zookeeper
introduce
zookeeper: provide coordination service for distributed framework, file system + notification mechanism
-
Working mechanism
The distributed service management framework designed based on the observer mode is responsible for storing and managing the data everyone cares about, and then accepting the registration of observers. Once the state of these data changes, Zookeeper will be responsible for notifying those observers who have registered on Zookeeper to respond accordingly
-
characteristic
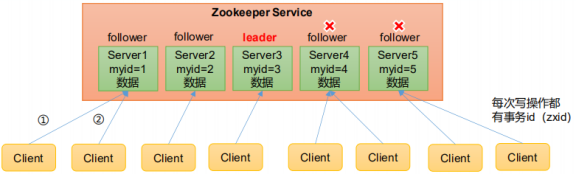
1) Zookeeper: a cluster composed of one Leader and multiple followers.
2) . if more than half of the nodes in the cluster survive, the cluster can serve normally. Therefore, Zookeeper is suitable for installing an odd number of servers.
3) Global data consistency: each Server saves a copy of the same data. When the Client connects to any Server, the data is consistent.
4) The update requests are executed in sequence, and the update requests from the same Client are executed in sequence according to their sending order.
5) . data update is atomic. A data update either succeeds or fails.
6) . real time. Within a certain time range, the Client can read the latest data. -
data structure
The structure of ZooKeeper data model is very similar to that of Unix file system. On the whole, it can be regarded as a tree, and each node is called a ZNode. Each ZNode can store 1MB of data by default, and each ZNode can be uniquely identified through its path.
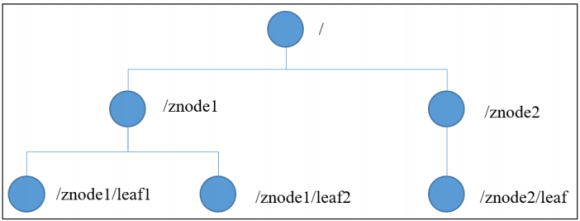
-
Application scenario
The services provided include: unified naming service, unified configuration management, unified cluster management, dynamic uplink and downlink of server nodes, soft load balancing, etc.
1) Unified naming service
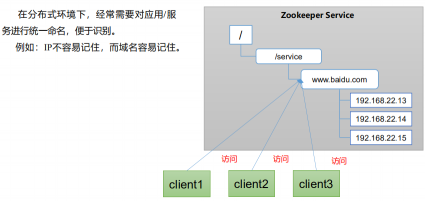
2) Unified configuration management
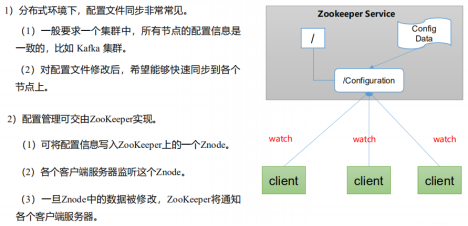
3) Unified cluster management
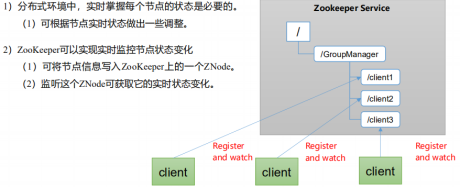
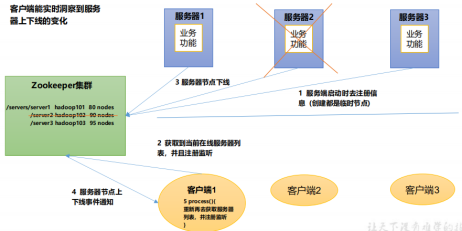
4) . server nodes dynamically go online and offline
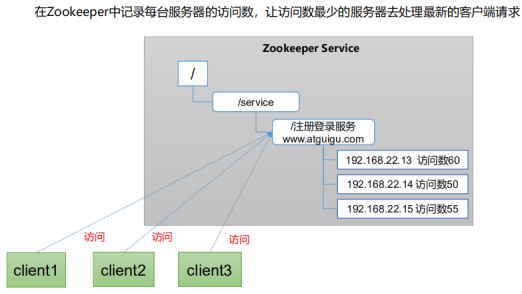
5) . soft load balancing
-
Election mechanism
First start
1) Server 1 starts and initiates an election. Server 1 voted for itself. At this time, server 1 has one vote, less than half (3 votes), the election cannot be completed, and the state of server 1 remains LOOKING;
2) Server 2 starts and initiates another election. Servers 1 and 2 vote for themselves and exchange vote information respectively: at this time, server 1 finds that the myid of server 2 is larger than that of server 1, and changes the vote to recommend server 2. At this time, there are 0 votes for server 1 and 2 votes for server 2. Without more than half of the results, the election cannot be completed, and the status of server 1 and 2 remains LOOKING
