preface
In the first section, we mentioned that on the kafka server side, we can create producers and send messages through commands. However, in the actual development, we all create producers and send messages in the project in the form of java. In this section, we will explain kafka producer based on JAVA API.
1, Introduction to JAVA API call kafka producer
Let's start with the code and see how java creates producers and sends messages.
Firstly, the kafka client jar package is introduced into the pom of maven project, as shown in the following figure:
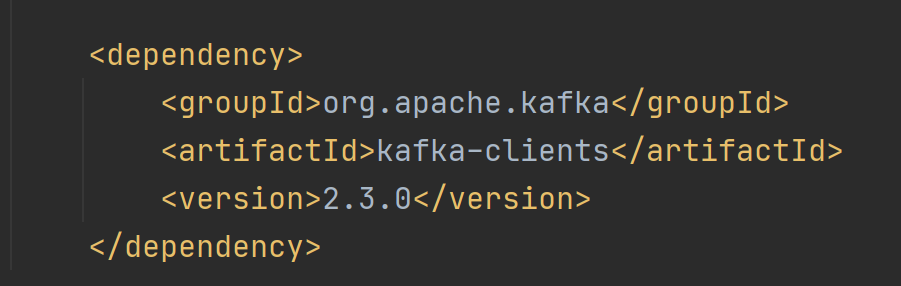
We are talking about version 2.30 here, so we also choose version 2.3 for jar package.
Then create a producer class and send a message to kafka service. The code is as follows:
public class HelloKafkaProducer {
public static void main(String[] args) {
//Create a Properties collection, set and store the Properties of kafka producers
Properties properties = new Properties();
//kafka service address. Multiple addresses can be set in the cluster environment, separated by commas
properties.put("bootstrap.servers","127.0.0.1:9092");
//kafka only knows byte array when receiving message, defines serializer of key and serializer of value of message, and converts them into byte array
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//Create a kafka producer object and pass the properties to the producer
try (KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);){
//The producer's message is stored in the ProducerRecord object
ProducerRecord<String,String> record;
try {
//TODO sends 4 messages
for(int i=0;i<4;i++){
//Set the subject of the message, the key value of the message and the content of the message
record = new ProducerRecord<String,String>("Hello World", null,"lison");
//send message
producer.send(record);
System.out.println(i+",message is sent");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
After running the code, the message is sent to the kafka server. The topic is a new topic, which is not available in the kafka server. Let's further understand and analyze the above code.
2, Producer attributes
From the above entry code, we can see that some attributes need to be set for the producer, such as kafka service address, serializer, etc. Let's summarize the attributes of producers.
kafka's JAVA API provides the ProducerConfig class, which defines all the attributes of the producer. Let's look at several key attributes:
- acks:0,1,all,-1
Message confirmation mechanism. The default value is 1. In the ProducerConfig class, there is an explanation of the acks mechanism:

ACKS_DOC is the interpretation of acks attribute. The interpretation after translation is as follows:
The number of confirmations received by the producer before the request is completed. This controls the persistence of records sent. As mentioned in the previous knowledge, the producer interacts with the division leader, so the division leader needs to confirm the number.
Let's continue to translate:
Allow the following settings:
- **acks=0 * * if set to zero, the producer will not wait for any confirmation from the server at all. The record is immediately added to the socket buffer and is considered sent. In this case, there is no guarantee that the server has received the record, and the retry configuration will not take effect (because the client is usually unaware of any failure). The offset returned for each record will always be set to - 1
- **acks=1 * * this means that the leader will write the record to the local log, but will not wait for full confirmation of all follower copies. In this case, if the leader fails immediately after confirming the record but before the follower copies it, the record will be lost
- acks=all, which means that the leader will wait for the full set of synchronous replica confirmation records. This ensures that records will not be lost as long as at least one synchronous copy remains active. This is the most powerful guarantee. This is equivalent to the acks=-1 setting. "
As we know from the above translation, when acks is 0, no matter whether the partition leader of kafka service receives it successfully or not, send it. When acks is 0, kafka's retry mechanism will not be used. When acks is 1, confirm that the leader has successfully received the message. As for whether the message is successfully copied by other copies, the producer does not care. According to the knowledge mentioned in the previous cluster, if the message fails to replicate to other replicas in the leader, the message will not be consumed by consumers. When acks is all or - 1, the producer will think that the message has been sent successfully only when the partition and other replicas have received the message. This is the safest mechanism, but it also affects the performance.
