Perfect version of kettle to realize data incremental synchronization
preface
Some time ago, there was an operation of using kettle to realize data synchronization, including Installation and configuration of kettle, creation of job, creation of translate, etc.
At that time, the time point of dead writing was used (that is, the data will be queried and compared from this time point during each synchronization, and the data will be synchronized and updated to the target data source). Of course, when the amount of data is small and the primary key ID is used for data comparison, the speed of data synchronization is still very fast,
However, with the continuous increase of data and the change of different business requirements, we can't use ID for data comparison in some businesses. At this time, when the amount of data is particularly large, we will obviously feel the difficulty of data synchronization. In addition, I need to open VPN to synchronize the test environment from the customer's production environment, Due to the limitation of network speed and the factors of server hardware, the late synchronization speed is very slow.
Originally, I thought it was enough to synchronize some data, but because the demand needs to update the data in real time every day, I had to "upgrade" the synchronization method at that time.
abstract
This record is mainly based on the previous method, so it will not be recorded in detail this time Installation and configuration of kettle, creation of job, creation of translate, etc.
The use environment is as follows:
Data source:
Source data source: MySQL;
target data source: MySQL;
kettle version: windows version 7.0
Completed content:
1. Complete the real-time incremental synchronization of data by setting the update timestamp;
Note: in order to make the record clear and easy to read, a simple demo is used to record the core logic directly. If there are other business requirements, it can be upgraded on this basis.
1 core logic
How to complete near real-time incremental synchronization, we first need to consider two key factors: near real-time and incremental.
Near real time:
In fact, it's easy to implement. We can let kettle execute our job s periodically according to business needs. For example, the data of a table of source data is to add several pieces of data every hour, Then we can set the cycle frequency to 30 minutes / time, so as to complete the near real-time synchronization in business (it is not excluded that new data is added to the source data table in the synchronization project, but this generally does not happen. If you want to avoid it, you can shorten the cycle interval again)
Increment:
In fact, the increment is obvious, that is, the data that has been synchronized last time. When the job performs synchronization for the second time, we only need to synchronize the data added in the source data table. In order to realize this incremental addition, we can only use the timestamp to filter;
1.1 implementation overview based on logical analysis
The near real-time and incremental are analyzed above. The next step is the specific implementation of this demo. Let's take a look at the implementation overview first:

The figure above shows our final job:
1 click start
2. After starting, we need to query the timestamp of the last synchronization. This timestamp needs to be persisted and stored in our target data source timestamp table. In the synchronization implementation, we can manually create a timestamp as the data date when we start synchronization. When it is executed for the first time, it is synchronized from the created timestamp and subsequent data. And when we get the timestamp, we need to set the queried timestamp as a global variable, because this timestamp will be used later;
3 delete the current time stamp and the data after the time stamp according to the time stamp. The purpose of this is to roll back the data for a period of time to avoid data leakage.
4 data synchronization is actually the core logic of our data synchronization. We need to establish a translate to realize the specific logic; (the data in the conversion must be queried according to the timestamp. Here we use the timestamp, which is also the core of incremental synchronization)
5 when the data synchronization is completed, we need to sort the synchronized data in the target according to the time, take out the latest time, and update the timestamp at the same time, so that the latest timestamp can be used when the next job is executed;
6 success.
