Why do I need Stream
As a highlight of Java 8, stream is similar to Java InputStream and OutputStream in io package are completely different concepts. It is also different from the stream of XML parsing by StAX, nor is it the stream of real-time processing of big data by Amazon Kinesis. Stream in Java 8 is an enhancement of the function of Collection objects. It focuses on various very convenient and efficient aggregation operations or bulk data operations on Collection objects. Stream API greatly improves the programming efficiency and program readability with the help of the same new Lambda expression. At the same time, it provides serial and parallel modes for aggregation operation. The concurrent mode can make full use of the advantages of multi-core processor and use fork/join parallel mode to split tasks and speed up the processing process. It is usually difficult and error prone to write parallel code, but using stream API can easily write high-performance concurrent programs without writing one line of multi-threaded code. So, Java. Com, which first appeared in Java 8 util. Stream is a product of the comprehensive influence of functional language + multi-core era.
What is an aggregation operation
In traditional J2EE applications, Java code often has to rely on the aggregation operation of relational database to complete, such as:
- Average monthly consumption amount of customers
- The most expensive goods on sale
- Valid orders completed this week (excluding invalid orders)
- Take ten data samples as the home page recommendation
This kind of operation.
However, in today's era of data explosion, with diversified data sources and massive data, we often have to break away from RDBMS or make higher-level data statistics based on the data returned from the bottom. In the collection API of Java, there are only a few auxiliary methods. More often, programmers need to use Iterator to traverse the collection and complete the relevant aggregation application logic. This is a far less efficient and clumsy method. In Java 7, if you want to find all transactions of type grocery and return the transaction ID set sorted in descending order of transaction values, we need to write as follows:
Listing 1 Implementation of sorting and value taking in Java 7
List<Transaction> groceryTransactions = new Arraylist<>();
for(Transaction t: transactions){
if(t.getType() == Transaction.GROCERY){
groceryTransactions.add(t);
}
}
Collections.sort(groceryTransactions, new Comparator(){
public int compare(Transaction t1, Transaction t2){
return t2.getValue().compareTo(t1.getValue());
}
});
List<Integer> transactionIds = new ArrayList<>();
for(Transaction t: groceryTransactions){
transactionsIds.add(t.getId());
}Using Stream in Java 8 makes the code more concise and easy to read; And using concurrent mode, the program execution speed is faster.
Listing 2 Implementation of sorting and value taking in Java 8
List<Integer> transactionsIds = transactions.parallelStream(). filter(t -> t.getType() == Transaction.GROCERY). sorted(comparing(Transaction::getValue).reversed()). map(Transaction::getId). collect(toList());
Stream overview
What is flow
Stream is not a collection element. It is not a data structure and does not save data. It is about algorithms and calculations. It is more like an advanced version of Iterator. In the original version of Iterator, users can only explicitly traverse elements one by one and perform some operations on them; In the advanced version of stream, users only need to give what operations they need to perform on the elements contained in it, such as "filter out strings with a length greater than 10", "get the first letter of each string", etc. the stream will implicitly traverse internally and make corresponding data conversion.
Stream is like an Iterator. It is unidirectional and cannot be reciprocated. The data can only be traversed once. After traversing once, it is exhausted. It is like running water flowing in front of you and never returns.
Unlike iterators, Stream can operate in parallel, and iterators can only operate in command and serialization. As the name suggests, when traversing in serial mode, read each item before reading the next item. When parallel traversal is used, the data will be divided into multiple segments, each of which will be processed in different threads, and then the results will be output together. The parallel operation of Stream relies on the Fork/Join framework (JSR166y) introduced in Java 7 to split tasks and speed up the processing process. The evolution of Java's parallel API is basically as follows:
>
1. Java in 1.0-1.4 lang.Thread
2. Java in 5.0 util. concurrent
02. Phasers in 6.0, etc
10. Fork/Join framework in 7.0
1. Lambda in 8.0
Another feature of Stream is that the data source itself can be unlimited.
