended functional interfaces such as BiFunction, BinaryOperation and toIntFunction are also provided. They are all extended from these four functional interfaces and will not be repeated.
Summary: the functional interface is proposed to make it more convenient for us to use lambda expressions. We don't need to manually create a functional interface, just use it directly.
3. Method reference
If a method has been implemented for the content in the lambda body, you can use "method reference"
It can also be understood that method reference is another form of lambda expression, and its syntax is simpler than lambda expression
(a) Method reference
Three forms:
- Object:: instance method name
- Class:: static method name
- Class:: instance method name (available when the first parameter in the lambda parameter list is the caller of the instance method and the second parameter is the parameter of the instance method)
public void test() {
/**
*be careful:
* 1.lambda The parameter list and return value type of the invocation method in the body should be consistent with the function list and the return value type of the abstract method in the functional interface.
* 2.If the first parameter in the lambda parameter list is the caller of the instance method and the second parameter is the parameter of the instance method, you can use ClassName::method
*
*/
Consumer<Integer> con = (x) -> System.out.println(x);
con.accept(100);
// Method reference - object:: instance method
Consumer<Integer> con2 = System.out::println;
con2.accept(200);
// Method reference - class name:: static method name
BiFunction<Integer, Integer, Integer> biFun = (x, y) -> Integer.compare(x, y);
BiFunction<Integer, Integer, Integer> biFun2 = Integer::compare;
Integer result = biFun2.apply(100, 200);
// Method reference - class name:: instance method name
BiFunction<String, String, Boolean> fun1 = (str1, str2) -> str1.equals(str2);
BiFunction<String, String, Boolean> fun2 = String::equals;
Boolean result2 = fun2.apply("hello", "world");
System.out.println(result2);
}
(b) Constructor reference
Format: ClassName::new
public void test2() {
// Constructor reference class name:: new
Supplier<Employee> sup = () -> new Employee();
System.out.println(sup.get());
Supplier<Employee> sup2 = Employee::new;
System.out.println(sup2.get());
// Construct a method with a parameter: new
Function<Integer, Employee> fun = (x) -> new Employee(x);
Function<Integer, Employee> fun2 = Employee::new;
System.out.println(fun2.apply(100));
}
© Array reference
Format: type []: New
public void test(){
// Array reference
Function<Integer, String[]> fun = (x) -> new String[x];
Function<Integer, String[]> fun2 = String[]::new;
String[] strArray = fun2.apply(10);
Arrays.stream(strArray).forEach(System.out::println);
}
4.Stream API
Three steps of Stream operation
(1) Create stream
(2) Intermediate operations (filtering, map)
(3) Terminate operation
Creation of stream:
// 1. Verify the stream() or parallelstream () provided through the Collection series Collection
List<String> list = new ArrayList<>();
Strean<String> stream1 = list.stream();
// 2. Obtain the array stream through the static method stream() of Arrays
String[] str = new String[10];
Stream<String> stream2 = Arrays.stream(str);
// 3. Pass the static method of in the Stream class
Stream<String> stream3 = Stream.of("aa","bb","cc");
// 4. Create infinite flow
// iteration
Stream<Integer> stream4 = Stream.iterate(0,(x) -> x+2);
//generate
Stream.generate(() ->Math.random());
Intermediate operation of Stream:
/**
* Filtering and de duplication
*/
emps.stream()
.filter(e -> e.getAge() > 10)
.limit(4)
.skip(4)
// The hashCode and equals methods need to be overridden by the elements in the stream
.distinct()
.forEach(System.out::println);
/**
* Generate a new flow through map mapping
*/
emps.stream()
.map((e) -> e.getAge())
.forEach(System.out::println);
/**
* Natural sorting custom sorting
*/
emps.stream()
