Big data related knowledge points
1. Introduction to Kafka
Kafka is a high-throughput distributed publish and subscribe message system. It can process all action flow data in consumer scale websites. It has the ability of high performance, persistence, multi copy backup and horizontal expansion
- Distributed system, easy to expand outward;
- At the same time, it provides high throughput for publishing and subscription;
- Support multiple subscribers, which can automatically balance consumers in case of failure;
- Persistent messages to disk, which can be used for mass consumption;
[the external chain image transfer fails, and the source station may have anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-hbsmojf-1645556442) (C: \ users \ Luffy \ desktop \ Luffy \ note \ knowledge points of big data application. assets\image-20210829191209280.png)]
Producer: producer is the producer, the producer of message and the entrance of message.
kafka cluster:
Broker: a broker is an instance of kafka. There are one or more instances of kafka on each server. Let's think that each broker corresponds to a server. The brokers in each kafka cluster have a unique number, such as broker-0 and broker-1 in the figure
Topic: the topic of a message, which can be understood as the classification of messages. kafka's data is saved in topic. Multiple topics can be created on each broker.
Partition: partition of topic. Each topic can have multiple partitions. The function of partition is to do load and improve kafka throughput. The data of the same topic in different partitions are not repeated. The representation of partition is folder by folder!
Replication: each partition has multiple replicas, which are used as spare tires. When the leader fails, a spare tire will be selected to become the leader. In kafka, the default maximum number of replicas is 10, and the number of replicas cannot be greater than the number of brokers. Followers and leaders are definitely on different machines, and the same machine can only store one replica (including itself) for the same partition.
Message: the body of each message sent.
Consumer: the consumer, that is, the consumer of the message, is the export of the message.
Consumer Group: we can form multiple consumer groups into one Consumer Group. In kafka's design, the data of the same partition can only be consumed by one consumer in the Consumer Group. Consumers in the same Consumer Group can consume data in different partitions of the same topic, which is also to improve kafka throughput!
Zookeeper: kafka cluster relies on zookeeper to save the meta information of the cluster to ensure the availability of the system
2. Based on Ubuntu 18 04 installation and deployment of Kafka
2.1 installing Java
1. Install openjdk-8-jdk
sudo apt-get update sudo apt-get install openjdk-8-jdk
