This article strictly refers to the connection (strictly copying other people's content to prevent loss and facilitate your own viewing): https://www.cnblogs.com/xiao-xue-di/p/11840339.html#_label7
Reading catalog
- 1.1. major function
- 1.2. Usage scenario
- Consumption group and partition rebalancing
- 1.3. Detailed introduction
- 2.1. download
- 2.2. install
- 2.3. to configure
- 2.4. function
- 2.5. First message
kafka practical tutorial (python operation kafka), detailed explanation of kafka configuration file
There are many reasons why applications write data to Kafka: user behavior analysis, log storage, asynchronous communication, etc. Diversified usage scenarios bring diversified requirements: can messages be lost? Is repetition tolerated? Message throughput? Message delay?
kafka introduction
Kafka belongs to Apache organization and is a high-performance cross language distributed publish subscribe message queue system [7]. Its main features are:
- Provide message persistence capability in the way of time complexity O(1), and ensure constant time access performance for large data;
- With high throughput, a single server can reach hundreds of thousands of throughput per second;
- Support message partition between servers, support distributed consumption, and ensure the message order in each partition;
- Lightweight, supporting real-time data processing and offline data processing.
1.1. major function
According to the official website, Apache Kafka ® Is a distributed streaming media platform, which mainly has three functions:
1: Publishing and subscribing to message flows is similar to message queuing, which is why kafka is classified as a message queuing framework
2: The message flow is recorded in a fault-tolerant manner, and kafka stores the message flow in a file manner
3: It can be processed when the message is released
1.2. Usage scenario
1: Build a reliable pipeline between systems or applications for transmitting real-time data, message queuing function
2: Build real-time stream data processing program to transform or process data stream, data processing function
kafka producer
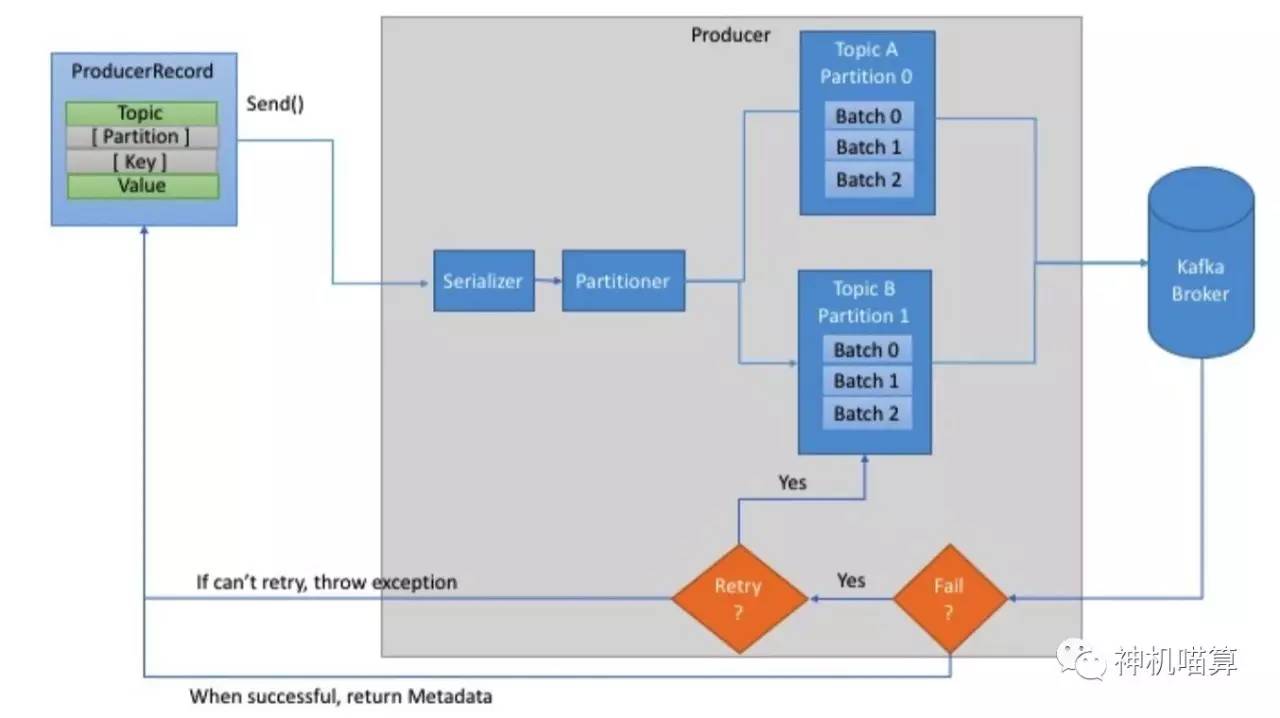
First, creating a ProducerRecord must include Topic and value, and key and partition are optional. Then, the key and value objects are serialized as ByteArray and sent to the network.
Next, the message is sent to the partitioner. If a partition is specified when creating a ProducerRecord, the partitioner does nothing at this time. Simply return the specified partition. If no partition is specified, the partitioner will generate a partition based on the key of the producer record. After selecting partition, producer adds record to batch record corresponding to topic and partition. Finally, the dedicated thread is responsible for sending batch records to the appropriate Kafka broker.
When the broker receives a message, it will return a response. If the message is successfully written to Kafka, the broker will return the RecordMetadata object (including topic, partition and offset); on the contrary, the broker will return error. At this time, the producer will try to retry sending the message several times until the producer returns error.
After instantiating the producer, send a message. There are three main methods to send messages:
-
Send immediately: just send the message to the server, regardless of whether the care message is successfully sent. In most cases, this sending method will succeed because Kafka has high availability and producer will automatically retry; But sometimes messages are lost;
-
Synchronous sending: Send a message through the send() method and return the Future object. The get() method will wait for the Future object to see if the send() method is successful;
-
Asynchronous sending: send messages through the send() method with callback function. When the producer receives the response from Kafka broker, it will trigger the callback function
In all the above cases, you must always consider that sending messages may fail, and figure out how to handle exceptions.
Usually, a producer starts a thread and starts sending messages. In order to optimize the performance of a producer, there are generally the following ways: a single producer sends messages from multiple threads; Use multiple producers.
kafka consumer
There are three consumption patterns of kafka: at most once, at least once, exactly once. The reason why there are these three modes is that the two actions of the client processing messages and submitting feedback are not atomic.