-
batch.size
When multiple messages are sent to the same partition, the producer will put them in the same batch. This parameter specifies the memory size that can be used by a batch, calculated in bytes. When the batch memory is filled, all messages in the batch will be sent out. However, producers do not always wait until the batch is full to send. Half full or even one message batch may also be sent. The default is 16384(16k). If a message exceeds the size of the batch, it will not be written in. -
linger.ms
Specifies the time for the producer to wait for more messages to be added to the batch before sending the batch. The default is 0 50ms. 0 means that it will be sent when there is no batch. -
max.request.size
Control the maximum size of the request sent by the producer, which is 1M by default (this parameter is related to the message.max.bytes parameter of Kafka host, and can be set to be consistent) -
buffer.memory
Producer memory buffer size -
retries
The number of retries after message sending failure. The default is integer MAX_ VALUE. By default, the producer waits for 100ms between retries. You can use the parameter retry backoff. MS parameter to change this time interval. -
request.timeout.ms
The maximum time that the client will wait for the response of the request is 30 seconds by default -
max.block.ms
The maximum blocking time. If it exceeds, an exception will be thrown. The default is 60000ms -
compression.type
The type of compression that applies to compressed data. The default is no compression, none, gzip, snappy
Compression is the idea of using time for space. Specifically, it is to use CPU time for space or network I/0 transmission.
3, Serializer
The Kafka service receives byte arrays, so in the producer, it is necessary to specify the serializer of the key and value of the message. It mainly implements org apache. kafka. common. serialization. All classes of serializer interface can be used as serializers of Kafka.
Let's look at the source code of the Serializer interface:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) {
}
byte[] serialize(String var1, T var2);
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {
}
}
According to the source code, the return value of the final serialization is byte [].
Let's see what serialization implementation classes kafka's JAVA API provides us.
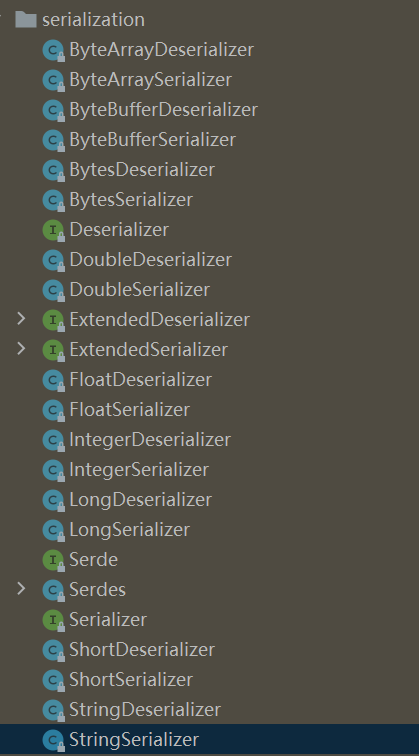
kafka provides many serializers, and each serializer corresponds to a deserializer. Let's look at some useful serializers.
- StringSerializer
As the name suggests, this is a serializer that serializes strings. Let's look at the serialize method in the StringSerializer source code:
public byte[] serialize(String topic, String data) {
try {
return data == null ? null : data.getBytes(this.encoding);
} catch (UnsupportedEncodingException var4) {
throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + this.encoding);
}
}
We can see that it calls the getBytes method of String and returns it as byte []. For simple strings, we need not say more. For objects, we can convert them into json strings and send them to kafka server with StringSerializer serializer.
- UUIDSerializer
Let's look at the serialize method of UUID serializer:
public byte[] serialize(String topic, UUID data) {
try {
return data == null ? null : data.toString().getBytes(this.encoding);
} catch (UnsupportedEncodingException var4) {
throw new SerializationException("Error when serializing UUID to byte[] due to unsupported encoding " + this.encoding);
}
}
As you can see, we can directly pass in the UUID object. This serializer is used when sending the unique id of business data.
- JsonSerializer
json serializer, which serializes json objects in jackson form. Look at its source code:
public byte[] serialize(String topic, JsonNode data) {
if (data == null) {
return null;
} else {
try {
return this.objectMapper.writeValueAsBytes(data);
} catch (Exception var4) {
throw new SerializationException("Error serializing JSON message", var4);
}
}
}
You can see that you need to pass in a JsonNode object, which is a class of jackson tool. jackson is a json processing tool, which we will not explain here.
In addition, kafka also provides byte,short,double,long and other basic types of serializers for us to use.
