This article is about Learning Guide for Big Data Specialists from Zero (Full Upgrade) Kafka: Partial supplement.
1 Producer API
1.1 Message Sending Process
Kafka's roducer sends messages asynchronously, involving two threads, the main thread and the Ender thread, and a thread-sharing variable, RecordAccumulator.
The main thread sends messages to the RecordAccumulator, and the Sender thread continuously pulls and cancels messages from the RecordAccumulator to the Kafka broker.

Related parameters:
Batch.size: sender will not send data until the data has accumulated to batch.size.
linger.ms: If the data is too late to reach batch.size, sender waits for linger.time to send the data.
1.2 Asynchronous Send API
1) Import Dependency
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
</dependencies>2) Add log4j profile
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- Type Name Console,Name is a required attribute -->
<Appender type="Console" name="STDOUT">
<!-- Layout as PatternLayout The way,
The output style is[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- Additivity is false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig Set up -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>3) Write code
Classes to be used:
KafkaProducer: You need to create a producer object to send data
ProducerConfig: Gets the required set of configuration parameters
ProducerRecord: Each data is encapsulated as a ProducerRecord object
1. API without callback function
package com.atguigu.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
//kafka cluster, broker-list
props.put("bootstrap.servers", "hadoop102:9092");
props.put("acks", "all");
//retry count
props.put("retries", 1);
//Batch size
props.put("batch.size", 16384);
//waiting time
props.put("linger.ms", 1);
//RecordAccumulator Buffer Size
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
}2. API with callback function
The callback function is called when producer receives an ack and is called asynchronously. The method has two parameters, RecordMetadata and Exception. If Exception is null, the message is sent successfully. If Exception is not null, the message is sent unsuccessfully.
Note: Message sending failures are retried automatically and do not require us to retry manually in the callback function.
package com.atguigu.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");//kafka cluster, broker-list
props.put("acks", "all");
props.put("retries", 1);//retry count
props.put("batch.size", 16384);//Batch size
props.put("linger.ms", 1);//waiting time
props.put("buffer.memory", 33554432);//RecordAccumulator Buffer Size
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i)), new Callback() {
//Callback function, which is called asynchronously when Producer receives an ack
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("success->" + metadata.offset());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
}1.3 Partitioner
1) DefaultPartitioner
2) Custom Partitioner
public class MyPartitioner implements Partitioner {
/**
* Calculate which partition a message is sent to
* @param topic theme
* @param key Message key
* @param keyBytes The serialized byte array of the message key
* @param value Message value
* @param valueBytes The serialized byte array of the message's value
* @param cluster
* @return
*
* Requirements: Take the atguigu theme for example, two partitions
* The value of the message contains the Entry 0 partition of "atguigu"
* Other messages enter partition 1
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String msgValue = value.toString();
int partition ;
if(msgValue.contains("atguigu")){
partition = 0;
}else{
partition = 1;
}
return partition;
}
/**
* End Work
*/
@Override
public void close() {
}
/**
* Read Configured
* @param configs
*/
@Override
public void configure(Map<String, ?> configs) {
}
}
1.4 Synchronous Send API
Synchronous sending means that after a message is sent, the current thread is blocked until ack is returned.
Because the send method returns a Future object, we can also achieve the effect of synchronous sending according to the characteristics of the Future object, which only needs to be sent by calling the get of the Future object.
package com.atguigu.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");//kafka cluster, broker-list
props.put("acks", "all");
props.put("retries", 1);//retry count
props.put("batch.size", 16384);//Batch size
props.put("linger.ms", 1);//waiting time
props.put("buffer.memory", 33554432);//RecordAccumulator Buffer Size
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), Integer.toString(i))).get();
}
producer.close();
}
}2 Consumer API
Consumer consumer data is easily guaranteed to be reliable because it is persistent in Kafka, so there is no need to worry about data loss.
Because consumer may have power outage and other malfunctions in the process of consumption, it needs to continue to consume from the location before the malfunction after consumer recovers, so consumer needs to record which offset he consumed in real time so that he can continue to consume after the malfunction recovers.
Therefore, the maintenance of offset is a must for Consumer consumption data.
