js cookie anti crawl
theoretical basis
From Python-3 anti crawler principle and bypass practice
Cookies can be used not only for storing user identity information or maintaining state of Web server, but also for anti crawler. Most crawlers only request HTML text resources by default, which means that they will not actively complete the browser's operation of saving cookies. Cookie anti crawler means that the server distinguishes normal users and crawlers by verifying the cookie value in the request header. This method is widely used in Web applications. For example, the browser will automatically check whether there is a set cookie header field in the response header. If so, the value will be saved locally, and each subsequent request will automatically carry the corresponding cookie value, At this time, the server only needs to verify the cookie value in the request header. The server will verify whether the cookie value in each request header complies with the rules. If it passes the verification, it will return to normal resources. Otherwise, the request will be redirected to the home page, and the set cookie header field and cookie value will be added to the response header.
actual combat
observation
Open the developer tool, switch the page, and see which interface url we want to crawl to

It is found that the target is a string of URLs similar to UUIDs, and then look at html. In fact, the url composed of this string of UUIDs can be obtained through the a tag. Now, just crawl the specific information of our target
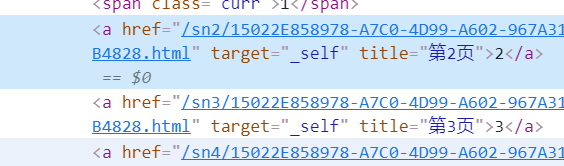
Take a look at how our specific information is represented in html

You can see that it is also a form of a tag, so our idea is clear
Just find one uuid of url=> Through detailed information a The link in the tag crawls all the details=> Through the on the next page a The link in the tab goes to the next page url=> Loop until the end of the page is empty
Let's write a simple crawler to see if we can get it and use the website directly
import requests
cookies = {
'Hm_lvt_9511d505b6dfa0c133ef4f9b744a16da': '1631673117',
'ASP.NET_SessionId': 'xel3j5xxd5fxgu5rgv0cf2ms',
'spvrscode': 'abdc551c0bd7f81cca4e2804c23afe646e1a1904a5570f1e626ce42731a8b2bb7e2ac5430a0b4c2671adf2973523fe3be72a87e6e56c76657e1ac381a254570e7ac433db747372123549b582c4dfa98f60816aca302433f60fddfbff563c19556c1cb013f26eadbd5d81d8ffc0a22fae8275c1fd42b386c2ef1d085048ae3a9a544793a7c2307dd2',
'Hm_lpvt_9511d505b6dfa0c133ef4f9b744a16da': '1631685108',
}
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '"Microsoft Edge";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
response = requests.get('https://www.***.***/15022E858978-A7C0-4D99-A602-967A31FB4828.html', headers=headers, cookies=cookies)
print(response.text)

Damn it, there are really no simple things in the world. We met an expert. We can tell the students that this is an expert. Jesus can't save it when he comes...... That's impossible. It inherits the tradition of shredded pork teacher's service first. If you have difficulties, you have to solve them. If you can't solve them, you'd better pick up my kettle and drink water while analyzing. Take out my old friend burpsuit I haven't seen for many years (last time it was a year), try it bit by bit, send it to the repeater, delete parameters one by one, and finally locate spvrscode = in the cookie. When it is empty, a string of js code will be returned, and when the cookie expires, it will return unauthorized access, Now use the previous cookie kill script to locate how cookies are generated.
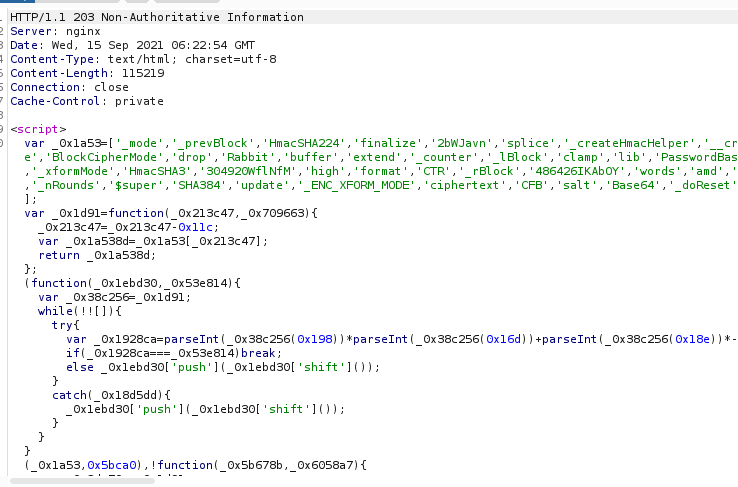
var cookie = document.cookie;
document = Object.defineProperty(document, 'cookie', {
get: function () {
console.log('getter: ' + cookie);
return cookie;
},
set: function (value) {
console.log('setter: ' + value);
cookie = value
}
});
First clear the data and cookie s, and then note that it will redirect the web page and refresh the web page. At this time, if we directly release the hook at the upper and lower breakpoints of the script, the redirect will refresh our hook. Therefore, you can use the oil monkey script hook or run the hook script at each breakpoint
Finally located here
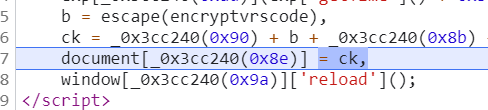
Just check the value of ck to see if it is the result we want