Custom serializer:
We can define our own Serializer and formulate serialization rules, as long as we implement the Serializer interface. At the same time, we also need to formulate a deserializer to deserialize according to the rules we have agreed in advance. In general, examples are as follows:
Let's first define a custom class and serialize it:
public class DemoUser {
private int id;
private String name;
public DemoUser(int id) {
this.id = id;
}
public DemoUser(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "DemoUser{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
Then we formulate the serializer of this class:
public class SelfSerializer implements Serializer<DemoUser> {
public void configure(Map<String, ?> configs, boolean isKey) {
//do nothing
}
/**
* The serializer finally returns the byte array. We can make our own rules, and then deserialize according to the set rules
* @param topic
* @param data
* @return
*/
public byte[] serialize(String topic, DemoUser data) {
try {
byte[] name;
int nameSize;
if(data==null){
return null;
}
if(data.getName()!=null){
name = data.getName().getBytes("UTF-8");
//Length of string
nameSize = data.getName().length();
}else{
name = new byte[0];
nameSize = 0;
}
/*id The length of the string is 4 bytes, and the length description of the string is 4 bytes,
The length of the string itself is nameSize bytes*/
ByteBuffer buffer = ByteBuffer.allocate(4+4+nameSize);
buffer.putInt(data.getId());//4
buffer.putInt(nameSize);//4
buffer.put(name);//nameSize
return buffer.array();
} catch (Exception e) {
throw new SerializationException("Error serialize DemoUser:"+e);
}
}
public void close() {
//do nothing
}
}
Then we need to define the deserializer:
public class SelfDeserializer implements Deserializer<DemoUser> {
public void configure(Map<String, ?> configs, boolean isKey) {
//do nothing
}
public DemoUser deserialize(String topic, byte[] data) {
try {
if(data==null){
return null;
}
if(data.length<8){
throw new SerializationException("Error data size.");
}
ByteBuffer buffer = ByteBuffer.wrap(data);
int id;
String name;
int nameSize;
id = buffer.getInt();
nameSize = buffer.getInt();
byte[] nameByte = new byte[nameSize];
buffer.get(nameByte);
name = new String(nameByte,"UTF-8");
return new DemoUser(id,name);
} catch (Exception e) {
throw new SerializationException("Error Deserializer DemoUser."+e);
}
}
public void close() {
//do nothing
}
}
In this way, we realize our custom serialization requirements for custom classes. However, the serializer provided by kafka itself can meet our needs in most cases. We try to avoid custom serializers. Because the serializer provided by kafka must be safer than our customized one.
4, Mapping relationship between message key and partition
In the above code, we can see that when creating the ProducerRecord object, there are three parameters:
record = new ProducerRecord<String,String>("Hello World", null,"lison");
The first parameter is the subject, the second parameter is the key value of the message, and the third parameter is the value of the message. As we mentioned earlier, kafka's theme is composed of one or more partitions. By default, kafka distributes messages evenly among partitions. It also applies the principle of least use. Send messages to any partition where there are few messages. When we set the key value for the message, that is, the second parameter, then the same key value message will be sent to the same partition, provided that the partition is fixed. Once the number of partitions is changed, it is impossible to ensure that all messages of the same key are in the same partition. Therefore, when creating a theme, we should plan the number of partitions. We will talk about the rebalancing of partitions in consumers. It is also related to the planning of partitions. In short, it is very important to plan the partitions in advance.
Custom partitioner:
kafka client provides Partitioner interface, which is the specification of Partitioner. As mentioned above, kafka sends messages to partitions evenly by default. This mechanism is actually implemented by the implementation class of Partitioner. Let's take a look at the source code of the default partition provided by kafka:
public class DefaultPartitioner implements Partitioner {
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap();
public DefaultPartitioner() {
}
public void configure(Map<String, ?> configs) {
}
//Partition rules are defined here
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//Lists all sections of the topic
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
//If the key value is empty, uniform hashing is performed
if (keyBytes == null) {
int nextValue = this.nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return ((PartitionInfo)availablePartitions.get(part)).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {//If the key value is not empty, the partition is calculated according to the fixed algorithm. Therefore, messages with the same key value enter the same partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = (AtomicInteger)this.topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = (AtomicInteger)this.topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
public void close() {
}
}
We can also customize the partition and send messages to different partitions according to our rules, such as sending the specified message to the specified partition. You can write a custom partition by yourself.
It should be noted that to use a custom partition, you need to set producerconfig in the producer's attribute PARTITIONER_ CLASS_ The value of the config attribute, that is, the "partitioner.class" attribute, is the package name and path of our custom partition.