3) Server 3 starts and initiates an election. Both servers 1 and 2 change to server 3. The voting results: 0 votes for server 1, 0 votes for server 2 and 3 votes for server 3. At this time, server 3 has more than half of the votes, and server 3 is elected Leader. The status of server 1 and 2 is changed to FOLLOWING, and the status of server 3 is changed to LEADING;
4) Server 4 starts and initiates an election. At this time, servers 1, 2 and 3 are no longer in the voting state and will not change the vote information. Result of exchange of ballot information: server 3 has 3 votes and server 4 has 1 vote. At this time, server 4 obeys the majority, changes the vote information to server 3, and changes the status to FOLLOWING;
5) Server 5 starts up and becomes a younger brother like 4.Not the first start
1) When one of the following two situations occurs to a server in the ZooKeeper cluster, it will start to enter the Leader election
• server initialization starts.
• unable to maintain connection with the Leader while the server is running.2) When a machine enters the Leader election process, the current cluster may also be in the following two states:
• a Leader already exists in the cluster.
If there is already a Leader, when the machine tries to elect a Leader, it will be informed of the Leader information of the current server. For this machine, it only needs to establish a connection with the Leader machine and synchronize the status.• there is no Leader in the cluster.
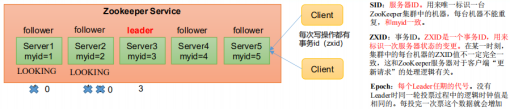
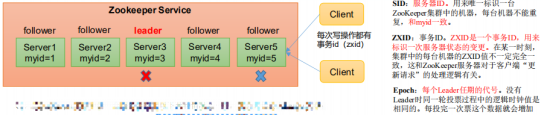
Suppose ZooKeeper consists of five servers,
SID is 1, 2, 3, 4 and 5 respectively,
ZXID is 8, 8, 8, 7 and 7 respectively,
And the server with SID 3 is the Leader.
At some point, the 3 and 5 servers failed, so the Leader election began.
Voting of machines with SID 1, 2 and 4: (1, 8, 1) (1, 8, 2) (1, 7, 4)
(EPOCH,ZXID,SID )
Election Leader rules:
① EPOCH big direct winner
② The same as EPOCH, the one with a large transaction id wins
③ If the transaction id is the same and the server id is larger, the winner will win -
Listener principle

1) First, there must be a main() thread
2) Create a Zookeeper client in the main thread. At this time, two threads will be created,
One is responsible for network connection communication (connect),
One is responsible for listening
3) Send the registered listening event to Zookeeper through the connect thread.
4) Add the registered listening events to the list in the list of registered listeners of Zookeeper.
5) Zookeeper will send this message to the listener thread when it detects data or path changes.
