1, Overview
1. Inheritance structure of collection
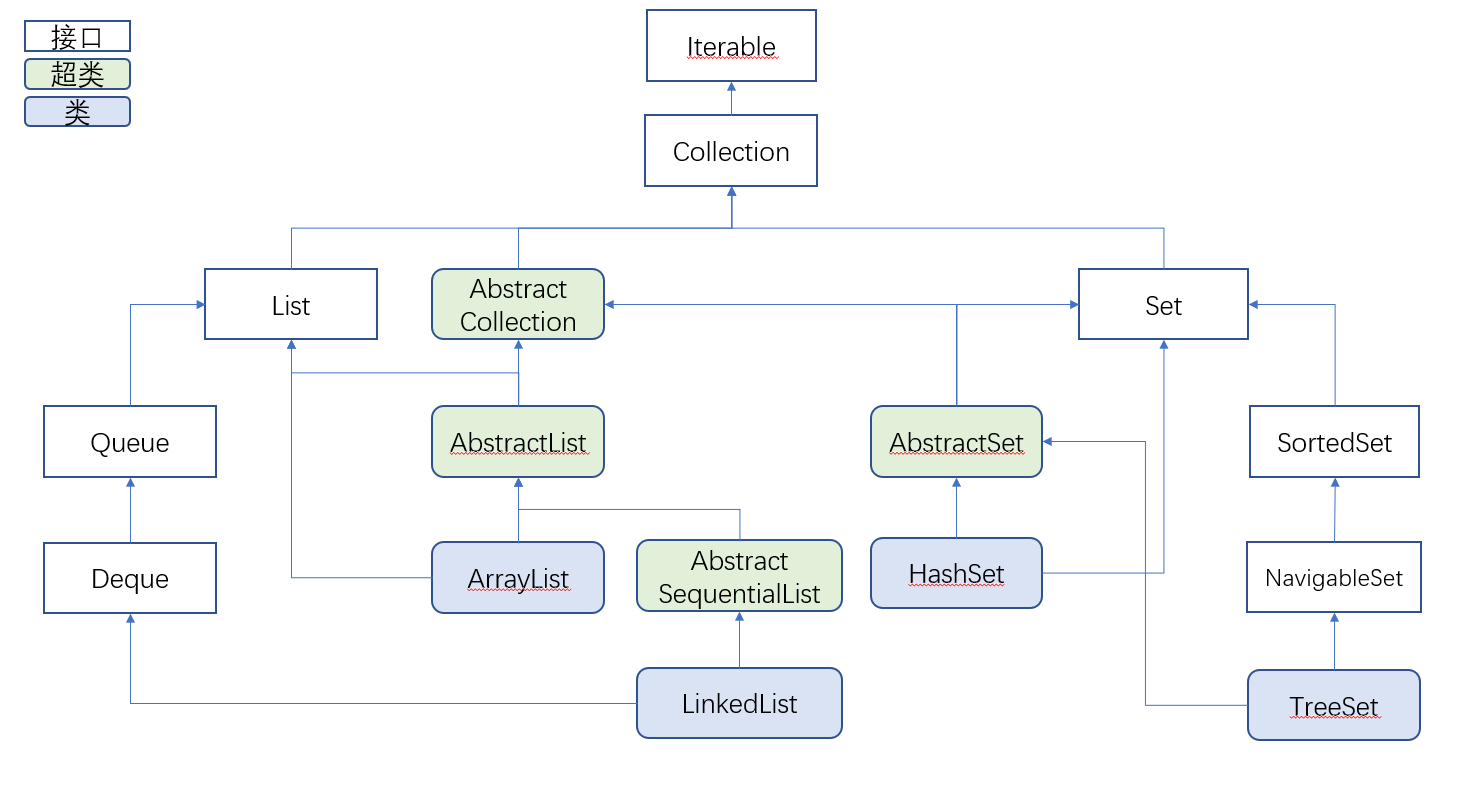
As can be seen from the above figure, there are two interfaces list and set under the Collection. List represents the linear table in the data structure, and the implementation method of linear table is divided into linked list and array. Set means set. Each element in a set is independent, so set is often used in de duplication scenarios. The two underlying data structures of set are Hash table and red black tree.