5, Three sending methods of producers
- Send and forget
In the above entry code, we can see that the producer directly called the send method without receiving any return value, which is the send and forget mode. This mode doesn't matter if the message is sent out, whether the kafka service receives the message successfully or not. For unimportant data, we can use this method. Because kafka has a retry mechanism, it can retry sending data that is not sent successfully at one time. Therefore, the probability of message loss will be reduced. For businesses that can accept the loss of data, this mode can be used. - Synchronous transmission
The send method has a return value. When we ignore the return value of the send method, we use the send and forget mode. The return value of the send method is the Future object. Synchronous sending is the Future object that gets the return value, and the get method of Future is called in the back code to block the thread. The thread will not execute until the message is sent successfully. The code is as follows:
public class KafkaFutureProducer {
private static KafkaProducer<String,String> producer = null;
public static void main(String[] args) {
public static void main (String[]args){
Properties properties = new Properties();
properties.put("bootstrap.servers", "39.100.116.73:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<String, String>(properties);
try {
ProducerRecord<String, String> record;
try {
record = new ProducerRecord<String, String>(
"Hello World", null, "Synchronous transmission");
//Get the return value of the send method. The RecordMetadata object is the message returned to the producer by the kafka service after receiving the message
Future<RecordMetadata> future = producer.send(record);
System.out.println("Other businesses can be handled here");
//Block the thread until the kafka service returns RecordMetadata data
RecordMetadata recordMetadata = future.get();//Blocking in this position
if (null != recordMetadata) {
//The RecordMetadata object contains the offset, partition and other information of the message in the kafka service
System.out.println("offset:" + recordMetadata.offset() + "-" + "partition:" + recordMetadata.partition());
}
} catch (Exception e) {
//If the sending fails, an exception will be thrown and the catch statement will be entered. We will handle the exception according to the actual business
e.printStackTrace();
}
} finally {
producer.close();
}
}
}
}
- Asynchronous transmission
Send asynchronously. Just define the callback function in the send method. The second parameter is passed into the implementation interface org apache. kafka. clients. producer. The implementation class of the callback class acts as a callback.
The code is as follows:
public class KafkaAsynProducer {
//private static KafkaProducer<String,String> producer = null;
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers","127.0.0.1:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
/*Message instance to be sent*/
ProducerRecord<String,String> record;
try {
record = new ProducerRecord<String,String>(
"ceshi",null,"Asynchronous transmission");
//The second parameter is the Callback class, which implements its onCompletion method and enters the Callback function
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata,
Exception exception) {
if(null!=exception){
System.out.println("Exception thrown by return function");
exception.printStackTrace();
}
if(null!=metadata){
System.out.println("Callback function entered");
System.out.println("offset:"+metadata.offset()+"-"
+"partition:"+metadata.partition());
}
}
});
System.out.println("After callback");
}catch (Exception e){
System.out.println("catch Statement throws an exception");
e.printStackTrace();
}finally {
producer.close();
}
System.out.println("Method last");
}
Here, let's test the asynchronous effect of kafka. First, let's send the message successfully. Let's see the order of output statements:
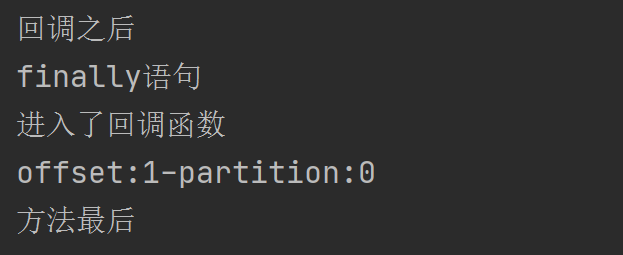
We can see that after calling the send method, the following "after callback" output statement is executed first, and then the finally statement is executed before the method in the callback function is executed. This shows that the message occurs asynchronously. Sending the message does not affect the execution process of the following code. Why is the "method last" the last output? Because it is a code block other than try. After finally executing, the following code will be executed.
Next, we modify the ip or port of kafka to an error, or turn off the kafka service. In short, we simulate the unsuccessful sending of messages. Let's look at the output order:

After running the code, you can see that the output statement of "after callback method" is not output at the first time, but is stuck waiting for the connection of kafka service. Finally, it is not connected and enters the callback function before leaving. This shows that kafka sends messages asynchronously when messages are sent normally. When the message is not sent normally, the thread will still get stuck. Therefore, kafka's asynchronous mode is not completely asynchronous. We will explain its principle in the later advanced article. You can refer to this article for reference:
https://blog.csdn.net/liuxiao723846/article/details/106106257
6, Producer in multithreaded environment
The producer of kafka is thread safe, that is, multiple threads share one producer, and there will be no data security problems. We won't explain too much here. The actual scenario of public producers under multithreading is still rare.