6) The process() method was called inside the listener thread. -
Process role
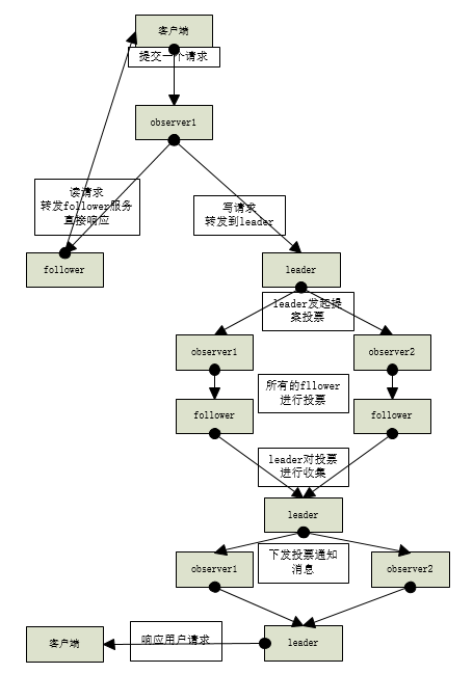
Leader: accept all follower requests and uniformly coordinate to launch voting; Be responsible for all internal data exchange of follower and all write related operations
Follower: serve the client, participate in the voting of the proposal, exchange data with the leader, read and respond to the leader's proposal
Observer: additional voting without participating in the proposal; Exchange data with the leader, receive the client request, and forward the write request to the leader, but the leader will not require observer to vote
deploy
#It starts from 3 nodes by default and is installed on 3 node nodes
-
All zookeeper node machines are installed
for i in 54 55 56; do scp apache-zookeeper-3.6.3-bin.tar.gz root@192.168.10.$i:/data/; done tar -xvf /data/apache-zookeeper-3.6.3-bin.tar.gz -C /data/ mv /data/apache-zookeeper-3.6.3-bin/ /data/zookeeper-3.6.3/
-
Add environment variables to all zookeeper node machines
vim /etc/profile.d/my_env.sh #Add ZK_HOME export ZK_HOME=/data/zookeeper-3.6.3 export PATH=$PATH:$ZK_HOME/bin source /etc/profile
-
Modify configuration files for all zookeeper node machines
cd /data/zookeeper-3.6.3/conf/ cp -p zoo_sample.cfg zoo.cfg vim zoo.cfg # Response milliseconds tickTime=2000 # Number of connections required for initial synchronization initLimit=10 #Number of connections required for transmission synchronization syncLimit=5 #Directory where snapshots are stored dataDir=/data/zookeeper-3.6.3/data/tmp #The port to which the client will connect clientPort=2181 #Number of client connections #maxClientCnxns=60 #Number of snapshots retained in dataDir #autopurge.snapRetainCount=3 #Clear task interval h, set to "0" to disable the automatic clearing function #autopurge.purgeInterval=1 #Finally add server.1=1 Node host ip:2888:3888 server.2=2 Node host ip:2888:3888 server.3=3 Node host ip:2888:3888
vim /data/zookeeper-3.6.3/bin/zkEnv.sh #Add first line JAVA_HOME=/opt/jdk1.8.0_212
-
Create storage folder
mkdir -p /data/zookeeper-3.6.3/data/tmp
-
#Create a myid file. The id must be the server corresponding to the host name in the configuration file (id) consistent
1 Execute on node host echo 1 > /data/zookeeper-3.6.3/data/tmp/myid 2 Execute on node host echo 2 > /data/zookeeper-3.6.3/data/tmp/myid 3 Execute on node host echo 3 > /data/zookeeper-3.6.3/data/tmp/myid
-
All zookeeper node machines start the service
#The command starts separately #start-up /data/zookeeper-3.6.3/bin/zkServer.sh start #View status /data/zookeeper-3.6.3/bin/zkServer.sh status #stop it /data/zookeeper-3.6.3/bin/zkServer.sh stop
#Configure startup service vim /usr/lib/systemd/system/zookeeper.service [Unit] Description=zookeeper After=network.target ConditionPathExists=/data/zookeeper-3.6.3/conf/zoo.cfg [Service] Type=forking Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/jdk1.8.0_212/bin" ExecStart=/data/zookeeper-3.6.3/bin/zkServer.sh start ExecReload=/data/zookeeper-3.6.3/bin/zkServer.sh restart ExecStop=/data/zookeeper-3.6.3/bin/zkServer.sh stop User=root Group=root [Install] WantedBy=multi-user.target systemctl daemon-reload systemctl start zookeeper.service systemctl status zookeeper.service systemctl enable zookeeper.service
-
connect:
/data/zookeeper-3.6.3/bin/zkCli.sh
use
-
connect
/data/zookeeper-3.4.13/bin/zkCli.sh -server hadoop102:2181
-
monitor
#Monitor changes in node data get -w /sanguo #Listen for changes in the increase or decrease of child nodes ls -w /sanguo
-
Historical service
history
-
Create node
create [-s -e] /sanguo/weiguo/zhangliao "zhangliao" -s Containing sequence -e Temporary (client disconnected, node deleted)
-
