Atomicity
Many people confuse [java memory structure] with [Java Memory Model]. Java Memory Model means Java Memory Model (JMM).
For its authoritative explanation, please refer to https://download.oracle.com/otn-pub/jcp/memory_model-1.0-pfd-spec-oth-JSpec/memory_model-1_0-pfd-spec.pdf?AuthParam=1562811549_4d4994cbd5b59d964cd2907ea22ca08b
In short, JMM defines a set of rules and guarantees for the visibility, ordering and atomicity of data when reading and writing shared data (member variables and arrays) by multiple threads
Atomicity
Atomicity was mentioned when learning threads. Here is an example to briefly review:
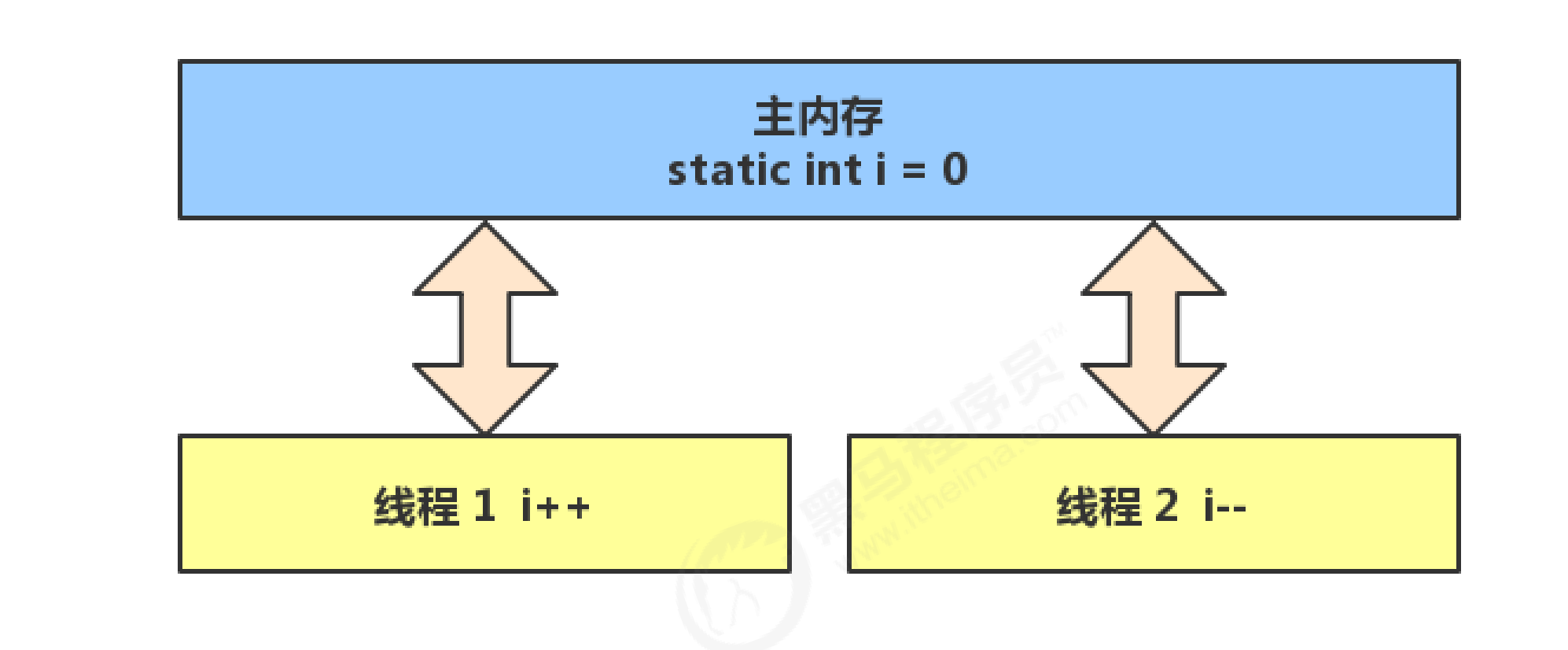
The question is raised. Two threads increase and decrease static variables with an initial value of 0 for 5000 times respectively. Is the result 0?
problem analysis
The above results may be positive, negative or zero. Why? Because the self increment and self decrement of static variables in Java are not atomic operations.
For example, for i + + (i is a static variable), the following JVM bytecode instructions will actually be generated:
getstatic i // Gets the value of the static variable i iconst_1 // Prepare constant 1 iadd // addition putstatic i // Store the modified value into the static variable i
The corresponding i-- is similar:
getstatic i // Gets the value of the static variable i iconst_1 // Prepare constant 1 isub // subtraction putstatic i // Store the modified value into the static variable i
This is a static variable, which is different from local variables
The local variable i + + increases iinc directly on the slot
The static variable i + + is getstatic loaded into the operand stack, and then iadd adds iconst_1 constant 1
Different threads operate in their own operand stack
If it is a single thread, the above 8 lines of code are executed sequentially (without interleaving), there is no problem:
// Assume that the initial value of i is 0 getstatic i // Thread 1 - get the value of static variable i, i=0 in the thread iconst_1 // Thread 1 - prepare constant 1 iadd // Thread 1 - self incrementing i=1 putstatic i // Thread 1 - stores the modified value into static variable I, static variable i=1 getstatic i // Thread 1 - get the value of static variable i, i=1 in the thread iconst_1 // Thread 1 - prepare constant 1 isub // Thread 1 - self decrementing i=0 putstatic i // Thread 1 - stores the modified value in static variable I, static variable i=0
However, these 8 lines of code may be interleaved under multithreading (why? Think about it):
Because in concurrent operations, different threads preempt the cpu. The cpu runs in a time slice. Once the time slice arrives, the threads should be switched, and then all threads preempt the cpu time slice. It is also possible that the same thread preempts the cpu time slice many times.
