1, Prepare
Ensure that JDK and zookeeper services have been built on the server;
If the construction is not completed, please refer to the following articles:
Installing zookeeper: https://blog.csdn.net/xuan_lu/article/details/120474451
Installation of JDK1.8: https://blog.csdn.net/xuan_lu/article/details/107297710
kafka official website: https://www.apache.org/dyn/closer.cgi?path=/kafka/2.2.0/kafka_2.11-2.2.0.tgz
Click to download the installation package
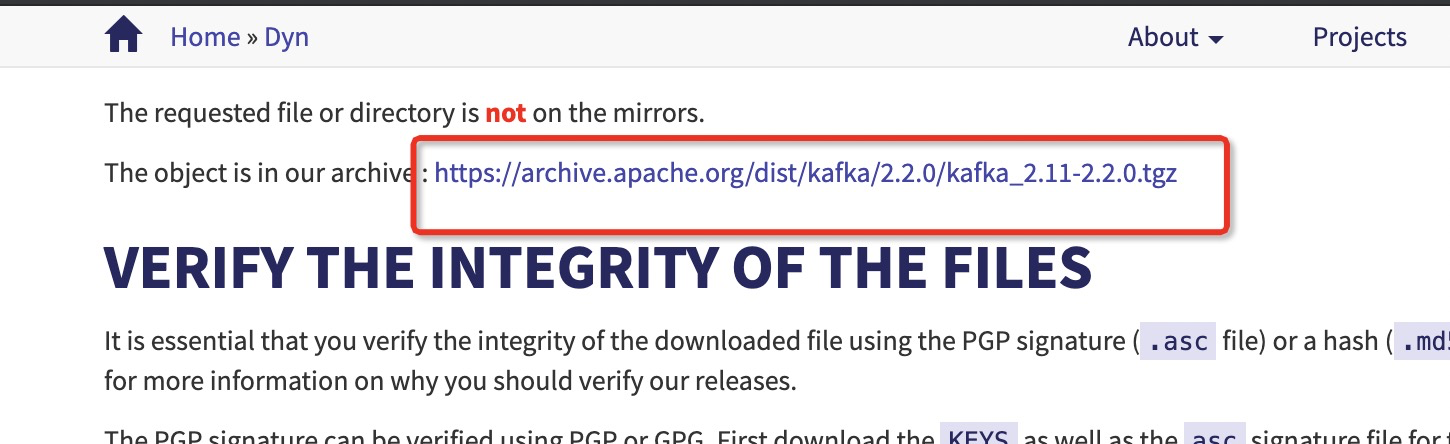
2, Installation and configuration
-
Decompression: tar -zxvf kafka_2.11-2.2.0.tgz
-
Renaming: mv kafka_2.11-2.2.0 kafka
-
Create a logs file to store kafka logs:
Create MKDIR kafka logs in the kafka installation directory
/opt/software/kafka/kafka-logs -
Modify the server.properties configuration file
- Modify log storage directory:
log.dirs=/opt/software/kafka/kafka-logs - Modify or determine the zookeeper address and port:
zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=6000 - Modify broker.id
broker.id=1
3, Detailed description of configuration file
#The unique identifier of a broker in the cluster. It is required to be a positive number. Changing the IP address without changing the broker.id will not affect consumers broker.id=1 #listeners=PLAINTEXT://:9092 #advertised.listeners=PLAINTEXT://your.host.name:9092 #listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SS # The maximum number of threads that the broker processes messages. Generally, it does not need to be modified num.network.threads=3 # The number of threads that the broker processes disk IO. The value should be greater than the number of your hard disk num.io.threads=8 # Send buffer of socket (SO_SNDBUF) socket.send.buffer.bytes=102400 # Receive buffer of socket (SO_RCVBUF) socket.receive.buffer.bytes=102400 # The maximum number of bytes requested by the socket. To prevent memory overflow, message.max.bytes must be less than socket.request.max.bytes=104857600 #The storage address of Kafka data. Multiple addresses are separated by commas. / tmp/kafka-logs-1, / tmp/kafka-logs-2 log.dirs=/opt/software/kafka/kafka-logs # The number of partitions per topic. More partitions will produce more segment file s num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 # When the following number of messages is reached, the data will be flush ed into the log file. Default 10000 #log.flush.interval.messages=10000 # When the following time (ms) is reached, a forced flush operation is performed. No matter which one reaches interval.ms and interval.messages, it will flush. Default 3000ms #log.flush.interval.ms=1000 # The log saving time (hours|minutes) is 7 days (168 hours) by default. After this time, the data will be processed according to the policy. bytes and minutes will be triggered whichever comes first. log.retention.hours=168 #log.retention.bytes=1073741824 # Controls the size of the log segment file. If the size is exceeded, it will be appended to a new log segment file (- 1 means there is no limit) log.segment.bytes=1073741824 # Check the cycle of log fragment files to see if they meet the deletion policy settings (log.retention.hours or log.retention.bytes) log.retention.check.interval.ms=300000 # Zookeeper quorum setting. If more than one is separated by commas, for example, IP: prot, IP: prot zookeeper.connect=localhost:2181 # Timeout for connection zk zookeeper.connection.timeout.ms=6000 # Actual synchronization between leader and follower in ZooKeeper cluster group.initial.rebalance.delay.ms=0
4, Run
1. Start zookeeper service
Since the zookeeper service has been started on the Xiaobian server, it is not necessary to re execute the start command;
If the server zookeeper service is not started, execute the following command in the kafka Directory:
Start the single node Zookeeper instance using the script in the installation package:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
Note: the following commands can be executed in the kafka installation root directory;
2. Start kafka service
Choose one of the following methods
- kafka directory startup
Use kafka-server-start.sh to start the Kafka service:
bin/kafka-server-start.sh config/server.properties
This command execution is not run by the background process, so use the following command
bin/kafka-server-start.sh -daemon config/server.properties - The command needs to switch to kafka's bin directory,
./kafka-server-start.sh -daemon /opt/software/kafka//config/server.properties
3. Create topic
Use kafka-topics.sh to create topic test for single partition and single copy:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test

4. View topic
bin/kafka-topics.sh --list --zookeeper localhost:2181

5. Generate message: kafka-console-producer.sh
Send messages using kafka-console-producer.sh
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test

Use Ctrl+C to exit the generated message;
6. Consumption news: kafka-console-consumer.sh
Use kafka-console-consumer.sh to receive messages and print them on the terminal
Bin / kafka-console-consumer.sh -- zookeeper localhost: 2181 -- topic test -- from beginning
It should be noted that the above command is used for the lower version of kafka, otherwise an error will be reported. The higher version of kafka installed by Xiaobian will report an error, so replace it with the following command:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning

7. View description Topic information
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test

explain:
The first row gives a summary of all partitions, and each additional row gives information about a partition. Since we have only one partition, we have only one row.
Leader: is the node responsible for all reads and writes of a given partition. Each node will become the leader of the randomly selected part of the partition.
Replicas: is the list of nodes that replicate the logs of this partition, whether they are leaders or not, or even if they are currently active.
Isr: is a set of synchronized replicas. This is a subset of the replica list that is currently alive and guided to the leader.
8. Delete topic
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test

Reference resources:
1.Installing Kafka on CentOS 7
https://cloud.tencent.com/developer/article/1388439