Consumer groups and consumers
- Consumer groups and consumers are one-to-many relationships.
- Consumers in the same consumer group can consume multiple zones and are exclusive.
- The partition allocation policy for consumers is defined by the interface PartitionAssignor, which has three built-in allocation policies, RangeAssignor, RoundRobinAssignor, StickyAssignor, to support custom policies.
- Different consumer groups can consume the same zones without interruption.
Consumer Coordinator and Group Coordinator
- Consumer Coordinator on the client side and Group Coordinator on the server side keep communicating through the heartbeat.
- Consumers need to make sure that the coordinator is read before they consume.
- Select the node Node with the fewest requests, that is, the node with the fewest InFlightRequests.
- A request to get a coordinator node is sent to this node, and the sending process is similar to sending a pull request.
- A request to join a group is sent to the found coordinator node, where the heartbeat thread is disabled.
- Join the group response processor JoinGroupResponseHandler to process the response, which includes generationId, memberId, leaderId, protocol.
- If it is a leader consumer, that is, memberId=leaderId, the partition allocation needs to be calculated based on the allocation policy protocol.
- Encapsulate the partition allocation results into a synchronization group request and send the synchronization group request to the coordinator node.
- The Sync Group Response Processor SyncGroupResponseHandler handles the response to the above request.
- If Step 5 determines that it is not a follower consumer, it is also necessary to send a synchronization group request to the coordinator, but instead of encapsulating the partition allocation results, it is obtained from the group coordinator.
- Start the heartbeat thread after joining the group successfully.
- Update the partition allocation for the local cache, where the consumer rebalance listener is invoked.
Consumer Status
- UNJOINED: The initial state of the consumer is UNJOINED, indicating that the consumer is not in the consumption group.
- REBALANCING: The status changes to REBALANCING to indicate rebalancing before the consumer sends a request to the coordinator to join the group
- STABLE: The consumer listens on the message and returns successfully. The state changes to STABLE, indicating a stable state. If the message fails, the state is reset to UNJOINED
Heartbeat Threads
- When a consumer joins a consumer group, a heartbeat thread is started and communication with the group coordinator is maintained.
- If the consumer state is not STABLE, no heartbeat is sent.
- If the group coordinator is unknown, wait for a period of time to try again.
- If the heartbeat session times out, the marker coordinator node is unknown.
- If heartbeat polling times out, send a request to leave the group.
- If you do not need to send a heartbeat at this time, wait for a period of time to try again.
- Send a heartbeat, register the response listener, set the receive time after receiving the response, and make the next heartbeat.
Offset
Pull offset
- If a partition is specified, the consumer coordinator pulls a mapping relationship between a set of partitions and submitted offsets from the group coordinator and caches them to SubscriptionState.
- Set offset reset policy: LATEST, EARLIEST,NONE.
- Updates the offset location of consumption asynchronously.
Submit Offset
- Consumer Coordinator gets the current coordinator node.
- Send a submit offset request to this node and return to Future.
Join Group Process
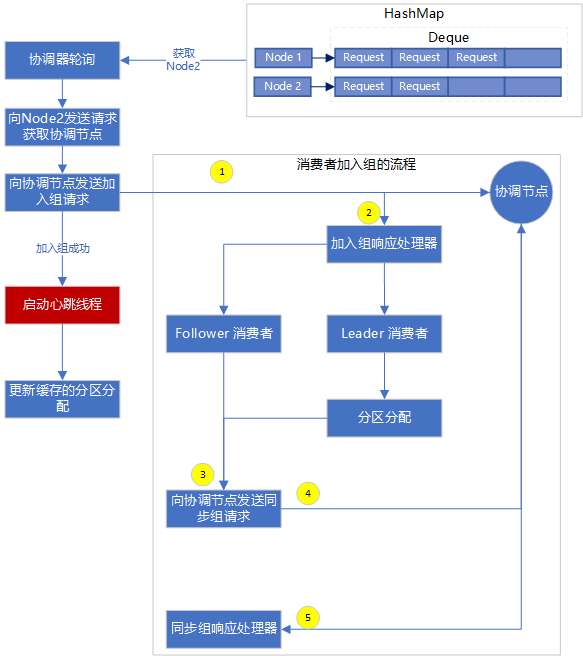
Source Code Analysis of Consumer Joining Group Process
boolean updateAssignmentMetadataIfNeeded(final long timeoutMs) {
final long startMs = time.milliseconds();
if (!coordinator.poll(timeoutMs)) { // Get Coordinator
return false;
}
// Update Offset
return updateFetchPositions(remainingTimeAtLeastZero(timeoutMs, time.milliseconds() - startMs));
}
// Get Coordinator
public boolean poll(final long timeoutMs) {
final long startTime = time.milliseconds();
long currentTime = startTime;
long elapsed = 0L;
if (subscriptions.partitionsAutoAssigned()) { // Is Auto-Assign Theme Type
// Update last polling time for heartbeat
pollHeartbeat(currentTime);
if (coordinatorUnknown()) { // Coordinator unknown
// Ensure coordinator is ready
if (!ensureCoordinatorReady(remainingTimeAtLeastZero(timeoutMs, elapsed))) {
return false;
}
}
if (rejoinNeededOrPending()) { // Need to join consumption group
// Join group, synchronize group
if (!ensureActiveGroup(remainingTimeAtLeastZero(timeoutMs, elapsed))) {
return false;
}
currentTime = time.milliseconds();
}
} else { // Specify partition type
if (metadata.updateRequested() && !client.hasReadyNodes(startTime)) {// If there are no ready nodes
// Blocking waiting for metadata updates