When a negative number occurs:
// Assume that the initial value of i is 0 getstatic i // Thread 1 - get the value of static variable i, i=0 in the thread getstatic i // Thread 2 - get the value of static variable i, i=0 in the thread iconst_1 // Thread 1 - prepare constant 1 iadd // Thread 1 - self incrementing i=1 putstatic i // Thread 1 - stores the modified value into static variable I, static variable i=1 iconst_1 // Thread 2 - prepare constant 1 isub // Thread 2 - self decreasing thread i=-1 putstatic i // Thread 2 - store the modified value into static variable I, static variable i=-1
When a positive number occurs:
// Assume that the initial value of i is 0 getstatic i // Thread 1 - get the value of static variable i, i=0 in the thread getstatic i // Thread 2 - get the value of static variable i, i=0 in the thread iconst_1 // Thread 1 - prepare constant 1 iadd // Thread 1 - self incrementing i=1 iconst_1 // Thread 2 - prepare constant 1 isub // Thread 2 - self decreasing thread i=-1 putstatic i // Thread 2 - store the modified value into static variable I, static variable i=-1 putstatic i // Thread 1 - stores the modified value into static variable I, static variable i=1
Different threads operate in their own operand stack. After the operation, the results are stored in main memory. This thread does not know about the operations of other threads. Read in 0 at the same time, i add 1, and you subtract 1. When i was adding, i didn't know you had changed i to - 1 and put it in the main memory. i'll just change i to 1, put it in main memory, and then overwrite you.
resolvent
Synchronized (synchronized keyword)
grammar
synchronized( object ) {
Code to be used as atomic operation
}
Using synchronized to solve concurrency problems:
static int i = 0;
static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int j = 0; j < 5000; j++) {
synchronized (obj) {
i++;
}
}
});
Thread t2 = new Thread(() -> {