delete
#Delete node delete [-v] path #Delete multiple nodes on a path deleteall path
-
Modify the specific value of the setting node
set /sanguo/weiguo "simayi"
-
see
#Get the value of the node get -s /sanguo #Content included ls / #Detailed data of current node ls -s / #czxid: create the transaction zxid of the node #ctime: the number of milliseconds that znode was created (since 1970) #mzxid: transaction zxid last updated by znode #mtime: the number of milliseconds znode was last modified (since 1970) #pZxid: the last updated child node zxid of znode #cversion: change number of znode child node and modification times of znode child node #Data version: znode data change number #aclVersion: change number of znode access control list #Ephemeral owner: if it is a temporary node, this is the session id of the znode owner. 0 if it is not a temporary node. #dataLength: the data length of znode #numChildren: number of child nodes of znode
kafka
introduce
-
advantage
1) Decoupling: it allows you to independently extend or modify the processing processes on both sides, as long as they comply with the same interface constraints.
2) Redundancy: message queues persist data until they have been completely processed, thus avoiding the risk of data loss. In the "insert get delete" paradigm adopted by many message queues, before deleting a message from the queue, your processing system needs to clearly indicate that the message has been processed, so as to ensure that your data is safely saved until you use it.
3) Scalability: because the message queue decouples your processing process, it is easy to increase the frequency of message queuing and processing, as long as you add another processing process.
4) , flexibility & peak processing capacity: applications still need to continue to play a role in the case of a sharp increase in traffic, but such sudden traffic is not common. It is undoubtedly a waste of resources to deal with this kind of access at any time. Using message queuing enables key components to withstand the sudden access pressure without completely crashing due to sudden overloaded requests.
5) . recoverability: failure of some components of the system will not affect the whole system. Message queuing reduces the coupling between processes, so even if a process processing messages hangs, the messages added to the queue can still be processed after the system recovers.
6) Sequence guarantee: in most usage scenarios, the sequence of data processing is very important. Most message queues are sorted and can ensure that the data will be processed in a specific order. (Kafka guarantees the order of messages in a Partition)
7) Buffer: it helps to control and optimize the speed of data flow through the system and solve the inconsistency between the processing speed of production messages and consumption messages.
8) Asynchronous communication: many times, users do not want or need to process messages immediately. Message queuing provides an asynchronous processing mechanism that allows users to put a message on the queue without processing it immediately. Put as many messages into the queue as you want, and then process them when needed. -
consumption pattern
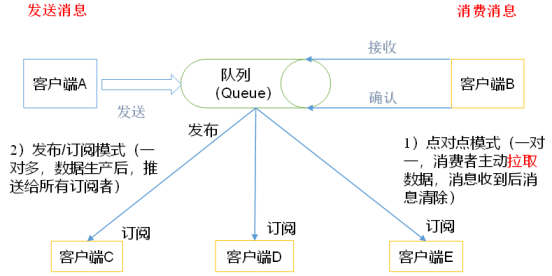
1) . point to point mode (one-to-one, consumers actively pull data, and the message is cleared after receiving the message)
The peer-to-peer model is usually a message delivery model based on pull or polling. This model requests information from the queue rather than pushing the message to the client. The characteristic of this model is that the messages sent to the queue are received and processed by one and only one receiver, even if there are multiple message listeners.