2. Check the java version
java -version
[the external chain picture transfer fails, and the source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-dhecyufk-1645556443) (C: \ users \ Luffy \ desktop \ Luffy \ note \ knowledge points of big data application. assets\image-20210829193511128.png)]
2.2 installation of Zookeeper
1. From https://zookeeper.apache.org/releases.html Download the latest stable version of ZooKeeper, currently using version 3.6.3

2. Unzip apache-zookeeper-3.6.3
tar -xzvf apache-zookeeper-3.6.3.tar.gz

3. To run zookeeper, you need to configure the sample to zoo_sample.cfg renamed zoo CFG, open to see some default configurations
cd apache-zookeeper-3.6.3/conf/ mv zoo_sample.cfg zoo.cfg cat zoo.cfg
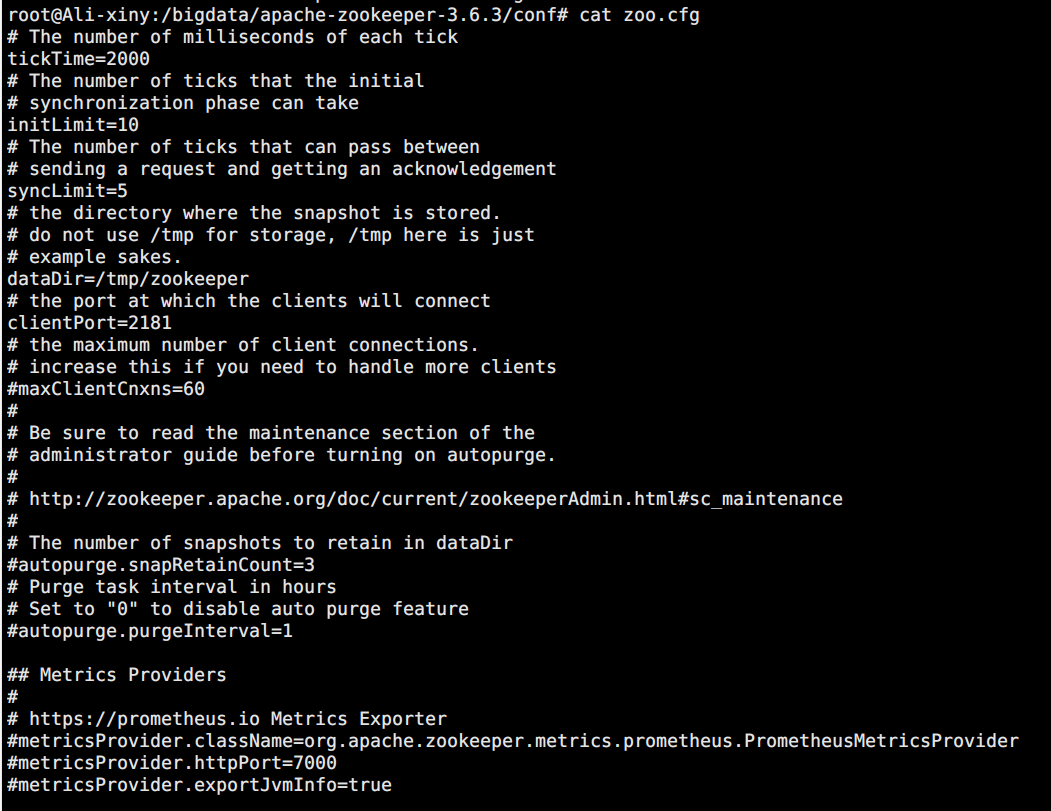
- tickTime :
The unit of duration is milliseconds, which is the basic time measurement unit used by zk. For example, 1 * tickTime is the heartbeat time between the client and zk server, and 2 * tickTime is the timeout time of the client session.
The default value of tickTime is 2000 milliseconds. A lower value of tickTime can find timeout problems faster, but it will also lead to higher network traffic (heartbeat messages) and higher CPU utilization (session tracking processing). - clientPort :
The TCP port that zk service process listens to. By default, the server will listen to port 2181. - dataDir :
There is no default configuration, which must be configured. It is used to configure the directory where snapshot files are stored. If dataLogDir is not configured, the transaction log will also be stored in this directory. - server:zookeeper service synchronization configuration
4. Modify zoo CFG configuration
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/bigdata/zookeeper/zookeeperData dataDir=/bigdata/zookeeper/zookeeperLog # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 ## Metrics Providers # # https://prometheus.io Metrics Exporter #metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider #metricsProvider.httpPort=7000 #metricsProvider.exportJvmInfo=true server.1=localhost:2888:3888
a key:
dataDir=/bigdata/zookeeper/zookeeperData
dataDir=/bigdata/zookeeper/zookeeperLog
server.1=localhost:2888:3888
2.3 installation of Kafka
1. Download address: https://kafka.apache.org/downloads , you can download directly using wget under ubuntu
wget https://artfiles.org/apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3.tar.gz
2. Unzip apache-zookeeper-3.6.3 tar. gz
tar -zxvf apache-zookeeper-3.6.3.tar.gz
3. Create a log directory under your kafka directory
cd kafka/ mkdir logs-1
4. Enter the extracted kafka directory and modify the configuration file of kafka server
vim config/server.properties
# Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=1 ############################# Socket Server Settings ############################# # The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 listeners=PLAINTEXT://localhost:9092 # Hostname and port the broker will advertise to producers and consumers. If not set, # it uses the value for "listeners" if configured. Otherwise, it will use the value # returned from java.net.InetAddress.getCanonicalHostName(). #advertised.listeners=PLAINTEXT://localhost:9092 # Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details #listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL # The number of threads that the server uses for receiving requests from the network and sending responses to the network num.network.threads=3 # The number of threads that the server uses for processing requests, which may include disk I/O num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=102400 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=102400 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 ############################# Log Basics ############################# # A comma separated list of directories under which to store log files log.dirs=/bigdata/kafka/logs-1 # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=1
a key:
listeners=PLAINTEXT://localhost:9092
log.dirs=/bigdata/kafka/logs-1
5. Start zookeeper
./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
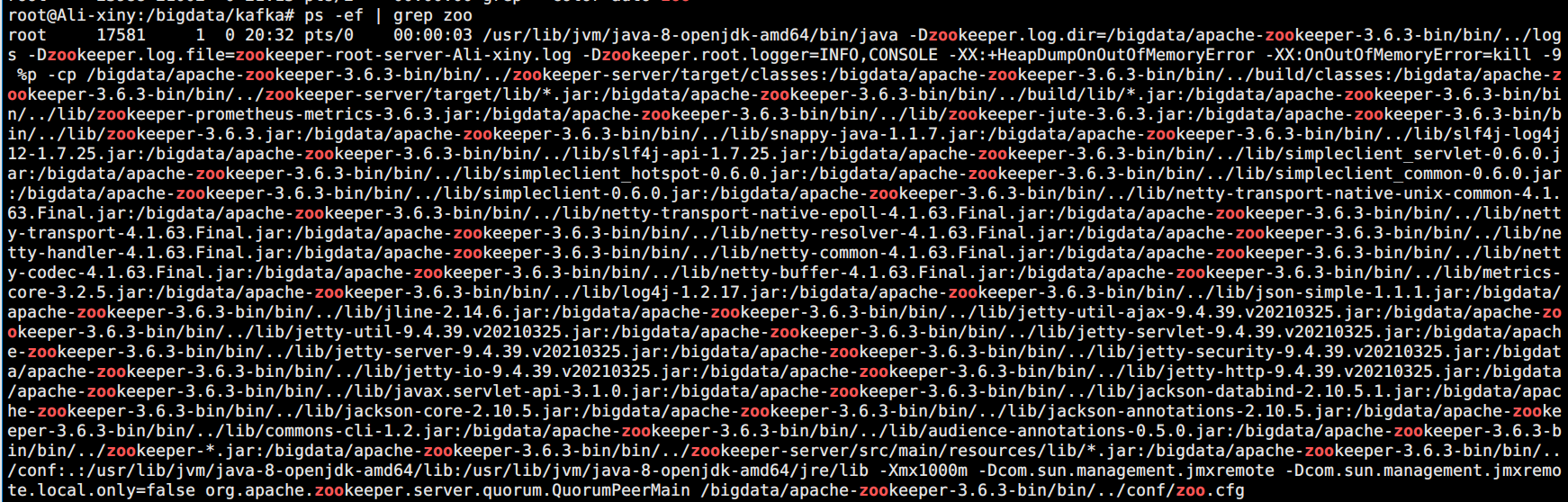
Check whether the startup is successful
ps -ef | grep zoo
6. Start Kafka service and use Kafka server start SH, start Kafka service
./bin/kafka-server-start.sh config/server.properties
7. Create topic and use Kafka topics SH create topic test of single partition and single copy
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
View topic list
./bin/kafka-topics.sh --list --zookeeper localhost:2181

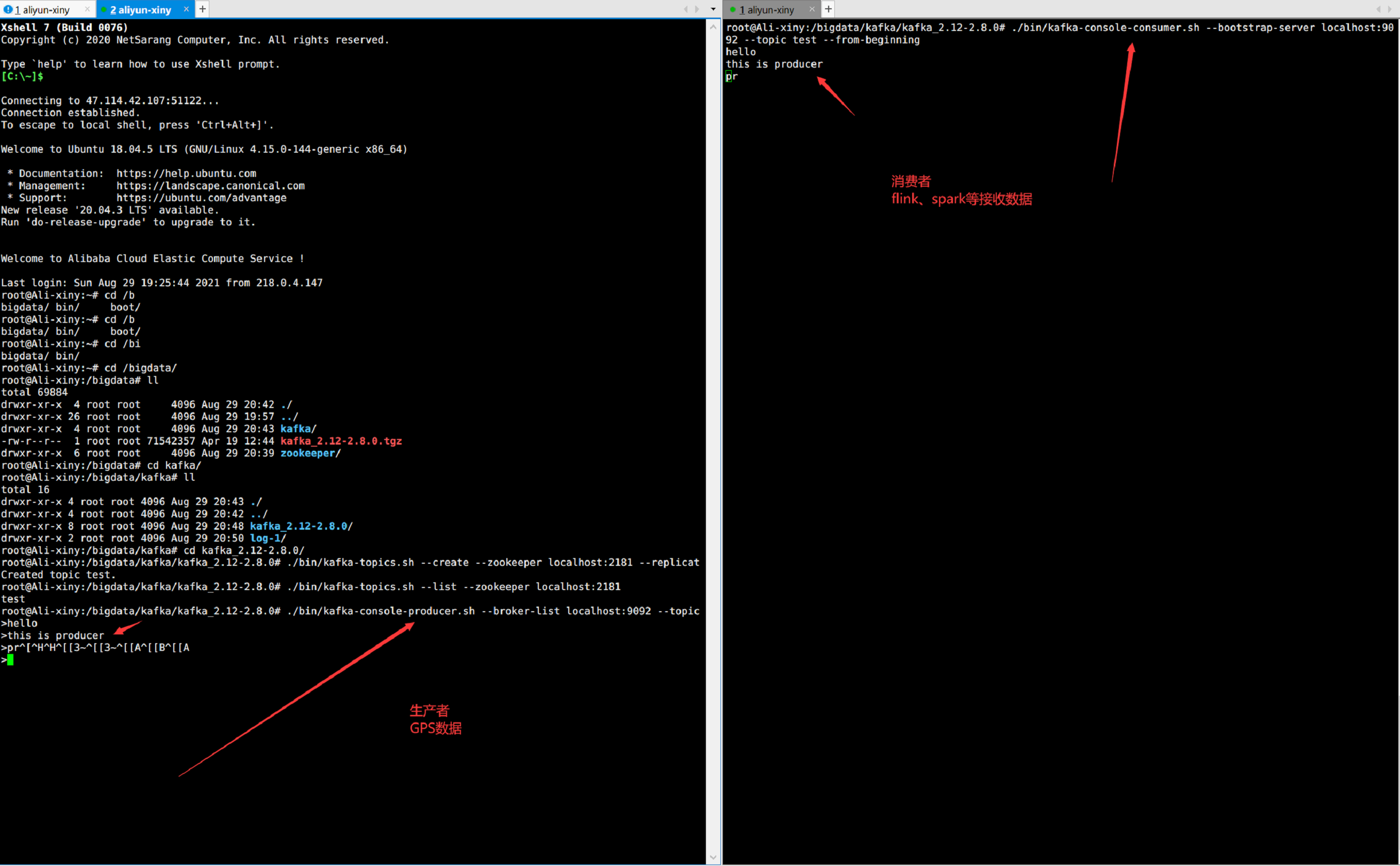
8. Create a message generator and generate a message
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
9. Create message consumers and consume messages
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
10. Test the input content in the production message window and print it in the consumption window
11. View topic message
./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test

3. Introduction to the architecture of GPS data acquisition system based on Netty to Kafka
3.1 GPS data acquisition
The GPS device sends data to the acquisition terminal every certain time. The acquisition terminal receives and analyzes the data through netty and sends it to kafka. The service terminal consumes kafka data in batch through topic, calculates and analyzes the data and distributes it to the database.
3.1.1 Netty's Reactor thread model
