
1. General
Reprint: Kafka source code analysis: Group coordination and management mechanism
In Kafka's design, consumers generally have the concept of a group (of course, there are consumers who do not belong to any group). Organizing multiple consumers into a group can improve the consumption and processing capacity of messages, and ensure the order of message consumption without repeating or missing consumption. The consumer under a group name includes one leader role and multiple follower roles. Although these two roles are equivalent in terms of consumption messages, the leader role is also responsible for managing the whole group relative to the follower role. When a new consumer joins the group, or a consumer quits the current group for some reason, or the topic partition subscribed to changes, the partition needs to be reassigned to the consumer under the group name. After the server determines the partition allocation strategy, the specific implementation of partition allocation is entrusted to the leader consumer, After the partition allocation is completed, the allocation result is fed back to the server.
The GroupCoordinator class has been mentioned many times when analyzing the consumer operation mechanism. In this article, let's analyze the role and implementation of the GroupCoordinator component. The main functions of GroupCoordinator component include partition allocation of consumers belonging to the same group, maintenance of internal offset topic, and management of consumers and group information to which consumers belong. Each broker node in the cluster will create and start a GroupCoordinator instance when it is started, and each instance will manage a subset of all consumer groups in the cluster.
2. Definition and startup of groupcoordinator component
The fields of the GroupCoordinator class are defined as follows:
class GroupCoordinator(
val brokerId: Int, // ID of the broker node to which it belongs
val groupConfig: GroupConfig, // The group configuration object records the minimum and maximum duration of session expiration in the group, that is, the legal interval of timeout
val offsetConfig: OffsetConfig, // Record configuration items related to OffsetMetadata
val groupManager: GroupMetadataManager, // Responsible for managing group metadata and corresponding offset information
val heartbeatPurgatory: DelayedOperationPurgatory[DelayedHeartbeat], // Purgatory for managing DelayedHeartbeat delayed tasks
val joinPurgatory: DelayedOperationPurgatory[DelayedJoin], // Purgatory for managing DelayedJoin deferred tasks
time: Time) extends Logging {
/** Identifies whether the current GroupCoordinator instance is started */
private val isActive = new AtomicBoolean(false)
// ... Omit method definition
}
The GroupMetadataManager class is mainly used to manage the metadata information and offset related information of the consumer group. The field definitions are as follows:
class GroupMetadataManager(val brokerId: Int, // broker node ID
val interBrokerProtocolVersion: ApiVersion, // kafka version information
val config: OffsetConfig, // Record configuration items related to OffsetMetadata
replicaManager: ReplicaManager, // Manage the partition information of offset topic on the broker node
zkUtils: ZkUtils,
time: Time) extends Logging with KafkaMetricsGroup {
/** Message compression type */
private val compressionType: CompressionType = CompressionType.forId(config.offsetsTopicCompressionCodec.codec)
/** Cache the GroupMetadata object corresponding to each group on the server */
private val groupMetadataCache = new Pool[String, GroupMetadata]
/** The ID collection of the offset topic partition being loaded */
private val loadingPartitions: mutable.Set[Int] = mutable.Set()
/** ID collection of offset topic partition that has been loaded */
private val ownedPartitions: mutable.Set[Int] = mutable.Set()
/** Identity GroupCoordinator is shutting down */
private val shuttingDown = new AtomicBoolean(false)
/** Record the number of partitions for offset topic */
private val groupMetadataTopicPartitionCount = getOffsetsTopicPartitionCount
/** Used to schedule tasks such as delete expired consumer offsets and group coordinator migration */
private val scheduler = new KafkaScheduler(threads = 1, threadNamePrefix = "group-metadata-manager-")
// ... Omit method definition
}
When the Kafka service is started, it will create a GroupCoordinator instance for each broker node and call the GroupCoordinator#startup method to start running. During startup, the GroupCoordinator mainly calls the GroupMetadataManager#enableMetadataExpiration method to start the delete expired group metadata scheduled task:
def startup(enableMetadataExpiration: Boolean = true) {
info("Starting up.")
if (enableMetadataExpiration) groupManager.enableMetadataExpiration()
isActive.set(true)
info("Startup complete.")
}
def enableMetadataExpiration() {
// Start scheduled task scheduler
scheduler.startup()
// Start the delete expired group metadata scheduled task
scheduler.schedule(name = "delete-expired-group-metadata",
fun = cleanupGroupMetadata,
period = config.offsetsRetentionCheckIntervalMs,
unit = TimeUnit.MILLISECONDS)
}
The main function of the scheduled task delete expired group metadata is to remove the offset metadata corresponding to the expired topic partition from the metadata information of the group, and record these metadata in the offset topic in the form of messages. The specific execution process is as follows:
- Calculate and obtain the offset metadata information corresponding to the expired topic partition according to the current timestamp;
- Switch the group in Empty status and all offset metadata recorded under the name have expired to Dead status;
- If the group has expired, the corresponding metadata information is removed locally from the GroupCoordinator, and encapsulated into a message together with the offset metadata information obtained in step 1 and recorded in the offset topic.
The specific logic is implemented by the GroupMetadataManager#cleanupGroupMetadata method, as follows:
private[coordinator] def cleanupGroupMetadata(): Unit = {
this.cleanupGroupMetadata(None)
}
def cleanupGroupMetadata(deletedTopicPartitions: Option[Seq[TopicPartition]]) {
val startMs = time.milliseconds()
var offsetsRemoved = 0
// Traverse and process the metadata information corresponding to each group
groupMetadataCache.foreach { case (groupId, group) =>
val (removedOffsets, groupIsDead, generation) = group synchronized {
// Calculate the offset metadata information corresponding to the topic partition to be removed
val removedOffsets = deletedTopicPartitions match {
// Removes the specified topic partition collection from the group metadata information
case Some(topicPartitions) => group.removeOffsets(topicPartitions)
// Remove the topic partition collection with expired offset metadata and no offset to be submitted
case None => group.removeExpiredOffsets(startMs)
}
// If the current status of the group is Empty and all offset s of the topic partition under the name have expired, switch the status of the group to Dead
if (group.is(Empty) && !group.hasOffsets) {
info(s"Group $groupId transitioned to Dead in generation ${group.generationId}")
group.transitionTo(Dead)
}
(removedOffsets, group.is(Dead), group.generationId)
}
// Get the partition number corresponding to group in offset topic
val offsetsPartition = partitionFor(groupId)
val appendPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition)
getMagic(offsetsPartition) match {
// The corresponding group is managed by the current GroupCoordinator
case Some(magicValue) =>
val timestampType = TimestampType.CREATE_TIME
val timestamp = time.milliseconds()
// Gets the partition object of the current group in offset topic
val partitionOpt = replicaManager.getPartition(appendPartition)
partitionOpt.foreach { partition =>
// Traverse and process the offset metadata information corresponding to each topic partition to be removed, and encapsulate it into message data
val tombstones = removedOffsets.map { case (topicPartition, offsetAndMetadata) =>
trace(s"Removing expired/deleted offset and metadata for $groupId, $topicPartition: $offsetAndMetadata")
val commitKey = GroupMetadataManager.offsetCommitKey(groupId, topicPartition)
Record.create(magicValue, timestampType, timestamp, commitKey, null)
}.toBuffer
trace(s"Marked ${removedOffsets.size} offsets in $appendPartition for deletion.")
// If the current group has expired, remove the corresponding metadata information locally and encapsulate the group information into a message,
// If generation is 0, it means that the current group only uses kafka to store offset information
if (groupIsDead && groupMetadataCache.remove(groupId, group) && generation > 0) {
tombstones += Record.create(magicValue, timestampType, timestamp, GroupMetadataManager.groupMetadataKey(group.groupId), null)
trace(s"Group $groupId removed from the metadata cache and marked for deletion in $appendPartition.")
}
if (tombstones.nonEmpty) {
try {
// Append a message to offset topic without ack. If it fails, the periodic task will retry later
partition.appendRecordsToLeader(MemoryRecords.withRecords(timestampType, compressionType, tombstones: _*))
offsetsRemoved += removedOffsets.size
trace(s"Successfully appended ${tombstones.size} tombstones to $appendPartition for expired/deleted offsets and/or metadata for group $groupId")
} catch {
case t: Throwable =>
error(s"Failed to append ${tombstones.size} tombstones to $appendPartition for expired/deleted offsets and/or metadata for group $groupId.", t)
}
}
}
case None =>
info(s"BrokerId $brokerId is no longer a coordinator for the group $groupId. Proceeding cleanup for other alive groups")
}
}
info(s"Removed $offsetsRemoved expired offsets in ${time.milliseconds() - startMs} milliseconds.")
}
3.Group status definition and conversion
The GroupState attribute defines the state of the group and is maintained by the GroupCoordinator. Around the characteristics of GroupState, Kafka implements five sample objects to describe the five states of a group:
- PreparingRebalance: indicates that the group is preparing to perform partition reallocation.