.sorted((e1 ,e2) -> {
if (e1.getAge().equals(e2.getAge())){
return e1.getName().compareTo(e2.getName());
} else{
return e1.getAge().compareTo(e2.getAge());
}
})
.forEach(System.out::println);
Termination of Stream:
/**
* Find and match
* allMatch-Check that all elements match
* anyMatch-Check to see if at least one element matches
* noneMatch-Check if not all elements match
* findFirst-Returns the first element
* findAny-Returns any element in the current stream
* count-Returns the total number of elements in the stream
* max-Returns the maximum value in the stream
* min-Returns the minimum value in the stream
*/
/**
* Check for matching elements
*/
boolean b1 = emps.stream()
.allMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b1);
boolean b2 = emps.stream()
.anyMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b2);
boolean b3 = emps.stream()
.noneMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));
System.out.println(b3);
Optional<Employee> opt = emps.stream()
.findFirst();
System.out.println(opt.get());
// Parallel flow
Optional<Employee> opt2 = emps.parallelStream()
.findAny();
System.out.println(opt2.get());
long count = emps.stream()
.count();
System.out.println(count);
Optional<Employee> max = emps.stream()
.max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()));
System.out.println(max.get());
Optional<Employee> min = emps.stream()
.min((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()));
System.out.println(min.get());
There are also two more powerful termination operations, reduce and collect
Reduce operation: reduce:(T identity,BinaryOperator)/reduce(BinaryOperator) - you can combine the elements in the stream repeatedly to get a value
/**
* reduce : Protocol operation
*/
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer count2 = list.stream()
.reduce(0, (x, y) -> x + y);
System.out.println(count2);
Optional<Double> sum = emps.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println(sum);
Collect operation: collect - converts the Stream into other forms, receives the implementation of a Collection interface, and is used to summarize the elements in the Stream
/**
* collect: Collection operation
*/
List<Integer> ageList = emps.stream()
.map(Employee::getAge)
.collect(Collectors.toList());
ageList.stream().forEach(System.out::println);
5. Parallel stream and serial stream
In jdk1 8 the new stream package also provides parallel operation flow and serial operation flow for collection operations. Parallel flow is to cut the content into multiple data blocks, and use multiple threads to process the content of each data block respectively. The Stream api declares that parallel() and sequential() methods can be used to switch between parallel and serial streams.
jdk1.8 parallel flow uses fork/join framework for parallel operation
6.ForkJoin framework
Fork/Join framework: when necessary, fork a large task into several small tasks (when it cannot be disassembled), and then join and summarize the operation results of each small task.
Key words: recursive separation and combination, division and rule.
Adopt "work stealing" mode:
When executing a new task, it can split it into smaller tasks and add small tasks to the line
Process queue, and then steal one from the queue of a random thread and put it in its own queue
Compared with the general implementation of thread pool, the advantage of fork/join framework lies in the of the tasks contained therein
In terms of treatment methods In a general thread pool, if a thread is executing a task for some reason
If it cannot continue running, the thread will be in a waiting state In the fork/join framework implementation, if
A subproblem cannot continue because it waits for another subproblem to complete Then deal with the child
The thread of the problem will actively look for other sub problems that have not yet run to execute This approach reduces the number of threads
The waiting time improves the performance.