1. At most once: after receiving the message, the client automatically submits it before processing the message, so kafka thinks that the consumer has consumed it and the offset increases.
2. At least once: the client receives the message, processes the message, and then submits the feedback. In this way, when the message processing is finished and the network is interrupted or the program hangs up before submitting the feedback, kafka thinks that the message has not been consumed by the consumer, resulting in repeated message push.
3. Exactly once: ensure that message processing and submission feedback are in the same transaction, that is, atomicity.
Starting from these points, this paper expounds in detail how to realize the above three ways.
At most once
Set enable auto. Commit is true
Set auto commit. interval. MS is a small time interval
client should not call commitSync(), kafka will submit automatically within a specific time interval.
At least once
Method 1
Set enable auto. Commit is false
The client calls commitSync() to increase the message offset;
Method 2
Set enable auto. Commit is true
Set auto commit. interval. MS is a large time interval
The client calls commitSync() to increase the message offset;
Exactly once
3.1 ideas
If you want to implement this method, you must control the offset of the message and record the current offset. The processing of the message and the movement of the offset must be kept in the same transaction. For example, in the same transaction, save the message processing results to the mysql database and update the offset of the message at this time.
3.2 realization
Set enable auto. Commit is false
Save the offset in ConsumerRecord to the database
rebalance is required when the partition changes. The following events will trigger the partition change
1. The partition size in the topic subscribed by the consumer changes
2 topic is created or deleted
3. A member of the consumer's group hangs up
4. The new consumer joins the group by calling join
At this time, the consumer captures these events and processes the offset by implementing the ConsumerRebalanceListener interface.
The consumer moves to the offset position of the specified partition by calling the seek(TopicPartition, long) method.
reference resources: https://blog.csdn.net/laojiaqi/article/details/79034798
Broker
Kafka is a high-throughput distributed messaging system written in Scala and Java. It provides fast, scalable, distributed, partitioned and replicable log subscription services. It consists of Producer, Broker and Consumer
Producer publishes messages to a Topic, while Consumer subscribes to messages of a Topic. Once there is a new message generated by a Topic, the Broker will deliver it to all consumers subscribing to it. Each Topic is divided into multiple partitions. This design is conducive to data management and load balancing.
- Broker: message middleware processing node. A Kafka node is a broker. Multiple brokers can form a Kafka cluster.
- Control ler: the central Controller is responsible for managing the status of partitions and replicas and managing the reallocation of these partitions. (it involves the partition leader election)
- ISR: synchronous replica group
Topic
In Kafka, messages are organized by Topic
- Partition: the physical grouping of topics. A topic can be divided into multiple partitions, and each partition is an ordered queue.
- Segment: partition is physically composed of multiple segments
- Offset: each partition is composed of a series of ordered and immutable messages, which are continuously appended to the partition Each message in the partition has a continuous serial number called offset, which is used to uniquely identify a message in the partition
partition storage distribution in topic
In the Kafka file storage, there are multiple different partitions under the same topic. Each partition is a directory. The partition naming rule is topic name + ordered sequence number. The sequence number of the first partition starts from 0, and the maximum sequence number is the number of partitions minus 1.
├── data0 │ ├── cleaner-offset-checkpoint │ ├── client_mblogduration-35 │ │ ├── 00000000000004909731.index │ │ ├── 00000000000004909731.log // 1G file -- Segment │ │ ├── 00000000000005048975.index // The number is Offset │ │ ├── 00000000000005048975.log │ ├── client_mblogduration-37 │ │ ├── 00000000000004955629.index │ │ ├── 00000000000004955629.log │ │ ├── 00000000000005098290.index │ │ ├── 00000000000005098290.log │ ├── __consumer_offsets-33 │ │ ├── 00000000000000105157.index │ │ └── 00000000000000105157.log │ ├── meta.properties │ ├── recovery-point-offset-checkpoint │ └── replication-offset-checkpoint
- Cleaner offset checkpoint: the last cleanup offset of each log is saved
- meta.properties: broker.id information
- Recovery point offset checkpoint: indicates the records that have been written to the disk. The data below recoveryPoint has been brushed to the disk.
- Replication offset checkpoint: used to store the HighWatermark of each replica (high watermark (HW), which indicates the message that has been committed. The data below HW is synchronized and consistent among replicas.)
How files are stored in partiton
Each section consists of multiple equal size segment data files. However, the number of segment file messages in each segment is not necessarily equal. This feature facilitates the rapid deletion of old segment file.
Each Parton only needs to support sequential reading and writing. The life cycle of the segment file is determined by the server configuration parameters.
Storage structure of segment file in partiton
The composition and physical structure of the segment file in the section.
segment file: it consists of two parts, index file and data file. These two files correspond to each other one by one and appear in pairs. The suffixes ". Index" and ". log" represent segment index file and data file respectively
Segment file naming rules: the first segment of the global part starts from 0, and the name of each subsequent segment file is the offset value of the last message of the previous segment file. The maximum value is 64 bit long, 19 bit numeric character length, and no number is filled with 0.
Taking a pair of segment file files as an example, the physical structure of the corresponding relationship between index < - > data file in segment is as follows
- The Index file stores a large amount of metadata and points to the physical offset address of the message in the corresponding log file.
- The log data file stores a large number of messages
Taking the metadata 3497 in the Index file as an example, the third message(368772nd message in the global Parton) is represented in the data file in turn, and the physical offset address of the message is 497.
Let's look inside the segment data file
segment data file consists of many messages. The physical structure of message is described in detail below:
| keyword | interpretative statement |
|---|---|
| 8 byte offset | The message is set at the offset of the partition |
| 4 byte message size | message size |
| 4 byte CRC32 | Check message with crc32 |
| 1 byte "magic" | Indicates the version number of the Kafka service program agreement issued this time |
| 1 byte "attributes" | Represents a stand-alone version, or identifies a compression type, or an encoding type. |
| 4 byte key length | Indicates the length of the key. When the key is - 1, the K byte key field is not filled in |
| K byte key | Optional |
| value bytes payload | Represents the actual message data. |
2.4 how to find message through offset in partition
For example, to read a message with offset=368776, you need to find it in the following two steps.
- The first step is to find the segment file
- Figure 2 above is an example, of which 00000000000000 Index represents the first file, and the starting offset is 0.5 Second file 00000000000000368769 The message volume start offset of index is 368770 = 368769 + 1 Similarly, the third file is 00000000000000737337 The starting offset of index is 737338 = 737337 + 1, and so on. Name and sort these files with the starting offset. You can quickly locate specific files as long as you search the file list according to offset , binary.