Is the value of the cookie we want, so we can start the reverse work here. How is the step-by-step backtracking ck generated
ck=_0x3cc240(0x90) + b + _0x3cc240(0x8b) + exp[_0x3cc240(0x95)]() + ';'
_0x3cc240(0x90)='spvrscode=' b='e73fbff4ed0cd6bdd7a2b41a2b2c915ce7b0b047552752268c1ea11adfc9b5422c33f2ec7cfdc9fe0b7df5ca707503f80b0039c93e8636c6ac1063c135494a1a6254d35b623e2f4803a67ac44ec8c7e99f517d25fbec1f7dfbfb569004d7eef408ad6e675c4562172112e4e1da5f359d25e07e80915b71794669e0f88c6f11b39a0e5d34695d5bc9'//target ...//The rest has little effect
Go after b
b = escape(encryptvrscode) encryptvrscode='e73fbff4ed0cd6bdd7a2b41a2b2c915ce7b0b047552752268c1ea11adfc9b5422c33f2ec7cfdc9fe0b7df5ca707503f80b0039c93e8636c6ac1063c135494a1a6254d35b623e2f4803a67ac44ec8c7e99f517d25fbec1f7dfbfb569004d7eef408ad6e675c4562172112e4e1da5f359d25e07e80915b71794669e0f88c6f11b39a0e5d34695d5bc9'//target encryptvrscode = encrypted[_0x3cc240(0x97)][_0x3cc240(0x8f)]() _0x3cc240(0x97)='ciphertext' _0x3cc240(0x8f)='toString'
Then continue to track encrypted and explore that it is a bull and horse object at once
var keyHex = CryptoJS['enc'][_0x3cc240(0xa3)][_0x3cc240(0xa4)](a)
, encrypted = CryptoJS[_0x3cc240(0xa2)][_0x3cc240(0x8a)](b, keyHex, {
'mode': CryptoJS[_0x3cc240(0xaf)]['ECB'],
'padding': CryptoJS[_0x3cc240(0xa9)][_0x3cc240(0x99)]
})
CryptoJS... At a glance, master LAN said the encryption library. Just translate it
_0x3cc240(0xa3)='Utf8' _0x3cc240(0xa4)='parse' a='eb74960d' _0x3cc240(0xa2)=`DES` _0x3cc240(0x8a)='encrypt' _0x3cc240(0xa9)=`pad` _0x3cc240(0x99)=`Pkcs7` b='E04A051E2E4370CE3F2AB90D7ECF6CFAC225C8B8FC6076977E8546DC17C7F890D3D442529EEE9941C3BDE3766931B7C846F43BBB36E02E3ED90B87B40A96AEDF'//This b is not that b, so the following result is different from the previous one. Let's start with a new b
translate
var keyHex = CryptoJS['enc']['Utf8']['parse']('eb74960d')
, encrypted = CryptoJS[`DES`]['encrypt'](b, keyHex, {
'mode': CryptoJS[`mode`]['ECB'],
'padding': CryptoJS[`pad`][`Pkcs7`]
})
At this time, you can take a look at the use case of CryptoJS on Baidu, and we will know its encryption process. The official use process is roughly as follows
var CryptoJS = require("crypto-js");
// Encrypt
var ciphertext = CryptoJS.AES.encrypt('my message', 'secret key 123').toString();
// Decrypt
var bytes = CryptoJS.AES.decrypt(ciphertext, 'secret key 123');
var originalText = bytes.toString(CryptoJS.enc.Utf8);
console.log(originalText); // 'my message'
In fact, this is an ECB mode of DES encryption, so we can find a website to try (the key is changed and refreshed again)
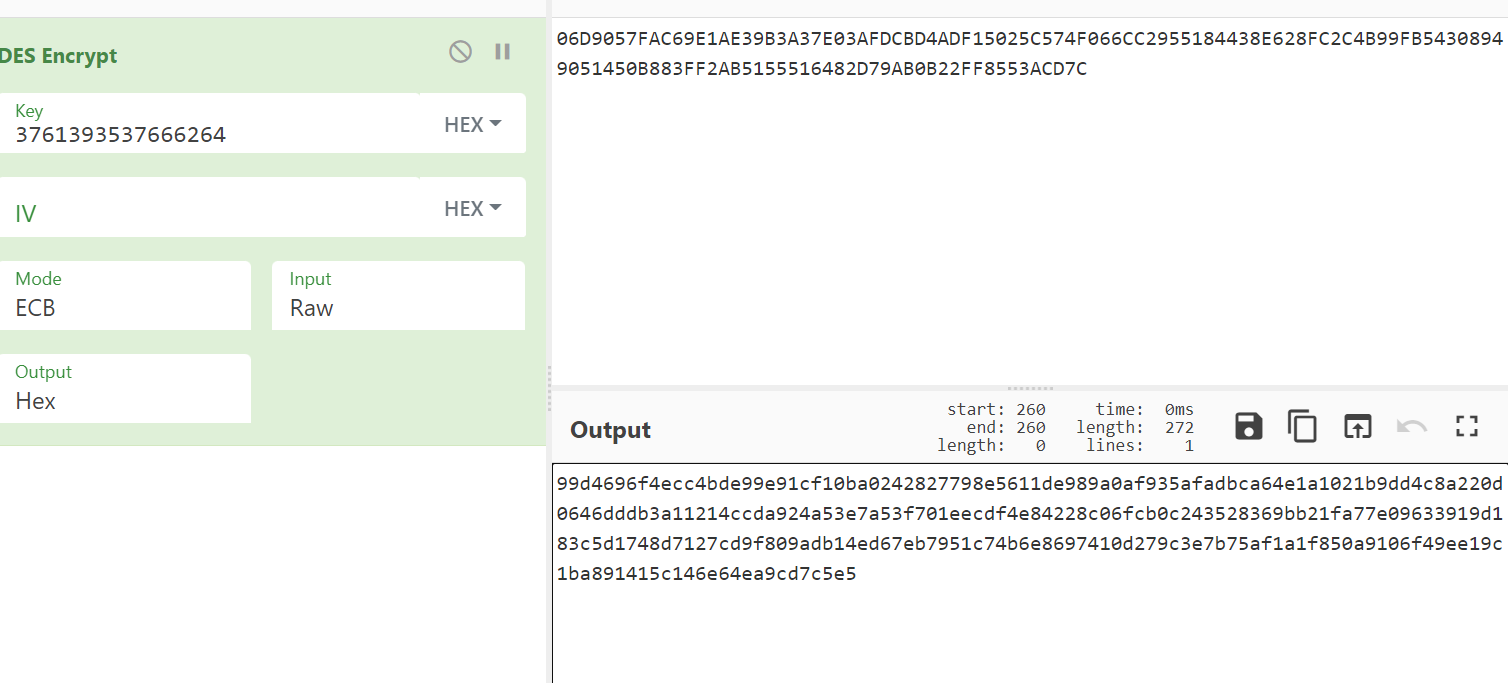