/**
* To use Fark - Join, the class must inherit
* RecursiveAction((no return value)
* Or
* RecursiveTask((with return value)
*
*/
public class ForkJoin extends RecursiveTask<Long> {
/**
* To use Fark Join, the class must inherit the RecursiveAction (no return value) or
* RecursiveTask((with return value)
*
* @author Wuyouxin
*/
private static final long serialVersionUID = 23423422L;
private long start;
private long end;
public ForkJoin() {
}
public ForkJoin(long start, long end) {
this.start = start;
this.end = end;
}
// Define threshold
private static final long THRESHOLD = 10000L;
@Override
protected Long compute() {
if (end - start <= THRESHOLD) {
long sum = 0;
for (long i = start; i < end; i++) {
sum += i;
}
return sum;
} else {
long middle = (end - start) / 2;
ForkJoin left = new ForkJoin(start, middle);
//Dismantle the molecular task and press it into the thread queue
left.fork();
ForkJoin right = new ForkJoin(middle + 1, end);
right.fork();
//Merge and return
return left.join() + right.join();
}
}
/**
* Realize the accumulation of numbers
*/
@Test
public void test1() {
//start time
Instant start = Instant.now();
//A thread pool support is needed here
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoin(0L, 10000000000L);
// No return value pool execute();
// There is a return value
long sum = pool.invoke(task);
//End time
Instant end = Instant.now();
System.out.println(Duration.between(start, end).getSeconds());
}
/**
* java8 Parallel stream (parallel)
*/
@Test
public void test2() {
//start time
Instant start = Instant.now();
// Cumulative summation of parallel stream computing
LongStream.rangeClosed(0, 10000000000L).parallel()
.reduce(0, Long :: sum);
//End time
Instant end = Instant.now();
System.out.println(Duration.between(start, end).getSeconds());
}
@Test
public void test3(){
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream().forEach(System.out::print);
list.parallelStream()
.forEach(System.out::print);
}
Show the effect of multithreading:
@Test
public void test(){
// Parallel streams are executed by multiple threads
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEach(System.out::print);
//
System.out.println("=========================");
numbers.stream()
.sequential()
.forEach(System.out::print);
}
Optional container
Using the Optional container can quickly locate the NPE and reduce the amount of code for non empty parameter verification to a certain extent.
/**
* Optional.of(T t); // Create an Optional instance
* Optional.empty(); // Create an empty Optional instance
* Optional.ofNullable(T t); // If T is not null, create an Optional instance; otherwise, create an empty instance
* isPresent(); // Judgment is enough to contain value
* orElse(T t); //If the calling object contains a value, return the value; otherwise, return T
* orElseGet(Supplier s); // If the calling object contains a value, return the value; otherwise, return the value obtained in s
* map(Function f): // If there is a value, process it and return the processed Optional. Otherwise, return Optional empty();
* flatMap(Function mapper);// Similar to map. The return value is Optional
*
* Summary: optional Of (null) will directly report to NPE
*/
Optional<Employee> op = Optional.of(new Employee("zhansan", 11, 12.32, Employee.Status.BUSY));
System.out.println(op.get());
// NPE
Optional<Employee> op2 = Optional.of(null);
System.out.println(op2);
@Test
public void test2(){
Optional<Object> op = Optional.empty();
System.out.println(op);
// No value present
System.out.println(op.get());
}
@Test
public void test3(){
Optional<Employee> op = Optional.ofNullable(new Employee("lisi", 33, 131.42, Employee.Status.FREE));
System.out.println(op.get());
Optional<Object> op2 = Optional.ofNullable(null);
System.out.println(op2);
// System.out.println(op2.get());
}
@Test
public void test5(){
Optional<Employee> op1 = Optional.ofNullable(new Employee("Zhang San", 11, 11.33, Employee.Status.VOCATION));
System.out.println(op1.orElse(new Employee()));
System.out.println(op1.orElse(null));
}
@Test
public void test6(){
Optional<Employee> op1 = Optional.of(new Employee("pseudo-ginseng", 11, 12.31, Employee.Status.BUSY));
op1 = Optional.empty();
Employee employee = op1.orElseGet(() -> new Employee());
System.out.println(employee);
}
@Test
public void test7(){
Optional<Employee> op1 = Optional.of(new Employee("pseudo-ginseng", 11, 12.31, Employee.Status.BUSY));
System.out.println(op1.map( (e) -> e.getSalary()).get());
}
The default implementation method and static method can be defined in the interface
In the interface, you can use the default and static keywords to modify the common methods defined in the interface
public interface Interface {
default String getName(){
return "zhangsan";
}
static String getName2(){
return "zhangsan";
}
}
In jdk1 Many interfaces in version 8 will add new methods. In order to ensure the downward compatibility of 1.8, the interface implementation classes in version 1.7 do not need to re implement the newly added interface methods. The default implementation is introduced. The usage of static is to directly use the interface name to adjust the methods. When a class inherits the parent class and implements the interface, if the latter two methods have the same name, it will inherit the method with the same name in the parent class first, that is, "class first". If the interface of two methods with the same name is implemented, the implementation class must manually declare which method in the interface is implemented by default.