// It is recommended to write synchronized in the outer layer of for, so that locking and unlocking will only be performed once
synchronized (obj) {
for (int j = 0; j < 5000; j++) {
i--;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
How to understand it: you can think of obj as a room and threads t1 and t2 as two people.
When thread t1 executes synchronized(obj), it is like t1 enters the room, locks the door with its back hand, and executes count + + code in the door.
At this time, if t2 also runs to synchronized(obj), it finds that the door is locked and can only wait outside the door.
When t1 executes the code in the synchronized {} block, it will unlock the door and come out of obj room. The t2 thread can then enter the obj room, lock the door and execute its count -- code.
Note: in the above example, t1 and t2 threads must lock the same obj object with synchronized. If t1 locks m1 object and t2 locks m2 object, it is like two people entering two different rooms respectively, which can not achieve the effect of synchronization.
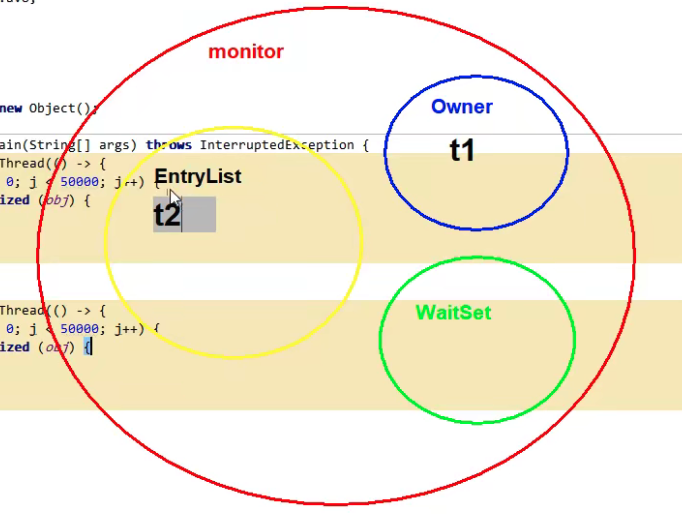
- After the t1 thread comes in, it finds that the lock has no owner, and then it becomes the owner
- t2 thread finds an owner and enters EntryList to wait (blocked)
- When t1 is released after running, t2 can become the owner
- If there are multiple threads in the EntryList, they will preempt the Owner
visibility
Unrequitable cycle
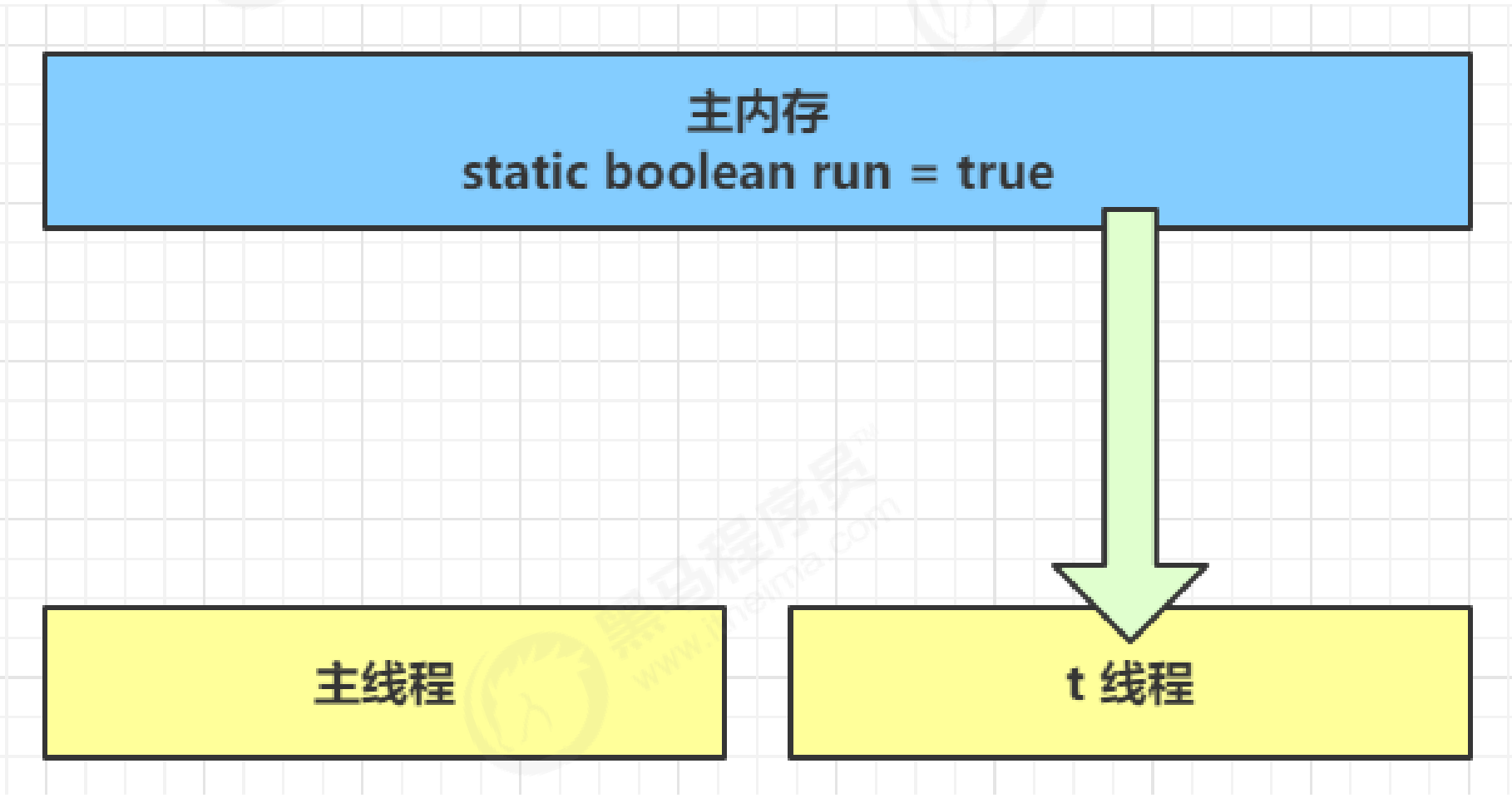
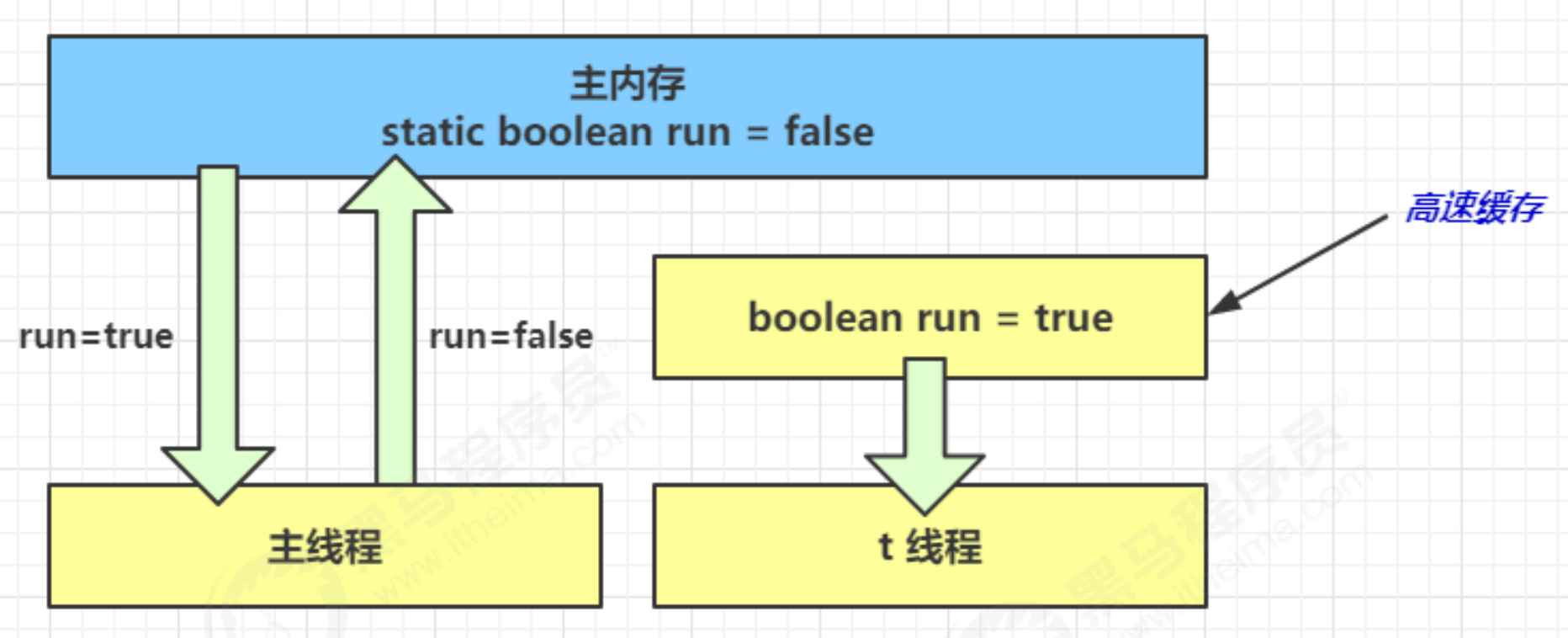
Let's take a look at a phenomenon. The modification of the run variable by the main thread is not visible to the t thread, which makes the t thread unable to stop:
public class Demo4_1 {
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while (run) {
}
});
t.start();
Thread.sleep(1000);
run = false; // The thread t does not stop as expected
}
}
Why? Analyze:
- In the initial state, the t thread just started to read the value of run from the main memory to the working memory.