- AwaitingSync: indicates that the group is waiting for the partition allocation result of the leader consumer. The new version has been renamed CompletingRebalance.
- Stable: indicates that the group is in normal operation.
- Dead: indicates that there is no consumer under the group name, and the corresponding metadata has been (or is being) deleted.
- Empty: indicates that there is no consumer under the group name, and is waiting for all offset metadata recorded to expire.
The transition between Group states and the reasons for the transition are shown in the following figure and table:
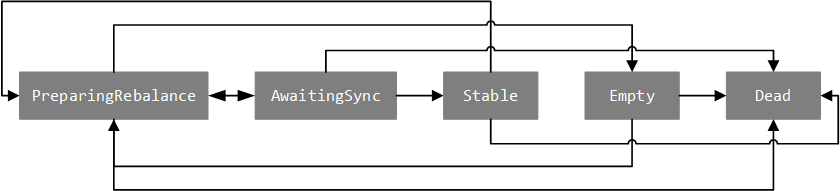
| current state | Target status | Conversion reason |
|---|---|---|
| PreparingRebalance | AwaitingSync | All consumers under the name of group have applied to join, or it timed out waiting for consumers to apply to join. |
| PreparingRebalance | Empty | All consumers under the group name have left. |
| PreparingRebalance | Dead | The metadata information corresponding to group is removed. |
| AwaitingSync | Stable | group receives partition allocation results from the leader consumer. |
| AwaitingSync | PreparingRebalance | 1. A consumer applies to join or quit; 2. The metadata information of the consumers under the name has been updated; 3. The name of the consumer's heartbeat timed out. |
| AwaitingSync | Dead | The metadata information corresponding to group is removed. |
| Stable | PreparingRebalance | 1. A consumer applies to join or quit; 2. The name of the consumer's heartbeat timed out. |
| Stable | Dead | The metadata information corresponding to group is removed. |
| Empty | PreparingRebalance | Consumers apply to join. |
| Empty | Dead | 1. All offset metadata information under the group name has expired; 2. The metadata information corresponding to the group is removed. |
| Dead | nothing |
4. Failover mechanism
In Kafka version 0.8.2.2, offset topic is introduced to store consumption offset location data to solve the performance pressure and instability faced by ZK storage in the previous version, which is maintained by the GroupCoordinator component. Offset topic is not different from the ordinary topic in Kafka in nature except in purpose. Kafka sets 50 partitions for offset topic by default, and each partition is allocated with 3 copies. When a broker node goes down, if the leader replica of an offset topic partition is running on the node, considering the service availability, it is necessary to select a qualified follower replica on other available broker nodes as the new leader replica, At the same time, the GroupCoordinator instance on the broker node continues to maintain the corresponding offset topic partition. Because it involves the change of the GroupCoordinator instance, when the new GroupCoordinator instance takes over and maintains these offset topic partitions, it is necessary to restore the metadata information of the corresponding group on these GroupCoordinator instances (an offset topic partition records a batch of group metadata and offset consumption data).
When analyzing Kafka's partition replica mechanism, the previous article introduced the processing of leaderandisrequest requests. ReplicaManager defined the ReplicaManager#becomeLeaderOrFollower method to perform role switching on the replica of the specified topic partition. This method receives a callback function of type (iteratable [partition], iteratable [partition]) = > unit, which is used to process the partition object collection that completes the switching of leader role and follower role respectively. The specific definition of the callback function is located in KafkaApis#handleLeaderAndIsrRequest method, and the implementation is as follows:
// Complete the migration of GroupCoordinator
def onLeadershipChange(updatedLeaders: Iterable[Partition], updatedFollowers: Iterable[Partition]) {
updatedLeaders.foreach { partition =>
// Only the offset topic is processed. When the broker node maintains the leader copy of the offset topic partition, the callback is executed
if (partition.topic == Topic.GroupMetadataTopicName) coordinator.handleGroupImmigration(partition.partitionId)
}
updatedFollowers.foreach { partition =>
// Only the offset topic is processed. When the broker node maintains the follower copy of the offset topic partition, the callback is executed
if (partition.topic == Topic.GroupMetadataTopicName) coordinator.handleGroupEmigration(partition.partitionId)
}
}
It can be seen from the above implementation that the callback function only processes the partition corresponding to offset topic. When the GroupCoordinator instance starts to maintain the leader copy of a partition of offset topic, it will trigger the execution of the GroupCoordinator #handlegroupmigration method, When the GroupCoordinator instance starts to maintain the follower copy of an offset topic partition, it will trigger the execution of the GroupCoordinator #handlegroupemission method. The implementation of these two methods is analyzed below.
The GroupCoordinator#handleGroupImmigration method is implemented as follows:
def handleGroupImmigration(offsetTopicPartitionId: Int) {
groupManager.loadGroupsForPartition(offsetTopicPartitionId, onGroupLoaded)
}
private def onGroupLoaded(group: GroupMetadata) {
group synchronized {
info(s"Loading group metadata for ${group.groupId} with generation ${group.generationId}")
assert(group.is(Stable) || group.is(Empty))
// Traverse and update the heartbeat information of all consumers under the current group name
group.allMemberMetadata.foreach(completeAndScheduleNextHeartbeatExpiration(group, _))
}
}
The execution logic of the groupcoordinator #completeandschedulenexthheartbeatexpiration method will be analyzed in the next section. Here we mainly look at the implementation of the GroupMetadataManager#loadGroupsForPartition method, which updates the metadata of the corresponding group based on the offset topic and initializes the offset information corresponding to each topic partition:
def loadGroupsForPartition(offsetsPartition: Int, onGroupLoaded: GroupMetadata => Unit) {
// Build the topic partition object corresponding to offset topic
val topicPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition)
def doLoadGroupsAndOffsets() {
info(s"Loading offsets and group metadata from $topicPartition")
inLock(partitionLock) {
// Check whether the current offset topic partition is loading. If it is already loading, return
if (loadingPartitions.contains(offsetsPartition)) {
info(s"Offset load from $topicPartition already in progress.")
return
} else {
loadingPartitions.add(offsetsPartition)
}
}
try {
// Update the metadata information of the corresponding group based on offset topic loading, and initialize the offset information corresponding to each topic partition
this.loadGroupsAndOffsets(topicPartition, onGroupLoaded)
} catch {
case t: Throwable => error(s"Error loading offsets from $topicPartition", t)
} finally {
inLock(partitionLock) {
ownedPartitions.add(offsetsPartition)
loadingPartitions.remove(offsetsPartition)
}
}
}
// Asynchronous scheduling execution
scheduler.schedule(topicPartition.toString, doLoadGroupsAndOffsets)
}
The specific loading and updating process is implemented using the asynchronous scheduling strategy. The implementation is located in the GroupMetadataManager#loadGroupsAndOffsets method, which will read all message data under the corresponding topic partition and process them respectively according to the message type:
private[coordinator] def loadGroupsAndOffsets(topicPartition: TopicPartition, onGroupLoaded: GroupMetadata => Unit) {
// Gets the HW value of the specified topic partition
def highWaterMark: Long = replicaManager.getHighWatermark(topicPartition).getOrElse(-1L)
val startMs = time.milliseconds()
// Get and process the Log object corresponding to the topic partition
replicaManager.getLog(topicPartition) match {
case None =>
// non-existent
warn(s"Attempted to load offsets and group metadata from $topicPartition, but found no log")
case Some(log) =>
var currOffset = log.logStartOffset
val buffer = ByteBuffer.allocate(config.loadBufferSize)
// Record the mapping relationship between the topic partition and the corresponding offset information
val loadedOffsets = mutable.Map[GroupTopicPartition, OffsetAndMetadata]()
val removedOffsets = mutable.Set[GroupTopicPartition]()
// Record the mapping relationship between group and corresponding group metadata information
val loadedGroups = mutable.Map[String, GroupMetadata]()
val removedGroups = mutable.Set[String]()
// The Log data is read from the first LogSegment in the Log object to the HW position,
// Load offset information and group metadata information
while (currOffset < highWaterMark && !shuttingDown.get()) {
buffer.clear()
// Read log data to memory
val fileRecords = log
.read(currOffset, config.loadBufferSize, maxOffset = None, minOneMessage = true)
.records.asInstanceOf[FileRecords]
val bufferRead = fileRecords.readInto(buffer, 0)
// Traversal processing message collection (deep iteration)
MemoryRecords.readableRecords(bufferRead).deepEntries.asScala.foreach { entry =>
val record = entry.record
require(record.hasKey, "Group metadata/offset entry key should not be null")
// The type of the current message is determined by the key of the message
GroupMetadataManager.readMessageKey(record.key) match {
// If it is a message recording offset
case offsetKey: OffsetKey =>
val key = offsetKey.key
if (record.hasNullValue) {
// If the flag is deleted, the corresponding offset information is removed
loadedOffsets.remove(key)
removedOffsets.add(key)
} else {
// Non delete tag, parse and update the offset information corresponding to the key
val value = GroupMetadataManager.readOffsetMessageValue(record.value)
loadedOffsets.put(key, value)
removedOffsets.remove(key)
}
// If it is a message recording group metadata
case groupMetadataKey: GroupMetadataKey =>
val groupId = groupMetadataKey.key
val groupMetadata = GroupMetadataManager.readGroupMessageValue(groupId, record.value)
