1. Introduction
Autonomous pod and controller managed Pod:
- Autonomous Pod: the pod exits and will not be created again because there is no manager (resource controller).
- Pod managed by the controller: maintain the number of copies of the pod throughout the life cycle of the controller
There are many controller s built in K8S, which are equivalent to a state machine to control the specific state and behavior of Pod
2. ReplicaSet
Function: used to ensure that the number of application copies of the container is always the number of user-defined copies. If a container exits abnormally, a new Pod will be created to replace it; If more, it will be recycled automatically.
RS is the replacement of RC (replication controller, obsolete). The selector tag is used to identify which pod s belong to its current, and the labels in the template must correspond
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
$ kubectl get pod --show-labels NAME READY STATUS RESTARTS AGE LABELS nginx-26h68 1/1 Running 0 37s app=web nginx-42hmj 1/1 Running 0 37s app=web nginx-jsg8f 1/1 Running 0 37s app=web $ kubectl label pod nginx-26h68 app=nginx --overwrite=true pod/nginx-26h68 labeled $ kubectl get pod --show-labels NAME READY STATUS RESTARTS AGE LABELS nginx-26h68 1/1 Running 0 112s app=nginx # No longer managed by rs nginx-42hmj 1/1 Running 0 112s app=web nginx-cdt4w 1/1 Running 0 16s app=web nginx-jsg8f 1/1 Running 0 112s app=web
3. Deployment
Role: automatically manage ReplicaSet. ReplicaSet does not support rolling update, but Deployment does.
- Rolling upgrade and rollback application (create a new RS, the Pod of the new RS increases by 1, and the Pod of the old RS decreases by 1)
- Expansion and contraction
- Pause and resume Deployment
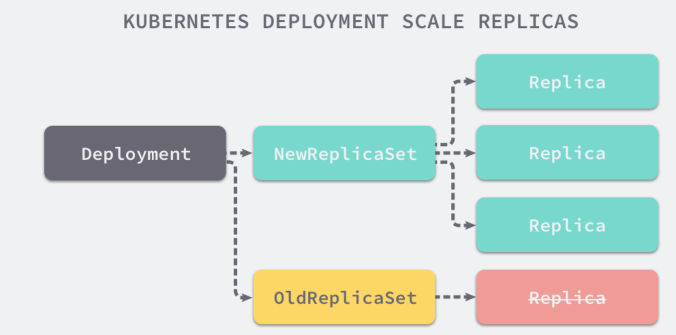
Deploy a simple Nginx application
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
$ kubectl get pod --show-labels NAME READY STATUS RESTARTS AGE LABELS nginx-7848d4b86f-578zp 1/1 Running 0 64s app=nginx,pod-template-hash=7848d4b86f nginx-7848d4b86f-79mrj 1/1 Running 0 64s app=nginx,pod-template-hash=7848d4b86f nginx-7848d4b86f-zrmgx 1/1 Running 0 64s app=nginx,pod-template-hash=7848d4b86f # Capacity expansion $ kubectl scale deployment nginx --replicas=5 # When the image is updated, rs is automatically created $ kubectl set image deployment/nginx nginx=nginx:1.21.3 # RollBACK $ kubectl rollout undo deployment/nginx # Query rollback status $ kubectl rollout status deployment/nginx # View the historical version (when creating, add -- record and the description will be displayed) $ kubectl rollout history deployment/nginx # Rollback to a historical version $ kubectl rollout undo deployment/nginx --to-revision=2 # update paused $ kubectl rollout pause deployment/nginx
Version update strategy: 25% replacement by default
Clean up history version: you can specify the maximum number of revision history records retained by Deployment by setting spec.revisionHistoryLimit. All revisions are reserved by default. If this item is set to 0, Deployment cannot be rolled back
4. DaemonSet
Ensure that a Pod copy is running on each node that is not tainted. When a new node joins the cluster, it will automatically add a Pod copy on the node When the cluster removes a node, the Pod will also be recycled. Deleting the DaemonSet will delete all the pods it creates.
Some typical scenarios of using the DaemonSet:
- Run the cluster storage daemon, such as glusterd, ceph on each Node
- Run the log collection daemon on each Node, such as fluent D and logstash
- Run the monitoring daemon on each Node, such as promethsus Node exporter, collected, datalog agent, new replica agent, Ganglia, gmond
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx
labels:
app: nginx
spec:
selector:
matchLabels:
name: nginx
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: nginx
image: nginx
5. Job
Role: it is responsible for batch processing tasks, that is, tasks that are executed only once. It ensures the successful completion of one or more pods of batch processing tasks
If the execution fails, a Pod will be re created and the execution will continue until it succeeds
Special instructions:
- . The format of spec.template is the same as that of Pod
- . spec.restartPolicy only supports Never or OnFailure
- . spec.completions flag the number of pods to be run at the end of the Job. The default is 1
- . spec.parallelism flag indicates the number of pods running in parallel. The default is 1
- . spec.activeDeadlineSeconds flag failed. The maximum retry time of Pod will not be retried beyond this time
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
$ kubectl get job NAME COMPLETIONS DURATION AGE pi 1/1 10s 96s $ kubectl get pod NAME READY STATUS RESTARTS AGE pi-mr59r 0/1 Completed 0 74s $ kubectl logs pi-mr59r 3.1415926535897932384626...
