students, today we will deeply analyze the source code of HashMap. I believe many students will be asked about the source code during the interview. Which one is the most asked? Most students will definitely think of HashMap. Through the study of this article, you will be able to easily master the source code knowledge of HashMap.
abstract
HashMap is the most frequently used data type for mapping (key value pair) processing by Java programmers. Relative to jdk1 7,JDK1.8 optimize the implementation of the bottom layer of HashMap, such as changing the original array + linked list into the data structure of array + linked list + red black tree, and optimizing the capacity expansion mechanism. This paper combines jdk1 7 and jdk1 8, in-depth discussion of the source code implementation of HashMap, etc.
Hashtable
Before discussing hash tables, let's look at other data structures:
Array: use a continuous storage unit to store data. For the search of the specified subscript, the time complexity is O(1); To search through a given value, you need to traverse the array and compare the given keywords and array elements one by one. The time complexity is O(n). Of course, for an ordered array, you can use binary search, interpolation search, Fibonacci search and other methods to improve the search complexity to O(logn); For the general insert and delete operation, it involves the movement of array elements, and its average complexity is also O(n)
Linear linked list: for operations such as adding and deleting linked lists (after finding the specified operation location), only the references between nodes need to be processed, and the time complexity is O(1), while the search operation needs to traverse the linked list for comparison one by one, and the complexity is O(n)
Binary tree: insert, search, delete and other operations on a relatively balanced ordered binary tree. The average complexity is O(logn).
Hash table: compared with the above data structures, adding, deleting, searching and other operations in the hash table have very high performance. Without considering the hash conflict (the hash conflict will be discussed later), it can be completed only by one positioning, and the time complexity is O(1)
Let's see how the hash table achieves the amazing constant order O(1)?
we know that there are only two physical storage structures of data structure: sequential storage structure and chain storage structure (such as stack, queue, tree and graph are abstracted from the logical structure). As mentioned above, finding an element in the array according to the subscript can be achieved at one time. The hash table takes advantage of this feature, and the backbone of the hash table is the array.
For example, if we want to add or find an element, we can complete the operation by mapping the keyword of the current element to a position in the array through a function and locating it once through the array subscript.
This function can be simply described as: storage location = f (keyword). This function f is generally called hash function. The design of this function will directly affect the quality of hash table.
For example, we need to perform an insert operation in the hash table:
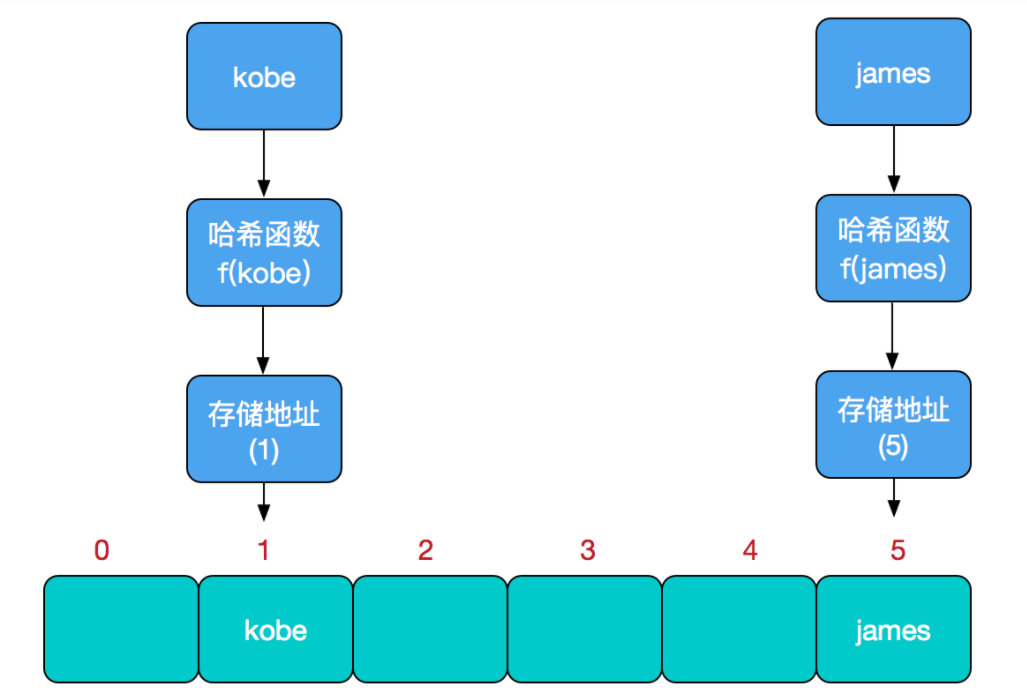
The process of query is the same as that of insertion. First calculate the actual storage location through hash, and then take it out from the array according to the address.