2.1 Autocommit offset
1) Import Dependency
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.11.0.0</version> </dependency>
2) Write code
Classes to be used:
KafkaConsumer: You need to create a consumer object to consume data
ConsumerConfig: Gets the required set of configuration parameters
ConsuemrRecord: Each data is encapsulated as a ConsumerRecord object
To enable us to focus on our business logic, Kafka provides the ability to autocommit offsets. Autocommit offset parameters:
enable.auto.commit: Turn on automatic commit offset
auto.commit.interval.ms: Time interval for automatic offset submission
The following is the code for automatically submitting offset s:
package com.atguigu.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("first"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}2.2 Reset Offset
auto.offset.rest = earliest | latest | none |
2.3 Manual submission of offset
Although automatic offset submission is very convenient, due to its time-based submission, it is difficult for developers to grasp the timing of offset submission. Therefore, Kafka also provides an API for manual offset submission.
There are two ways to manually submit offsets: commitSync (synchronous commit) and commitAsync (asynchronous commit). The same thing is that both submit the highest number of offsets for this poll. The difference is that commitSync blocks the current thread until the commit succeeds and automatically fails to retry.(Submission failures also occur due to uncontrollable factors); however, commitAsync does not have a failed retry mechanism and therefore may fail to submit.
1) Submit offset synchronously
The synchronous submission offset is more reliable because it has a failed retry mechanism. Below is an example of synchronous submission offset.
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class CustomComsumer {
public static void main(String[] args) {
Properties props = new Properties();
//Kafka Cluster
props.put("bootstrap.servers", "hadoop102:9092");
//Consumer group, as long as the group.id is the same, belongs to the same consumer group
props.put("group.id", "test");
props.put("enable.auto.commit", "false");//Turn off automatic submission offset
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("first"));//Consumer Subscription Subject
while (true) {
//Consumer pull data
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
//Synchronous commit, current thread will block until offset commit succeeds
consumer.commitSync();
}
}
}2) Submit offset asynchronously
Although synchronous submission offsets are more reliable, they can block the current thread until the submission succeeds. Throughput can therefore be significantly affected. In more cases, asynchronous submission offsets are preferred.
The following is an example of asynchronous submission of offset:
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
//Kafka Cluster
props.put("bootstrap.servers", "hadoop102:9092");
//Consumer group, as long as the group.id is the same, belongs to the same consumer group
props.put("group.id", "test");
//Turn off automatic submission offset
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("first"));//Consumer Subscription Subject
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);//Consumer pull data
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
//Asynchronous commit
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for" + offsets);
}
}
});
}
}
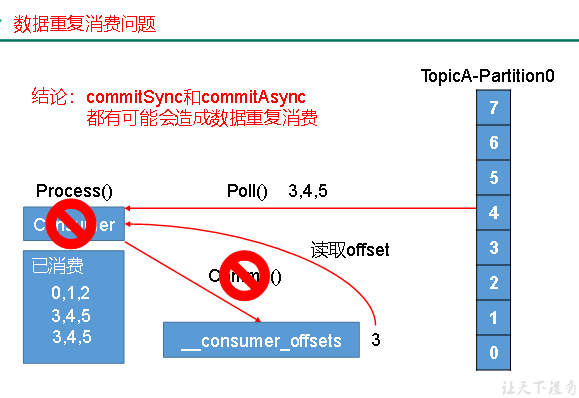
}3) Data Leakage Consumption and Repeated Consumption Analysis
Both synchronous and asynchronous submissions of offsets may result in data leakage or duplicate consumption. Submitting offsets before consumption may result in data leakage; Submitting offsets after consumption may result in data leakage
Duplicate consumption.
2.3 Custom Storage offset
Before Kafka version 0.9, offsets were stored in zookeeper, version 0.9 and later. By default, offsets were stored in a built-in topic in Kafka. In addition, Kafka has the option of customizing storage offsets.
Maintenance of offset s is cumbersome, as consumer Rebalace needs to be considered.
When a new consumer joins a consumer group, an existing consumer launches a consumer group, or the partition of a subscribed topic changes, it triggers a redistribution of the partition, a process called Rebalance.
After a consumer's Rebalance occurs, the partition of each consumer's consumption changes. Therefore, the consumer should first obtain the partition to which he or she has been reassigned and locate the offset that each partition recently submitted to continue to consume.
To implement a custom storage offset, you need to use ConsumerRebalanceListener, which is an example code in which the method of submitting and getting offsets needs to be implemented by the offset storage system you choose.
View Code