- Because t threads frequently read the value of run from the main memory, the JIT compiler will cache the value of run into the cache in its own working memory to reduce the access to run in the main memory and improve efficiency
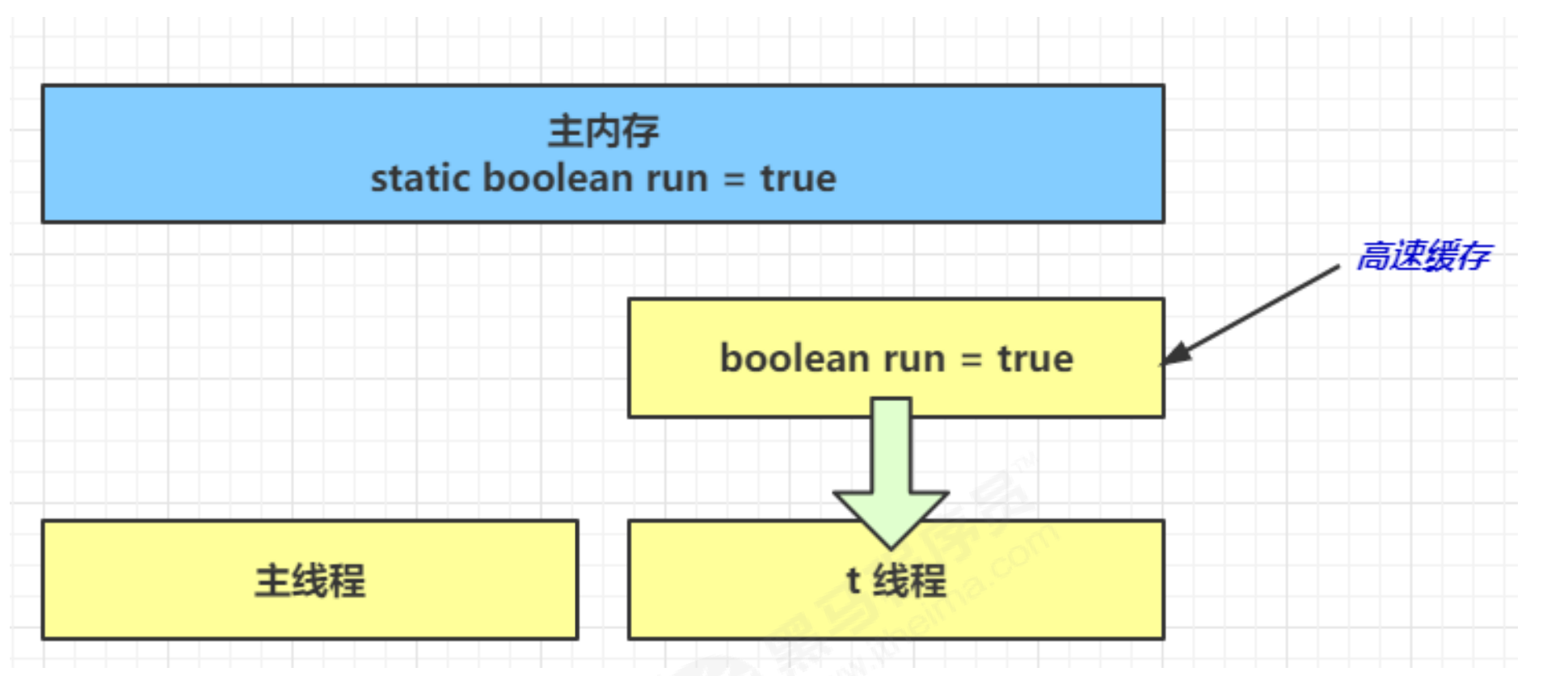
- One second later, the main thread modifies the value of run and synchronizes it to main memory, while t reads the value of this variable from the cache in its working memory, and the result is always the old value
resolvent
Volatile (volatile keyword)
It can be used to modify member variables and static member variables. It can prevent threads from looking up the value of variables from their own work cache and must obtain its value from main memory. Threads operate volatile variables directly in main memory
public class Demo4_1 {
volatile static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while (run) {
}
});
t.start();
Thread.sleep(1000);
run = false;
}
}
result
visibility
The previous example actually reflects visibility. It ensures that the modification of volatile variables by one thread is visible to another thread among multiple threads, which can not guarantee atomicity. It is only used in the case of one write thread and multiple read threads: the above example is understood from bytecode:
getstatic run // Thread t get run true getstatic run // Thread t get run true getstatic run // Thread t get run true getstatic run // Thread t get run true putstatic run // Thread main changes run to false, only this time getstatic run // Thread t get run false
Let's compare the previous examples of thread safety: two threads, one i + + and one i --, can only ensure to see the latest value, but can't solve the problem of instruction interleaving
// Assume that the initial value of i is 0 getstatic i // Thread 1 - get the value of static variable i, i=0 in the thread getstatic i // Thread 2 - get the value of static variable i, i=0 in the thread iconst_1 // Thread 1 - prepare constant 1 iadd // Thread 1 - self incrementing i=1 putstatic i // Thread 1 - stores the modified value into static variable I, static variable i=1 iconst_1 // Thread 2 - prepare constant 1 isub // Thread 2 - self decreasing thread i=-1 putstatic i // Thread 2 - store the modified value into static variable I, static variable i=-1
Note that synchronized statement blocks can not only ensure the atomicity of code blocks, but also ensure the visibility of variables in code blocks. But the disadvantage is that synchronized is a heavyweight operation with relatively lower performance
If you add System.out.println() to the dead loop of the previous example, you will find that thread t can correctly see the modification of the run variable even without the volatile modifier. Think about why?