Java defines an interface for mapping in data structures util. Map, this interface mainly has four common implementation classes, namely HashMap, Hashtable, LinkedHashMap and TreeMap. The class inheritance relationship is shown in the following figure:
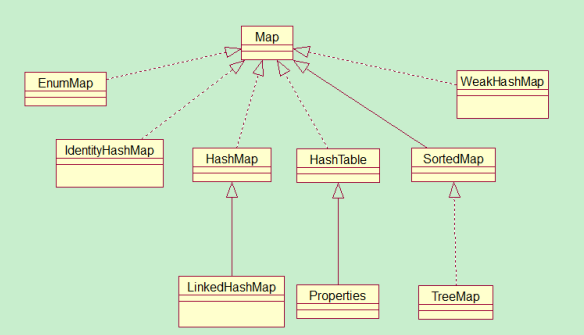
The following describes the characteristics of each implementation class:
(1) HashMap: it stores data according to the hashCode value of the key. In most cases, it can directly locate its value, so it has fast access speed, but the traversal order is uncertain. HashMap can only allow the key of one record to be null at most, and the value of multiple records to be null. HashMap is not thread safe, that is, multiple threads can write HashMap at any time, which may lead to inconsistent data. If you need to meet thread safety, you can use the synchronized map method of Collections to make HashMap thread safe, or use ConcurrentHashMap.
(2) Hashtable: hashtable is a legacy class. The common functions of many mappings are similar to HashMap. The difference is that it inherits from the Dictionary class and is thread safe. Only one thread can write hashtable at any time. The concurrency is not as good as ConcurrentHashMap, because ConcurrentHashMap introduces segment lock. Hashtable is not recommended to be used in new code. It can be replaced with HashMap when thread safety is not required, and with ConcurrentHashMap when thread safety is required.
(3) LinkedHashMap: LinkedHashMap is a subclass of HashMap, which saves the insertion order of records. When traversing LinkedHashMap with Iterator, the records obtained first must be inserted first, or they can be sorted according to the access order with parameters during construction.
(4) TreeMap: TreeMap implements the SortedMap interface, which can sort the records it saves according to the key. By default, the key value is sorted in ascending order, and the sorting Comparator can also be specified. When traversing TreeMap with Iterator, the records obtained are sorted. If you use a sorted map, it is recommended to use TreeMap. When using a TreeMap, the key must implement the Comparable interface or pass in a custom Comparator when constructing a TreeMap, otherwise it will throw Java Exception of type lang.classcastexception.
Hash Collisions
In the process of mapping, there may be different keywords but the obtained hash addresses are the same. This phenomenon is called hash conflict. We need to minimize this conflict and make the hash addresses as different as possible, so that the linear table will be more hashed and uniform.
What if two different elements have the same actual storage address obtained by the hash function?
In other words, when we hash an element, get a storage address, and then insert it, we find that it has been occupied by other elements. In fact, this is the so-called hash conflict, also known as hash collision. The design of hash function is very important. A good hash function will ensure simple calculation and uniform hash address distribution as much as possible. However, we need to be clear that the array is a continuous fixed length memory space. No matter how good the hash function is, it can not guarantee that the storage address will not conflict. So how to solve the hash conflict? There are many solutions to hash conflict: open addressing method (in case of conflict, continue to find the next unoccupied storage address), re hash function method and chain address method. HashMap adopts the chain address method, that is, array + linked list.
