Project prospect
Recently, many projects have been deployed on NVIDIA platform with low hardware cost. The computing power of NVIDIA platform hardware from small to large is Jetson nano, Jetson TK1, Jetson TX and Jetson Xavier, plus 1000 to 10000. I just started all the small series, and NVIDIA has a good quantitative tool, tensorrt Xiaobian QQ1039463596

tensorrt There is a good learning resource, you can refer to
Thanks to the big guy of open source
https://github.com/wang-xinyu/tensorrtx
Jetson nano has an environment
opencv3.4.9 Above version tensorrt7.2.1.6 pytorch1.6 cuda-10.2 cudnn-8
yolov5 model
1. Model training
I won't talk about the relevant principles of yolov5. At present, many projects are used by everyone. Here I only talk about how to convert. First, go to the official git clone source code
Because I am using version 3.0, clone the 3.0 branch, otherwise the conversion will definitely make an error, and the other is yolov5.0 PT into the code of tenosorrt model engine.
git clone -b v3.0 https://github.com/ultralytics/yolov5.git
First, refer to yolov5 official website to train a complete best PT model and passed the test. As shown in the figure, here is the data of training a helmet and head

2. Model transformation
Download github model transformation code and compile it
git clone -b yolov5-v3.0 https://github.com/wang-xinyu/tensorrtx.git
Enter the path and run
cd {tensorrtx}/yolov5/
// update CLASS_NUM in yololayer.h if your model is trained on custom dataset
mkdir build
cd build
cp {ultralytics}/yolov5/yolov5s.wts {tensorrtx}/yolov5/build
cmake ..
make
sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x/s6/m6/l6/x6 or c/c6 gd gw] // serialize model to plan file
sudo ./yolov5 -d [.engine] [image folder] // deserialize and run inference, the images in [image folder] will be processed.
Note that opencv must have dnn module here. After conversion, an engine model will be generated. At this time, you can test successfully in the same path before calling python
3. Model inference
I have done two things here. One is to modify the original Yolo_ trt. The NMS mode in py file is too slow in the original version, and the data needs to be copied frequently in GPU and CPU. I directly use CPU for calculation. Second, I change the way of reading stream decoding, abandon opencv reading stream, and use cuda of gestreamer for decoding, which speeds up the decoding process After encapsulation, it is very conducive to migration. The file form is as follows
The code is as follows:
"""
An example that uses TensorRT's Python api to make inferences.
"""
import ctypes
import os
import random
import sys
import threading
import time
import cv2
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trt
import torch
INPUT_W = 608
INPUT_H = 608
CONF_THRESH = 0.1
IOU_THRESHOLD = 0.4
global num
num=0
def NMS(dets,score, thresh):
#x1, y1, x2, y2, and score assignment
# (x1, y1) (x2, y2) are the upper left and lower right corners of the box
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = score
#Area of each candidate box
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#Order is sorted in descending order according to score, and the original index of sorting is obtained, not the original array after sorting
order = scores.argsort()[::-1]
# :: - 1 indicates reverse order
temp = []
while order.size > 0:
i = order[0]
temp.append(i)
#Calculate the coordinates of the intersection box between the rectangular box with the maximum current probability and other rectangular boxes
# Due to numpy's broadcast mechanism, the vector is obtained
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#Calculate the area of the intersecting box. Note that when the rectangular box does not intersect, w or h will be a negative number, which needs to be replaced by 0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#Calculate overlap IoU
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#Find rectangle index with overlap not higher than threshold
inds = np.where(ovr <= thresh)[0]
#Update the order sequence. Since the index of the rectangle obtained earlier is 1 smaller than the index of the rectangle in the original order sequence, this 1 should be added back
order = order[inds + 1]
return temp
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
class YoLov5TRT(object):
"""
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path):
# Create a Context on this device,
self.cfx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
# Deserialize the engine from file
with open(engine_file_path, "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
Frame=[]
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(cuda_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# Store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
def infer(self,frame):
threading.Thread.__init__(self)
# Make self the active context, pushing it on top of the context stack.
self.cfx.push()
# Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
t1=time.time()
input_image, image_raw, origin_h, origin_w = self.preprocess_image(frame)
# Copy input image to host buffer
np.copyto(host_inputs[0], input_image.ravel())
# Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# Run inference.