public class Demo4_1 {
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while (run) {
System.out.println("1");
}
});
t.start();
Thread.sleep(1000);
run = false;
}
}
result
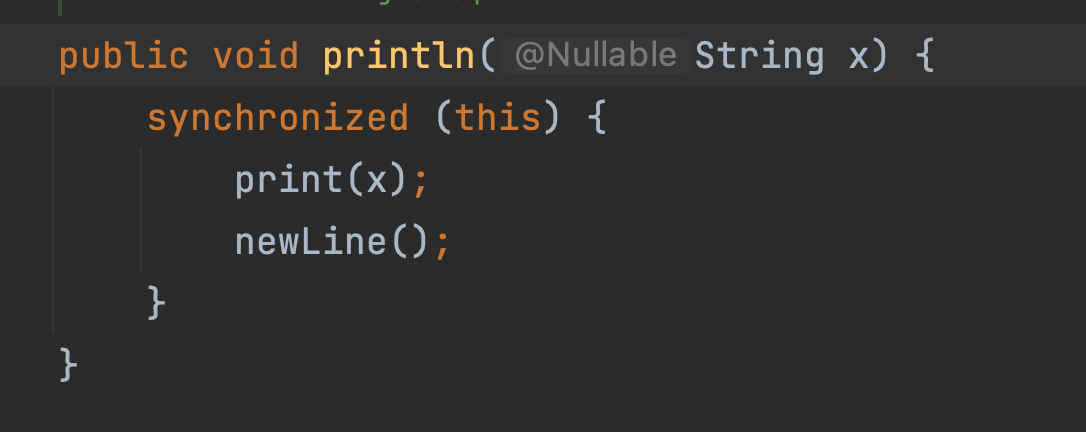
reason
System.out.println(“1”); Modified by synchronized
Order
Strange results
int num = 0;
boolean ready = false;
// Thread 1 executes this method
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// Thread 2 executes this method
public void actor2(I_Result r) {
num = 2;
ready = true;
}
I_Result is an object with an attribute r1 to save the result. Q: how many possible results are there?
Some students analyze it like this
- Case 1: thread 1 executes first. At this time, ready = false, so the result of entering the else branch is 1
- Case 2: thread 2 executes num = 2 first, but does not have time to execute ready = true. Thread 1 executes, or enters the else branch. The result is 1
- Case 3: thread 2 executes to ready = true, and thread 1 executes. This time, it enters the if branch, and the result is 4 (because num has already been executed)
But I tell you, the result may be 0, believe it or not!
- In this case, thread 2 executes ready = true, switches to thread 1, enters the if branch, adds 0, and then switches back to thread 2 to execute num = 2
I believe many people have fainted
This phenomenon is called instruction rearrangement, which is some optimization of JIT compiler at run time. This phenomenon can be repeated only after a large number of tests:
With the help of Java Concurrent pressure measurement tool jcstress https://wiki.openjdk.java.net/display/CodeTools/jcstress
mvn archetype:generate -DinteractiveMode=false - DarchetypeGroupId=org.openjdk.jcstress -DarchetypeArtifactId=jcstress-java-test-archetype -DgroupId=org.sample -DartifactId=test -Dversion=1.0
Create maven project and provide the following test classes
@JCStressTest
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "!!!!")
@State
public class ConcurrencyTest {
int num = 0;
boolean ready = false;
@Actor
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
@Actor public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
implement
mvn clean install java -jar target/jcstress.jar
We will output the results we are interested in and extract one of the results:
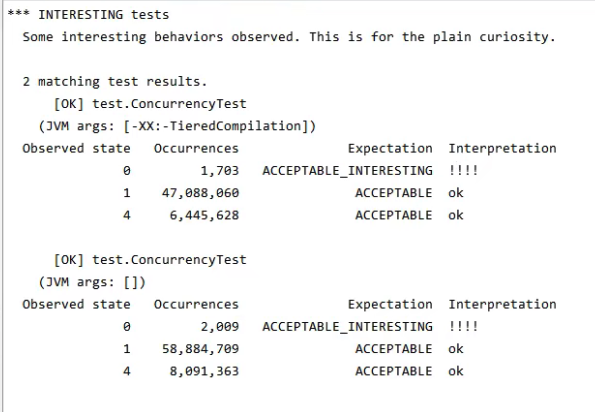
It can be seen that there are 638 times when the result is 0. Although the number is relatively small, it appears after all.
resolvent
volatile modified variable, which can disable instruction rearrangement
@JCStressTest
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "!!!!")