final boolean metadataUpdated = client.awaitMetadataUpdate(remainingTimeAtLeastZero(timeoutMs, elapsed));
if (!metadataUpdated && !client.hasReadyNodes(time.milliseconds())) {
return false; // Failed to update metadata
}
currentTime = time.milliseconds();
}
}
maybeAutoCommitOffsetsAsync(currentTime); // Asynchronous Autocommit Offset
return true;
}
// Ensure coordinator is ready
protected synchronized boolean ensureCoordinatorReady(final long timeoutMs) {
final long startTimeMs = time.milliseconds();
long elapsedTime = 0L;
while (coordinatorUnknown()) { // If the coordinator is unknown
final RequestFuture<Void> future = lookupCoordinator(); // Send a request for a coordinator to the node with the fewest queues for current requests
client.poll(future, remainingTimeAtLeastZero(timeoutMs, elapsedTime));
if (!future.isDone()) {
break; // Response incomplete, exit
}
}
return !coordinatorUnknown();
}
// Join group, synchronize group
boolean ensureActiveGroup(long timeoutMs, long startMs) {
startHeartbeatThreadIfNeeded(); // Start Heartbeat Thread
return joinGroupIfNeeded(joinTimeoutMs, joinStartMs);
}
boolean joinGroupIfNeeded(final long timeoutMs, final long startTimeMs) {
long elapsedTime = 0L;
while (rejoinNeededOrPending()) {
// Send Join Group Request
final RequestFuture<ByteBuffer> future = initiateJoinGroup();
client.poll(future, remainingTimeAtLeastZero(timeoutMs, elapsedTime));
if (!future.isDone()) {
// we ran out of time
return false;
}
if (future.succeeded()) { // Join Success, Callback Processing Response, Update Cached Partition Allocation
ByteBuffer memberAssignment = future.value().duplicate();
onJoinComplete(generation.generationId, generation.memberId, generation.protocol, memberAssignment);
}
}
return true;
}
// Send Join Group Request
private synchronized RequestFuture<ByteBuffer> initiateJoinGroup() {
if (joinFuture == null) {
disableHeartbeatThread(); // Pause heartbeat thread
state = MemberState.REBALANCING; // Status changed to REBALANCING
joinFuture = sendJoinGroupRequest(); // Send Join Group Request to Coordinator
joinFuture.addListener(new RequestFutureListener<ByteBuffer>() { // Response listener
@Override
public void onSuccess(ByteBuffer value) { // Success
synchronized (AbstractCoordinator.this) {
state = MemberState.STABLE; // Status changed to STABLE
rejoinNeeded = false; // No need to join
if (heartbeatThread != null)
heartbeatThread.enable(); // Start a paused heartbeat
}
}
@Override
public void onFailure(RuntimeException e) { // fail
synchronized (AbstractCoordinator.this) {
state = MemberState.UNJOINED; // Status changed to UNJOINED
}
}
});
}
return joinFuture;
}
// Send Join Group Request to Coordinator
RequestFuture<ByteBuffer> sendJoinGroupRequest() {
JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
groupId,
this.sessionTimeoutMs,
this.generation.memberId,
protocolType(),
metadata()).setRebalanceTimeout(this.rebalanceTimeoutMs);
int joinGroupTimeoutMs = Math.max(rebalanceTimeoutMs, rebalanceTimeoutMs + 5000);
return client.send(coordinator, requestBuilder, joinGroupTimeoutMs)
.compose(new JoinGroupResponseHandler()); // Asynchronous Callback Response Processing Class
}
// Asynchronous Callback Response Processing Class
private class JoinGroupResponseHandler extends CoordinatorResponseHandler<JoinGroupResponse, ByteBuffer> {
@Override
public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) {
Errors error = joinResponse.error();
if (error == Errors.NONE) {
synchronized (AbstractCoordinator.this) {
if (state != MemberState.REBALANCING) { // If REBALANCING, the state is abnormal
future.raise(new UnjoinedGroupException());
} else {
AbstractCoordinator.this.generation = new Generation(joinResponse.generationId(), joinResponse.memberId(), joinResponse.groupProtocol());
if (joinResponse.isLeader()) { // The current consumer group is leader
onJoinLeader(joinResponse).chain(future);
} else { // When the consumer is a follower
onJoinFollower().chain(future);
}
}
}
}
}
}
// Send leader consumer synchronization group request
private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) {
try {
// Allocate partitions to consumers based on the allocation policy of the response
Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.leaderId(), joinResponse.groupProtocol(), joinResponse.members());
SyncGroupRequest.Builder requestBuilder = new SyncGroupRequest.Builder(groupId, generation.generationId, generation.memberId, groupAssignment);
return sendSyncGroupRequest(requestBuilder);
} catch (RuntimeException e) {
return RequestFuture.failure(e);
}
}
// Send follower consumer synchronization group request
private RequestFuture<ByteBuffer> onJoinFollower() {
SyncGroupRequest.Builder requestBuilder =
new SyncGroupRequest.Builder(groupId, generation.generationId, generation.memberId,
Collections.<String, ByteBuffer>emptyMap()); // Send requests without allocation information
return sendSyncGroupRequest(requestBuilder);
}