context.execute_async(bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# Synchronize the stream
stream.synchronize()
# Remove any context from the top of the context stack, deactivating it.
self.cfx.pop()
# Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
# Do postprocess
result_boxes, result_scores, result_classid = self.post_process(
output, origin_h, origin_w
)
print("time: ",time.time()-t1)
#Draw rectangles and labels on the original image
for i in range(len(result_boxes)):
box = result_boxes[i]
plot_one_box(
box,
image_raw,
label="{}:{:.2f}".format(
categories[int(result_classid[i])],result_scores[i]),)
#Save image
global num
#save_name="image/"+str(num)+".jpg"
#cv2.imwrite(save_name, image_raw)
#num+=1
def destroy(self):
# Remove any context from the top of the context stack, deactivating it.
self.cfx.pop()
def preprocess_image(self,frame):
"""
description: Read an image from image path, convert it to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
image_raw = frame
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
# Calculate widht and height and paddings
r_w = INPUT_W / w
r_h = INPUT_H / h
if r_h > r_w:
tw = INPUT_W
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((INPUT_H - th) / 2)
ty2 = INPUT_H - th - ty1
else:
tw = int(r_h * w)
th = INPUT_H
tx1 = int((INPUT_W - tw) / 2)
tx2 = INPUT_W - tw - tx1
ty1 = ty2 = 0
# Resize the image with long side while maintaining ratio
image = cv2.resize(image, (tw, th))
# Pad the short side with (128,128,128)
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, (128, 128, 128)
)
image = image.astype(np.float32)
# Normalize to [0,1]
image /= 255.0
# HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# CHW to NCHW format
image = np.expand_dims(image, axis=0)
# Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def xywh2xyxy(self, origin_h, origin_w, x):
"""
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
param:
origin_h: height of original image
origin_w: width of original image
x: A boxes tensor, each row is a box [center_x, center_y, w, h]
return:
y: A boxes tensor, each row is a box [x1, y1, x2, y2]
"""
y = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)
r_w = INPUT_W / origin_w
r_h = INPUT_H / origin_h
if r_h > r_w:
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2 - (INPUT_H - r_w * origin_h) / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2 - (INPUT_H - r_w * origin_h) / 2
y /= r_w
else:
y[:, 0] = x[:, 0] - x[:, 2] / 2 - (INPUT_W - r_h * origin_w) / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2 - (INPUT_W - r_h * origin_w) / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
y /= r_h
return y
def post_process(self, output, origin_h, origin_w):
"""
description: postprocess the prediction
param:
output: A tensor likes [num_boxes,cx,cy,w,h,conf,cls_id, cx,cy,w,h,conf,cls_id, ...]
origin_h: height of original image
origin_w: width of original image
return:
result_boxes: finally boxes, a boxes tensor, each row is a box [x1, y1, x2, y2]
result_scores: finally scores, a tensor, each element is the score correspoing to box
result_classid: finally classid, a tensor, each element is the classid correspoing to box
"""
# Get the num of boxes detected
num = int(output[0])
# Reshape to a two dimentional ndarray
pred = np.reshape(output[1:], (-1, 6))[:num, :]
# to a torch Tensor
#pred = torch.Tensor(pred).cuda()
# Get the boxes
boxes = pred[:, :4]
# Get the scores
scores = pred[:, 4]
# Get the classid
classid = pred[:, 5]
# Choose those boxes that score > CONF_THRESH
si = scores > CONF_THRESH
boxes = boxes[si, :]
scores = scores[si]
classid = classid[si]
# Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
boxes = self.xywh2xyxy(origin_h, origin_w, boxes)
# Do nms
indices=NMS(boxes,scores,IOU_THRESHOLD)
result_boxes = boxes[indices,:]
result_scores = scores[indices]
result_classid = classid[indices]
return result_boxes, result_scores, result_classid
def open_cam_rtsp(cameraName,latancy,width,height):
gst_str = ('rtspsrc location={} latency={} ! '
'rtph264depay ! h264parse ! omxh264dec ! '
'nvvidconv ! '
'video/x-raw, width=(int){}, height=(int){}, '
'format=(string)BGRx ! '
'videoconvert ! appsink').format(cameraName, latancy, width, height)
return cv2.VideoCapture(gst_str, cv2.CAP_GSTREAMER)
if __name__ == "__main__":
camera_addr='rtsp://admin:mkls1123@192.168.0.64/'
cap=open_cam_rtsp(camera_addr,200,1280,720)
#cap=cv2.VideoCapture("1.mp4")
# load custom plugins
PLUGIN_LIBRARY = "libmyplugins.so"
ctypes.CDLL(PLUGIN_LIBRARY)
engine_file_path = "yolov5s.engine"
# load coco labels
categories = ["person", "hat"]
# a YoLov5TRT instance
yolov5_wrapper = YoLov5TRT(engine_file_path)
while True:
ret,Frame=cap.read()
if ret==True:
time.sleep(0.00001)
yolov5_wrapper.infer(Frame)
else:
self.cap=open_cam_rtsp(camera_addr,200,1280,720)
time.sleep(5)
# destroy the instance
yolov5_wrapper.destroy()
The final test results are as follows:
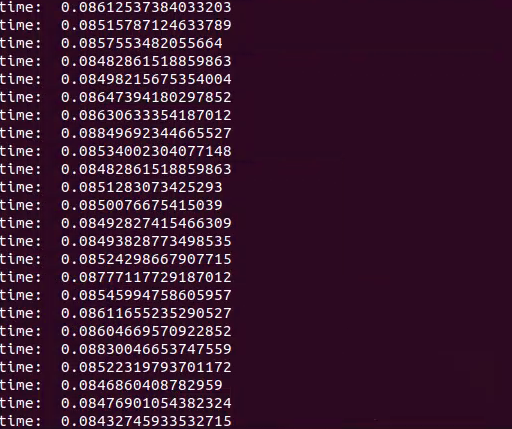
You can see that the whole process takes about 80ms
Test effect video

Further, it can be real-time after tracking and counting

In this paper, fp32 model is adopted, and the subsequent optimization can be continued to within 30ms, from reading stream to detection, tracking, and finally pushing rtsp stream.