At present, high-performance network communication services are mostly based on the combination of epoll mechanism and multithreading model. Netty can adjust its thread model during operation according to user-defined program startup parameters. etty officially recommends using the master-slave Reactor multithreading model. Its main feature is that it has multiple thread pools. The main thread pool is to process new client connections. After processing the new connections, bind the new Socket to a thread in the slave thread pool; The slave thread pool will be responsible for the subsequent reading and writing, encoding and decoding, and business processing of this Socket. The purpose of designing the master-slave Reactor multithreading model is to separate the monitoring port service from the data processing function, so as to improve the ability of data processing. In practical applications, netty supports adding multiple slave thread pools. Different services can be allocated to different slave thread pools according to business characteristics, or several services with similar characteristics can be allocated to the same slave thread pool.
3.1.2 Kafka streaming message processing system
Kafka's commit log queue is the concrete implementation of Kafka's message queue concept. Producers send streaming messages to the commit log queue, and other consumers can process the latest information of these logs in milliseconds. Each data consumer has its own pointer in the commit log and moves independently, so that consumers can process the messages in the queue reliably and sequentially in a distributed environment. The commit log can be shared by multiple producers and consumers, and covers multiple machines in the cluster, providing fault tolerance guarantee for the machines in the cluster. As a modern distributed system, Kafka can also expand and shrink horizontally. In addition, Kafka's message broker can support the persistence of TB level messages.
3.2 system architecture design
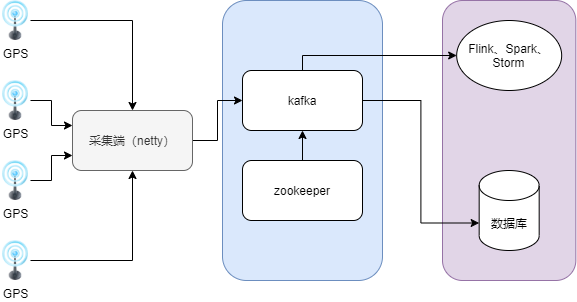
The acquisition terminal is composed of GPS equipment and regional acquisition server. The message collection end exposes the IP address and port for the collection terminal to connect. When there is a new TCP connection or a new message is sent, the network communication processing program of the message collection end will be triggered. Messages that need further processing will be pushed to the Kafka cluster asynchronously by the message collector. Then, different Kafka consumer processes process the messages pushed to the Kafka cluster according to different business requirements. These messages are either persisted to the database or other real-time calculations. In addition, Zookeeper is used to monitor the operation status of Kafka cluster and coordinate the management of Kafka cluster; At the same time, Zookeeper can also reserve service software to coordinate and manage the service level expansion business of the collection end.
4. Front end display of transportation big data platform