Cluster is a kind of computer system, which is connected by a group of loosely integrated computer software and / or hardware to complete the computing work with high close cooperation. In a sense, they can be regarded as a computer. A single computer in a cluster system is usually called a node and is usually connected through a local area network, but there are other possible connection modes. Cluster computers are often used to improve the computing speed and / or reliability of a single computer. In general, the performance price ratio of cluster computer is much higher than that of single computer, such as workstation or supercomputer.
Characteristics of clusters
The cluster has the following two characteristics:
- Scalability: the performance of the cluster is not limited to a single service entity. New service entities can be dynamically added to the cluster to enhance the performance of the cluster.
- High availability: when one node of the cluster fails, the application running on this node will be automatically taken over at the other node. Eliminating a single point of failure is very important to enhance data availability, accessibility and reliability.
Cluster capabilities
- Load balancing: load balancing distributes the tasks evenly to the computing and network resources in the cluster environment to improve the data throughput.
- Error recovery: if a server in the cluster cannot be used due to failure or maintenance needs, resources and applications will be transferred to the available cluster nodes. The process in which the resources of one node cannot work and the resources of another available node can transparently take over and continue to complete the task is called error recovery.
Load balancing and error recovery require that resources executing the same task exist in each service entity, and for each resource of the same task, the information view required to execute the task must be the same.
1, Cluster usage scenario
Kafka is a distributed message system, which has the characteristics of high-level expansion and high throughput. In Kafka cluster, there is no concept of "central master node". All nodes in the cluster are equal.
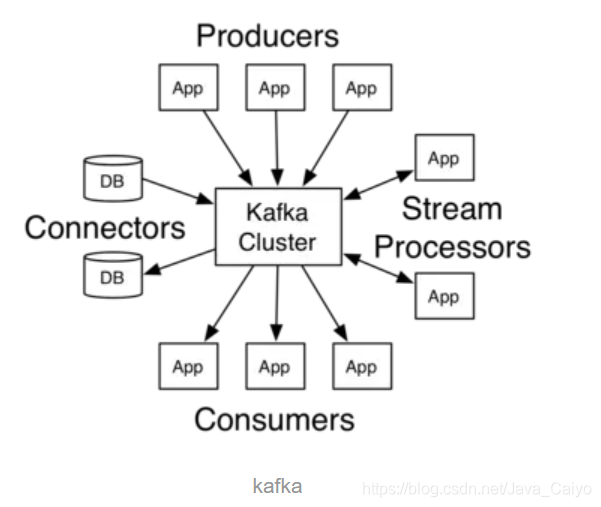
Broker
Each Broker is a Kafka service instance. Multiple brokers form a Kafka cluster. The messages published by producers will be saved in the Broker, and consumers will pull messages from the Broker for consumption.
Kafka cluster architecture diagram
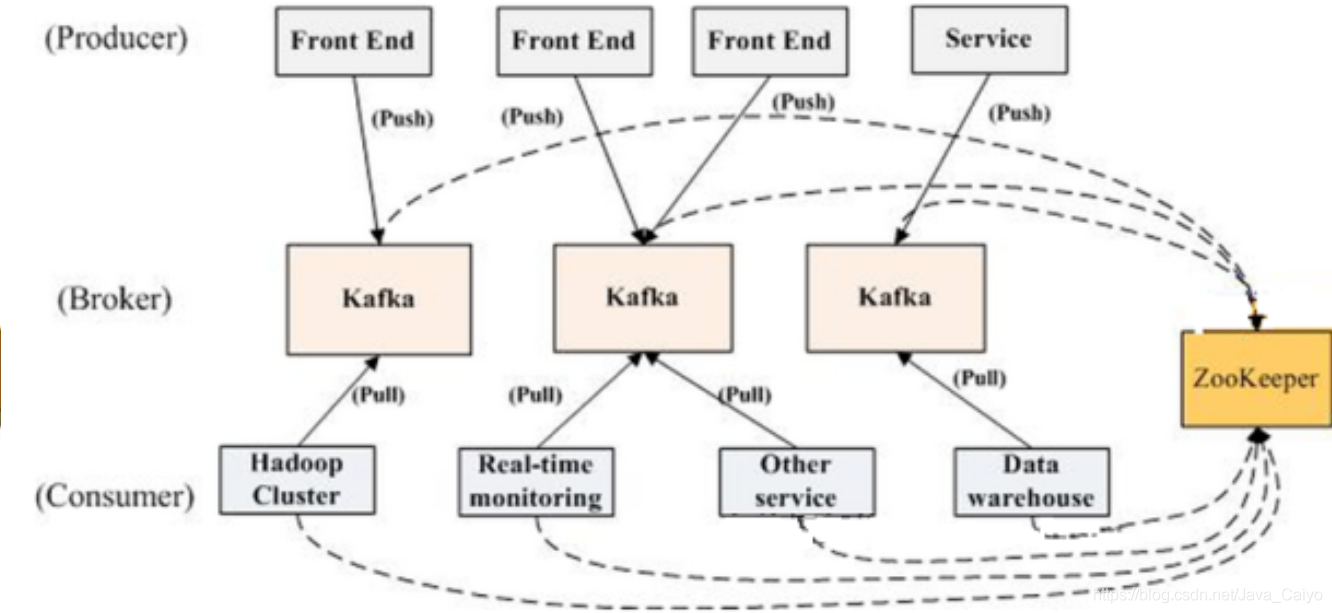
As can be seen from the figure, Kafka strongly relies on ZooKeeper to manage its own cluster through ZooKeeper, such as Broker list management, relationship between Partition and Broker, relationship between Partition and Consumer, load balancing between Producer and Consumer, consumption progress Offset record, Consumer registration, etc. Therefore, in order to achieve high availability, ZooKeeper must also be a cluster.
2, Cluster construction
1.ZooKeeper cluster construction
scene
Real clusters need to be deployed on different servers, but when we test, we can't afford to start more than a dozen virtual machines at the same time. So here we build a pseudo cluster, that is, build all services on one virtual machine and distinguish them by ports.
We need to build a Zookeeper cluster (pseudo cluster) with three nodes.
Install JDK
Cluster directory
Create the Zookeeper cluster directory and copy the unzipped Zookeeper to the following three directories