@State
public class ConcurrencyTest {
int num = 0;
volatile boolean ready = false;
@Actor
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
@Actor public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
The result is:

Ordered understanding
The JVM can adjust the execution order of statements without affecting the correctness. Consider the following code
static int i; static int j; // Perform the following assignment operations in a thread i = ...; // More time-consuming operations j = ...;
It can be seen that whether to execute i or j first will not affect the final result. Therefore, when the above code is actually executed, it can be
i = ...; // More time-consuming operations j = ...;
It can also be
j = ...; i = ...; // More time-consuming operations
This feature is called instruction rearrangement. In multithreading, instruction rearrangement will affect the correctness. For example, the famous double checked locking mode implements a single example
public final class Singleton {
private Singleton() {
}
private static Singleton INSTANCE = null;
public static Singleton getInstance() {
// An instance is not created before it enters the internal synchronized code block
if (INSTANCE == null) {
synchronized (Singleton.class) {
// Maybe another thread has created an instance, so judge again
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
The above implementation features are:
- Lazy instantiation
- Only when getInstance() is used for the first time can synchronized locking be used. No locking is required for subsequent use
However, in a multithreaded environment, the above code is problematic. The bytecode corresponding to INSTANCE = new Singleton() is:

The sequence of 4 and 7 steps is not fixed. Maybe the jvm will optimize as follows: first assign the reference address to the INSTANCE variable, and then execute the construction method. If two threads t1 and t2 execute according to the following time series:

At this time, t1 has not completely executed the construction method. If many initialization operations need to be performed in the construction method, t2 will get an uninitialized single instance
Use volatile modification on INSTANCE to disable instruction rearrangement. However, it should be noted that volatile in JDK version 5 or above is really effective
happens-before
Happens before specifies which write operations are visible to the read operations of other threads. It is a summary of a set of rules for visibility and ordering. Regardless of the following happens before rules, JMM cannot ensure that the write of a thread to a shared variable is visible to the read of the shared variable by other threads
- The write of the variable before the thread unlocks m is visible to the read of the variable by other threads that lock m next
static int x;
static Object m = new Object();
new Thread(()->{
synchronized(m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized(m) {
System.out.println(x);
}
},"t2").start();
- When a thread writes a volatile variable, it is visible to other threads reading the variable
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();
- The write to the variable before the thread starts is visible to the read to the variable after the thread starts
static int x;
x = 10;
new Thread(()->{
System.out.println(x);
},"t2").start();
- The write to the variable before the thread ends is visible to the read after other threads know it ends (for example, other threads call t1.isAlive() or t1.join() to wait for it to end)
static int x;
Thread t1 = new Thread(()->{
x = 10;
},"t1");
t1.start();
t1.join();
System.out.println(x);
- Thread t1 writes to the variable before interrupting T2 (interrupt), which is visible to other threads after they know that T2 is interrupted (through t2.interrupted or t2.isInterrupted)
static int x;
public static void main(String[] args) {
Thread t2 = new Thread(()->{
while(true) {
if(Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
},"t2");
t2.start();
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
x = 10;
t2.interrupt();
},"t1").start();
while(!t2.isInterrupted()) {
Thread.yield();
}
System.out.println(x);
-
The writing of the default value of the variable (0, false, null) is visible to the reading of the variable by other threads
-
It has transitivity. If x HB - > y and Y HB - > Z, then there is x HB - > Z
Variables refer to member variables or static member variables
CAS and atomic class
CAS
Lock free concurrency. CAS is Compare and Swap, which embodies an optimistic locking idea. For example, multiple threads need to perform + 1 operation on a shared integer variable:
// You need to keep trying
while(true) {
int Old value = Shared variable ; // For example, you get the current value 0
int result = Old value + 1; // Add 1 to the old value of 0, and the correct result is 1
/*At this time, if other threads change the shared variable to 5, the correct result 1 of this thread will be invalidated. At this time, compareAndSwap returns false and try again until compareAndSwap returns true, which means that other threads do not interfere with my modifications
*/
if( compareAndSwap ( Old value, result )) {
// Successful, exit loop
}
}
- Before exchanging the result with the old value, the old value is compared with the shared variable. If the shared variable is not changed by other threads and is equal to the old value, the old value will be exchanged with the result.
- When obtaining a shared variable, in order to ensure the visibility of the variable, you need to use volatile decoration. The combination of CAS and volatile can realize lock free concurrency, which is suitable for the scenario of non fierce competition and multi-core CPU.
- Because synchronized is not used, the thread will not be blocked, which is one of the factors to improve efficiency
- However, if the competition is fierce, it can be expected that retry will occur frequently, but the efficiency will be affected
The CAS bottom layer relies on an Unsafe class to directly call CAS instructions at the bottom of the operating system. The following is an example of thread safety protection directly using Unsafe objects
package P4;
import sun.misc.Unsafe;
import java.lang.reflect.Field;
/**
* @author Chaichai is happy every day
* @create 2021-09-30 11:27 morning
* <p>
* 『Stay hungry, stay foolish. 』
*/
public class TestCAS {
public static void main(String[] args) throws InterruptedException {
DataContainer dc = new DataContainer();
int count = 10000;
Thread t1 = new Thread(() -> {
for (int i = 0; i < count; i++) {
dc.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < count; i++) {
dc.decrease();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(dc.getData());
}
}
class DataContainer{
private volatile int data;
static final Unsafe unsafe;
static final long DATA_OFFSET;
static {
try {
// Unsafe objects cannot be called directly. They can only be obtained through reflection
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
unsafe = (Unsafe) theUnsafe.get(null);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new Error(e);
}
try {
// The offset of the data property in the DataContainer object, which is used by Unsafe to access the property directly
DATA_OFFSET = unsafe.objectFieldOffset(DataContainer.class.getDeclaredField("data"));
} catch (NoSuchFieldException e) {
throw new Error(e);
}
}
public void increase() {
int oldValue;
while(true) {
// Get the old value of shared variable. You can add breakpoints in this line and modify data debugging to deepen understanding
oldValue = data;
// cas tries to change the data to the old value + 1. If the old value is changed by another thread during the period, false is returned
if (unsafe.compareAndSwapInt(this, DATA_OFFSET, oldValue, oldValue + 1)) {
return;
}
}
}
public void decrease() {
int oldValue;
while(true) {
oldValue = data;
if (unsafe.compareAndSwapInt(this, DATA_OFFSET, oldValue, oldValue - 1)) {
return;
}
}
}
public int getData() {
return data;
}
}
result
Optimistic lock and pessimistic lock
- CAS is based on the idea of optimistic locking: the most optimistic estimate is that you are not afraid of other threads to modify shared variables. Even if you do, it doesn't matter. I'll try again at a loss.