Composition of flow
When we use a stream, there are usually three basic steps:
Obtain a data source → data conversion → execute the operation to obtain the desired result. Each time the original Stream object is converted, a new Stream object is returned (there can be multiple conversions), which allows the operation to be arranged like a chain and become a pipeline, as shown in the figure below.
Figure 1 Composition of stream pipeline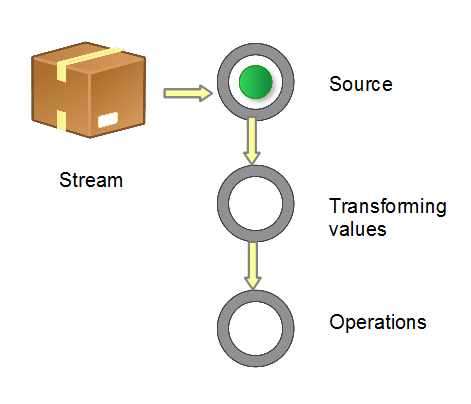
There are several ways to generate a Stream Source:
-
From Collection and array
- Collection.stream()
- Collection.parallelStream()
- Arrays.stream(T array) or Stream.of()
From BufferedReader
- java.io.BufferedReader.lines()
- Static factory
- java.util.stream.IntStream.range()
- java.nio.file.Files.walk()
-
Build yourself
- java.util.Spliterator
- Others
- Random.ints()
- BitSet.stream()
- Pattern.splitAsStream(java.lang.CharSequence)
- JarFile.stream()
There are two types of operations for streams:
- Intermediate: a flow can be followed by zero or more intermediate operations. Its main purpose is to open the flow, make some degree of data mapping / filtering, and then return a new flow for the next operation. Such operations are lazy, that is, only calling such methods does not really start the traversal of the flow.
- Terminal: a flow can only have one terminal operation. When this operation is executed, the flow will be used "light" and can no longer be operated. So this must be the last operation of the stream. Only when the terminal operation is executed can the flow traversal really start, and a result or a side effect will be generated.
When performing multiple Intermediate operations on a Stream, each element of the Stream is converted and executed multiple times each time. Is the time complexity the sum of all operations done in N (conversion times) for loops? In fact, this is not the case. All conversion operations are lazy. Multiple conversion operations will only be integrated during Terminal operation and completed in one cycle. We can simply understand that there is a set of operation functions in the Stream. Each conversion operation is to put the conversion function into this set, cycle the set corresponding to the Stream during the Terminal operation, and then execute all functions for each element.
Another operation is called short circuiting. Used to refer to:
- For an intermediate} operation, if it accepts an infinite/unbounded Stream, but returns a limited new Stream.
- For a "terminal" operation, if it accepts an infinite "Stream, but can calculate the result in a limited time.
When an infinite Stream is operated and the operation is expected to be completed in a limited time, it is necessary and not sufficient to have a short circuiting operation in the pipeline.
Listing 3 An example of a stream operation
int sum = widgets.stream() .filter(w -> w.getColor() == RED) .mapToInt(w -> w.getWeight()) .sum();
stream() gets the source of the current small object. Filter and mapToInt are intermediate operations to filter and convert data. The last sum() is terminal operation to sum the weight of all qualified small objects.
Detailed explanation of the use of flow
In short, the use of Stream is to implement a filter map reduce process, produce an end result, or cause a side effect.
Construction and transformation of flow
The following provides examples of the most common ways to construct streams.
Listing 4 Several common methods of constructing flow
// 1. Individual values
Stream stream = Stream.of("a", "b", "c");
// 2. Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3. Collections
List<String> list = Arrays.asList(strArray);
stream = list.stream();It should be noted that for the basic numerical type, there are three corresponding packaging types: Stream:
IntStream,LongStream,DoubleStream. Of course, we can also use Stream < integer >, Stream < long > > and Stream < double >, but "boxing" and "unboxing" will be very time-consuming, so we provide corresponding streams for these three basic numerical types.
Java 8 does not provide other numerical} streams, because this will lead to more expanded content. The conventional numerical aggregation operation can be carried out through the above three streams.