When offset=368776, locate to 00000000000000368769 index|log
- The second step is to find the message through the segment file
- In the first step, locate the segment file. When offset=368776, locate 00000000000000368769 The physical location of the metadata of the index (which is small and can be put in memory for direct operation) and the physical offset address of 00000000000000000000368769.log, and then find the index in the order of 00000000000000000000368769.log until offset=368776.
We can see the advantages of this from Section 2.3 above. The segment index file adopts the sparse index storage method, which reduces the size of the index file. It can be operated directly in memory through the map. The sparse index sets a metadata pointer for each corresponding message of the data file. It saves more storage space than the dense index, but it takes more time to find.
2.5 reading and writing message summary
Write message
- Messages are transferred from the java heap to the page cache (i.e. physical memory).
- The disk is flushed by the asynchronous thread, and messages are flushed from the page cache to the disk.
Read message
- The message is directly transferred from the page cache to the socket and sent out.
- When no corresponding data is found from the page cache, disk IO will be generated
The disk Load message is sent to the page cache, and then sent directly from the socket
Design features of Kafka efficient file storage
- A parition large file in topic is divided into multiple small file segments. Through multiple small file segments, it is easy to regularly clear or delete consumed files and reduce disk occupation.
- Through the index information, you can quickly locate the message and determine the maximum size of the response.
- By mapping all the index metadata to memory, the IO disk operation of segment file can be avoided.
- Through sparse storage of index files, the occupied space of index file metadata can be greatly reduced.
reference resources: https://www.cnblogs.com/byrhuangqiang/p/6364088.html
Kafka consumer

Consumption group and partition rebalancing
It can be seen that when new consumers join the consumption group, they will consume one or more partitions, which were previously in the charge of other consumers; In addition, When a consumer leaves the consumption group (such as restart, downtime, etc.), the partitions it consumes will be allocated to other partitions. This phenomenon is called rebalancing (rebalance). Rebalancing is a very important property of Kafka, which ensures high availability and horizontal expansion. However, it should also be noted that during the rebalancing period, all consumers cannot consume messages, so the whole consumption group will be temporarily unavailable. Moreover, rebalancing the partition will also lead to the expiration of the original consumer status, resulting in the loss of consumers The status needs to be updated again, which will also reduce consumption performance. Later we will discuss how to balance safely and how to avoid it as much as possible.
Consumers keep alive in the consumer group by regularly sending heartbeat to a broker as a group coordinator. This broker is not fixed, and each consumer group may be different. When consumers pull messages or submit, heartbeat will be sent.
If the consumer does not send a heartbeat for more than a certain time, Then its session (session) will expire. The group Coordinator will think that the consumer has been down, and then trigger the rebalancing. It can be seen that there is a certain time from the consumer's down to the session expiration. During this time, the consumer's partition cannot consume messages; usually, we can shut down gracefully, so that the consumer will send a leaving message to the group coordinator The sample group coordinator can rebalance immediately without waiting for the session to expire.
At 0.10 In version 1, Kafka modified the heartbeat mechanism to separate the sending heartbeat from the pulling message, so that the sending heartbeat frequency is not affected by the pulling frequency. In addition, the higher version of Kafka supports the configuration of how long a consumer does not pull messages but remains alive. This configuration can avoid livelock. Livelock refers to that the application is not faulty but cannot be consumed further for some reasons.
1.3. Detailed introduction
At present, Kafka is mainly used as a distributed publish subscribe message system. The basic mechanism of Kafka is briefly introduced below
1.3. 1 message transmission process
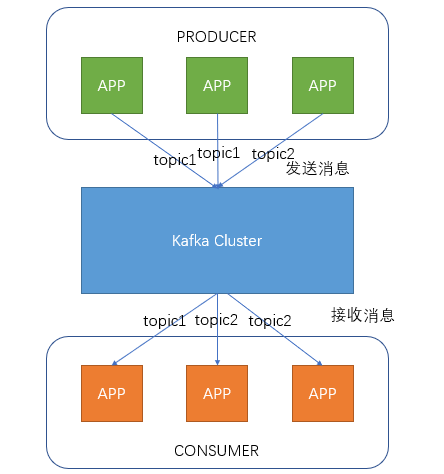
Producers, i.e. producers, send messages to the Kafka cluster. Before sending messages, they will classify the messages, i.e. topic. The figure above shows that two producers send messages classified as topic1 and the other one sends messages classified as topic2.
Topic s are topics. Messages can be classified by specifying topics for messages. Consumers can only focus on the messages in the topics they need
The Consumer is the Consumer. By establishing a long connection with the kafka cluster, the Consumer continuously pulls messages from the cluster, and then can process these messages.
As can be seen from the above figure, the number of consumers and producers under the same Topic does not correspond.
1.3.2 kafka server message storage strategy
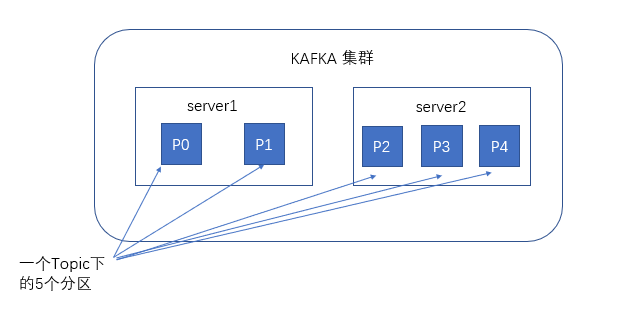
When it comes to kafka storage, we have to mention partitions. When creating a topic, you can specify the number of partitions at the same time. The more partitions, the greater its throughput, but the more resources it requires, which will also lead to higher unavailability. After receiving the messages sent by the producer, kafka will store the messages in different partitions according to the balancing strategy.
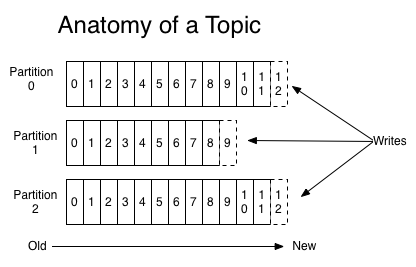
In each partition, messages are stored in order, and the latest received messages will be consumed finally.
message in kafka exists in the form of topic, which is physically divided into many partitions. partition is physically composed of many segment s, which is the real carrier for storing messages.