2) . publish / subscribe mode (one to many, push to all subscribers after data production)
The publish subscribe model is a push based messaging model. The publish subscribe model can have many different subscribers. Temporary subscribers only receive messages when they actively listen to the topic, while persistent subscribers listen to all messages of the topic, even if the current subscriber is unavailable and offline. -
Architecture and roles
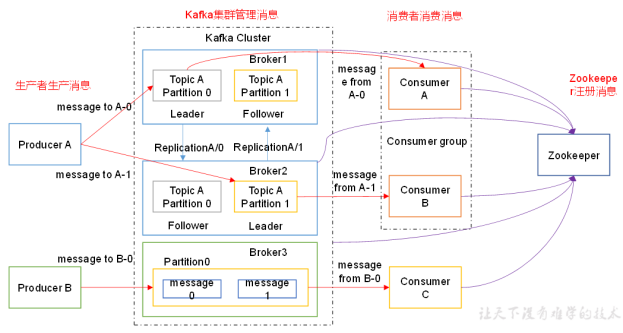
role
Producer: Message producer, which is the client that sends messages to kafka broker;Consumer: the message consumer, the client that fetches messages from kafka broker;
Consumer Group (CG): This is kafka's method to broadcast (to all consumers) and unicast (to any consumer) a topic message. A topic can have multiple CGS. The message of topic will be copied (not really, but conceptually) to all CG, but each part will only send the message to one consumer in the CG. If you need to implement broadcasting, as long as each consumer has an independent CG. To achieve unicast, as long as all consumers are in the same CG. CG can also group consumers freely without sending messages to different topics for many times;
Broker: a server is a broker. A cluster consists of multiple brokers. A broker can accommodate multiple topic s
Topic: it can be understood as a queue;
Partition: it is equivalent to the extensibility load of topic. A very large topic can be distributed to multiple broker s (i.e. servers). A topic can be divided into multiple partitions, and each partition is an orderly queue. Each message in the partition is assigned an ordered id (offset). kafka only guarantees to send messages to consumer s in the order of one partition, and does not guarantee the order of a topic as a whole (among multiple partitions);
Offset: the stored files of Kafka are based on offset Kafka. The advantage of using offset as the name is convenient to find. For example, if you want to find a location in 2049, just find 2048 Kafka file. Of course, the first offset is 00000000000 kafka.
deploy
-
Installation package (on slave1, slave2 and slave3)
for i in 54 55 56; do scp kafka_2.12-2.7.0.tgz root@192.168.10.$i:/data/; done tar -xvf /data/kafka_2.12-2.7.0.tgz -C /data/ mv /data/kafka_2.12-2.7.0 /data/kafka
-
Add environment variables (on slave1, slave2 and slave3)
vim /etc/profile.d/my_env.sh #Add KAFKA_HOME export KAFKA_HOME=/data/kafka export PATH=$PATH:$KAFKA_HOME/bin source /etc/profile
-
Modify the configuration file (on slave1, slave2 and slave3)
vim /data/kafka/config/server.properties #id of the agent broker.id=host ip last digits of a number #Log path log.dirs=/data/kafka/logs #zookeeper cluster address zookeeper.connect=slave1-zookeeperIp:2181,slave2-zookeeperIp:2181,slave3-zookeeperIp:2181 #Allow to delete topic delete.topic.enable=true
-
Start (on slave1, slave2 and slave3)
#Configure startup service vim /usr/lib/systemd/system/kafka.service [Unit] Description=kafka After=network.target [Service] Type=forking Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/jdk1.8.0_212/bin" WorkingDirectory=/data/kafka ExecStart=/data/kafka/bin/kafka-server-start.sh -daemon /data/kafka/config/server.properties ExecStop=/data/kafka/bin/kafka-server-stop.sh -daemon /data/kafka/config/server.properties User=root Group=root [Install] WantedBy=multi-user.target systemctl daemon-reload systemctl start kafka.service systemctl status kafka.service systemctl enable kafka.service
-
View roles (on slave1, slave2 and slave3)
jps
-
Verification (just operate on slave1)
#Create a topic cd /data/kafka_2.12-2.6.2/ ./bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --zookeeper slave3:2181 --topic aa #Simulate producers and release messages cd /data/kafka_2.12-2.6.2/ ./bin/kafka-console-producer.sh --broker-list slave2:9092 --topic aa #Simulate consumers and receive messages cd /data/kafka_2.12-2.6.2/ ./bin/kafka-console-consumer.sh --bootstrap-server slave1:9092 --topic aa
use
-
Create topic
bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first #Option Description: --topic definition topic name --replication-factor Define the number of copies --partitions Define the number of partitions
-
Delete topic
bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first #Server is required Set delete in properties topic. Enable = true, otherwise it is just marked for deletion or direct restart.