HashMap data structure
data structure
JDK1. The HashMap data structure of 7 is array + linked list. The node of the linked list stores an Entry object, and each Entry object stores four attributes (hash, key, value, next), as shown in the following figure:
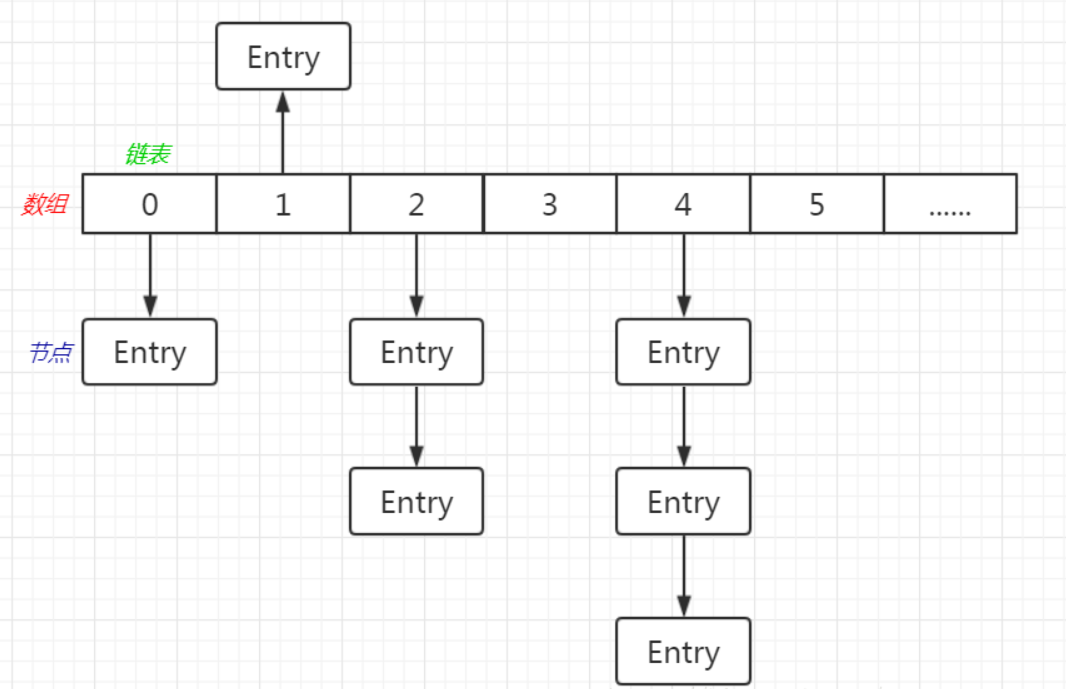
Summary:
The whole is an array, and each position of the data is a linked list
The value in each node in the linked list is the Object we store
Implementation principle of HashMap
The backbone of HashMap is an entry array. Entry is the basic unit of HashMap. Each entry contains a key value pair. (in fact, the so-called Map is actually a collection that saves the mapping relationship between two objects)
//The backbone array of HashMap can be seen as an Entry array. The initial value is an empty array {},
//The length of the trunk array must be a power of 2. As for why we do this, there will be a detailed analysis later.
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry is a static inner class in HashMap. The code is as follows
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//Store the reference to the next Entry, single linked list structure
int hash; //The value obtained by hashing the hashcode value of key,
//Stored in Entry to avoid double calculation
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
Therefore, the overall structure of HashMap is as follows:
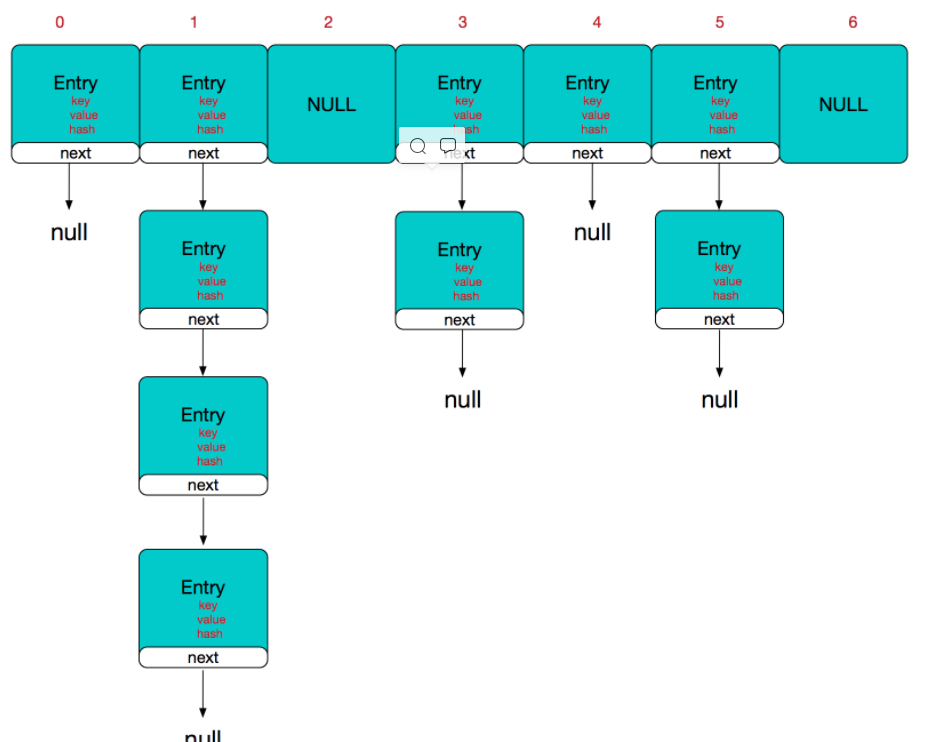
It can be seen from the figure that HashMap is composed of array + linked list. Array is the main body of HashMap, and linked list mainly exists to solve hash conflict. If the location of the located array does not contain linked list (the next of the current entry points to null), the operations such as searching and adding are fast, and only one addressing is required; If the located array contains a linked list, the time complexity of the addition operation is O(n). First traverse the linked list and overwrite it if it exists, otherwise add it; For the search operation, you still need to traverse the linked list, and then compare and search one by one through the equals method of the key object. Therefore, considering the performance, the fewer linked lists in HashMap appear, the better the performance will be.