if (groupMetadata != null) {
// The non deletion flag records the loaded group metadata information
trace(s"Loaded group metadata for group $groupId with generation ${groupMetadata.generationId}")
removedGroups.remove(groupId)
loadedGroups.put(groupId, groupMetadata)
} else {
// Delete tag
loadedGroups.remove(groupId)
removedGroups.add(groupId)
}
// Unknown message key type
case unknownKey =>
throw new IllegalStateException(s"Unexpected message key $unknownKey while loading offsets and group metadata")
}
currOffset = entry.nextOffset
}
}
// The topic partition with offset information in offset topic is distinguished by whether group metadata information is included in offset topic
val (groupOffsets, emptyGroupOffsets) = loadedOffsets
.groupBy(_._1.group)
.mapValues(_.map { case (groupTopicPartition, offset) => (groupTopicPartition.topicPartition, offset) })
.partition { case (group, _) => loadedGroups.contains(group) }
// Traverse the group with group metadata information in offset topic
loadedGroups.values.foreach { group =>
val offsets = groupOffsets.getOrElse(group.groupId, Map.empty[TopicPartition, OffsetAndMetadata])
// Update the metadata information corresponding to the group, mainly to update the offset information corresponding to each topic partition under the name
loadGroup(group, offsets)
onGroupLoaded(group)
}
// Traversal processing: if there is no group metadata information in offset topic, but there is offset information, create a new one
emptyGroupOffsets.foreach { case (groupId, offsets) =>
val group = new GroupMetadata(groupId)
// Update the metadata information corresponding to the group, mainly to update the offset information corresponding to each topic partition under the name
loadGroup(group, offsets)
onGroupLoaded(group)
}
// Detect the group metadata information to be deleted. If the corresponding group has a local record and there is offset information in offset topic,
// Such groups generally only rely on kafka to store offset information, but do not store the corresponding group metadata information
removedGroups.foreach { groupId =>
if (groupMetadataCache.contains(groupId) && !emptyGroupOffsets.contains(groupId))
throw new IllegalStateException(s"Unexpected unload of active group $groupId while loading partition $topicPartition")
}
}
}
The offset topic mainly records the metadata of the group and the consumption location information of the corresponding offset. The above method will analyze these two types of data respectively and recover the metadata information of the corresponding group recorded locally by the GroupCoordinator. If the offset topic contains the metadata information of the corresponding group, it will be reused directly during recovery. Otherwise, an empty GroupMetadata object will be created (such groups generally only use Kafka to store offset location data), and the offset value of each topic partition under the group name will be updated by using the GroupMetadataManager#loadGroup method, At the same time, record the group metadata into the local cache of the GroupCoordinator:
private def loadGroup(group: GroupMetadata, offsets: Map[TopicPartition, OffsetAndMetadata]): Unit = {
// Traverse and process the offset information of each topic partition, and be compatible with the expiration time of updating the old version
val loadedOffsets = offsets.mapValues { offsetAndMetadata =>
// Corresponding to the offset metadata of the old version, set the expiration timestamp as the commit time plus the system default retention time (24 hours by default)
if (offsetAndMetadata.expireTimestamp == OffsetCommitRequest.DEFAULT_TIMESTAMP)
offsetAndMetadata.copy(expireTimestamp = offsetAndMetadata.commitTimestamp + config.offsetsRetentionMs)
else
offsetAndMetadata
}
trace(s"Initialized offsets $loadedOffsets for group ${group.groupId}")
// Update the offset information of each topic partition under the group name
group.initializeOffsets(loadedOffsets)
// Update metadata information corresponding to group
val currentGroup = this.addGroup(group)
if (group != currentGroup)
debug(s"Attempt to load group ${group.groupId} from log with generation ${group.generationId} failed because there is already a cached group with generation ${currentGroup.generationId}")
}
Let's continue to look at the execution logic of the GroupCoordinator instance to maintain the follower copy of an offset topic partition. The implementation is located in the GroupCoordinator #handlegroupemission method:
def handleGroupEmigration(offsetTopicPartitionId: Int) {
groupManager.removeGroupsForPartition(offsetTopicPartitionId, onGroupUnloaded)
}
private def onGroupUnloaded(group: GroupMetadata) {
group synchronized {
info(s"Unloading group metadata for ${group.groupId} with generation ${group.generationId}")
val previousState = group.currentState
// Switch the current group to Dead state
group.transitionTo(Dead)
// Process separately according to the pre status
previousState match {
case Empty | Dead =>
case PreparingRebalance =>
// Traverse and respond to the JoinGroupRequest request of all consumers, and return NOT_COORDINATOR_FOR_GROUP error code
for (member <- group.allMemberMetadata) {
if (member.awaitingJoinCallback != null) {
member.awaitingJoinCallback(joinError(member.memberId, Errors.NOT_COORDINATOR_FOR_GROUP.code))
member.awaitingJoinCallback = null
}
}
// Attempt to perform a DelayedJoin deferred task
joinPurgatory.checkAndComplete(GroupKey(group.groupId))
case Stable | AwaitingSync =>
// Traverse and respond to the JoinGroupRequest request of all consumers, and return NOT_COORDINATOR_FOR_GROUP error code
for (member <- group.allMemberMetadata) {
if (member.awaitingSyncCallback != null) {
member.awaitingSyncCallback(Array.empty[Byte], Errors.NOT_COORDINATOR_FOR_GROUP.code)
member.awaitingSyncCallback = null
}
// An attempt was made to perform a DelayHeartbeat delay task
heartbeatPurgatory.checkAndComplete(MemberKey(member.groupId, member.memberId))
}
}
}
}
When the GroupCoordinator no longer manages the corresponding group, the group status of the local record will be switched to Dead, and the JoinGroupRequest request from the consumer under the group name will respond to NOT_COORDINATOR_FOR_GROUP error. In addition, the previously managed offset topic partition object and the corresponding group metadata information will be removed locally. The implementation is as follows:
def removeGroupsForPartition(offsetsPartition: Int, onGroupUnloaded: GroupMetadata => Unit) {
// Build the topic partition object corresponding to offset topic
val topicPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition)
// Asynchronous scheduling execution
scheduler.schedule(topicPartition.toString, removeGroupsAndOffsets)
def removeGroupsAndOffsets() {
var numOffsetsRemoved = 0
var numGroupsRemoved = 0
inLock(partitionLock) {
// Remove the specified partition from the offset topic partition collection that has been loaded, indicating that the current GroupCoordinator instance no longer manages the corresponding group
ownedPartitions.remove(offsetsPartition)
// Traverse the metadata information corresponding to the group to remove the local cache
for (group <- groupMetadataCache.values) {
if (partitionFor(group.groupId) == offsetsPartition) {
onGroupUnloaded(group)
groupMetadataCache.remove(group.groupId, group)
numGroupsRemoved += 1
numOffsetsRemoved += group.numOffsets
}
}
}
}
}
5. Heartbeat activation mechanism
Consumers rely on the heartbeat mechanism to report activity to the GroupCoordinator and send a HeartbeatRequest request request to the corresponding GroupCoordinator instance. The GroupCoordinator instance also depends on the consumer's heartbeat to judge the consumer's online and offline. KafkaApis defines the KafkaApis#handleHeartbeatRequest method to process the HeartbeatRequest request. The specific processing logic is delegated to the GroupCoordinator#handleHeartbeat method. This method will first verify that the target GroupCoordinator instance is legal and can process the current request, and then process the heartbeat request according to the status of the target group. Only when the target group is in PreparingRebalance or Stable status, and the current consumer does belong to the group, can it respond to the request normally. For groups in other status, it simply returns the corresponding error code.
The logic for normally responding to the HeartbeatRequest request is located in the groupcoordinator #completeandschedulenexthheartbeatexpiration method. The implementation is as follows:
private def completeAndScheduleNextHeartbeatExpiration(group: GroupMetadata, member: MemberMetadata) {
// Update the heartbeat time of the corresponding consumer
member.latestHeartbeat = time.milliseconds()
// Get consumers concerned about DelayedHeartbeat delayed tasks
val memberKey = MemberKey(member.groupId, member.memberId)
// Attempt to complete the previously added DelayedHeartbeat delay task
heartbeatPurgatory.checkAndComplete(memberKey)
// Calculate the next heartbeat timeout
val newHeartbeatDeadline = member.latestHeartbeat + member.sessionTimeoutMs
// Create a new DelayedHeartbeat delay task and add it to purgatory for management
val delayedHeartbeat = new DelayedHeartbeat(this, group, member, newHeartbeatDeadline, member.sessionTimeoutMs)
heartbeatPurgatory.tryCompleteElseWatch(delayedHeartbeat, Seq(memberKey))
}
The normal response to the heartbeat request will update the latest heartbeat time of the current consumer, try to complete the DelayedHeartbeat delay task that pays attention to the consumer, and create a new DelayedHeartbeat delay task. The delay time is the next heartbeat timeout. In the whole GroupCoordinator implementation, the above methods are called in many places, which also means that the heartbeat mechanism does not only depend on the HeartbeatRequest request request. In fact, as long as the consumer's request to the GroupCoordinator can carry heartbeat information, such as JoinGroupRequest, SyncGroupRequest, OffsetCommitRequest, etc.