- synchronized is based on the idea of pessimistic lock: the most pessimistic estimate is to prevent other threads from modifying shared variables. When I lock, you don't want to change it. Only after I change the lock can you have a chance.
Atomic operation class
juc (java.util.concurrent) provides atomic operation classes, which can provide thread safe operations, such as AtomicInteger, AtomicBoolean, etc. their bottom layer is implemented by CAS technology + volatile.
You can use AtomicInteger to rewrite the previous example:
package P4;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author Chaichai is happy every day
* @create 2021-09-30 11:44 morning
* <p>
* 『Stay hungry, stay foolish. 』
*/
public class Demo4_4 {
// Create an atomic class integer object
private static AtomicInteger i = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()-> {
for (int j = 0; j < 5000; j++) {
i.getAndIncrement(); // Get and auto increment i++
// i.incrementAndGet(); // Auto increment and get + + I
}
});
Thread t2 = new Thread(()-> {
for (int j = 0; j < 5000; j++) {
i.getAndDecrement(); // Get and subtract i--
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
result
synchronized optimization
In the Java HotSpot virtual machine, each object has an object header (including class pointer and Mark Word). Mark Word usually stores the hash code and generation age of this object. When locking, these information will be replaced with tag bit, thread lock record pointer, heavyweight lock pointer, thread ID, etc
Lightweight Locking
If an object has multithreaded access, but the multithreaded access time is staggered (that is, there is no competition), lightweight locks can be used to optimize. This is like:
Student (thread A) occupied his seat with his textbook, went out for half A class (CPU time expired), came back and found that the textbook had not changed, indicating that there was no competition, and continued his class. If another student (thread B) comes during this period, it will inform (thread A) of concurrent access, and thread A will be upgraded to A heavyweight lock and enter the heavyweight lock process.
The heavyweight lock is not so simple to occupy the seat with textbooks. You can imagine that thread A surrounded the seat with an iron fence before leaving
Suppose there are two methods to synchronize blocks and lock with the same object
static Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// Synchronization block A
method2();
}
}
public static void method2() {
synchronized( obj ) {
// Synchronization block B
}
}
The stack frame of each thread will contain a lock record structure, which can store the Mark Word of the locked object
| Thread 1 | Object Mark Word | Thread 2 |
|---|---|---|
| Access synchronization block A and copy Mark to the lock record of thread 1 | 01 (no lock) | - |
| CAS modifies Mark to record the address of thread 1 lock | 01 (no lock) | - |
| Success (locking) | 00 (lightweight lock) thread 1 lock record address | - |
| Execute synchronization block A | 00 (lightweight lock) thread 1 lock record address | - |
| Access synchronization block B and copy Mark to the lock record of thread 1 | 00 (lightweight lock) thread 1 lock record address | - |
| CAS modifies Mark to record the address of thread 1 lock | 00 (lightweight lock) thread 1 lock record address | - |
| Failed (found to be your own lock) | 00 (lightweight lock) thread 1 lock record address | - |
| Lock reentry | 00 (lightweight lock) thread 1 lock record address | - |
| Execute synchronization block B | 00 (lightweight lock) thread 1 lock record address | - |
| Synchronization block B execution completed | 00 (lightweight lock) thread 1 lock record address | - |
| Synchronization block A completed | 00 (lightweight lock) thread 1 lock record address | - |
| Successful (unlocked) | 01 (no lock) | |
| - | 01 (no lock) | Access synchronization block A and copy Mark to the lock record of thread 2 |
| - | 01 (no lock) | CAS modifies Mark to record the address of thread 2 lock |
| - | 00 (lightweight lock) thread 2 lock record address | Success (locking) |
| - | ... | ... |
The access times of thread 1 and thread 2 are staggered. (i.e. no competition)
Lock expansion
If the CAS operation fails when trying to add a lightweight lock, then another thread adds a lightweight lock (with competition) to this object. At this time, lock expansion is required to change the lightweight lock into a heavyweight lock.
static Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// Synchronization block
}
}
| Thread 1 | Object Mark | Thread 2 |
|---|---|---|
| Access the synchronization block and copy the Mark to the lock record of thread 1 | 01 (no lock) | - |
| CAS modifies Mark to record the address of thread 1 lock | 01 (no lock) | - |
| Success (locking) | 00 (lightweight lock) thread 1 lock record address | - |
| Execute synchronization block | 00 (lightweight lock) thread 1 lock record address | - |
| Execute synchronization block | 00 (lightweight lock) thread 1 lock record address | Access the synchronization block and copy Mark to thread 2 |
| Execute synchronization block | 00 (lightweight lock) thread 1 lock record address | CAS modifies Mark to record the address of thread 2 lock |
| Execute synchronization block | 00 (lightweight lock) thread 1 lock record address | Failure (finding that someone else has occupied the lock) |
| Execute synchronization block | 00 (lightweight lock) thread 1 lock record address | CAS changed Mark to weight lock |
| Execute synchronization block | 10 (weight lock) weight lock pointer | Blocking |
| completion of enforcement | 10 (weight lock) weight lock pointer | Blocking |
| Failed (unlocked) | 10 (weight lock) weight lock pointer | Blocking |
| Release the weight lock to evoke blocking thread contention | 01 (no lock) | Blocking |
| - | 10 (weight lock) | Competitive weight lock |
| - | 10 (weight lock) | Success (locking) |
| - | ... | ... |
When there is competition between threads, lightweight locks expand into heavyweight locks.
Weight lock
When competing for heavyweight locks, you can also use spin to optimize. If the current thread spins successfully (that is, the lock holding thread has exited the synchronization block and released the lock), the current thread can avoid blocking.
After Java 6, the spin lock is adaptive. For example, if the object has just succeeded in a spin operation, it is considered that the possibility of successful spin this time will be high, so spin more times; On the contrary, less spin or even no spin. In short, it is more intelligent.