Listing 5 Construction of numerical flow
IntStream.of(new int[]{1, 2, 3}).forEach(System.out::println);
IntStream.range(1, 3).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);Listing 6 Convert stream to other data structures
// 1. Array String[] strArray1 = stream.toArray(String[]::new); // 2. Collection List<String> list1 = stream.collect(Collectors.toList()); List<String> list2 = stream.collect(Collectors.toCollection(ArrayList::new)); Set set1 = stream.collect(Collectors.toSet()); Stack stack1 = stream.collect(Collectors.toCollection(Stack::new)); // 3. String String str = stream.collect(Collectors.joining()).toString();
A Stream can only be used once, and the above code has been reused several times for simplicity.
Operation of flow
Next, when a data structure is packaged into a Stream, it is necessary to start various operations on the elements inside. Common operations can be classified as follows.
- Intermediate
- map (mapToInt, flatMap, etc.), filter, distinct, sorted, peek, limit, skip, parallel, sequential, unordered
- Terminal
- forEach, forEachOrdered, toArray, reduce, collect, min, max, count, anyMatch, allMatch, noneMatch, findFirst, findAny, iterator
- Short-circuiting
- anyMatch, allMatch, noneMatch, findFirst, findAny, limit
Let's take a look at the typical usage of Stream.
map/flatMap
Let's look at the map first. If you are familiar with functional languages such as , scala , you should know this method well. Its function is to map each element of , inputStream , to another element of , outputStream ,.
Listing 7 Convert to uppercase
List<String> output = wordList.stream(). map(String::toUpperCase). collect(Collectors.toList());
This code converts all words to uppercase.
Listing 8 Square number
List<Integer> nums = Arrays.asList(1, 2, 3, 4); List<Integer> squareNums = nums.stream(). map(n -> n * n). collect(Collectors.toList());
This code generates the square of an integer list {1, 4, 9, 16}.
As can be seen from the above example, the map generates a 1:1 mapping, and each input element is transformed into another element according to the rules. There are also some scenes with one to many mapping relationship. At this time, flatMap is required.
Listing 9 One to many
Stream<List<Integer>> inputStream = Stream.of( Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6) ); Stream<Integer> outputStream = inputStream. flatMap((childList) -> childList.stream());
flatMap flattens the hierarchical structure in the input Stream, which is to pull out the bottom elements and put them together. Finally, there is no List in the new Stream of output, which is all direct numbers.
filter
filter performs a test on the original Stream, and the elements that pass the test are left to generate a new Stream.
Listing 10 Leave an even number
Integer[] sixNums = {1, 2, 3, 4, 5, 6};
Integer[] evens =
Stream.of(sixNums).filter(n -> n%2 == 0).toArray(Integer[]::new);After the filter with the condition "divided by 2", the remaining number is {2, 4, 6}.
Listing 11 Pick out the words
List<String> output = reader.lines(). flatMap(line -> Stream.of(line.split(REGEXP))). filter(word -> word.length() > 0). collect(Collectors.toList());
This code first arranges the words in each line into a new Stream with flatMap, and then retains the words with a length of not 0, that is, all the words in the whole article.
forEach
The forEach method receives a Lambda expression and executes it on each element of the Stream.
Listing 12 Print name (comparison between forEach and pre-java8)
// Java 8
roster.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.forEach(p -> System.out.println(p.getName()));
// Pre-Java 8
for (Person p : roster) {
if (p.getGender() == Person.Sex.MALE) {
System.out.println(p.getName());
}
}Traverse a collection of people, find out the men and print their names. It can be seen that the design of lambford is the most compact. Moreover, the Lambda expression itself can be reused, which is very convenient. When you need to optimize a multi-core system, you can parallelstream() forEach(), but the order of the original elements cannot be guaranteed. In parallel, the behavior of serial operation will be changed. At this time, the implementation of forEach itself does not need to be adjusted, and the for loop code before Java 8 may need to add additional multithreading logic.
However, it is generally believed that the difference between forEach and conventional for loops does not involve performance. They are only the difference between functional style and traditional Java style.