7. New date API LocalDate | LocalTime | LocalDateTime
The new date API s are immutable and are more suitable for multi-threaded environments
@Test
public void test(){
// Get the current date and time from the system clock in the default time zone. Regardless of time zone difference
LocalDateTime date = LocalDateTime.now();
//2018-07-15T14:22:39.759
System.out.println(date);
System.out.println(date.getYear());
System.out.println(date.getMonthValue());
System.out.println(date.getDayOfMonth());
System.out.println(date.getHour());
System.out.println(date.getMinute());
System.out.println(date.getSecond());
System.out.println(date.getNano());
// Manually create a LocalDateTime instance
LocalDateTime date2 = LocalDateTime.of(2017, 12, 17, 9, 31, 31, 31);
System.out.println(date2);
// Add to get a new date instance
LocalDateTime date3 = date2.plusDays(12);
System.out.println(date3);
// Subtract to get a new date instance
LocalDateTime date4 = date3.minusYears(2);
System.out.println(date4);
}
@Test
public void test2(){
// The time stamp is the millisecond value from 00:00:00 on January 1, 1970 to a certain time point
// Get UTC time zone by default
Instant ins = Instant.now();
System.out.println(ins);
System.out.println(LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli());
System.out.println(System.currentTimeMillis());
System.out.println(Instant.now().toEpochMilli());
System.out.println(Instant.now().atOffset(ZoneOffset.ofHours(8)).toInstant().toEpochMilli());
}
@Test
public void test3(){
// Duration: calculate the interval between two times
// Period: calculate the interval between two dates
Instant ins1 = Instant.now();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Instant ins2 = Instant.now();
Duration dura = Duration.between(ins1, ins2);
System.out.println(dura);
System.out.println(dura.toMillis());
System.out.println("======================");
LocalTime localTime = LocalTime.now();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
LocalTime localTime2 = LocalTime.now();
Duration du2 = Duration.between(localTime, localTime2);
System.out.println(du2);
System.out.println(du2.toMillis());
}
@Test
public void test4(){
LocalDate localDate =LocalDate.now();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
LocalDate localDate2 = LocalDate.of(2016,12,12);
Period pe = Period.between(localDate, localDate2);
System.out.println(pe);
}
@Test
public void test5(){
// Temporaladjust time checker
// For example, get the next working day next Sunday
LocalDateTime ldt1 = LocalDateTime.now();
System.out.println(ldt1);
// Get the first day of the year
LocalDateTime ldt2 = ldt1.withDayOfYear(1);
System.out.println(ldt2);
// Get the first day of the month
LocalDateTime ldt3 = ldt1.withDayOfMonth(1);
System.out.println(ldt3);
LocalDateTime ldt4 = ldt1.with(TemporalAdjusters.next(DayOfWeek.FRIDAY));
System.out.println(ldt4);
// Get next business day
LocalDateTime ldt5 = ldt1.with((t) -> {
LocalDateTime ldt6 = (LocalDateTime)t;
DayOfWeek dayOfWeek = ldt6.getDayOfWeek();
if (DayOfWeek.FRIDAY.equals(dayOfWeek)){
return ldt6.plusDays(3);
}
else if (DayOfWeek.SATURDAY.equals(dayOfWeek)){
return ldt6.plusDays(2);
}
else {
return ldt6.plusDays(1);
}
});
System.out.println(ldt5);
}
@Test
public void test6(){
// DateTimeFormatter: format time / date
// Custom format
LocalDateTime ldt = LocalDateTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy year MM month dd day");
String strDate1 = ldt.format(formatter);
String strDate = formatter.format(ldt);
System.out.println(strDate);
System.out.println(strDate1);
// Use the format provided by the api
DateTimeFormatter dtf = DateTimeFormatter.ISO_DATE;
LocalDateTime ldt2 = LocalDateTime.now();
String strDate3 = dtf.format(ldt2);
System.out.println(strDate3);