Let's take a look at the implementation of DelayedHeartbeat#tryComplete method and DelayedHeartbeat#onExpiration method for delayed tasks. These two methods call GroupCoordinator#tryCompleteHeartbeat and GroupCoordinator#onExpireHeartbeat methods respectively, while DelayedHeartbeat#onComplete method is an empty implementation, In other words, the real execution logic of the delayed heartbeat task is to delete the delayed task from purgatory, which is also in line with the purpose of the heartbeat mechanism. There is no need to deal with the normal heartbeat. Only when the consumer's heartbeat exceeds the time limit, it is necessary to deal with the relevant exceptions.
The GroupCoordinator#tryCompleteHeartbeat method will detect the current consumer's status. If one of the following three conditions is met, the DelayedHeartbeat delay task will be enforced, indicating that the corresponding consumer's heartbeat is normal:
- Consumer is waiting for a JoinGroupResponse or SyncGroupResponse response.
- The time between the consumer's last heartbeat and the expiration of the delayed task is within the consumer's session timeout.
- The consumer has left the previous group.
The GroupCoordinator#onExpireHeartbeat method will detect whether the current consumer is offline. If so, it will be executed according to the current status of the group:
- If the target group is Dead/Empty, do nothing;
- If the target group is running normally (Stable), or is waiting for the partition allocation result (AwaitingSync) of the leader consumer, the previous partition allocation result may be invalid due to the offline of the current consumer, so the partition needs to be reassigned;
- If the target group is in the PreparingRebalance state, there is no need to request to reallocate the partition again. However, because the current consumer is offline, the DelayedJoin delay task of the target group may meet the execution conditions, so try to execute.
The specific logic implementation is in the GroupCoordinator#onMemberFailure method. The implementation is as follows:
private def onMemberFailure(group: GroupMetadata, member: MemberMetadata) {
trace("Member %s in group %s has failed".format(member.memberId, group.groupId))
// Delete the corresponding consumer from GroupMetadata
group.remove(member.memberId)
group.currentState match {
// The corresponding group is invalid and does nothing
case Dead | Empty =>
// The previous partition allocation result may have expired. Switch the status of GroupMetadata to PreparingRebalance and prepare to re allocate partitions
case Stable | AwaitingSync => this.maybePrepareRebalance(group)
// When a consumer goes offline, it may meet the execution conditions of DelayedJoin that pays attention to the group and try to execute
case PreparingRebalance => joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
The execution logic of the GroupCoordinator#maybePrepareRebalance method will be analyzed when the partition redistribution mechanism is introduced in the next section.
6. Subregional redistribution mechanism
In the previous analysis of the consumer operating mechanism, we analyzed the execution process of the partition redistribution mechanism from the perspective of consumers. In this section, we continue to introduce the processing details of the cluster's requests from consumers involved in the partition redistribution operation from the perspective of the server, mainly including groupcoordinator request JoinGroupResult and SyncGroupRequest.
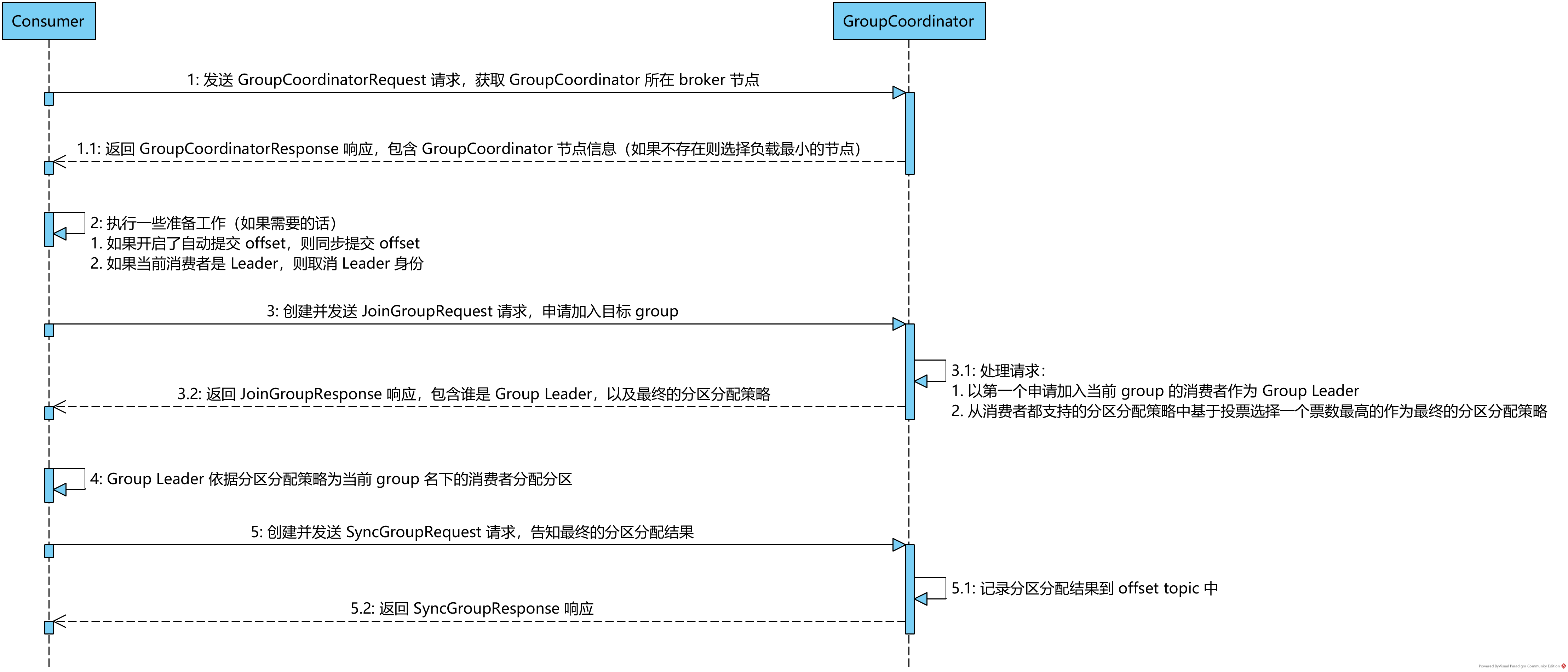
The above sequence diagram depicts the interaction process between the client and the server during partition redistribution.
6.1 groupcoordinator request processing
Before the consumer interacts with the GroupCoordinator, it is necessary to send a GroupCoordinator request to the broker node with less load to obtain the location information of the broker node where the GroupCoordinator instance managing the current group is located. KafkaApis provides the KafkaApis#handleGroupCoordinatorRequest method to process the GroupCoordinatorRequest request. The implementation of the method is as follows:
def handleGroupCoordinatorRequest(request: RequestChannel.Request) {
val groupCoordinatorRequest = request.body.asInstanceOf[GroupCoordinatorRequest]
// Permission verification
if (!authorize(request.session, Describe, new Resource(Group, groupCoordinatorRequest.groupId))) {
val responseBody = new GroupCoordinatorResponse(Errors.GROUP_AUTHORIZATION_FAILED.code, Node.noNode)
requestChannel.sendResponse(new RequestChannel.Response(request, responseBody))
} else {
// Get the partition ID of the offset topic corresponding to the group
val partition = coordinator.partitionFor(groupCoordinatorRequest.groupId)
// Get information about offset topic from MetadataCache. If it is not created, create it
val offsetsTopicMetadata = this.getOrCreateGroupMetadataTopic(request.listenerName)
val responseBody = if (offsetsTopicMetadata.error != Errors.NONE) {
// Failed to create offset topic information
new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode)
} else {
// Gets the node where the leader copy of the offset topic partition corresponding to the current group is located
val coordinatorEndpoint = offsetsTopicMetadata.partitionMetadata().asScala
.find(_.partition == partition)
.map(_.leader())
// Create a GroupCoordinatorResponse object and return the node information where the leader copy is located to the client
coordinatorEndpoint match {
case Some(endpoint) if !endpoint.isEmpty => new GroupCoordinatorResponse(Errors.NONE.code, endpoint)
case _ => new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode)
}
}
trace("Sending consumer metadata %s for correlation id %d to client %s.".format(responseBody, request.header.correlationId, request.header.clientId))
// Add the response object to the channel and wait for sending
requestChannel.sendResponse(new RequestChannel.Response(request, responseBody))
}
}
Kafka will find the broker node where the leader copy of the corresponding offset topic partition is located according to the ID of the requested group, encapsulate the node information into a GroupCoordinatorResponse response and send it to the consumer. Next, the consumer will establish a connection to the corresponding broker node and send a JoinGroupRequest to join the corresponding group.