6. CronJob
Function: timed Job
- Execute only once at a given point in time
- Run periodically at a given point in time
Special instructions:
-
. spec.schedule: scheduling, required field, the format is the same as Cron
-
. spec.jobTemplate: the format is the same as Pod
-
. spec.startingDeadlineSeconds: the time limit for starting a Job. Optional fields. If the scheduled time is missed for any reason, the Job that missed the execution time is considered to have failed
-
. spec.concurrencyPolicy: concurrency policy, optional field
- Allow: by default, concurrent jobs are allowed
- Forbid: concurrent jobs are prohibited and can only be executed sequentially
- Replace: replace the currently running Job with a new Job
-
. spec.suspend: suspend, optional field. If set to true, all subsequent executions will be suspended. The default is fasle
-
. Spec.successfuljobsshistorylimit and Spec.failedjobsshistorylimit: history limit, optional field. They specify how many completed and failed jobs can be retained. The default values are 3 and 1. If set to 0, jobs of related types will not be retained after completion
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo 'hello world'
restartPolicy: OnFailure
$ kubectl get cj NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE hello */1 * * * * False 4 13s 7m13s $ kubectl get job NAME COMPLETIONS DURATION AGE hello-27337347 1/1 5s 6m37s hello-27337348 1/1 6s 5m37s hello-27337349 1/1 6s 4m37s $ kubectl get pod NAME READY STATUS RESTARTS AGE hello-27337347-rbrk2 0/1 Completed 0 7m8s hello-27337348-bnnzt 0/1 Completed 0 6m8s hello-27337349-6wfgk 0/1 Completed 0 5m8s
7. StatefulSet
Role: solve the problem of stateful services and ensure the order of deployment and scale
Typical usage scenarios:
- Stable persistent storage, that is, after the Pod is rescheduled, it can also access the same persistent data, which is realized based on PVC
- Stable network identification, i.e. the PodName and HostName remain unchanged after the Pod is rescheduled, and is implemented based on Headless Service (i.e. Service without Cluster IP)
- Orderly deployment and orderly expansion, that is, pods are orderly. During deployment and expansion, they should be carried out in sequence according to the defined order (i.e. from 0 to N - 1. Before the next Pod runs, all pods must be in Running and Ready status), which is based on Init Containers
- Orderly contraction and orderly deletion (i.e. from N-1 to 0)
# Storages
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
nfs:
path: /nfsdata
server: 192.168.80.240
---
# MySQL configurations
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
# Apply this config only on the master.
[mysqld]
log-bin
default-time-zone='+8:00'
character-set-client-handshake=FALSE
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4 COLLATE utf8mb4_unicode_ci'
slave.cnf: |
# Apply this config only on slaves.
[mysqld]
super-read-only
default-time-zone='+8:00'
character-set-client-handshake=FALSE
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4 COLLATE utf8mb4_unicode_ci'
---
# Headless service for stable DNS entries of StatefulSet members.
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
# Client service for connecting to any MySQL instance for reads.
# For writes, you must instead connect to the master: mysql-0.mysql.
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
---
# Applications
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
# Generate mysql server-id from pod ordinal index.
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# Add an offset to avoid reserved server-id=0 value.
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# Copy appropriate conf.d files from config-map to emptyDir.
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d/
else
cp /mnt/config-map/slave.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d/
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: ipunktbs/xtrabackup
command:
- bash
- "-c"
- |
set -ex
# Skip the clone if data already exists.
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Skip the clone on master (ordinal index 0).
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# Clone data from previous peer.
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# Prepare the backup.
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 512m
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# Check we can execute queries over TCP (skip-networking is off).
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: ipunktbs/xtrabackup
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# Determine binlog position of cloned data, if any.
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup already generated a partial "CHANGE MASTER TO" query
# because we're cloning from an existing slave. (Need to remove the tailing semicolon!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# Ignore xtrabackup_binlog_info in this case (it's useless).
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# We're cloning directly from master. Parse binlog position.
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# Check if we need to complete a clone by starting replication.
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# In case of container restart, attempt this at-most-once.
mv change_master_to.sql.in change_master_to.sql.orig
fi
# Start a server to send backups when requested by peers.
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 100m
memory: 100Mi
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
8. Horizontal Pod AutoScalling
The resource utilization of applications usually has peaks and valleys. How to cut peaks and fill valleys to improve the overall resource utilization of the cluster, HPA provides the horizontal automatic scaling function of Pod
It is applicable to Deployment and ReplicaSet. It supports automatic capacity expansion / reduction according to the CPU and memory utilization of Pod, user-defined metric, etc