itcast@Server-node:/mnt/d/zookeeper-cluster$ ll total 0 drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 ./ drwxrwxrwx 1 dayuan dayuan 512 Aug 19 18:42 ../ drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-1/ drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-2/ drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-3/ itcast@Server-node:/mnt/d/zookeeper-cluster$
ClientPort settings
Configure the dataDir (zoo.cfg) clientPort of each Zookeeper as 2181, 2182 and 2183 respectively
# the port at which the clients will connect clientPort=2181
myid configuration
Create a myid file in the data directory of each zookeeper, with the contents of 0, 1 and 2 respectively. This file records the ID of each server
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$ cat temp/zookeeper/data/myid 0 dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$
zoo.cfg
In every zookeeper's zoo CFG configure the client access port and cluster server IP list.
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$ cat conf/zoo.cfg # The number of milliseconds of each tick # Heartbeat time zk of the server tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. #dataDir=/tmp/zookeeper dataDir=temp/zookeeper/data dataLogDir=temp/zookeeper/log # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.0=127.0.0.1:2888:3888 server.1=127.0.0.1:2889:3889 server.2=127.0.0.1:2890:3890 dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$
Explanation: server Server ID = server IP address: communication port between servers: voting port between servers
Start cluster
Starting the cluster is to start each instance separately. After starting, we can query the running status of each instance
itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-1$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /mnt/d/zookeeper-cluster/zookeeper-1/bin/../conf/zoo.cfg Mode: leader itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-2$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /mnt/d/zookeeper-cluster/zookeeper-2/bin/../conf/zoo.cfg Mode: follower itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-3$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /mnt/d/zookeeper-cluster/zookeeper-3/bin/../conf/zoo.cfg Mode: follower
2.Kafka cluster construction
Cluster directory
itcast@Server-node:/mnt/d/kafka-cluster$ ll total 0 drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:15 ./ drwxrwxrwx 1 dayuan dayuan 512 Aug 19 18:42 ../ drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:39 kafka-1/ drwxrwxrwx 1 dayuan dayuan 512 Jul 24 14:02 kafka-2/ drwxrwxrwx 1 dayuan dayuan 512 Jul 24 14:02 kafka-3/ drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:15 kafka-4/ itcast@Server-node:/mnt/d/kafka-cluster$
server.properties
# The broker number must be unique in the cluster broker.id=1 # host address host.name=127.0.0.1 # port port=9092 # Message log storage address log.dirs=/tmp/kafka/log/cluster/log3 # ZooKeeper address, multiple, separated by zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
Start cluster
Enter each Kafka instance through cmd and enter the command to start
............................... [2019-07-24 06:18:19,793] INFO [Transaction Marker Channel Manager 2]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager) [2019-07-24 06:18:19,793] INFO [TransactionCoordinator id=2] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator) [2019-07-24 06:18:19,846] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread) [2019-07-24 06:18:19,869] INFO [SocketServer brokerId=2] Started data-plane processors for 1 acceptors (kafka.network.SocketServer) [2019-07-24 06:18:19,879] INFO Kafka version: 2.2.1 (org.apache.kafka.common.utils.AppInfoParser) [2019-07-24 06:18:19,879] INFO Kafka commitId: 55783d3133a5a49a (org.apache.kafka.common.utils.AppInfoParser) [2019-07-24 06:18:19,883] INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