2 preparation
Before starting, prepare the tables and test data involved in the source and target data sources
2.1 target data source timestamp table
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for tel_time_temp -- ---------------------------- DROP TABLE IF EXISTS `tel_time_temp`; CREATE TABLE `tel_time_temp` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Primary key ID', `etl_type` bigint(20) NULL DEFAULT NULL COMMENT 'Timestamp service type(Used to specify which one job Timestamp of)', `temp_time` datetime NULL DEFAULT NULL COMMENT 'time stamp', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC; -- ---------------------------- -- Records of tel_time_temp -- ---------------------------- INSERT INTO `tel_time_temp` VALUES (1, 1, '2022-01-29 00:00:00'); SET FOREIGN_KEY_CHECKS = 1;
2.2 source data source table
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for tab_source -- ---------------------------- DROP TABLE IF EXISTS `tab_source`; CREATE TABLE `tab_source` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `tm` datetime NULL DEFAULT NULL COMMENT 'Monitoring time', `drp` decimal(10, 3) NULL DEFAULT NULL COMMENT 'rainfall', `create_time` datetime NULL DEFAULT NULL COMMENT 'Creation time', `update_time` datetime NULL DEFAULT NULL COMMENT 'Update time', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of tab_source -- ---------------------------- INSERT INTO `tab_source` VALUES (1, '2022-01-28 15:38:49', 10.000, '2022-01-28 15:39:01', '2022-01-28 15:39:06'); INSERT INTO `tab_source` VALUES (2, '2022-01-28 15:39:16', 12.300, '2022-01-28 15:39:22', '2022-01-28 15:39:24'); INSERT INTO `tab_source` VALUES (3, '2022-01-28 15:39:37', 15.300, '2022-01-28 15:39:43', '2022-01-28 15:39:45'); INSERT INTO `tab_source` VALUES (4, '2022-01-28 15:40:08', 15.360, '2022-01-28 15:40:14', '2022-01-28 15:40:16'); INSERT INTO `tab_source` VALUES (5, '2022-01-28 15:40:24', 14.230, '2022-01-28 15:40:30', '2022-01-28 15:40:32'); INSERT INTO `tab_source` VALUES (6, '2022-01-29 20:45:41', 66.000, '2022-01-29 20:45:48', '2022-01-29 20:45:51'); INSERT INTO `tab_source` VALUES (7, '2022-01-29 20:46:55', 88.000, '2022-01-29 20:46:58', '2022-01-29 20:47:02'); SET FOREIGN_KEY_CHECKS = 1;
2.3 target data source table
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for tab_target -- ---------------------------- DROP TABLE IF EXISTS `tab_target`; CREATE TABLE `tab_target` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `tm` datetime NULL DEFAULT NULL COMMENT 'Monitoring time', `drp` decimal(10, 3) NULL DEFAULT NULL COMMENT 'rainfall', `update_time` datetime NULL DEFAULT NULL COMMENT 'Update time', `create_time` datetime NULL DEFAULT NULL COMMENT 'Creation time', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;
3 get timestamp
There are two operations in obtaining time stamps. One is to query the time stamps from the time stamp table of the target data source, and the other is to update the time stamps to global variables and store them for standby.
So we can create a transform translate to complete these two operations
As shown in the figure

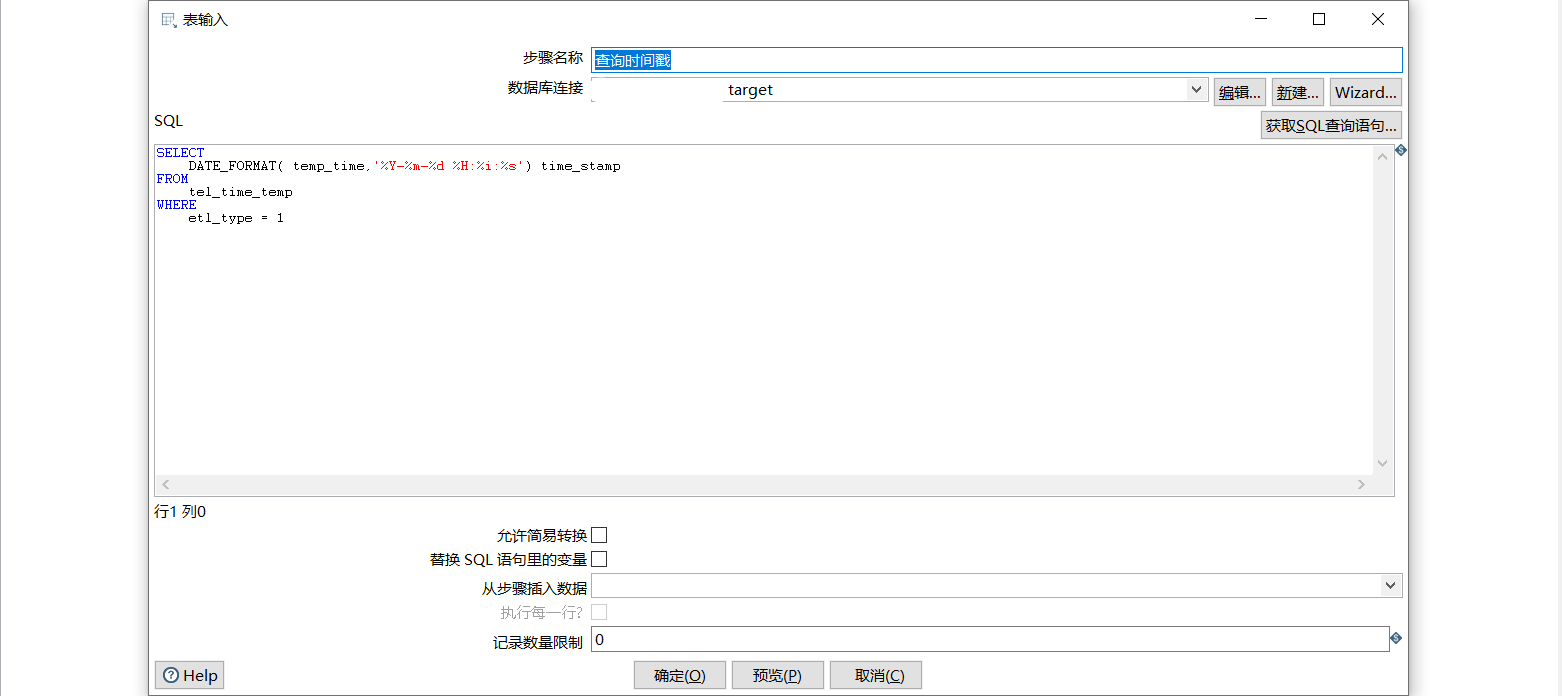
3.1 query timestamp
Create a table input to query the timestamp of the last synchronization from the timestamp table of the target data source.
Note that we try to convert tm into a string in the specified format to facilitate later comparison. If different database types directly use time for comparison, there may be problems, resulting in data synchronization failure or synchronization to duplicate data.
3.2 update timestamp to global variable
Set timestamp to global variable
Variable activity type can set four valid activity ranges for this variable, namely JVM, this job, parent job and grandfather job (this job is used in the demo)

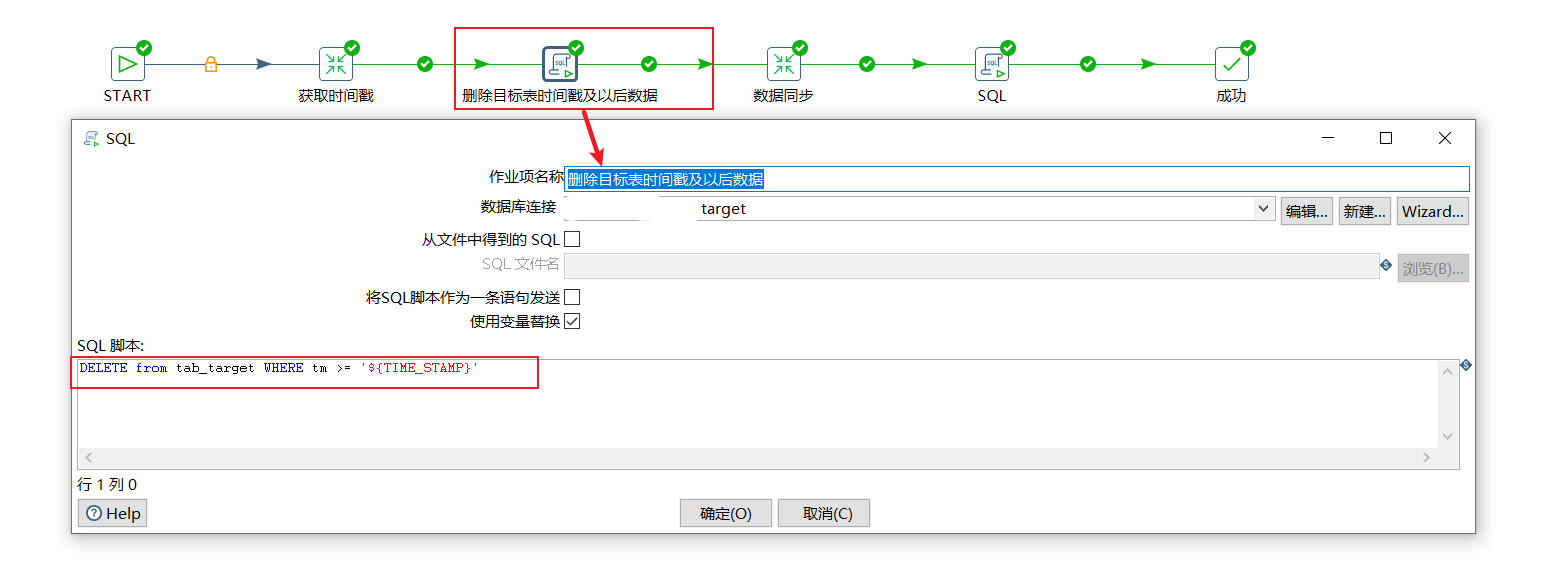
4 delete timestamp and subsequent data
Create an sql script in the job to complete it
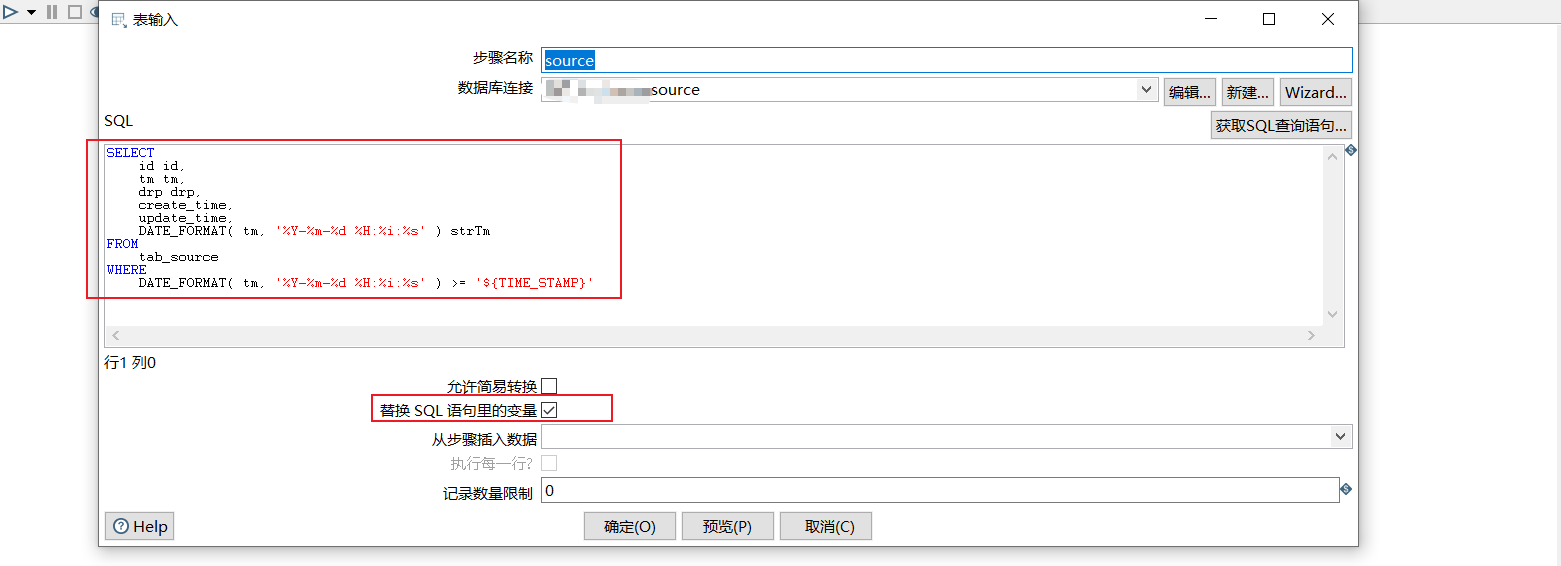