Several other important fields:
/**Number of key value pairs actually stored*/
transient int size;
/**Threshold value. When table = = {}, this value is the initial capacity (the default is 16); When the table is filled, that is, after allocating memory space for the table,
threshold Generally, it is capacity*loadFactory. HashMap needs to refer to threshold during capacity expansion, which will be discussed in detail later*/
int threshold;
/**The load factor represents the filling degree of the table. The default is 0.75
The reason for the existence of the load factor is to slow down the hash conflict. If the initial bucket is 16 and the capacity is not expanded until it is full of 16 elements, there may be more than one element in some buckets.
Therefore, the loading factor is 0.75 by default, that is, the HashMap with the size of 16 will expand to 32 when it reaches the 13th element.
*/
final float loadFactor;
/**HashMap The number of times that are changed. Because HashMap is not thread safe, when iterating on HashMap,
If the participation of other threads causes the structure of HashMap to change (such as put, remove and other operations),
Need to throw exception ConcurrentModificationException*/
transient int modCount;
Construction method
HashMap has four constructors. If the user does not pass in the parameters initialCapacity and loadFactor, the other constructors will use the default values initialCapacity is 16 by default and loadFactory is 0.75 by default
static final int MAXIMUM_CAPACITY = 1073741824;//Maximum capacity
public HashMap(int initialCapacity, float loadFactor) {
//The incoming initial capacity is verified here. The maximum capacity cannot exceed maximum_ CAPACITY = 1<<30(230)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//The init method is not actually implemented in HashMap, but there will be a corresponding implementation in its subclass, such as linkedHashMap
}
We can see that in the conventional constructor, there is no memory space allocated for the array table (except for the constructor whose input parameter is the specified Map), but the table array is really constructed when the put operation is executed;
OK, let's take a look at the implementation of the put operation
PUT implementation
public V put(K key, V value) {
//If the table array is an empty array {}, fill the array (allocate actual memory space for the table),
//The input parameter is threshold,
//At this time, the threshold is initialCapacity, and the default is 1 < < 4 (24 = 16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//If the key is null, the storage location is on the conflict chain of table[0] or table[0]
if (key == null)
return putForNullKey(value);
int hash = hash(key);//The hashcode of the key is further calculated to ensure uniform hash
int i = indexFor(hash, table.length);//Gets the actual location in the table
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//If the corresponding data already exists, perform the overwrite operation. Replace the old value with the new value and return the old value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//When ensuring concurrent access, if the internal structure of HashMap changes, the rapid response fails
addEntry(hash, key, value, i);//Add an entry
return null;
}
This method is used to allocate storage space in memory for the trunk array table,
Through roundUpToPowerOf2(toSize), you can ensure that the capacity is greater than or equal to the nearest quadratic power of toSize. For example, toSize=13, then capacity = 16; tosize=16,capacity=16; to_size=17,capacity=32
private void inflateTable(int toSize) {
int capacity = roundUpToPowerOf2(toSize);//capacity must be a power of 2
/**Here is the value of threshold, taking capacity*loadFactor and maximum_ Minimum value of capability + 1,
capaticy It must not exceed maximum_ Capability, unless loadFactor is greater than 1 */
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
This processing in the roundUpToPowerOf2 method ensures that the array length must be a power of 2, integer Highestonebit is used to obtain the value represented by the leftmost bit (other bits are 0)
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
Continue with the hash function
/**This is a magical function, using a lot of XOR, shift and other operations
The hashcode of the key is further calculated and the binary bit is adjusted to ensure that the final storage location is evenly distributed as far as possible*/
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
The value calculated by the above hash function is further processed by indexFor to obtain the actual storage location
/**
* Return array subscript
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
H & (length-1) ensure that the obtained index must be within the range of the array. For example, the default capacity is 16, length-1=15, h=18, which is converted into binary and calculated as index=2.