From the above inheritance structure, we find that the top-level interface is iteratable. iterator() method is defined in iteratable in the source code. This method will return an iterator object, and iterator is used to iterate the collection. The iteration methods of different data structures are different, so in the specific implementation classes of the inheritance system of the whole collection, Will implement the implementation class of iterator corresponding to their own data structure.
AbstractCollection, a virtual base class, is a simple implementation of the methods in the Collection. For specific methods that operate data structures, exceptions will be thrown directly in this class of methods, that is, subclasses are required to implement them. Similarly, AbstractList and AbstractSet are also simple implementations of some general methods. The specific content still needs subclasses to customize the implementation. In this way, the concept of a class of set can be better described and the basic actions of the set can be defined. Subclasses only need to consider the specific content of their own data structure.
In the List series, the two most common implementation classes are ArrayList and LinkedList. ArrayList is implemented based on array and LinkedList is implemented based on two-way linked List.
2. Briefly describe the usage scenario of the collection
Collection is very common in our daily programming. For example, when we find the content in the database, we return a List of class data, which is stored by List. For another example, we build a white List or blacklist of commodity categories to ensure that the categories are independent and will not be repeated, so we need to use the data structure of Set.
To be more specific, we have an information List of goods. When business needs, they are arranged in positive or reverse order according to the price. What kind of List structure is most suitable for storage at this time? Of course, it's an array, because we can quickly access, compare and sort based on the subscript of the array.
For example, in chestnuts, we need to maintain a queue of shop reservation table order numbers. Vip children's shoes can jump the queue. At this time, what kind of List structure do we need to use for storage? This reflects the efficiency of the insertion and deletion of the linked List. In spite of the above queue jumping, the array is actually no better than the linked List. However, once the queue jumping is added or the elements in the queue are deleted, the efficiency of the insertion and deletion of the linked List will be highlighted. It can directly delete the elements to be deleted by pointing to the variable pointer, The array needs to be shifted and overwritten.
2, Source code analysis of ArrayList
1. Brief introduction ArrayList
ArrayList is the most common data structure in our daily programming. It is implemented based on Object array.
transient Object[] elementData;
When we create a new ArrayList, if the size of the capacity is not specified, it will point to a default empty array.
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
However, if we specify the size of the capacity, if the specified size is greater than 0, an array of the specified size will be created. If the specified capacity is 0, it will point to the default empty array. If the specified capacity is less than 0, parameter exceptions will be exposed.
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
There are several properties in ArrayList that need to be mentioned. Among them, size is to record the actual stored values of the current object array (including the null value of add). DEFAULT_CAPACITY specifies the default capacity for the first expansion.
private static final int DEFAULT_CAPACITY = 10;
private int size;
2. The empty ArrayList is expanded for the first time
When we use the parameterless constructor to create ArrayList, the Object array in it actually points to an empty array. Therefore, when we add for the first time, we will follow a judgment logic. The general content is that if the current array points to the default empty, we will judge the minimum required capacity and the default initial capacity, make a comparison, and take the maximum value. The expansion of the array is based on arrays Copyof (elementdata, newcapacity) is used to copy the original contents into the newly created array and replace the array referenced by the container.
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
The specific expansion logic is completed in the growth (mincapacity) method. The core of the method is based on the capacity of 1.5 times of oldCapacity.
- If the capacity is less than what I need, at least use it.
- If it is greater than the maximum capacity of ArrayList, integer will be used MAX_ VALUE.
- If more than the minimum required capacity is less than the maximum container capacity, use 1.5 times this value.