6.2 JoinGroupRequest processing
For the JoinGroupRequest request from the consumer to join the specified group, the GroupCoordinator instance will determine the final partition allocation policy for the consumers in the group and elect a new group leader consumer. KafkaApis defines the KafkaApis#handleJoinGroupRequest method to process JoinGroupRequest. However, this method simply parses the request object, performs permission verification, and defines a callback function to send JoinGroupResponse response to the client. The specific process of processing the request is implemented by the GroupCoordinator#handleJoinGroup method:
def handleJoinGroup(groupId: String,
memberId: String,
clientId: String,
clientHost: String,
rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback) {
if (!isActive.get) {
// The GroupCoordinator instance was not started
responseCallback(joinError(memberId, Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code))
} else if (!validGroupId(groupId)) {
// Illegal groupId
responseCallback(joinError(memberId, Errors.INVALID_GROUP_ID.code))
} else if (!isCoordinatorForGroup(groupId)) {
// The current GroupCoordinator instance is not responsible for managing the current group
responseCallback(joinError(memberId, Errors.NOT_COORDINATOR_FOR_GROUP.code))
} else if (isCoordinatorLoadingInProgress(groupId)) {
// The current GroupCoordinator instance is loading the offset topic partition information corresponding to the group
responseCallback(joinError(memberId, Errors.GROUP_LOAD_IN_PROGRESS.code))
} else if (sessionTimeoutMs < groupConfig.groupMinSessionTimeoutMs || sessionTimeoutMs > groupConfig.groupMaxSessionTimeoutMs) {
// Session duration timeout to ensure that the consumer is active
responseCallback(joinError(memberId, Errors.INVALID_SESSION_TIMEOUT.code))
} else {
// Get and process the metadata information corresponding to the group
groupManager.getGroup(groupId) match {
// The corresponding group does not exist
case None =>
if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// If the consumer ID is specified but the corresponding group does not exist, the request is rejected
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
} else {
// If the group does not exist and the consumer ID is unknown, create a GroupMetadata object, add the consumer to the corresponding group, and perform partition rebalancing at the same time
val group = groupManager.addGroup(new GroupMetadata(groupId))
this.doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
// If the corresponding group exists, add the consumer to the corresponding group and perform partition rebalancing
case Some(group) =>
this.doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
}
}
Before specifically processing the JoinGroupRequest request, the GroupCoordinator instance will first perform a series of verification operations to ensure that the consumer and target group sending the request are legal, and the corresponding GroupCoordinator can normally process the current request. If the target group does not exist, if the corresponding consumer ID is not specified, a new group will be created first, and then the current consumer will be added to the corresponding group to start partition redistribution. The GroupCoordinator#doJoinGroup method will verify whether the consumer ID (if specified) can be recognized by the current group and whether the partition allocation policy specified by the consumer can be supported by the current group. If these conditions cannot be met, it is not necessary to continue to allocate partitions for the consumer. The method is implemented as follows:
private def doJoinGroup(group: GroupMetadata,
memberId: String,
clientId: String,
clientHost: String,
rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback) {
group synchronized {
if (!group.is(Empty)
// The partition allocation policy specified by the consumer is not supported by the corresponding group
&& (group.protocolType != Some(protocolType) || !group.supportsProtocols(protocols.map(_._1).toSet))) {
responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL.code))
} else if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID && !group.has(memberId)) {
// Consumer ID cannot be recognized
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
} else {
// Process according to the current status of the group
group.currentState match {
// The target group has expired
case Dead =>
// The metadata information of the corresponding group has been deleted, indicating that it has been migrated to other GroupCoordinator instances or is no longer available. The error code is returned directly
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
// The target group is performing partition rebalance
case PreparingRebalance =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// For a consumer with an unknown ID who applies to join, create the corresponding metadata information and allocate the ID. at the same time, switch the status of the group to PreparingRebalance and prepare to perform partition redistribution
this.addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
// For a consumer with a known ID, re apply to join, update the corresponding metadata information, switch the status of the group to PreparingRebalance, and prepare to perform partition redistribution
val member = group.get(memberId)
this.updateMemberAndRebalance(group, member, protocols, responseCallback)
}
// The target group is waiting for the partition allocation result of the leader consumer
case AwaitingSync =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// For a consumer with an unknown ID who applies to join, create the corresponding metadata information and allocate the ID. at the same time, switch the status of the group to PreparingRebalance and prepare to perform partition redistribution
this.addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
// For consumers with known ID, re apply to join
val member = group.get(memberId)
if (member.matches(protocols)) {
// The partition allocation policy has not changed, and the information of GroupMetadata is returned
responseCallback(JoinGroupResult(
members = if (memberId == group.leaderId) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocol,
leaderId = group.leaderId,
errorCode = Errors.NONE.code))
} else {
// When the partition allocation policy changes, update the corresponding metadata information, and switch the status of the group to PreparingRebalance, ready to perform partition redistribution
this.updateMemberAndRebalance(group, member, protocols, responseCallback)
}
}
// The target group is running normally, or is waiting for the offset to expire
case Empty | Stable =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// For a consumer with an unknown ID who applies to join, create the corresponding metadata information and allocate the ID. at the same time, switch the status of the group to PreparingRebalance and prepare to perform partition redistribution
this.addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
// For consumers with known ID, re apply to join
val member = group.get(memberId)
if (memberId == group.leaderId || !member.matches(protocols)) {
// If the current consumer is a group leader or the partition allocation policy supported changes, update the corresponding metadata information. At the same time, switch the status of the group to PreparingRebalance and prepare to perform partition redistribution
this.updateMemberAndRebalance(group, member, protocols, responseCallback)
} else {
// The partition allocation policy has not changed, and the GroupMetadata information is returned
responseCallback(JoinGroupResult(
members = Map.empty,
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocol,
leaderId = group.leaderId,
errorCode = Errors.NONE.code))
}
}
}
// If the current group is preparing to perform partition reallocation, try to perform the DelayedJoin delay task
if (group.is(PreparingRebalance)) joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
}
For consumers who meet the conditions, they need to divide and rule according to the current running state of the group. If the status of the current group is Dead, it indicates that the corresponding group is no longer available, or has been managed by other GroupCoordinator instances and responds directly to unknown_ MEMBER_ If the ID is wrong, the consumer can request the location information of the newly taken over GroupCoordinator instance again.
If the status of the current group is PreparingRebalance, the corresponding group is preparing to perform partition reallocation. At this time:
- For newly added consumers (no ID is specified), first create the consumer ID and metadata information for them and submit them to the target group for management, and then start the partition redistribution operation.
- For an existing consumer (with an ID specified), first update the consumer's final partition allocation policy and callback response function, and then start the partition reallocation operation.
If the status of the current group is AwaitingSync, it means that the corresponding group is waiting for the partition allocation result of the leader consumer. At this time:
- For newly added consumers (no ID is specified), first create the consumer ID and metadata information for them and submit them to the target group for management, and then start the partition redistribution operation.
- For existing consumers (with specified ID), if the partition allocation policy has not changed, there is no need to re allocate. If the partition allocation policy has changed, there is no need to re allocate
Update the final partition allocation policy and callback response function of the consumer, and then start the partition redistribution operation.
If the status of the current group is Empty or Stable, the corresponding group is in a normal running state. At this time:
- For newly added consumers (no ID is specified), first create the consumer ID and metadata information for them and submit them to the target group for management, and then start the partition redistribution operation.
- For an existing consumer (with specified ID), if it is not a leader or the partition allocation policy has not changed, there is no need to re allocate. Otherwise, it is necessary to update the consumer's final partition allocation policy and callback response function, and then start the partition re allocation operation.