Bit operations have higher performance for computers (there are a large number of bit operations in HashMap)
Therefore, the process of determining the final storage location is as follows:

Let's look at the implementation of addEntry:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//When the size exceeds the critical threshold and a hash conflict is about to occur, the capacity is expanded
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
From the above code, we can know that when a hash conflict occurs and the size is greater than the threshold, the array needs to be expanded. When expanding, we need to create a new array with a length of 2 times that of the previous array, and then transfer all the elements in the current Entry array. The length of the new array after expansion is 2 times that of the previous array. Therefore, capacity expansion is a relatively resource consuming operation.
The array length of HashMap must be a power of 2
Let's continue to look at the resize method mentioned above
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
If the array is expanded, the length of the array changes, and the storage location index = h& (length-1), the index may also change. It is necessary to recalculate the index. Let's take a look at the method of transfer first
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//The code in the for loop traverses the linked list one by one, recalculates the index position, and copies the old array data to the new array (the array does not store the actual data, so it is just a copy reference)
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
//Point the next chain of the current entry to the new index position. The newTable[i] may be empty or it may also be an entry chain. If it is an entry chain, insert it directly at the head of the linked list.
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
This method traverses the data in the old array one by one and throws it into the new expanded array. Our array index position is calculated by hashing the hashcode of the key value, and then performing bit operation with length-1 to obtain the final array index position.
The array length of HashMap must maintain the power of 2. For example, if the binary representation of 16 is 10000, then the length-1 is 15 and the binary representation is 01111. Similarly, the array length after capacity expansion is 32, the binary representation is 100000, the length-1 is 31 and the binary representation is 01111. We can also see from the figure below that this will ensure that all the low bits are 1, and there is only one bit difference after capacity expansion, that is, there is an extra leftmost 1. In this way, when passing through H & (length-1), as long as the leftmost difference corresponding to h is 0, It can ensure that the new array index obtained is consistent with the old array index (greatly reducing the re exchange of data positions of the old array that has been hashed well before). Personal understanding.
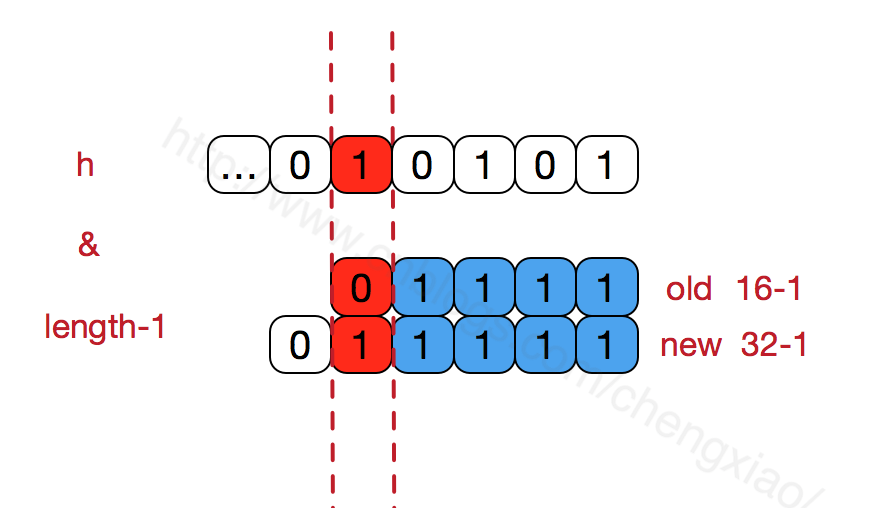
In addition, keeping the array length to the power of 2 and the low order of length-1 to 1 will make the obtained array index more uniform
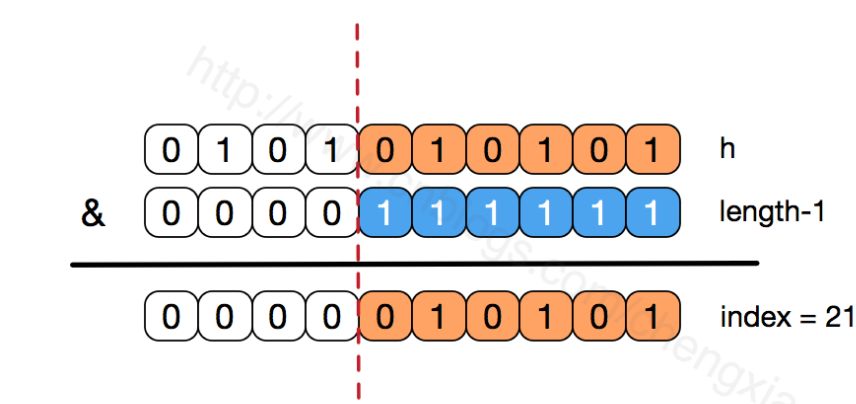
We can see that in the above & operation, the high bit will not affect the result (the hash function uses various bit operations to make the low bit more hash). We only focus on the low bit. If all the low bits are 1, for the low part of h, the change of any bit will affect the result, that is, to get the storage location of index=21, The low order of h has only one combination. This is why the array length is designed to be a power of 2.