The calculation of expansion capacity can be roughly divided into these three cases.
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
2.1 so why take the value of 1.5 times as the benchmark for comparison?
This value should belong to the category of experience. The designer just has the following two considerations.
- 1.5x capacity expansion can avoid frequent capacity expansion, which has a price. Frequent capacity expansion will affect the performance of ArrayList.
- Why not set 2x, 3x. Maybe compared with most cases, 1.5 times can reduce the waste of resources to a certain extent. After all, the length of our application array is an advance.
3. After sublist modifies the value, the original ArrayList will change
SubList is actually an internal class of ArrayList, a SubList object, which actually belongs to a part of the current ArrayList object. Generally speaking, SubList is a continuous subset of ArrayList.
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
// ... ...
}
The set method is as follows: get the original value of the index subscript of the parent ArrayList, replace the position with the new value and return the original value. Therefore, when you modify the sublist, the content of the value of the original parent ArrayList will also be modified. Therefore, if you want to keep the contents of the original address unchanged, the sublist can either just traverse or Copy a Copy.
public E set(int index, E e) {
rangeCheck(index);
checkForComodification();
E oldValue = ArrayList.this.elementData(offset + index);
ArrayList.this.elementData[offset + index] = e;
return oldValue;
}
4. ArrayList summary
To sum up, ArrayList itself is implemented based on arrays, and some methods are provided internally. get, set, etc. are fast accessed based on subscripts. The linear table realized by array has advantages in some scenarios, such as sorting, ordered list, fast search and so on. Of course, it also has some disadvantages. For example, if you insert a value at the non end position, you have to do a group of operations to move the array from the insertion position to the end, and the deletion is the same. The time complexity is O(n), and the performance is not very good.
3, LinkedList source code analysis
1. Is LinkedList just a list?
As we all know, LinkedList is implemented based on two-way linked list, which is very applicable in high-frequency insertion and deletion scenarios, such as queue and stack. Therefore, LinkedList implements Deque interface and provides push, pop, offer, poll and other methods.
Definition of node elements in LinkedList bidirectional linked list
private static class Node<E> {
E item; // Current element value
Node<E> next; // Successor
Node<E> prev; // precursor
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
The head node and tail node of LinkedList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
// ... ...
}
The above code definition is very intuitive, which is a typical linked list structure. Remember how to use linked list to realize stack and queue in the basic course of programming in college?
2. Iteration of LinkedList
According to the simple case of get(index), in fact, the linked list iteration is to constantly change the direction of the traversal pointer, traverse downward, and find the value of a fixed position by counting. Therefore, the query efficiency of linked list is not high.
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3. LinkedList summary
The main scenario of the linked list is still in the stack and queue, and the application scenario of non query and modification has great advantages in insertion and update. However, not all linked list query performance is not high. For example, based on 2n times of spatial complexity, multi-level index is adopted to greatly optimize the query performance of linked list, but relatively speaking, there is more index maintenance logic in insertion and deletion.
6, Summary
The difference between ArrayList and LinkedeList
- The data structure is different. ArrayList is based on array and LinkedList is based on two-way linked list.
- Query efficiency: ArrayList has fast random access speed based on array subscripts, while LinkedList is slow to complete the query through linked list iteration. (it takes 0ms to find the 40W in the 50W long array and 8ms to find the 40W in the 50W long linked list)
- The insertion and deletion efficiency is different. The ArrayList insertion and deletion operations need to be completed with the shift of elements, which is very inefficient. LinkedList insertion and deletion only need to adjust the pointing of the pointer field, which is very efficient.
The above efficiency problem is nothing more than the difference between the time complexity O (1) and O (n) of the two data structures in get(index), add (index, e) and remove (index).
The time complexity of ArrayList in get(index) is O (1), the time complexity of add (index, e) and remove (index) is O(n).
The time complexity of LinkedList is O(n) in get(index), O (1) in add (index, e) and remove (index).