In the above process, the GroupCoordinator#addMemberAndRebalance method is called many times to create metadata information and assign ID for consumers, and record the corresponding consumer metadata information in the group metadata information. Method GroupMetadata#add defines that if the leader consumer is not yet elected under the current group name, the consumer who first joined the current group acts as the leader role, and then calls the GroupCoordinator#updateMemberAndRebalance method to update the consumer's partition allocation strategy and response callback function. The two methods are implemented as follows:
private def addMemberAndRebalance(rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
clientId: String,
clientHost: String,
protocolType: String,
protocols: List[(String, Array[Byte])],
group: GroupMetadata,
callback: JoinCallback): MemberMetadata = {
// Generate consumer ID based on UUID
val memberId = clientId + "-" + group.generateMemberIdSuffix
// Create a new MemberMetadata metadata information object
val member = new MemberMetadata(memberId, group.groupId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols)
// Set the callback function, namely KafkaApis#sendResponseCallback method, to send the JoinGroupResponse response to the client
member.awaitingJoinCallback = callback
// Added to GroupMetadata, the first consumer to join the group becomes the leader role
group.add(member)
// The status of the group you are trying to switch is PreparingRebalance
this.maybePrepareRebalance(group)
member
}
private def updateMemberAndRebalance(group: GroupMetadata,
member: MemberMetadata,
protocols: List[(String, Array[Byte])],
callback: JoinCallback) {
// Update protocols supported by MemberMetadata
member.supportedProtocols = protocols
// Response callback function for updating MemberMetadata
member.awaitingJoinCallback = callback
// Attempt to perform a state switch
this.maybePrepareRebalance(group)
}
It can be seen from the above implementation that both methods finally call the GroupCoordinator#maybePrepareRebalance method, which will verify the current state of the group. If it is one of Stable, awatingsync and Empty, it will call the GroupCoordinator#prepareRebalance method to switch the state of the group to PreparingRebalance, Create a corresponding DelayedJoin delay task and wait for all consumers under the group name to send a JoinGroupRequest to join the current group.
private def prepareRebalance(group: GroupMetadata) {
// If it is in AwaitingSync status, it indicates that it is waiting for the partition allocation result of the leader consumer,
// At this time, for the SyncGroupRequest request from the follower, respond directly to the reservation_ IN_ Progress error
if (group.is(AwaitingSync)) resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS)
// Switch the group status to PreparingRebalance status and prepare to perform partition reallocation
group.transitionTo(PreparingRebalance)
info("Preparing to restabilize group %s with old generation %s".format(group.groupId, group.generationId))
// The partition rebalance timeout is the maximum timeout set by all consumers
val rebalanceTimeout = group.rebalanceTimeoutMs
// Create a DelayedJoin delay task to wait for the consumer to apply to join the current group
val delayedRebalance = new DelayedJoin(this, group, rebalanceTimeout)
val groupKey = GroupKey(group.groupId) // Focus on the current group
// Add delayed tasks to purgatory for management
joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))
}
The above method will first verify whether the current status of the group is AwaitingSync. If so, it indicates that the current GroupCoordinator instance is waiting for the partition allocation result of the leader consumer. At this time, if there is a SyncGroupRequest request from the follower consumer, it will directly respond to the reservation_ IN_ Progress error. At the same time, it is necessary to clear the partition allocation information of all consumer records under the group name. Then switch the status of the group to PreparingRebalance, which means that it is ready to perform partition redistribution, create a DelayedJoin delay task, and wait for all consumers under the group name to send a JoinGroupRequest to join the current group.
Let's take a look at the implementation of the delayed task DelayedJoin. The delay duration here is equal to the maximum timeout duration set by all consumers under the group name. Let's focus on the DelayedJoin#tryComplete and DelayedJoin#onComplete methods, which call the GroupCoordinator#tryCompleteJoin and GroupCoordinator#onCompleteJoin methods respectively. The GroupCoordinator#tryCompleteJoin method judges whether all known consumers under the group name have sent JoinGroupRequest based on the consumer metadata information membermetadata #awatingjoincallback field. If so, the DelayedJoin delay task is forced to be completed. The method is implemented as follows:
def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean): Boolean = {
group synchronized {
// Judge whether all known consumers have applied to join,
// Based on the awaitingJoinCallback callback function, only the consumer who sent the JoinGroupRequest request will set the callback
if (group.notYetRejoinedMembers.isEmpty) forceComplete() else false
}
}
def notYetRejoinedMembers: List[MemberMetadata] = members.values.filter(_.awaitingJoinCallback == null).toList
The MemberMetadata#awaitingJoinCallback field of consumer metadata information is actually the sendResponseCallback callback function defined in the KafkaApis#handleJoinGroupRequest method, which is used to send a JoinGroupResponse response to the client. Therefore, we can judge whether the corresponding consumer has sent a JoinGroupRequest according to this field, because the MemberMetadata#awaitingJoinCallback field will be assigned only after the request is sent.
When the delayed task DelayedJoin is executed, the GroupCoordinator#onCompleteJoin method will be triggered. The implementation is as follows:
def onCompleteJoin(group: GroupMetadata) {
var delayedStore: Option[DelayedStore] = None
group synchronized {
// Remove those known consumers who have not applied to rejoin the current group
group.notYetRejoinedMembers.foreach { failedMember => group.remove(failedMember.memberId) }
if (!group.is(Dead)) {
// Increment the age information of the group and select the partition allocation policy finally used by the group. If there are consumers under the group name, the switching state is AwaitingSync, otherwise it is Empty
group.initNextGeneration()
if (group.is(Empty)) {
info(s"Group ${group.groupId} with generation ${group.generationId} is now empty")
// If there is no consumer under the group name, record the empty partition allocation information to offset topic
delayedStore = groupManager.prepareStoreGroup(group, Map.empty, error => {
if (error != Errors.NONE) {
warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}")
}
})
} else {
info(s"Stabilized group ${group.groupId} generation ${group.generationId}")
// Send a JoinGroupResponse response to all consumers under the group name,
for (member <- group.allMemberMetadata) {
assert(member.awaitingJoinCallback != null)
val joinResult = JoinGroupResult(
members = if (member.memberId == group.leaderId) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = member.memberId,
generationId = group.generationId,
subProtocol = group.protocol,
leaderId = group.leaderId,
errorCode = Errors.NONE.code)
// This callback function is defined in KafkaApis#handleJoinGroupRequest (corresponding to the sendResponseCallback method), which is used to put the response object into the channel and wait for sending
member.awaitingJoinCallback(joinResult)
member.awaitingJoinCallback = null
// heartbeat mechanism
this.completeAndScheduleNextHeartbeatExpiration(group, member)
}
}
}
}
// Append message to offset topic
delayedStore.foreach(groupManager.store)
}
The DelayedJoin delay task is mainly waiting for the consumer under the group name to send the JoinGroupRequest request during the waiting period. Once the task meets the execution conditions (or may be due to timeout), it will be executed:
- Eliminate those known consumers who have not applied to rejoin the current group;
- If the target group status is already Dead, end the task;
- Otherwise, increment the age information of the group, determine the final partition allocation strategy for the consumers under the group name, and switch the group state to AwaitingSync or Empty according to whether there are consumers under the group name;
- If the switched group status is Empty, the Empty partition allocation result is appended to topic offset;
- If the switched group status is AwaitingSync, send a JoinGroupResponse response to all consumers under the group name and wait for the leader consumer's SyncGroupRequest to feed back the partition allocation result.
The implementation of step 3 is located in the GroupMetadata#initNextGeneration method. This method will switch the group to the corresponding state according to whether there are consumers under the group name. If there are consumers under the group name, it will also determine the final partition allocation policy. The method is implemented as follows:
def initNextGeneration(): Unit = {
assert(notYetRejoinedMembers == List.empty[MemberMetadata])
if (members.nonEmpty) {
generationId += 1
// Select a partition allocation policy supported by all consumers based on voting
protocol = selectProtocol
transitionTo(AwaitingSync)
} else {
generationId += 1
protocol = null
transitionTo(Empty)
}
}
Determine the final partition allocation strategy, which is simply to vote for a strategy with the highest vote as the final strategy from the partition allocation strategies supported by consumers. The implementation is as follows:
def selectProtocol: String = {
if (members.isEmpty)
throw new IllegalStateException("Cannot select protocol for empty group")
// Calculate partition allocation policies supported by all consumers
val candidates = candidateProtocols
// Select the protocols supported by all consumers as the candidate protocol set,
// Each consumer will vote through the vote method (vote for the first agreement in the supported agreement),
// Finally, the partition allocation strategy with the most votes is selected
val votes: List[(String, Int)] = allMemberMetadata
.map(_.vote(candidates))
.groupBy(identity)
.mapValues(_.size)
.toList
votes.maxBy(_._2)._1
}
The voting strategy of the MemberMetadata#vote method is actually to select the first one from the partition allocation strategies supported by consumers and all consumers under the group name to vote.