- Spin will occupy CPU time. Single core CPU spin is a waste, and multi-core CPU spin can give play to its advantages.
- For example, whether the car stalls when waiting for a red light. Not stalling is equivalent to spinning (waiting time is short and cost-effective), and stalling is equivalent to blocking (waiting time is long and cost-effective)
- After Java 7, you can't control whether to turn on the spin function
Spin retry success
| Thread 1 (on cpu1) | Object Mark | Thread 2 (on cpu2) |
|---|---|---|
| - | 10 (weight lock) | - |
| Access the synchronization block and get the monitor | 10 (weight lock) weight lock pointer | - |
| Success (locking) | 10 (weight lock) weight lock pointer | - |
| Execute synchronization block | 10 (weight lock) weight lock pointer | - |
| Execute synchronization block | 10 (weight lock) weight lock pointer | Access the synchronization block and get the monitor |
| Execute synchronization block | 10 (weight lock) weight lock pointer | Spin retry |
| completion of enforcement | 10 (weight lock) weight lock pointer | Spin retry |
| Successful (unlocked) | 01 (no lock) | Spin retry |
| - | 10 (weight lock) weight lock pointer | Success (locking) |
| - | 10 (weight lock) weight lock pointer | Execute synchronization block |
| - | ... | ... |
Spin retry failure
| Thread 1 (on cpu1) | Object Mark | Thread 2 (on cpu2) |
|---|---|---|
| - | 10 (weight lock) | - |
| Access the synchronization block and get the monitor | 10 (weight lock) weight lock pointer | - |
| Success (locking) | 10 (weight lock) weight lock pointer | - |
| Execute synchronization block | 10 (weight lock) weight lock pointer | - |
| Execute synchronization block | 10 (weight lock) weight lock pointer | Access the synchronization block and get the monitor |
| Execute synchronization block | 10 (weight lock) weight lock pointer | Spin retry |
| Execute synchronization block | 10 (weight lock) weight lock pointer | Spin retry |
| Execute synchronization block | 10 (weight lock) weight lock pointer | Spin retry |
| Execute synchronization block | 10 (weight lock) weight lock pointer | block |
| - | ... | ... |
Bias lock
The lightweight lock still needs to perform CAS operation every time it re enters when there is no competition (just its own thread). Bias lock is introduced in Java 6 for further optimization: only when CAS is used for the first time to set the thread ID to the Mark Word header of the object, and then it is found that the thread ID is its own, it means that there is no competition and there is no need to re CAS
- Revoking bias requires upgrading the locked thread to a lightweight lock, during which all threads need to be suspended (STW)
- The hashCode of the access object will also revoke the bias lock
- If the object is accessed by multiple threads, but there is no competition, the object biased to thread T1 still has the opportunity to re bias to T2, and the re bias will reset the Thread ID of the object
- Undo bias and redo bias are performed in batches. All objects of a class are operated in batches with the class as the unit
- If the undo bias reaches a certain threshold, all objects of the entire class become unbiased. If you always withdraw, you won't be biased directly.
- You can actively use - XX:-UseBiasedLocking to disable bias locking
You can refer to this paper: https://www.oracle.com/technetwork/java/biasedlocking-oopsla2006-wp-149958.pdf
Suppose there are two methods to synchronize blocks and lock with the same object
static Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// Synchronization block A
method2();
}
}
public static void method2() {
synchronized( obj ) {
// Synchronization block B
}
}
| Thread 1 | Object Mark |
|---|---|
| Access synchronization block A and check whether there is A thread ID in Mark | 101 (no lock can be biased) |
| Try to apply bias lock | 101 (lockless deflectable) object hashCode |
| success | 101 (lockless biased) thread ID |
| Execute synchronization block A | 101 (lockless biased) thread ID |
| Access synchronization block B and check whether there is a thread ID in Mark | 101 (lockless biased) thread ID |
| Is its own thread ID, and the lock is its own. No more operations are required | 101 (lockless biased) thread ID |
| Execute synchronization block B | 101 (lockless biased) thread ID |
| completion of enforcement | 101 (lockless deflectable) object hashCode |
Other optimization
Reduce locking time
Keep synchronization code blocks as short as possible
Reduce lock granularity
Split a lock into multiple locks to improve concurrency, for example:
- ConcurrentHashMap
- LongAdder is divided into base and cells. When there is no concurrent contention or the cell array is initializing, CAS will be used to accumulate the value to the base. If there is concurrent contention, the cell array will be initialized. The number of cells in the array will be allowed to be modified in parallel. Finally, each cell in the array will be accumulated and the base will be the final value
- LinkedBlockingQueue uses different locks for entering and leaving the queue. Compared with LinkedBlockingArray, there is only one lock, which is more efficient
Lock coarsening
It is better to cycle multiple times into the synchronization block than to cycle multiple times in the synchronization block. In addition, the JVM may make the following optimization to coarsen the locking operation of multiple append into one (because they lock the same object, it is not necessary to re-enter multiple times)
new StringBuffer().append("a").append("b").append("c");
Lock elimination
The JVM will perform code escape analysis. For example, a locked object is a local variable in a method and will not be accessed by other threads. At this time, all synchronization operations will be ignored by the immediate compiler.
Read write separation
CopyOnWriteArrayList ConyOnWriteSet
reference resources:
https://wiki.openjdk.java.net/display/HotSpot/Synchronization
http://luojinping.com/2015/07/09/java Lock optimization/
https://www.infoq.cn/article/java-se-16-synchronized
https://www.jianshu.com/p/9932047a89be
https://www.cnblogs.com/sheeva/p/6366782.html
https://stackoverflflow.com/questions/46312817/does-java-ever-rebias-an-individual-lock