// to parse time string
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime time = LocalDateTime.now();
String localTime = df.format(time);
LocalDateTime ldt4 = LocalDateTime.parse("2017-09-28 17:07:05",df);
System.out.println("LocalDateTime Turn into String Type of time:"+localTime);
System.out.println("String Type of time conversion LocalDateTime: "+ldt4);
}
// ZoneTime ZoneDate ZoneDateTime
@Test
public void test7(){
LocalDateTime now = LocalDateTime.now(ZoneId.of("Asia/Shanghai"));
System.out.println(now);
LocalDateTime now2 = LocalDateTime.now();
ZonedDateTime zdt = now2.atZone(ZoneId.of("Asia/Shanghai"));
System.out.println(zdt);
Set<String> set = ZoneId.getAvailableZoneIds();
set.stream().forEach(System.out::println);
}
Supplement:
Representing the date LocalDate Representing time LocalTime Represents the date and time LocalDateTime
Several advantages of the new date API:
* Previously used java.util.Date The month starts from 0. We usually+1 It's inconvenient to use, java.time.LocalDate The month and week have been changed to enum * java.util.Date and SimpleDateFormat Are not thread safe, and LocalDate and LocalTime And the most basic String It is an immutable type, which is thread safe and cannot be modified. * java.util.Date It is a "universal interface", which includes date, time and milliseconds, making it more clear whether to choose or not * The reason why the new interface works better is that the operation of date and time is taken into account. It is often pushed forward or backward for a few days. use java.util.Date coordination Calendar You have to write a lot of code, and ordinary developers may not be able to write it right.
LocalDate
public static void localDateTest() {
//Get the current date, only including the fixed format yyyy MM DD 2018-05-04
LocalDate today = LocalDate.now();
// According to the date, may is 5,
LocalDate oldDate = LocalDate.of(2018, 5, 1);
// According to the string: the default format is yyyy MM DD, 02 cannot be written as 2
LocalDate yesteday = LocalDate.parse("2018-05-03");
// If it is not a leap year, it will also report an error on the 29th
LocalDate.parse("2018-02-29");
}
LocalDate common conversion
/**
* Date conversion commonly used, first or last day
*/
public static void localDateTransferTest(){
//2018-05-04
LocalDate today = LocalDate.now();
// Take the first day of the month: May 1, 2018
LocalDate firstDayOfThisMonth = today.with(TemporalAdjusters.firstDayOfMonth());
// Take the second day of this month: May 2, 2018
LocalDate secondDayOfThisMonth = today.withDayOfMonth(2);
// Take the last day of the month, and you don't have to calculate whether it's 28, 29, 30 or 31:2018-05-31
LocalDate lastDayOfThisMonth = today.with(TemporalAdjusters.lastDayOfMonth());
// Next day: June 1, 2018
LocalDate firstDayOf2015 = lastDayOfThisMonth.plusDays(1);
// Take the first Wednesday in October 2018 so easy?: 2018-10-03
LocalDate thirdMondayOf2018 = LocalDate.parse("2018-10-01").with(TemporalAdjusters.firstInMonth(DayOfWeek.WEDNESDAY));
}
LocalTime
public static void localTimeTest(){
//16: 25:46.448 (nanosecond value)
LocalTime todayTimeWithMillisTime = LocalTime.now();
//16: 28:48 without nanosecond value
LocalTime todayTimeWithNoMillisTime = LocalTime.now().withNano(0);
LocalTime time1 = LocalTime.parse("23:59:59");
}
LocalDateTime
public static void localDateTimeTest(){
//Convert to timestamp millisecond value
long time1 = LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli();
long time2 = System.currentTimeMillis();
//Convert timestamp to localdatetime
DateTimeFormatter df= DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss.SSS");
System.out.println(df.format(LocalDateTime.ofInstant(Instant.ofEpochMilli(time1),ZoneId.of("Asia/Shanghai"))));
}