Another thing to note is that forEach is a terminal operation, so after it is executed, the elements of the Stream will be "consumed", and you cannot perform two terminal operations on a Stream. The following code is wrong:
stream.forEach(element -> doOneThing(element)); stream.forEach(element -> doAnotherThing(element));
On the contrary, the intermediate operation peek with similar functions can achieve the above purpose. The following is an example that appears on the api javadoc.
Listing 13 Peek performs an operation on each element and returns a new Stream
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());forEach cannot modify its own local variable value, nor can it end the loop in advance with keywords such as break/return.
findFirst
This is a terminal and short circuiting operation, which always returns the first element of the Stream, or empty.
The focus here is on its return value type: Optional. This is also a concept that imitates the Scala language. As a container, it may or may not contain a value. The purpose of using it is to avoid NullPointerException as much as possible.
Listing 14 Two use cases of optional
String strA = " abcd ", strB = null;
print(strA);
print("");
print(strB);
getLength(strA);
getLength("");
getLength(strB);
public static void print(String text) {
// Java 8
Optional.ofNullable(text).ifPresent(System.out::println);
// Pre-Java 8
if (text != null) {
System.out.println(text);
}
}
public static int getLength(String text) {
// Java 8
return Optional.ofNullable(text).map(String::length).orElse(-1);
// Pre-Java 8
// return if (text != null) ? text.length() : -1;
};In the case of more complex if (XX! = null), the readability of using Optional code is better, and it provides compile time check, which can greatly reduce the impact of Runtime Exception such as NPE on the program, or force programmers to deal with null problems earlier in the coding phase, rather than leaving it to be found and debugged at runtime.
The findAny, max/min, reduce and other methods in Stream return Optional values. Another example is intstream Average () returns OptionalDouble and so on.
reduce
The main function of this method is to combine the Stream elements. It provides a starting value (seed), and then combines it with the first, second and Nth elements of the previous Stream according to the operation rules (BinaryOperator). In this sense, string splicing, numeric sum, min, max, and average are all special "reduce". For example, the sum of Stream is equivalent to integer sum = integers reduce(0, (a, b) -> a+b); Or integer sum = integers reduce(0, Integer::sum);
If there is no starting value, the first two elements of the Stream will be combined and the return is Optional.
Listing 15 Use case of reduce
// String connection, concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// Find the minimum value, minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// Sum, sumValue = 10, with starting value
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// Summation, sumValue = 10, no starting value
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// Filter, string connection, concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").
filter(x -> x.compareTo("Z") > 0).
reduce("", String::concat);The above code is like reduce() in the first example. The first parameter (blank character) is the starting value, and the second parameter (String::concat) is BinaryOperator. This kind of reduce () with a starting value returns a specific object. For the fourth example, reduce (), which has no starting value, may not have enough elements and return Optional. Please pay attention to this difference.
limit/skip
limit returns the first n elements of the Stream; skip is to throw away the first n elements (it is renamed from a method called subStream).
Listing 16 Impact of limit and skip on the number of runs
public void testLimitAndSkip() {
List<Person> persons = new ArrayList();
for (int i = 1; i <= 10000; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<String> personList2 = persons.stream().
map(Person::getName).limit(10).skip(3).collect(Collectors.toList());
System.out.println(personList2);
}
private class Person {
public int no;
private String name;
public Person (int no, String name) {
this.no = no;
this.name = name;
}
public String getName() {
System.out.println(name);
return name;
}
}The output result is:
name1 name2 name3 name4 name5 name6 name7 name8 name9 name10 [name4, name5, name6, name7, name8, name9, name10]
This is a Stream with 10000 elements, but under the action of short circuiting operation limit and skip, the execution times of the getName() method specified by the map operation in the pipeline is 10 times limited by the limit, and the final return result is only returned after skipping the first three elements.
In one case, limit/skip cannot achieve the purpose of short circuiting, that is, they are placed after the sorting operation of the Stream. The reason is related to the intermediate operation of sorted: at this time, the system does not know the order of the Stream after sorting, so the operations in sorted look like they have not been limited or skipped at all.