The following describes the segment file in detail:
(1) Each partition (directory) is equivalent to a giant file, which is evenly distributed into multiple equal size segment data files. However, the number of segment file messages in each segment is not necessarily equal. This feature facilitates the rapid deletion of old segment file.
(2) Each Parton only needs to support sequential reading and writing. The life cycle of the segment file is determined by the server configuration parameters.
(3) segment file: it is composed of two parts, index file and data file. These two files correspond to each other one by one and appear in pairs with the suffix " Index "and". log "are expressed as segment index file and data file respectively
(4) segment file naming rules: the first segment of the global part starts from 0, and the name of each subsequent segment file is the offset value of the last message of the previous segment file. The maximum value is 64 bit long, 19 bit numeric character length, and no number is filled with 0.
The physical structure of the corresponding relationship between index < - > data file in segment is as follows:
Mapping relationship between index and log

. The index file stores the message logical relative offset (relative offset = absolute offset base offset) and the physical location (position) in the corresponding. log file. However, the. Index does not specify the mapping to the physical location for each message, but takes the entry as the unit. Each entry can specify the physical location mapping of n consecutive messages (for example, suppose there are 10 messages ranging from 20000 to 20009, and the. Index file can be configured for each entry
Specify the physical location mapping of 10 consecutive messages. In this example, the index entry will record the message with an offset of 20000 to its physical file location. Once the message is located, 20001 ~ 20009 can be found quickly.). The size of each entry is 8 bytes. The first 4 bytes are the relative offset of the message relative to the first message offset (base offset) of the log segment, and the last 4 bytes are the physical location of the message in the log file.
1.3. 3 interaction with producers
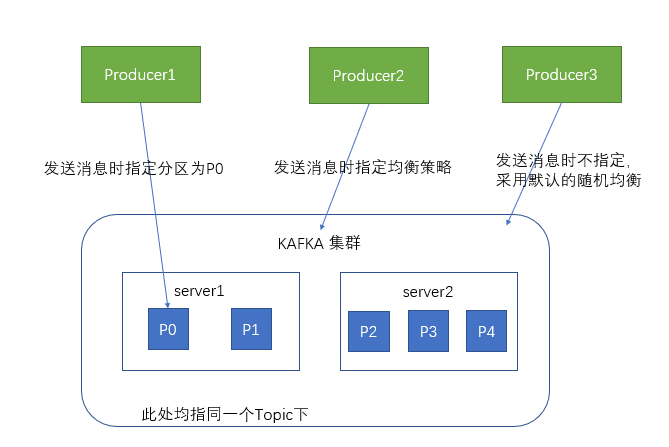
When the producer sends messages to the kafka cluster, it can send them to the specified partition through the specified partition
You can also specify an equalization policy to send messages to different partitions
If not specified, the default random equalization strategy will be adopted to randomly store messages in different partitions
1.3. 4 interaction with consumers
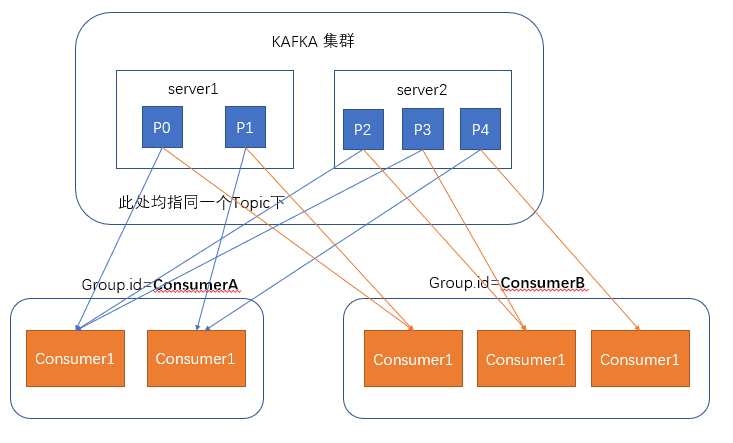
When consumers consume messages, kafka uses offset to record the current consumption location
In the design of kafka, multiple different groups can consume messages under the same topic at the same time. As shown in the figure, we have two different groups consuming messages at the same time. The offset of their consumption record position does not interfere with each other.
For a group, the number of consumers should not exceed the number of partitions, because in a group, each partition can only be bound to one consumer at most, that is, one consumer can consume multiple partitions, and one partition can only be consumed by one consumer
Therefore, if the number of consumers in a group is greater than the number of partitions, the redundant consumers will not receive any messages.
Installation and use of Kafka
2.1. download
You can visit Kafka's official website: http://kafka.apache.org/downloads
Download the latest kafka installation package and choose to download the binary version of tgz file. fq may be required according to the network status. The version we choose here is kafka_2.11-1.1.0, current version
2.2. install
Kafka is a program written in scala and running on the jvm virtual machine. Although it can also be used on windows, Kafka basically runs on the linux server. Therefore, we also use linux to start today's actual combat.