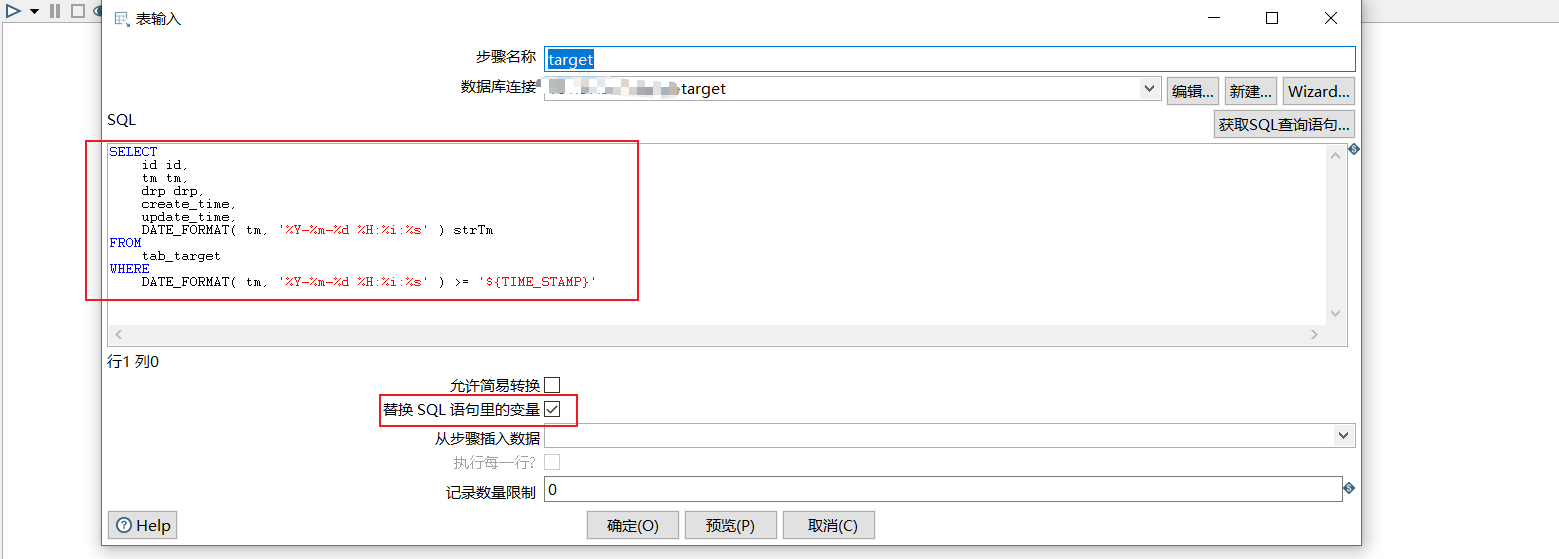
5 data synchronization
The data synchronization here does not specifically record how to create it. For details, please refer to Installation and configuration of kettle, creation of job, creation of translate, etc.
Some screenshots are listed below:

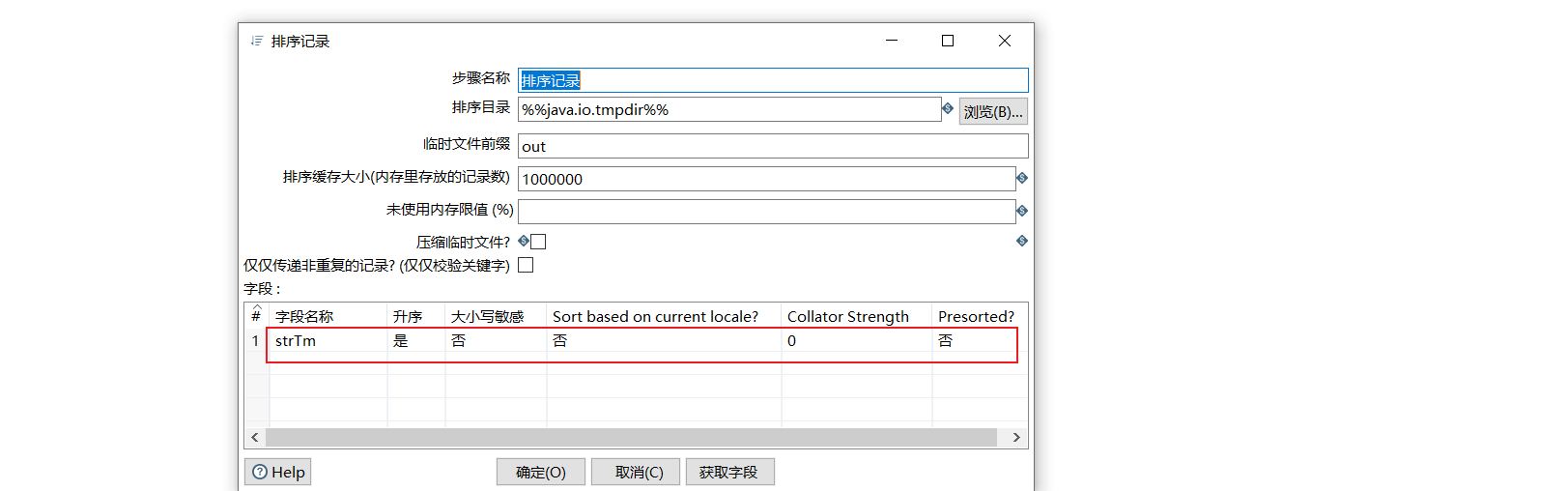
6 update timestamp
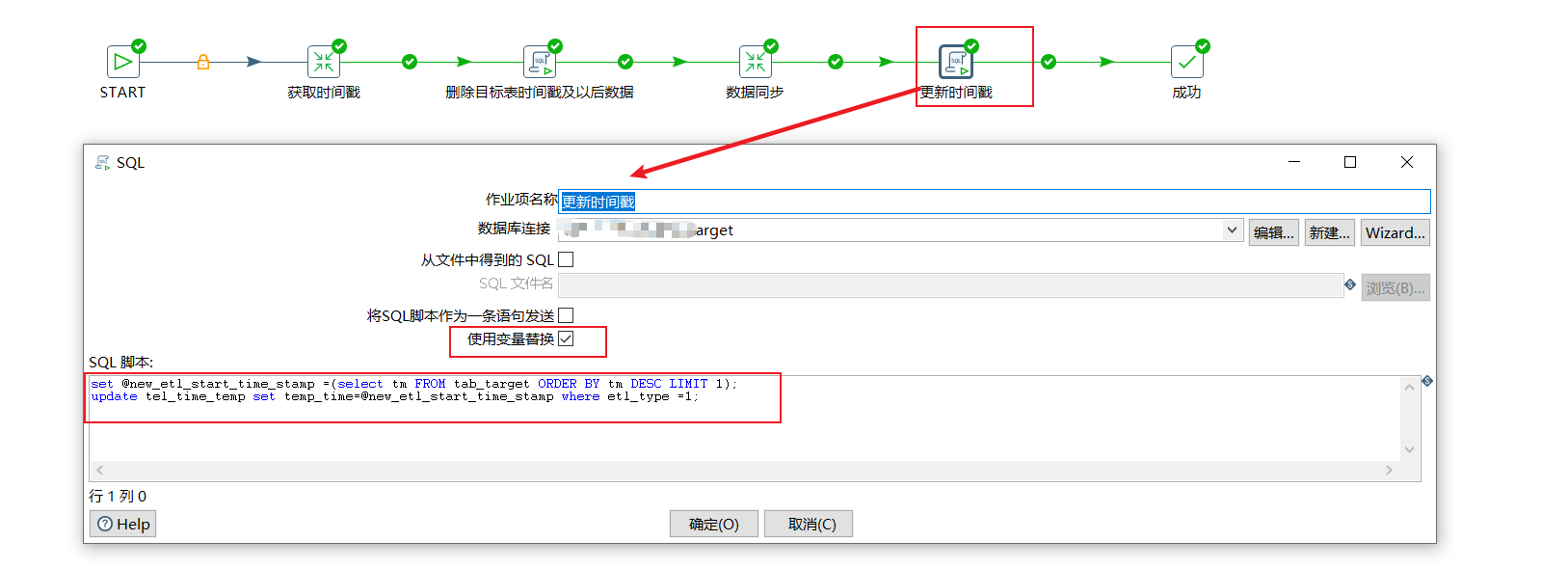
To update the timestamp, we only need to create the SQL script in the job.
set @new_etl_start_time_stamp =(select tm FROM tab_target ORDER BY tm DESC LIMIT 1); update tel_time_temp set temp_time=@new_etl_start_time_stamp where etl_type =1;
7. See the effect of execution
We set the job to execute every minute, judge whether the synchronization is successful by looking at the data changes in the timestamp table and target table before and after the first execution, and then add a new piece of data in the source table to see whether the timestamp table and target table are updated again one minute later.