We can see as like as two peas, then we know that this is a standard algorithm, python can be implemented simply, then there is another question which is where key and b come from. Upward tracing can be found in js.
var a = '7a957fbd'; var b = '06D9057FAC69E1AE39B3A37E03AFDCBD4ADF15025C574F066CC2955184438E628FC2C4B99FB54308949051450B883FF2AB5155516482D79AB0B22FF8553ACD7C';
over, you can start writing the program
Find any one on your first visit uuid of url obtain js=> Second carrying cookie visit url Get what we want html data=> Through detailed information a The link in the tag crawls all the details=> Through the on the next page a The link in the tab goes to the next page url=> Loop until the end of the page is empty
Here, I choose to call js code directly, or write regular matching to get message and key. I also use the previous code to supplement the environment. After running js, I still lack the environment, and install a CryptoJS
npm install crypto-js
Then import and find the results
var CryptoJS = require("crypto-js");
......
console.log(ck)

So now we can write our script to crawl and successfully get the cookie value. During this period, we need to add a getcookie function and use execjs. As mentioned earlier, we won't repeat it here. We can load js on the ground (in fact, it's OK not to land)
response = requests.get('https://****.***.***/15022E858978-A7C0-4D99-A602-967A31FB4828.html', headers=headers, cookies=cookies)
pattern = re.compile("<script>(.*)</script>",re.S)
jscode = pattern.findall(response.text)[0]
with open("./MyProxy.js", "r") as f:
envcode = f.read()
getcookie="function getcookie(){return document.cookie;}"
allcode = envcode + jscode+"\n"+getcookie;
with open("./allcode.js", "w") as f:
f.write(allcode)
ctx = execjs.compile(allcode)
spvrscode = ctx.call("getcookie")
print(spvrscode)

Note that the URL is one-to-one corresponding to spvrscode and sessionid, so you need to define a class to have a unified session. The final code is as follows
class spider:
def __init__(self):
self.session = requests.session()
def getdata(self, url):
headers = {
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
response = self.session.get(url, headers=headers)
html = response.text
if "******" not in response.text:
pattern = re.compile("<script>(.*)</script>",re.S)
jscode = pattern.findall(response.text)[0]
with open("./MyProxy.js", "r") as f:
envcode = f.read()
getcookie = "function getcookie(){return b;}"
allcode = envcode + jscode + "\n" + getcookie;
with open("./allcode.js", "w") as f:
f.write(allcode)
ctx = execjs.compile(allcode)
spvrscode = ctx.call("getcookie")
requests.utils.add_dict_to_cookiejar(self.session.cookies, {"spvrscode": spvrscode})
response = self.session.get('***********', headers=headers)
html = response.text
print(self.session.cookies.values())
if __name__ == '__main__':
s=spider();
s.getdata("https://***********")
Got html