Listing 17 Limit and skip have no effect on the number of runs after sorted
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList2 = persons.stream().sorted((p1, p2) ->
p1.getName().compareTo(p2.getName())).limit(2).collect(Collectors.toList());
System.out.println(personList2);The above example fine tuned listing 13, first sorting the Stream of five elements, and then performing the limit operation. The output result is:
name2 name1 name3 name2 name4 name3 name5 name4 [stream.StreamDW$Person@816f27d, stream.StreamDW$Person@87aac27]
That is, although the last number of returned elements is 2, the execution times of sorted expression in the whole pipeline are not reduced as in the previous example.
Finally, it should be noted that for a parallel Steam pipeline, if its elements are orderly, the cost of limit operation will be relatively large, because its return object must be the first n elements with the same order. Instead, the strategy is to cancel the order between elements, or do not use parallel Stream.
sorted
The sorting of streams is carried out through sorted, which is stronger than the sorting of arrays. The reason is that you can first carry out various map s, filter s, limit s, skip and even distinct on streams to reduce the number of elements before sorting, which can help the program significantly shorten the execution time. We optimized listing 14:
Listing 18 Optimization: limit and skip before sorting
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList2 = persons.stream().limit(2).sorted((p1, p2) -> p1.getName().compareTo(p2.getName())).collect(Collectors.toList());
System.out.println(personList2);The result will be much simpler:
name2 name1 [stream.StreamDW$Person@6ce253f1, stream.StreamDW$Person@53d8d10a]
Of course, this optimization has the limitation of business logic: it does not require sorting before taking value.
min/max/distinct
The functions of min and max can also be realized by sorting the Stream elements first and then findFirst, but the performance of the former will be better, which is O(n), while the cost of sorted is O(n log n). At the same time, they are independent as a special reduce method because finding the maximum and minimum value is a very common operation.
Listing 19 Find the length of the longest line
BufferedReader br = new BufferedReader(new FileReader("c:\\SUService.log"));
int longest = br.lines().
mapToInt(String::length).
max().
getAsInt();
br.close();
System.out.println(longest);The following example uses distinct to find words that are not repeated.
Listing 20 Find the words in the full text, turn them into lowercase and sort them
List<String> words = br.lines().
flatMap(line -> Stream.of(line.split(" "))).
filter(word -> word.length() > 0).
map(String::toLowerCase).
distinct().
sorted().
collect(Collectors.toList());
br.close();
System.out.println(words);Match
Stream has three match methods. Semantically speaking:
- allMatch: all elements in the Stream conform to the incoming predicate and return true
- anyMatch: as long as one element in the Stream matches the incoming predicate, it returns true
- noneMatch: none of the elements in the Stream match the incoming predicate, and return true
Neither of them needs to traverse all elements to return results. For example, allMatch skip s all the remaining elements and returns false as long as one element does not meet the conditions. Slightly modify the Person class in listing 13 by adding an age attribute and a getAge method.
Listing 21 Using Match
List<Person> persons = new ArrayList();
persons.add(new Person(1, "name" + 1, 10));
persons.add(new Person(2, "name" + 2, 21));
persons.add(new Person(3, "name" + 3, 34));
persons.add(new Person(4, "name" + 4, 6));
persons.add(new Person(5, "name" + 5, 55));
boolean isAllAdult = persons.stream().
allMatch(p -> p.getAge() > 18);
System.out.println("All are adult? " + isAllAdult);
boolean isThereAnyChild = persons.stream().
anyMatch(p -> p.getAge() < 12);
System.out.println("Any child? " + isThereAnyChild);Output result:
All are adult? false Any child? true
Advanced: generate your own flow
Stream.generate
By implementing the Supplier interface, you can control the generation of flow by yourself. This situation is usually used for streams with random numbers and constants, or streams that need to maintain some state information between the front and rear elements. Pass the Supplier instance to Stream The Stream generated by generate() is serial by default (relative to parallel) but unordered (relative to ordered). Because it is infinite, in the pipeline, you must limit the size of the Stream by using operations such as limit.