3, Multi cluster synchronization
MirrorMaker exists to solve Kafka's Cross cluster synchronization and create a mirror cluster; The following figure shows how it works. The tool consumes the source cluster messages and then pushes the data back to the target cluster.
1. Configuration
create mirror
Using MirrorMaker to create an image is relatively simple. After setting up the target Kafka cluster, you only need to start the mirror maker program. Among them, one or more consumer profiles and one producer profile are required, while whitelist and blacklist are optional. Specify the Zookeeper of the source Kafka cluster in the configuration of consumer and the Zookeeper (or broker.list) of the target cluster in the configuration of producer.
kafka-run-class.sh kafka.tools.MirrorMaker – consumer.config sourceCluster1Consumer.config – consumer.config sourceCluster2Consumer.config –num.streams 2 – producer.config targetClusterProducer.config –whitelist=".*"
consumer profile:
# format: host1:port1,host2:port2 ... bootstrap.servers=localhost:9092 # consumer group id group.id=test-consumer-group # What to do when there is no initial offset in Kafka or if the current # offset does not exist any more on the server: latest, earliest, none #auto.offset.reset=
producer profile:
# format: host1:port1,host2:port2 ... bootstrap.servers=localhost:9092 # specify the compression codec for all data generated: none, gzip, snappy, lz4, zstd compression.type=none
2. Tuning
How to ensure that the synchronization data is not lost? You need to confirm when sending it to the target cluster first: request required. When acks = 1 is sent, the blocking mode is adopted, otherwise the buffer is full and the data is discarded: queue enqueue. timeout. ms=-1
summary
This chapter mainly explains the Kafka cluster, introduces the cluster usage scenarios, the construction of Zookeeper and Kafka multi borrowing point clusters, and the synchronous operation of multi clusters.
**Reference: comprehensive analysis of advanced core knowledge in Java
Free access to 18 resume templates for Java Engineers: private letter [data] free access
last
Even job hopping is a learning process. Only a comprehensive review can make us better enrich ourselves, arm ourselves and make our interview no longer rough! Today, I'll share with you a comprehensive collection of Java interview questions on Github, which helped me win the Offer of a large factory and raise my monthly salary to 30K!
Data collection method: Blue portal
I also share it with you for the first time. I hope I can help you go to the big factory you like! Prepare for gold, silver and four!
There are 20 topics of knowledge points in total, which are:
Dubbo interview topic

JVM interview topics

Java Concurrent interview topic

Kafka interview topic

MongDB interview topic

MyBatis interview topic

MySQL interview topic

Netty interview topic

RabbitMQ interview topic

Redis interview topic

Spring Cloud interview topic

SpringBoot interview topic

zookeeper interview topic

Summary of common interview algorithm questions

Basic topics of computer network

Special topics on Design Patterns

Transferring... (img-n1xHQaHG-1623570079390)]
zookeeper interview topic
[external chain picture transferring... (img-Q3ns0a7W-1623570079391)]
Summary of common interview algorithm questions
[external chain picture transferring... (img-uBP2fQ6M-1623570079391)]
Basic topics of computer network
[external chain picture transferring... (img-0Z8nf7xD-1623570079391)]
Special topics on Design Patterns
[external chain picture transferring... (IMG gwrppvvf-1623570079392)]