Before execution: the data of timestamp table and target table are as follows


Execute the job and print the log
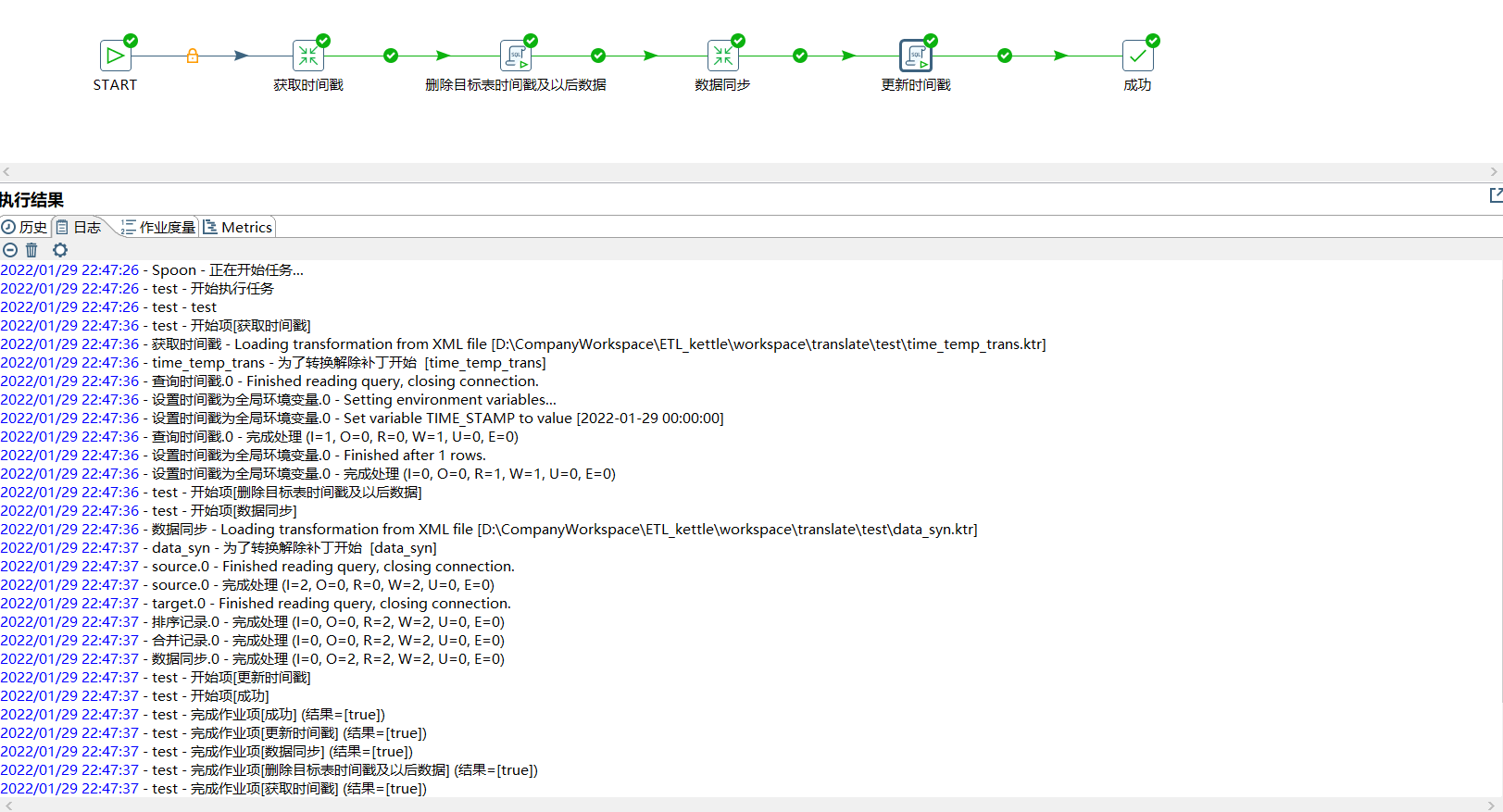
After execution, check the changes of timestamp and target table data: you can see two pieces of data just after the timestamp in the source data source


Next, add a new piece of the latest data in the source data source table. Execute it again to see the time stamp and data changes
In the legend, you can see that the timestamp and data have changed.
INSERT INTO `source`.`tab_source` (`tm`, `drp`, `create_time`, `update_time`) VALUES ('2022-01-30 00:00:00', 99.000, '2022-01-30 00:00:00', '2022-01-30 00:00:00');


8 concluding remarks
This is the end of the recording. For back-end development, the most exposed is often not code, but the processing of business data in many cases.