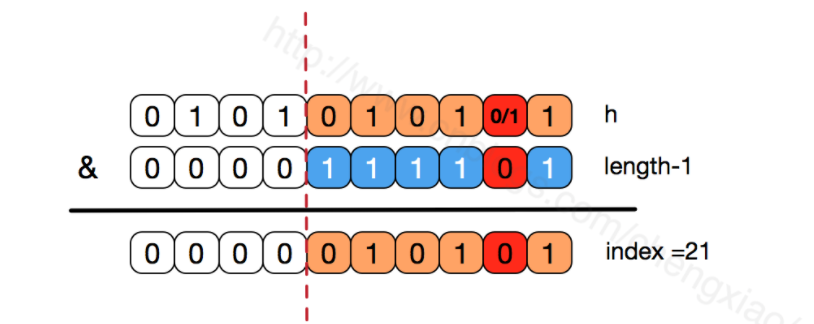
If it is not the power of 2, that is, the low order is not all 1. At this time, to make the low order part of index=21 and h no longer unique, the probability of hash conflict will become greater. At the same time, the bit corresponding to index will not be equal to 1 in any case, and the corresponding array positions will be wasted.
get principle
public V get(Object key) {
//If the key is null, you can directly go to table[0] to retrieve it.
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
The get method returns the corresponding value through the key value. If the key is null, go directly to table[0] for retrieval. Let's take another look at the getEntry method
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//Calculate the hash value through the hashcode value of the key
int hash = (key == null) ? 0 : hash(key);
//Indexfor (hash & length-1) obtains the final array index, then traverses the linked list and finds the corresponding records through the equals method
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
It can be seen that the implementation of get method is relatively simple. key(hashcode) – > hash – > indexfor – > the final index position, find the corresponding position table[i], then check whether there is a linked list, traverse the linked list, and compare and find the corresponding records through the equals method of key. It should be noted that some people think that the above judgment of e.hash == hash is unnecessary after locating the array position and then traversing the linked list. It can only be judged by equals. In fact, it is not. Imagine that if the passed in key Object rewrites the equals method but does not rewrite the hashCode, and the Object happens to be located in the array position. If only equals is used to judge, it may be equal, but its hashCode is inconsistent with the current Object. In this case, according to the hashCode convention of the Object, the current Object cannot be returned, but null should be returned, The following examples will further explain.
What are the similarities and differences between HashMap and HashTable?
Both have the same storage structure and conflict resolution methods.
- The default capacity of hashtable without specifying the capacity is 11, while that of HashMap is 16. Hashtable does not require that the capacity of the underlying array must be an integer power of 2, while HashMap requires an integer power of 2.
- Neither key nor value in Hashtable is allowed to be null, while both key and value in HashMap are allowed to be null (only one key can be null, while multiple values can be null). However, if there are put (null, null) operations in the Hashtable, the compilation can also pass, because both key and value are Object types, but NullPointerException exceptions will be thrown at runtime.
- When Hashtable is expanded, the capacity will be doubled + 1, while when HashMap is expanded, the capacity will be doubled.
epilogue
the above is the main content of the detailed explanation of the HashMap source code shared by kaka today. If there is any mistake, I hope students will actively point it out in the comment area. You are welcome to share and learn together.