7, Producer error handling method
If an error occurs when the producer client sends a message to the kafka server, there are two situations. One is a retrieable error. After this error occurs, the producer will automatically retry without reporting an error. When the number of retries reaches the set number, if it still fails, an error will be thrown. Another case is to throw an error directly. If the message sending is too large and exceeds the threshold set by kafka server, an error will be reported directly.
8, Producer listener
Question: what is the difference between a producer listener and a callback for sending messages?
@Use of KafkaListener annotation
9, spring integration producer client
In our actual development, we will integrate kafka client into spring or springboot, and rarely use the independent API provided by kafka for development. Fkaka producers will integrate us below.
First, introduce jar package into pom.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.0.RELEASE</version>
</dependency>
Then, we configure kafka's connection information kafka Properties, similar to JDBC Properties file.
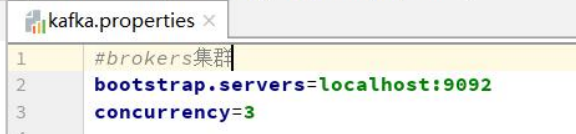
Then, we configure the integration information of kafka producer in the configuration file of spring:
<!-- to configure kafka.properties File path -->
<context:property-placeholder location="classpath*:config/kafka.properties" />
<!-- definition producer Parameters of,This is what we call the attributes of producers -->
<bean id="producerProperties" class="java.util.HashMap">
<constructor-arg>
<map>
<entry key="bootstrap.servers" value="${bootstrap.servers}" />
<entry key="key.serializer"
value="org.apache.kafka.common.serialization.StringSerializer" />
<entry key="value.serializer"
value="org.apache.kafka.common.serialization.StringSerializer" />
</map>
</constructor-arg>
</bean>
<!-- establish kafkatemplate Required producerfactory bean. Create with factory class kafkatemplate -->
<bean id="producerFactory"
class="org.springframework.kafka.core.DefaultKafkaProducerFactory">
<constructor-arg>
<ref bean="producerProperties"/>
</constructor-arg>
</bean>
<!-- Producer send listener bean -->
<bean id="sendListener" class="xxx.xxx.xxx" />
<!-- establish kafkatemplate bean,When using, you only need to inject this bean,
Ready to use template of send Message method -->
<bean id="kafkaTemplate" class="org.springframework.kafka.core.KafkaTemplate">
<constructor-arg ref="producerFactory" />
<constructor-arg name="autoFlush" value="true" />
<!-- Configure send listener bean -->
<property name="producerListener" ref="sendListener"></property>
</bean>
In the project, we can invoke the method provided by KafkaTemplate to realize the producer function. (kafkatemplate class is actually another set of methods encapsulated by spring by calling the JAVA API provided by Kafka)
Among them, we need to customize a listener and implement the ProducerListener interface to define the callback function after successful or failed message sending. The code is as follows:
public class SendListener implements ProducerListener {
public void onSuccess(String topic, Integer partition,
Object key, Object value, RecordMetadata recordMetadata) {
System.out.println("offset:"+recordMetadata.offset()+"-"
+"partition:"+recordMetadata.partition());
}
public void onError(String topic, Integer partition,
Object key, Object value, Exception exception) {
}
public boolean isInterestedInSuccess() {
return true;
}
}
10, springboot integrates producer client
First, introduce the jar package into the pom file:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.0.RELEASE</version>
</dependency>
Then, the configuration information can be written in the configuration class:
@Configuration
@EnableKafka
public class KafkaProducerConfig {
@Value("${kafka.producer.servers}")
private String servers;
@Value("${kafka.producer.retries}")
private int retries;
@Value("${kafka.producer.batch.size}")
private int batchSize;
@Value("${kafka.producer.linger}")
private int linger;
@Value("${kafka.producer.buffer.memory}")
private int bufferMemory;
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
KafkaTemplate kafkaTemplate
= new KafkaTemplate<String, String>(producerFactory()) ;
//kafkaTemplate.setProducerListener();
return kafkaTemplate;
}
}
In this way, the producer's function can be realized through the KafkaTemplate object.