First, make sure that jdk is installed on your machine. kafka needs java running environment. The previous kafka also needs zookeeper. The new kafka has a built-in zookeeper environment, so we can use it directly
For installation, if we only need to make the simplest attempt, we just need to unzip it to any directory. Here, we unzip the kafka compressed package to the / home directory
2.3. to configure
There is a config folder under the kafka decompression directory, which contains our configuration files
consumer.properites consumer configuration. This configuration file is used to configure consumers opened in Section 2.5. Here we can use the default
producer.properties producer configuration. This configuration file is used to configure the producers opened in Section 2.5. Here, we can use the default
server. Properties configuration of kafka server. This configuration file is used to configure kafka server. At present, only a few basic configurations are introduced
-
broker.id indicates the unique ID of the current kafka server in the cluster. It needs to be configured as integer, and the ID of each kafka server in the cluster should be unique. We can use the default configuration here
-
Listeners declare the port number that this kafka server needs to listen to. If it is running a virtual machine on the local machine, you can not configure this item. By default, the address of localhost will be used. If it is running on a remote server, it must be configured, for example: listeners = plaintext: / / 192.168 180.128:9092. And ensure that the 9092 port of the server can be accessed
-
zookeeper.connect declares the address of the zookeeper to which kafka is connected. It needs to be configured as the address of the zookeeper. Since the zookeeper in the higher version of kafka is used this time, the default configuration can be used
zookeeper.connect=localhost:2181
When we have multiple applications that use zookeer in different applications and use the default zk port, the 2181 port conflict will occur. We can set our own port number in the config folder, zookeeper The properties file is modified to
clientPort=2185
That is, the zk open interface is 2185
At the same time, modify the access port of kafka, server The properties file is modified to
zookeeper.connect=localhost:2185
In this way, we have successfully modified the port number in kafka
2.4. function
Start zookeeper
cd enter kafka decompression directory and enter
bin/zookeeper-server-start.sh config/zookeeper.properties
After starting zookeeper successfully, you will see the following output

2. Start kafka
cd enter kafka decompression directory and enter
bin/kafka-server-start.sh config/server.properties
After starting kafka successfully, you will see the following output

2.5. First message
2.5. 1 create a topic
Kafka manages the same kind of data through topic. Using the same topic for the same kind of data can make data processing more convenient
Open the terminal in kafka decompression directory and enter
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Create a topic named test

After creating topic, you can enter
bin/kafka-topics.sh --list --zookeeper localhost:2181
To view the topic that has been created
2.5. 2 create a message consumer
Open the terminal in kafka decompression directory and enter
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
You can create a consumer whose topic is test

After the consumer is created, because no data has been sent, no data is printed out after execution
But don't worry. Don't close this terminal. Open a new terminal. Next, we create the first message producer
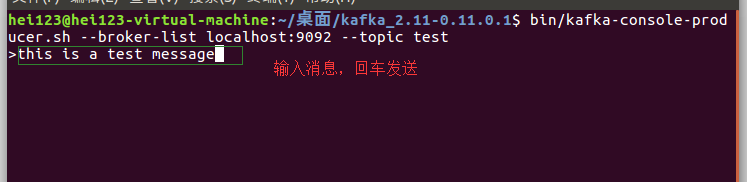
2.5. 3 create a message producer
Open a new terminal in the kafka decompression directory and enter
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
After execution, you will enter the editor page
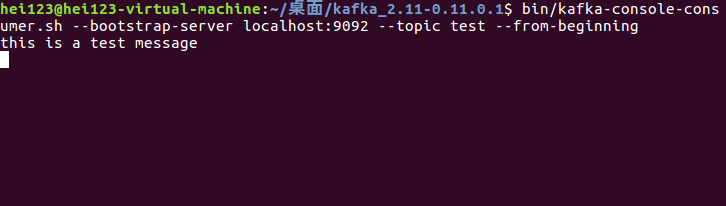
After sending the message, you can go back to our message consumer terminal. You can see that the message we just sent has been printed in the terminal
kafka cleaning up data and topic
1. Delete the kafka storage directory (server.properties file log.dirs configuration, the default is "/ TMP / kafka logs") and the related topic directory
2. Kafka's command to delete topic is:
./bin/kafka-topics --delete --zookeeper [zookeeper server] --topic [topic name]
If the configuration file loaded when kafaka starts is server Properties is not configured with delete topic. If enable = true, the deletion at this time is not the real deletion, but the topic is marked as: marked for deletion
You can command:
./bin/kafka-topics --zookeeper [zookeeper server] --list To see all topic
If you want to delete it, you can do the following:
(1) Log in to zookeeper client: Command:. / bin / zookeeper client
(2) Find the directory where topic is located: ls /brokers/topics
(3) Find the topic to be deleted and execute the command: rmr /brokers/topics / [topic name]. At this time, the topic is completely deleted.
In addition, the topic marked marked for deletion can be obtained through the command LS / admin / delete in the zookeeper client_ topics/[topic name],
If you delete the topic here, the marked for deletion tag will disappear
There is also information about topic in zookeeper's config: ls /config/topics / [topic name] I don't know what use it is for now
Summary:
Completely delete topic:
1. Delete the kafka storage directory (server.properties file log.dirs configuration, the default is "/ TMP / kafka logs") and the related topic directory
2. If delete is configured topic. If enable = true, you can delete it directly through the command. If the command cannot delete it, you can delete the topic under the broker directly through the zookeeper client.
python operation kafka
Now that we know that kafka is a message queue, let's learn how to transfer data to kafka and how to get data from kafka
First install python's kafka library
pip install kafka-python
According to the example on the official website, run an application first
1. Producer demo:
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=['broker1:1234'])
# Asynchronous by default
future = producer.send('my-topic', b'raw_bytes')
# Block for 'synchronous' sends
try:
record_metadata = future.get(timeout=10)
except KafkaError:
# Decide what to do if produce request failed...
log.exception()
pass
# Successful result returns assigned partition and offset
print (record_metadata.topic)
print (record_metadata.partition)
print (record_metadata.offset)
# produce keyed messages to enable hashed partitioning
producer.send('my-topic', key=b'foo', value=b'bar')
# encode objects via msgpack
producer = KafkaProducer(value_serializer=msgpack.dumps)
producer.send('msgpack-topic', {'key': 'value'})
# produce json messages
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii'))
producer.send('json-topic', {'key': 'value'})
# produce asynchronously
for _ in range(100):
producer.send('my-topic', b'msg')
def on_send_success(record_metadata):
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
def on_send_error(excp):
log.error('I am an errback', exc_info=excp)
# handle exception
# produce asynchronously with callbacks
producer.send('my-topic', b'raw_bytes').add_callback(on_send_success).add_errback(on_send_error)
# block until all async messages are sent
producer.flush()
# configure multiple retries
producer = KafkaProducer(retries=5)After startup, the producer can send the byte stream to the kafka server
2. Consumer (simple demo):
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',bootstrap_servers=['127.0.0.1:9092']) #The parameters are receiving subject and kafka server address
# This is a permanent blocking process. Producer messages are cached in the message queue and are not deleted, so each message has an offset in the message queue
for message in consumer: # consumer is a message queue. When there is a message in the background, the message queue will automatically increase. Therefore, there will always be data during traversal. When there is no data in the message queue, it will block waiting for the message
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))After startup, consumers can get data from kafka server
3. Consumer (consumer group)
from kafka import KafkaConsumer
# Using group, only one consumer instance can read data for members of the same group
consumer = KafkaConsumer('test',group_id='my-group',bootstrap_servers=['127.0.0.1:9092'])
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))Start multiple consumers. Only one member can consume. If the requirements are met, the consumption group can expand horizontally to improve the processing capacity
4. Consumer (read the earliest readable message currently)
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',auto_offset_reset='earliest',bootstrap_servers=['127.0.0.1:9092'])
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))auto_offset_reset: reset the offset, move early to the earliest available message, and latest to the latest message. The default is latest
Source code definition: {'smallest': 'early', 'large': 'latest'}
5. Consumer (set offset manually)
# ==========Read the specified location message===============
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
consumer = KafkaConsumer('test',bootstrap_servers=['127.0.0.1:9092'])
print(consumer.partitions_for_topic("test")) #Get partition information of test topic
print(consumer.topics()) #Get a list of topics
print(consumer.subscription()) #Gets the topic of the current consumer subscription
print(consumer.assignment()) #Get the topic and partition information of the current consumer
print(consumer.beginning_offsets(consumer.assignment())) #Gets the offset that the current consumer can consume
consumer.seek(TopicPartition(topic='test', partition=0), 5) #Reset offset, consume from 5th offset
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))6. Consumer (subscribing to multiple topics)
# =======Subscribe to multiple consumers==========
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
consumer = KafkaConsumer(bootstrap_servers=['127.0.0.1:9092'])
consumer.subscribe(topics=('test','test0')) #Subscribe to topics to consume
print(consumer.topics())
print(consumer.position(TopicPartition(topic='test', partition=0))) #Gets the latest offset of the current topic
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))7. Consumer (pull message manually)
from kafka import KafkaConsumer
import time
consumer = KafkaConsumer(bootstrap_servers=['127.0.0.1:9092'])
consumer.subscribe(topics=('test','test0'))
while True:
msg = consumer.poll(timeout_ms=5) #Get message from kafka
print(msg)
time.sleep(2)8. Consumer (message suspend and resume)
# ==============Message recovery and suspension===========
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
import time
consumer = KafkaConsumer(bootstrap_servers=['127.0.0.1:9092'])
consumer.subscribe(topics=('test'))
consumer.topics()
consumer.pause(TopicPartition(topic=u'test', partition=0)) # After pause is executed, the consumer cannot read until resume is called.
num = 0
while True:
print(num)
print(consumer.paused()) #Gets the currently pending consumer
msg = consumer.poll(timeout_ms=5)
print(msg)
time.sleep(2)
num = num + 1
if num == 10:
print("resume...")
consumer.resume(TopicPartition(topic='test', partition=0))
print("resume......")After pause is executed, the consumer cannot read until resume is called.
Here is a complete demo
from kafka import KafkaConsumer
# To consume latest messages and auto-commit offsets
consumer = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers=['localhost:9092'])
for message in consumer:
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
# consume earliest available messages, don't commit offsets
KafkaConsumer(auto_offset_reset='earliest', enable_auto_commit=False)
# consume json messages
KafkaConsumer(value_deserializer=lambda m: json.loads(m.decode('ascii')))
# consume msgpack
KafkaConsumer(value_deserializer=msgpack.unpackb)
# StopIteration if no message after 1sec
KafkaConsumer(consumer_timeout_ms=1000)
# Subscribe to a regex topic pattern
consumer = KafkaConsumer()
consumer.subscribe(pattern='^awesome.*')
# Use multiple consumers in parallel w/ 0.9 kafka brokers
# typically you would run each on a different server / process / CPU
consumer1 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')
consumer2 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')Python creates a custom Kafka Topic
client = KafkaClient(bootstrap_servers=brokers)
if topic not in client.cluster.topics(exclude_internal_topics=True): # Topic does not exist
request = admin.CreateTopicsRequest_v0(
create_topic_requests=[(
topic,
num_partitions,
-1, # replication unset.
[], # Partition assignment.
[(key, value) for key, value in configs.items()], # Configs
)],
timeout=timeout_ms
)
future = client.send(2, request) # 2 is the Controller. The creation of all nodes sent to other nodes failed.
client.poll(timeout_ms=timeout_ms, future=future, sleep=False) # here
result = future.value
# error_code = result.topic_error_codes[0][1]
print("CREATE TOPIC RESPONSE: ", result) # 0 success, 41 NOT_CONTROLLER, 36 ALREADY_EXISTS
client.close()
else: # Topic already exists
print("Topic already exists!")
returnConfiguration of kafka
There are three configuration files under the kafka/config / Directory:
producer.properties
consumer.properties
server.properties
The configuration of kafka is divided into three different configurations: broker (server.properties), producer (producer.properties) and consumer (consumer.properties)
A global configuration of BROKER
The three core configuration brokers id,log.dir,zookeeper.connect .