-
send message
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first >hello world >atguigu atguigu
-
Consumption news
bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --from-beginning --topic first #--From beginning: all previous data in the first topic will be read out. Select whether to add the configuration according to the business scenario.
-
see
#View all topic s in the current server bin/kafka-topics.sh --zookeeper hadoop102:2181 --list #View the details of a Topic bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
EFAk monitoring installation
Monitoring installation (any node installation)
-
Extract to local
tar -zxvf kafka-eagle-bin-2.0.8.tar.gz -C /data/ cd /data/kafka-eagle-bin-2.0.8 tar -xvf efak-web-2.0.8-bin.tar.gz -C /data/ mv /data/efak-web-2.0.8/ /data/efak-web rm -rf /data/kafka-eagle-bin-2.0.8
-
Add environment variable
vim /etc/profile.d/my_env.sh #Add KE_HOME export KE_HOME=/data/efak-web export PATH=$PATH:$KE_HOME/bin source /etc/profile
-
Modify profile
vim /data/efak-web/conf/system-config.properties #Monitoring multiple clusters efak.zk.cluster.alias=cluster1,cluster2 cluster1.zk.list=zookeeper1IP:2181,zookeeper2IP:2181,zookeeper3IP:2181 #cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181 #web interface access port efak.webui.port=8048 # kafka offset storage location cluster1.efak.offset.storage=kafka #cluster2.efak.offset.storage=zk # kafka icon monitoring, 15 days by default efak.metrics.charts=true efak.metrics.retain=15 #sqlite storage of kafka source data information #efak.driver=org.sqlite.JDBC #efak.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db #efak.username=root #efak.password=www.kafka-eagle.org # kafka sasl authenticate cluster1.efak.sasl.enable=false cluster1.efak.sasl.protocol=SASL_PLAINTEXT cluster1.efak.sasl.mechanism=SCRAM-SHA-256 cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-eagle"; cluster1.efak.sasl.client.id= cluster1.efak.blacklist.topics= cluster1.efak.sasl.cgroup.enable=false cluster1.efak.sasl.cgroup.topics= #cluster2.efak.sasl.enable=false #cluster2.efak.sasl.protocol=SASL_PLAINTEXT #cluster2.efak.sasl.mechanism=PLAIN #cluster2.efak.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="kafka-eagle"; #cluster2.efak.sasl.client.id= #cluster2.efak.blacklist.topics= #cluster2.efak.sasl.cgroup.enable=false #cluster2.efak.sasl.cgroup.topics= # kafka ssl authenticate #cluster3.efak.ssl.enable=false #cluster3.efak.ssl.protocol=SSL #cluster3.efak.ssl.truststore.location= #cluster3.efak.ssl.truststore.password= #cluster3.efak.ssl.keystore.location= #cluster3.efak.ssl.keystore.password= #cluster3.efak.ssl.key.password= #cluster3.efak.ssl.endpoint.identification.algorithm=https #cluster3.efak.blacklist.topics= #cluster3.efak.ssl.cgroup.enable=false #cluster3.efak.ssl.cgroup.topics= #mysql storage of kafka source data information efak.driver=com.mysql.cj.jdbc.Driver efak.url=jdbc:mysql://127.0.0.1:3306/efakweb?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull efak.username=efakweb efak.password=efakweb
-
start-up
/data/efak-web/bin/ke.sh start /data/efak-web/bin/ke.sh stop
-
visit
http://192.168.9.102:8048/ke
admin/123456
Like the pro can focus on praise comments Oh! It will be updated every day in the future! This article is a small original article; The files and installation packages used in the article can be obtained by adding the contact information of Xiaobian;
Welcome to exchange the contact information of Xiaobian VX: cxklittlebroth to enter the operation and maintenance exchange group