Listing 22 Generate 10 random integers
Random seed = new Random(); Supplier<Integer> random = seed::nextInt; Stream.generate(random).limit(10).forEach(System.out::println); //Another way IntStream.generate(() -> (int) (System.nanoTime() % 100)). limit(10).forEach(System.out::println);
Stream.generate() also accepts its own Supplier. For example, when constructing massive test data, assign values to each variable with some automatic rules; Or calculate the value of each element of the stream according to the formula. These are situations where status information is maintained.
Listing 23 Self implementing Supplier
Stream.generate(new PersonSupplier()).
limit(10).
forEach(p -> System.out.println(p.getName() + ", " + p.getAge()));
private class PersonSupplier implements Supplier<Person> {
private int index = 0;
private Random random = new Random();
@Override
public Person get() {
return new Person(index++, "StormTestUser" + index, random.nextInt(100));
}
}Output result:
StormTestUser1, 9 StormTestUser2, 12 StormTestUser3, 88 StormTestUser4, 51 StormTestUser5, 22 StormTestUser6, 28 StormTestUser7, 81 StormTestUser8, 51 StormTestUser9, 4 StormTestUser10, 76
iterate is similar to reduce in that it accepts a seed value and an UnaryOperator (for example, f). Then the seed value becomes the first element of the Stream, f(seed) is the second, f(f(seed)) is the third, and so on.
Listing 24 Generate an arithmetic sequence
Stream.iterate(0, n -> n + 3).limit(10). forEach(x -> System.out.print(x + " "));
Output result:
0 3 6 9 12 15 18 21 24 27
And Stream Similarly to generate, the pipeline must have an operation such as limit to limit the size of the Stream during iterate.
Advanced: use Collectors for reduction
java. util. Stream. The main function of collectors class is to assist in various useful reduction operations, such as transforming the output to Collection and grouping Stream elements.
groupingBy/partitioningBy
Listing 25 Group by age
Map<Integer, List<Person>> personGroups = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.groupingBy(Person::getAge));
Iterator it = personGroups.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, List<Person>> persons = (Map.Entry) it.next();
System.out.println("Age " + persons.getKey() + " = " + persons.getValue().size());
}The above code first generates the information of 100 people, and then groups them according to their age. People of the same age are put into the same list, and you can see the following output:
Age 0 = 2 Age 1 = 2 Age 5 = 2 Age 8 = 1 Age 9 = 1 Age 11 = 2 ......
List 26 Group according to minors and adults
Map<Boolean, List<Person>> children = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.partitioningBy(p -> p.getAge() < 18));
System.out.println("Children number: " + children.get(true).size());
System.out.println("Adult number: " + children.get(false).size());Output result:
Children number: 23 Adult number: 77
After grouping using the condition "age less than 18", we can see that minors under the age of 18 are one group and adults are another group. partitioningBy is actually a special kind of groupingBy. It constructs the returned data structure according to the two results of conditional test. get(true) and get(false) can be all element objects.
Concluding remarks
In short, the characteristics of Stream can be summarized as follows:
- Not a data structure
- It has no internal storage. It just uses the operation pipeline to grab data from the source (data structure, array, generator function, IO channel).
- It also never modifies the data of the underlying data structure encapsulated by itself. For example, the filter operation of Stream will generate a new Stream that does not contain the filtered elements, instead of deleting those elements from the source.
- All Stream operations must take lambda expressions as parameters
- Index access is not supported
- You can request the first element, but you cannot request the second, third, or last element. However, please refer to the next item.
- It's easy to generate arrays or lists
- Inerting
- Many Stream operations are delayed backward until it finds out how much data it needs in the end.
- Intermediate operations are always lazy.
- Parallel capability
- When a Stream is parallelized, there is no need to write multithreaded code, and all operations on it will be carried out automatically in parallel.
- Can be infinite
- A collection has a fixed size, but a Stream does not. Short circuiting operations such as limit(n) and findFirst() can operate on an infinite Stream and complete it quickly.