------------------------------------------- System related ------------------------------------------- ##The unique identifier of each broker in the cluster. It is required to be a positive number. When changing the IP address, do not change the broker ID will not affect consumers broker.id =1 ##The storage address of Kafka data. Multiple addresses are separated by commas. / tmp/kafka-logs-1, / tmp/kafka-logs-2 log.dirs = /tmp/kafka-logs ##The port provided to the client response port =6667 ##The maximum size of the message body, in bytes message.max.bytes =1000000 ## The maximum number of threads that the broker processes messages. Generally, it does not need to be modified num.network.threads =3 ## The number of threads that the broker processes disk IO. The value should be greater than the number of your hard disk num.io.threads =8 ## The number of threads processed by some background tasks, such as deleting expired message files, generally does not need to be modified background.threads =4 ## The maximum number of request queues waiting for IO threads to process. If the number of requests waiting for IO exceeds this value, it will stop accepting external messages. This is a self-protection mechanism queued.max.requests =500 ##If the host address of the broker is set, it will be bound to this address. If not, it will be bound to all interfaces and send one of them to ZK. Generally, it is not set host.name ## If the advertising address is set, it will be provided to producers, consumers and other broker s. How to use it has not been studied advertised.host.name ## The ad address port must be different from the setting in port advertised.port ## Socket send buffer, socket tuning parameter SO_SNDBUFF socket.send.buffer.bytes =100*1024 ## Socket acceptance buffer, socket tuning parameter SO_RCVBUFF socket.receive.buffer.bytes =100*1024 ## The maximum number of socket requests to prevent serverOOM, message Max.bytes must be less than socket request. Max.bytes, which will be overwritten by the specified parameters when topic is created socket.request.max.bytes =100*1024*1024 ------------------------------------------- LOG relevant ------------------------------------------- ## The partition of topic is stored in a pile of segment files. This controls the size of each segment and will be overwritten by the specified parameters when topic is created log.segment.bytes =1024*1024*1024 ## This parameter will be displayed when the log segment does not reach log segment. The size of bytes will also force the creation of a new segment, which will be overwritten by the specified parameters when topic is created log.roll.hours =24*7 ## The log cleaning policy options are: delete and compact are mainly used to process expired data, or the log file reaches the limit, which will be overwritten by the specified parameters when topic is created log.cleanup.policy = delete ## The maximum time of data storage exceeds this time, which will be determined according to the log cleanup. The policy set in the policy handles data, that is, how long the consumer can consume data ## log.retention.bytes and log retention. Any minute that meets the requirements will be deleted and will be overwritten by the specified parameters when topic is created log.retention.minutes=7days Specify how often logs are checked to see if they can be deleted. The default is 1 minute log.cleanup.interval.mins=1 ## Topic maximum file size of each partition. Size limit of a topic = number of partitions * log retention. bytes . - 1 no size limit ## log.retention.bytes and log retention. Any minute that meets the requirements will be deleted and will be overwritten by the specified parameters when topic is created log.retention.bytes=-1 ## Cycle time of file size check, whether to punish log cleanup. Policies set in policy log.retention.check.interval.ms=5minutes ## Enable log compression log.cleaner.enable=false ## Number of threads running log compression log.cleaner.threads =1 ## Maximum size processed during log compression log.cleaner.io.max.bytes.per.second=None ## The cache space for log compression and de duplication. The larger the space, the better log.cleaner.dedupe.buffer.size=500*1024*1024 ## The IO block size used in log cleaning generally does not need to be modified log.cleaner.io.buffer.size=512*1024 ## The expansion factor of hash table in log cleaning generally does not need to be modified log.cleaner.io.buffer.load.factor =0.9 ## Check whether the interval of log cleanup is penalized log.cleaner.backoff.ms =15000 ## The greater the frequency control of log cleaning, the more efficient it means. At the same time, there will be some waste of space, which will be overwritten by the specified parameters when topic is created log.cleaner.min.cleanable.ratio=0.5 ## The maximum retention time for compressed logs is also the maximum time for the client to consume messages, the same as log retention. The difference between minutes is that one controls uncompressed data and the other controls compressed data. It will be overwritten by the specified parameters when topic is created log.cleaner.delete.retention.ms =1day ## The index file size limit of the segment log will be overwritten by the specified parameters when topic is created log.index.size.max.bytes =10*1024*1024 ## After a fetch operation, a certain space is required to scan the latest offset size. The larger the setting, the faster the scanning speed, but also better memory. Generally, this parameter does not need to be ignored log.index.interval.bytes =4096 ## Number of messages accumulated before log file "sync" to disk ## Because disk IO operation is a slow operation, but it is also a necessary means of "data reliability" ## Therefore, the setting of this parameter needs to make a necessary trade-off between "data reliability" and "performance" ## If this value is too large, it will cause a long time for each "fsync" (IO blocking) ## If this value is too small, it will cause more "fsync" times, which also means that the overall client request has a certain delay ## If the physical server fails, messages without fsync will be lost log.flush.interval.messages=None ## Check whether the time interval of curing to the hard disk is required log.flush.scheduler.interval.ms =3000 ## It is not enough to control the disk write timing of messages only through interval ## This parameter is used to control the time interval of "fsync". If the message volume never reaches the threshold, but the time interval from the last disk synchronization ## When the threshold is reached, it will also be triggered log.flush.interval.ms = None ## The retention time of a file after it is cleared in the index generally does not need to be modified log.delete.delay.ms =60000 ## Control the time point of the last solidified hard disk to facilitate data recovery. Generally, it does not need to be modified log.flush.offset.checkpoint.interval.ms =60000 ------------------------------------------- TOPIC relevant ------------------------------------------- ## Whether to allow automatic creation of topic. If false, you need to create topic through the command auto.create.topics.enable =true ## A topic. The number of replication s in the default partition must not be greater than the number of broker s in the cluster default.replication.factor =1 ## If the number of partitions of each topic is not specified during topic creation, it will be overwritten by the specified parameters during topic creation num.partitions =1 example --replication-factor3--partitions1--topic replicated-topic : name replicated-topic There is one partition, and the partition is copied to three broker Come on. ----------------------------------copy(Leader,replicas) relevant ---------------------------------- ## Timeout of socket during communication between partition leader and replica controller.socket.timeout.ms =30000 ## The queue size of messages when the partition leader is synchronized with replica data controller.message.queue.size=10 ## The maximum waiting time for replicas to respond to the partition leader. If it exceeds this time, the replicas will be listed in the ISR (in sync replicas) and considered dead and will not be added to the management replica.lag.time.max.ms =10000 ## If the follower lags behind the leader too much, it will be considered that this follower [or partition dependencies] has expired ## Usually, when the follower communicates with the leader, the message synchronization in replicas will always lag due to network delay or link disconnection ## If there are too many messages, the leader will think that the network delay of this follower is large or the message throughput capacity is limited, and will migrate this replica ## To other follower s ## It is recommended