The implementation of step 4 is in the GroupMetadataManager#prepareStoreGroup method. The main logic of this step is to create a Kafka message based on the partition allocation result (but the partition allocation result here is an empty set) and write it to the offset topic. The method is implemented as follows:
def prepareStoreGroup(group: GroupMetadata,
groupAssignment: Map[String, Array[Byte]],
responseCallback: Errors => Unit): Option[DelayedStore] = {
// Process according to the message version of the offset topic partition corresponding to the group
getMagic(partitionFor(group.groupId)) match {
case Some(magicValue) =>
val groupMetadataValueVersion = {
if (interBrokerProtocolVersion < KAFKA_0_10_1_IV0) 0.toShort
else GroupMetadataManager.CURRENT_GROUP_VALUE_SCHEMA_VERSION
}
val timestampType = TimestampType.CREATE_TIME
val timestamp = time.milliseconds()
// Create a message that records GroupMetadata information, where value is the allocation result of the partition
val record = Record.create(magicValue, timestampType, timestamp,
GroupMetadataManager.groupMetadataKey(group.groupId),
GroupMetadataManager.groupMetadataValue(group, groupAssignment, version = groupMetadataValueVersion))
// Get the offset topic partition object corresponding to the group
val groupMetadataPartition = new TopicPartition(Topic.GroupMetadataTopicName, partitionFor(group.groupId))
// Construct the mapping relationship between offset topic partition and message set
val groupMetadataRecords = Map(groupMetadataPartition -> MemoryRecords.withRecords(timestampType, compressionType, record))
val generationId = group.generationId
// ... Omit the putCacheCallback callback function, which will be called back after the message is appended to the offset topic, and will be analyzed later
// There is no real additional message here, but it is recorded in the DelayedStore. The specific additional is added by the GroupMetadataManager#store method
Some(DelayedStore(groupMetadataRecords, putCacheCallback))
case None =>
responseCallback(Errors.NOT_COORDINATOR_FOR_GROUP)
None
}
}
The method creates a Kafka message based on the partition allocation result and writes it to the partition corresponding to offset topic (the previous section analyzes that the metadata information of the group is recovered on the new GroupCoordinator node based on this message during GroupCoordinator failover). It should be noted that no real write operation is performed here, Instead, the data to be written and the callback function after writing are encapsulated into a DelayedStore object, and the real write operation is performed only when the GroupMetadataManager#store method is called later:
def store(delayedStore: DelayedStore) {
// Call the ReplicaManager#appendRecords method to append a message to the offset topic
replicaManager.appendRecords(
config.offsetCommitTimeoutMs.toLong,
config.offsetCommitRequiredAcks, // -1. The message is considered to be successfully appended only after all replicas in the ISR set have synchronized the message
internalTopicsAllowed = true, // Specifies that messages are allowed to be appended to the internal topic, that is, offset topic
delayedStore.partitionRecords, // Mapping between partition and corresponding message
delayedStore.callback) // Callback function
}
The callback function in the above method is actually the putCacheCallback method defined in the GroupMetadataManager#prepareStoreGroup method. When the message is appended to the offset topic, it will call back to execute the method:
def putCacheCallback(responseStatus: Map[TopicPartition, PartitionResponse]) {
if (responseStatus.size != 1 || !responseStatus.contains(groupMetadataPartition))
throw new IllegalStateException("Append status %s should only have one partition %s".format(responseStatus, groupMetadataPartition))
// Get message append response result
val status = responseStatus(groupMetadataPartition)
val responseError = if (status.error == Errors.NONE) {
// Append succeeded
Errors.NONE
} else {
// ... Append exceptions, perform some conversion operations on the error code, and omit
}
// Execute callback function
responseCallback(responseError)
}
When the message is appended to offset topic, it will be encapsulated into the corresponding error code according to the append result of the message and call back the responseCallback method. This is a function of errors = > unit. In this step, the function simply prints a line of warning log when the append fails. After all, the appended message is empty.
6.3 SyncGroupRequest processing
For the GroupCoordinator instance, the last step of the partition reallocation operation is to process the SyncGroupRequest request from the leader consumer to obtain the result information of the leader consumer allocating the partition to the consumer under the current group name based on the partition allocation policy determined by the server. The KafkaApis#handleSyncGroupRequest method is defined in KafkaApis to process the request, and the specific processing logic is implemented by the GroupCoordinator#handleSyncGroup method. This method will first verify the running state of the GroupCoordinator instance to ensure that the SyncGroupRequest request from the corresponding consumer can be processed. The specific processing logic is implemented as follows:
private def doSyncGroup(group: GroupMetadata,
generationId: Int,
memberId: String,
groupAssignment: Map[String, Array[Byte]],
responseCallback: SyncCallback) {
var delayedGroupStore: Option[DelayedStore] = None
group synchronized {
if (!group.has(memberId)) {
// The current consumer does not belong to this group
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code)
} else if (generationId != group.generationId) {
// Illegal information
responseCallback(Array.empty, Errors.ILLEGAL_GENERATION.code)
} else {
group.currentState match {
case Empty | Dead =>
// Direct return error code
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code)
case PreparingRebalance =>
// Direct return error code
responseCallback(Array.empty, Errors.REBALANCE_IN_PROGRESS.code)
case AwaitingSync =>
// Set the response callback function of the corresponding consumer
group.get(memberId).awaitingSyncCallback = responseCallback
// Only SyncGroupRequest requests from the leader consumer are processed
if (memberId == group.leaderId) {
info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}")
// Fill the partition allocation result corresponding to the consumer without partition allocation into an empty byte array
val missing = group.allMembers -- groupAssignment.keySet
val assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap
// Write GroupMetadata related information to the corresponding offset topic partition in the form of a message
delayedGroupStore = groupManager.prepareStoreGroup(group, assignment,
// ... The callback response logic completed by the additional message is omitted, which will be analyzed later
)
}
case Stable =>
// Return the existing partition allocation results to the current consumer
val memberMetadata = group.get(memberId)
responseCallback(memberMetadata.assignment, Errors.NONE.code)
// Heartbeat related operations
this.completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId))
}
}
}
// Execute write offset topic logic
delayedGroupStore.foreach(groupManager.store)
}
The GroupCoordinator relies on the current status of the target group to divide and rule SyncGroupRequest requests. For Empty, Dead and PreparingRebalance States, it directly returns the corresponding error code. At this time, there is no meaning and conditions for normal response to SyncGroupRequest requests. The following mainly analyzes awatingsync and Stable states.
For AwaitingSync status, the GroupCoordinator is waiting for the partition allocation result of the leader consumer (i.e. SyncGroupRequest request), so the group in this status only processes the SyncGroupRequest request from the leader consumer. If the number of consumers is more than the number of partitions of topic, the extra consumers will not allocate partitions. Kafka requires that a partition be consumed by at most one consumer in design, so the partition allocation information of these extra consumers will be empty. Then, the GroupCoordinator instance will call the GroupMetadataManager#prepareStoreGroup method to write the partition allocation information into the offset topic. The execution logic of this method has been analyzed earlier, so it will not be repeated here. Focus on the implementation of the callback function of this method. As described earlier, when the message is added to the offset topic, the callback function specified by the callback parameter will be called back, and the callback logic here is implemented as follows:
(error: Errors) => {
group synchronized {
// Check the status of the group (waiting for the leader consumer to send the partition allocation result to the group Coordinator) and the age information
if (group.is(AwaitingSync) && generationId == group.generationId) {
if (error != Errors.NONE) {
// Clear the partition allocation result and send an exception response
resetAndPropagateAssignmentError(group, error)
// Switch the group status to PreparingRebalance and try to allocate partitions again
maybePrepareRebalance(group)
} else {
// Set the partition allocation result and send a normal SyncGroupResponse response
setAndPropagateAssignment(group, assignment)
group.transitionTo(Stable)
}
}
}
}
If the append message fails, the allocation result of the partition will be cleared in the callback logic and the error message will be returned to the leader consumer. Meanwhile, the GroupCoordinator instance will switch to PreparingRebalance to try to allocate the partition again. If the message is appended successfully, the partition allocation result will be updated to the metadata information of the corresponding consumer under the group name, and the normal SyncGroupResponse will be responded to the leader consumer. At the same time, the status of the group will be switched to Stable to start normal operation.
For the Stable state, the group is in normal operation at this time. Therefore, for the SyncGroupRequest request from the consumer, the historical partition allocation results are simply returned directly without special processing.
6.4 consumer request processing
6.4.1 OffsetFetchRequest processing
After the partition reassignment operation is completed, the consumer will generally be reassigned to a new partition. At this time, the consumer needs to send an OffsetFetchRequest request to the cluster to obtain the offset value of the last consumer in the corresponding topic partition and continue consumption from this location to prevent repeated consumption or missing consumption of messages.
KafkaApis defines the KafkaApis#handleOffsetFetchRequest method to process the OffsetFetchRequest request. This method will perform permission verification on the requested topic partition. If the verification passes, it will decide whether to obtain the offset location information of the target topic partition from ZK or offset topic according to the version number specified in the request. At present, in order to avoid the impact of ZK pressure on service availability, the new version of Kafka has used offset topic instead of ZK by default to record the offset location information of consumers' consumption. Therefore, this section only introduces the processing process of OffsetFetchRequest request based on offset topic.