to increase this value in an environment with a small number of broker s or insufficient network replica.lag.max.messages =4000 ##socket timeout between follower and leader replica.socket.timeout.ms=30*1000 ## socket cache size during leader replication replica.socket.receive.buffer.bytes=64*1024 ## The maximum size of data obtained by replicas each time replica.fetch.max.bytes =1024*1024 ## The maximum waiting time for communication between replicas and the leader. If it fails, it will be retried replica.fetch.wait.max.ms =500 ## The minimum data size of the fetch. If the data in the leader that has not been synchronized is less than this value, it will be blocked until the condition is met replica.fetch.min.bytes =1 ## The number of threads copied by the leader. Increasing this number will increase the IO of the follower num.replica.fetchers=1 ## How often each replica checks whether the highest water level is cured replica.high.watermark.checkpoint.interval.ms =5000 ## Whether the controller is allowed to close the broker. If it is set to true, all leader s on this broker will be closed and transferred to other brokers controlled.shutdown.enable =false ## Number of controller shutdown attempts controlled.shutdown.max.retries =3 ## Time interval for each shutdown attempt controlled.shutdown.retry.backoff.ms =5000 ## Automatically balance the allocation policies between broker s auto.leader.rebalance.enable =false ## If the imbalance ratio of the leader exceeds this value, the partition will be rebalanced leader.imbalance.per.broker.percentage =10 ## Time interval to check whether the leader is unbalanced leader.imbalance.check.interval.seconds =300 ## The maximum amount of space that the client retains offset information offset.metadata.max.bytes ----------------------------------ZooKeeper relevant---------------------------------- ##The address of the zookeeper cluster can be multiple, separated by commas, hostname1:port1,hostname2:port2,hostname3:port3 zookeeper.connect = localhost:2181 ## The maximum timeout of ZooKeeper is the heartbeat interval. If it is not reflected, it is considered dead and not easy to be too large zookeeper.session.timeout.ms=6000 ## Connection timeout of ZooKeeper zookeeper.connection.timeout.ms =6000 ## Synchronization between leader and follower in ZooKeeper cluster zookeeper.sync.time.ms =2000 Modification of configuration Some of these configurations can be configured by each topic Replaced by its own configuration, e.g New configuration bin/kafka-topics.sh --zookeeper localhost:2181--create --topic my-topic --partitions1--replication-factor1--config max.message.bytes=64000--config flush.messages=1 Modify configuration bin/kafka-topics.sh --zookeeper localhost:2181--alter --topic my-topic --config max.message.bytes=128000 Delete configuration: bin/kafka-topics.sh --zookeeper localhost:2181--alter --topic my-topic --deleteConfig max.message.bytes
II. CONSUMER configuration
The core configuration is group id,zookeeper.connect
## The group ID to which the Consumer belongs. The broker is based on the group It is very important to use ID to determine whether it is a queue mode or a publish subscribe mode group.id ## If the consumer ID is not set, it will increase automatically consumer.id ## An ID for tracking and investigation, preferably the same as group Same ID client.id = group id value ## For the designation of zookeeper cluster, it can be multiple hostname1: port1, hostname2: port2 and hostname3: port3. The zk configuration must be the same as that of broker zookeeper.connect=localhost:2182 ## The heartbeat timeout of zookeeper. If it exceeds this time, it is considered dead zookeeper.session.timeout.ms =6000 ## Connection waiting time of zookeeper zookeeper.connection.timeout.ms =6000 ## Synchronization time of zookeeper's follower and leader zookeeper.sync.time.ms =2000 ## The processing method when there is no initial offset in zookeeper. smallest: reset to minimum largest: reset to maximum anythingelse: throw an exception auto.offset.reset = largest ## The timeout of the socket. The actual timeout is: max.fetch wait + socket. timeout. ms. socket.timeout.ms=30*1000 ## Accepted cache space size of socket socket.receive.buffer.bytes=64*1024 ##Message size limit obtained from each partition fetch.message.max.bytes =1024*1024 ## Whether to synchronize the offset to zookeeper after consuming the message. When the Consumer fails, it can obtain the latest offset from zookeeper auto.commit.enable =true ## Time interval for automatic submission auto.commit.interval.ms =60*1000 ## Blocks used to process consumption messages. Each block can be equivalent to fetch message. Value in max.bytes queued.max.message.chunks =10 ## When a new consumer is added to the group, it will reblance, and then the consumer of partitions will migrate to the new group ## If a consumer obtains the consumption permission of a partition, it will register with zk ##"Partition Owner registry" node information, but it is possible that the old consumer has not released this node at this time, ## This value is used to control the number of retries of the registered node rebalance.max.retries =4 ## Time interval of each rebalancing rebalance.backoff.ms =2000 ## Time of each leader re-election refresh.leader.backoff.ms ## The minimum data sent by the server to the consumer. If it does not meet this value, it will wait until it meets the value requirements fetch.min.bytes =1 ## If the minimum size (fetch.min.bytes) is not satisfied, the maximum waiting time for a consumer request fetch.wait.max.ms =100 ## An exception is thrown when no message arrives within the specified time. Generally, it does not need to be modified consumer.timeout.ms = -1
III. configuration of PRODUCER
Compare the core configuration: metadata broker. list,request.required.acks,producer.type,serializer.class
## The address where the consumer obtains the message meta information (topics, partitions and replicas). The configuration format is: host1:port1,host2:port2. You can also set a vip outside metadata.broker.list ##Confirmation mode of message ##0: the arrival confirmation of the message is not guaranteed. Just send the message with low delay, but the message will be lost. When a server fails, it is a bit like TCP ##1: Send a message and wait for the leader to receive the confirmation. It has certain reliability ## -1: Send a message and wait for the leader to receive the confirmation and perform the copy operation before returning. This ensures the highest reliability request.required.acks =0 ## Maximum waiting time for message sending request.timeout.ms =10000 ## Cache size of socket send.buffer.bytes=100*1024 ## The serialization method of key, if not set, is the same as that of serializer class key.serializer.class ## The default partition policy is module partitioner.class=kafka.producer.DefaultPartitioner ## The compression mode of messages is none by default. gzip and snappy can be used compression.codec = none ## Compression can be performed for dictating specific topic s compressed.topics=null ## Number of retries after message sending failure message.send.max.retries =3 ## Interval after each failure retry.backoff.ms =100 ## The time interval for the producer to regularly update the topic meta information. If it is set to 0, the data will be updated after each message is sent topic.metadata.refresh.interval.ms =600*1000 ## The user can specify it at will, but it cannot be repeated. It is mainly used to track and record messages client.id="" ------------------------------------------- Message mode correlation ------------------------------------------- ## Producer type async: send asynchronous execution message sync: send synchronous execution message producer.type=sync ## In asynchronous mode, messages will be cached at the set time and sent at one time queue.buffering.max.ms =5000 ## Maximum number of messages waiting in asynchronous mode queue.buffering.max.messages =10000 ## In asynchronous mode, if the waiting time for entering the queue is set to 0, then either enter the queue or discard it directly queue.enqueue.timeout.ms = -1 ## In asynchronous mode, the maximum number of messages sent each time, provided that the queue is triggered buffering. Max.messages or queue buffering. Max.ms limit batch.num.messages=200 ## The serialization processing class of the message body is transformed into a byte stream for transmission serializer.class= kafka.serializer.DefaultEncoder
reference resources:
https://www.cnblogs.com/hei12138/p/7805475.html
https://blog.csdn.net/zt3032/article/details/78756293
https://kafka-python.readthedocs.io/en/master/index.html
The article is finally published in this article link: https://blog.csdn.net/luanpeng825485697/article/details/81036028