The specific processing logic is executed by the GroupCoordinator#handleFetchOffsets method. If the topic partition to obtain offset is not specified in the request, it means that it is expected to obtain the offset value submitted by all topic partitions in the current group recently. The method is implemented as follows:
def handleFetchOffsets(groupId: String, partitions: Option[Seq[TopicPartition]] = None): (Errors, Map[TopicPartition, OffsetFetchResponse.PartitionData]) = {
if (!isActive.get) {
// The current GroupCoordinator instance is not running
(Errors.GROUP_COORDINATOR_NOT_AVAILABLE, Map())
} else if (!isCoordinatorForGroup(groupId)) {
// The current GroupCoordinator instance is not responsible for managing the current group
debug("Could not fetch offsets for group %s (not group coordinator).".format(groupId))
(Errors.NOT_COORDINATOR_FOR_GROUP, Map())
} else if (isCoordinatorLoadingInProgress(groupId)) {
// The current GroupCoordinator instance is loading the offset topic partition information corresponding to the group
(Errors.GROUP_LOAD_IN_PROGRESS, Map())
} else {
// Returns the latest submitted offset position information corresponding to the specified topic partition set
(Errors.NONE, groupManager.getOffsets(groupId, partitions))
}
}
def getOffsets(groupId: String, topicPartitionsOpt: Option[Seq[TopicPartition]]): Map[TopicPartition, OffsetFetchResponse.PartitionData] = {
trace("Getting offsets of %s for group %s.".format(topicPartitionsOpt.getOrElse("all partitions"), groupId))
// Get the metadata information corresponding to the group
val group = groupMetadataCache.get(groupId)
if (group == null) {
// If the metadata information corresponding to group does not exist, the offset returned is - 1
topicPartitionsOpt.getOrElse(Seq.empty[TopicPartition]).map { topicPartition =>
(topicPartition, new OffsetFetchResponse.PartitionData(OffsetFetchResponse.INVALID_OFFSET, "", Errors.NONE))
}.toMap
} else {
group synchronized {
if (group.is(Dead)) {
// There is no consumer under the corresponding group name, and the metadata information has been deleted
topicPartitionsOpt.getOrElse(Seq.empty[TopicPartition]).map { topicPartition =>
(topicPartition, new OffsetFetchResponse.PartitionData(OffsetFetchResponse.INVALID_OFFSET, "", Errors.NONE))
}.toMap
} else {
topicPartitionsOpt match {
// The request does not specify a topic partition, which means that the latest submitted offset value corresponding to all topic partitions under the group name is requested
case None =>
group.allOffsets.map { case (topicPartition, offsetAndMetadata) =>
topicPartition -> new OffsetFetchResponse.PartitionData(offsetAndMetadata.offset, offsetAndMetadata.metadata, Errors.NONE)
}
// Finds the latest submitted offset value corresponding to the specified topic partition set
case Some(_) =>
topicPartitionsOpt.getOrElse(Seq.empty[TopicPartition]).map { topicPartition =>
val partitionData = group.offset(topicPartition) match {
case None =>
new OffsetFetchResponse.PartitionData(OffsetFetchResponse.INVALID_OFFSET, "", Errors.NONE)
case Some(offsetAndMetadata) =>
new OffsetFetchResponse.PartitionData(offsetAndMetadata.offset, offsetAndMetadata.metadata, Errors.NONE)
}
topicPartition -> partitionData
}.toMap
}
}
}
}
}
The GroupMetadata#offsets field of the Group metadata information caches the latest submitted offset location information and user-defined data of each topic partition, so here you only need to obtain the offset value of the corresponding topic partition.
6.4.2 OffsetCommitRequest request processing
After consuming the specified offset, the consumer will submit the offset value to the server in the form of OffsetCommitRequest request based on the configuration and corresponding scenarios. After receiving the OffsetCommitRequest request, the server needs to record the consumption location of the corresponding topic partition for each consumer.
KafkaApis defines the KafkaApis#handleOffsetCommitRequest method to process the OffsetCommitRequest request. This method will verify whether the target topic exists and whether it has read permission for the topic. If the conditions are met, it will determine whether to record the corresponding offset location information to ZK or offset topic according to the version number specified in the request, This section also only introduces the processing of offset commitrequest request based on offset topic.
The specific processing logic is executed by the GroupCoordinator #handlecommitooffsets method, which first verifies the status of the GroupCoordinator to ensure that the current OffsetCommitRequest request can be processed normally, and calls the GroupCoordinator #docommitooffsets method to encapsulate the offset consumption location information into a message and append it to the offset topic if allowed:
private def doCommitOffsets(group: GroupMetadata,
memberId: String,
generationId: Int,
offsetMetadata: immutable.Map[TopicPartition, OffsetAndMetadata],
responseCallback: immutable.Map[TopicPartition, Short] => Unit) {
var delayedOffsetStore: Option[DelayedStore] = None
group synchronized {
if (group.is(Dead)) {
// The target group is invalid. Respond directly to the error code
responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID.code))
} else if (generationId < 0 && group.is(Empty)) {
// The information of the target group is not maintained by kafka, but only depends on the offset consumption information recorded by kafka
delayedOffsetStore = groupManager.prepareStoreOffsets(group, memberId, generationId, offsetMetadata, responseCallback)
} else if (group.is(AwaitingSync)) {
// The target group is currently performing partition reallocation
responseCallback(offsetMetadata.mapValues(_ => Errors.REBALANCE_IN_PROGRESS.code))
} else if (!group.has(memberId)) {
// The target group does not contain the current consumer
responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID.code))
} else if (generationId != group.generationId) {
// Inconsistent target information
responseCallback(offsetMetadata.mapValues(_ => Errors.ILLEGAL_GENERATION.code))
} else {
// Append the message recording offset information to the corresponding offset topic partition
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
delayedOffsetStore = groupManager.prepareStoreOffsets(group, memberId, generationId, offsetMetadata, responseCallback)
}
}
// Perform a real append message operation
delayedOffsetStore.foreach(groupManager.store)
}
The specific process of adding messages to offset topic has been analyzed above and will not be repeated.
6.4.3 LeaveGroupRequest processing
When the consumer unsubscribes from the specified topic or configures internal leave. group. on. Close = true indicates that the group to which the consumer belongs will be exited together when the consumer is closed, and when the consumer goes offline for some abnormal reasons, a LeaveGroupRequest will be sent to the corresponding GroupCoordinator node, which has informed the consumer corresponding to the cluster that it has failed and may need to trigger partition reallocation.
KafkaApis defines the KafkaApis#handleLeaveGroupRequest method to process the LeaveGroupRequest request. This method will first perform permission verification on the consumer and entrust the GroupCoordinator to process the corresponding offline policy on the premise that the permission verification passes. The specific logical implementation is in the GroupCoordinator#handleLeaveGroup method:
def handleLeaveGroup(groupId: String, memberId: String, responseCallback: Short => Unit) {
if (!isActive.get) {
// The GroupCoordinator instance was not started
responseCallback(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code)
} else if (!isCoordinatorForGroup(groupId)) {
// The current GroupCoordinator instance is not responsible for managing the current group
responseCallback(Errors.NOT_COORDINATOR_FOR_GROUP.code)
} else if (isCoordinatorLoadingInProgress(groupId)) {
// The current GroupCoordinator instance is loading the offset topic partition information corresponding to the group
responseCallback(Errors.GROUP_LOAD_IN_PROGRESS.code)
} else {
groupManager.getGroup(groupId) match {
// The corresponding group does not exist or has expired
case None =>
responseCallback(Errors.UNKNOWN_MEMBER_ID.code)
case Some(group) =>
group synchronized {
if (group.is(Dead) || !group.has(memberId)) {
responseCallback(Errors.UNKNOWN_MEMBER_ID.code)
} else {
val member = group.get(memberId)
// Set MemberMetadata#isLeaving to true and try to complete the corresponding DelayedHeartbeat delay task
this.removeHeartbeatForLeavingMember(group, member)
// Remove the corresponding MemberMetadata object from the group metadata information and switch the state
this.onMemberFailure(group, member)
// Call callback response function
responseCallback(Errors.NONE.code)
}
}
}
}
}
If the group to which the consumer sending the LeaveGroupRequest belongs exists and runs normally, the server will first set the MemberMetadata#isLeaving field of the corresponding consumer metadata information to true, identify that the current consumer is offline, and try to trigger the DelayedHeartbeat delay task that pays attention to the current consumer. In addition, the consumer will be removed from the metadata information of the group to which it belongs, and whether to trigger the partition reallocation operation or the DelayedJoin delay task that pays attention to the group will be determined according to the current state of the group. The relevant implementation is located in the GroupCoordinator#onMemberFailure method. This method has been analyzed earlier and will not be repeated here.
7. Summary
In this paper, we analyze the function and implementation of the GroupCoordinator component. The component has a close relationship with consumers. During the running period, consumers are basically responsible for handling the rest of the interaction except pulling messages from the ReplicaManager component for consumption. Kafka relies on this component to manage the group to which the consumer belongs and coordinate the consumers under the group name. It mainly provides partition allocation and rebalancing support, records the consumption offset location information of the group, and maintains the heartbeat with consumers. In addition, the GroupCoordinator has a built-in failover mechanism to ensure that when the leader copy of the corresponding partition of topic offset fails, it can switch to a new GroupCoordinator instance to continue providing services.