preface
OkHttp can be said to be the most common network request framework in Android development. OkHttp is easy to use, extensible and powerful. OkHttp source code and principle are also frequent visitors in the interview
However, OKHttp has a lot of source code content. If you want to learn its source code, you are often confused and can't grasp the key point at the moment
This article combs OKHttp related knowledge points from several problems in order to quickly build OKHttp knowledge system. If it is useful to you, you are welcome to praise it~
This paper mainly includes the following contents
- What is the overall process of OKHttp requests?
- How does the OKHttp distributor work?
- How does the OKHttp interceptor work?
- What is the difference between an application interceptor and a network interceptor?
- How does OKHttp reuse TCP connections?
- How to clear OKHttp idle connections?
- What are the advantages of OKHttp?
- What design patterns are used in the OKHttp framework?
1. Introduction to the overall okhttp request process
First, let's look at how the simplest Http request is sent.
val okHttpClient = OkHttpClient()
val request: Request = Request.Builder()
.url("https://www.google.com/")
.build()
okHttpClient.newCall(request).enqueue(object :Callback{
override fun onFailure(call: Call, e: IOException) {
}
override fun onResponse(call: Call, response: Response) {
}
})This code looks relatively simple. During the OkHttp Request process, at least only OkHttpClient, Request, Call and Response need to be contacted, but a lot of logic processing will be carried out inside the framework.
Most of the logic of all network requests is concentrated in the interceptor, but before entering the interceptor, you need to rely on the distributor to allocate the request task.
As for distributors and interceptors, we will briefly introduce them here and explain them in more detail later
- Distributor: internally maintain queue and thread pool, and complete request allocation;
- Interceptor: the five default interceptors complete the whole request process.
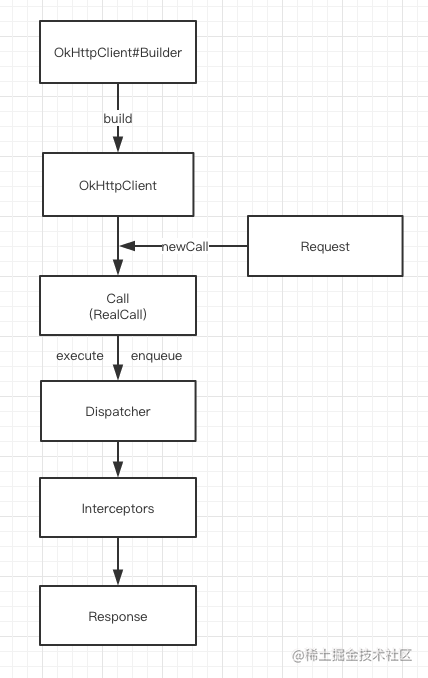
The whole network request process is roughly as shown above
- Build OKHttpClient and Request through builder mode
- OKHttpClient initiates a new request through newCall
- Maintain the request queue and thread pool through the distributor to complete the request provisioning
- Complete a series of operations such as request retry, cache processing, connection establishment, etc. through the five default interceptors
- Get network request results
2. How does okhttp distributor work?
The main function of the distributor is to maintain the request queue and thread pool. For example, we have 100 asynchronous requests. We certainly can't request them at the same time. Instead, we should queue them into categories, including the list in request and the waiting list. After the request is completed, we can take the waiting requests from the waiting list to complete all requests
Here, synchronous requests are slightly different from asynchronous requests
Synchronization request
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}Because synchronous requests do not require a thread pool, there are no restrictions. So the distributor only makes records. The subsequent requests can be synchronized in the order of joining the queue
Asynchronous request
synchronized void enqueue(AsyncCall call) {
//The maximum number of requests shall not exceed 64, and the same Host request shall not exceed 5
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}When the executing task does not exceed the maximum limit of 64 and the number of requests from the same Host does not exceed 5, it will be added to the executing queue and submitted to the thread pool at the same time. Otherwise, join the waiting queue first.
After each task is completed, the finished method of the distributor will be called, which will take out the tasks in the waiting queue to continue execution
3. How does okhttp interceptor work?
After the task distribution of the distributor above, the interceptor will be used to start a series of configurations
# RealCall
override fun execute(): Response {
try {
client.dispatcher.executed(this)
return getResponseWithInterceptorChain()
} finally {
client.dispatcher.finished(this)
}
}Let's take another look at the execute method of RealCall. It can be seen that getResponseWithInterceptorChain is returned. The construction and processing of the responsibility chain is actually in this method
internal fun getResponseWithInterceptorChain(): Response {
// Build a full stack of interceptors.
val interceptors = mutableListOf<Interceptor>()
interceptors += client.interceptors
interceptors += RetryAndFollowUpInterceptor(client)
interceptors += BridgeInterceptor(client.cookieJar)
interceptors += CacheInterceptor(client.cache)
interceptors += ConnectInterceptor
if (!forWebSocket) {
interceptors += client.networkInterceptors
}
interceptors += CallServerInterceptor(forWebSocket)
val chain = RealInterceptorChain(
call = this,interceptors = interceptors,index = 0
)
val response = chain.proceed(originalRequest)
}As shown above, a responsibility chain of OkHttp interceptor is constructed
The responsibility chain, as its name suggests, is an execution chain used to handle the responsibilities of related transactions. There are multiple nodes on the execution chain. Each node has the opportunity (condition matching) to process the requested transaction. If a node is completed, it can be passed to the next node to continue processing or return to processing according to the actual business requirements.
As shown above, the order and function of adding responsibility chain are shown in the following table:
| Interceptor | effect |
|---|---|
| Application interceptor | What you get is the original request. You can add some custom header s, general parameters, parameter encryption, gateway access, etc. |
| RetryAndFollowUpInterceptor | Handling error retries and redirects |
| BridgeInterceptor | The bridge interceptors at the application layer and network layer mainly work to add cookies and fixed header s for requests, such as Host, content length, content type, user agent, etc., and then save the cookies of the response results. If the response is compressed with gzip, it also needs to be decompressed. |
| CacheInterceptor | Cache interceptor. If the cache is hit, the network request will not be initiated. |
| ConnectInterceptor | The connection interceptor internally maintains a connection pool, which is responsible for connection reuse, creating connections (three handshakes, etc.), releasing connections, and creating socket streams on connections. |
| Network interceptors | User defined interceptors are usually used to monitor data transmission at the network layer. |
| CallServerInterceptor | The request interceptor actually initiates the network request after the pre preparation is completed. |
In this way, our network request passes through the responsibility chain level by level, and will eventually be executed to the intercept method of CallServerInterceptor. This method will encapsulate the result of the network Response into a Response object and return. After that, it goes back level by level along the responsibility chain, and finally returns to the return of getResponseWithInterceptorChain method, as shown in the following figure:
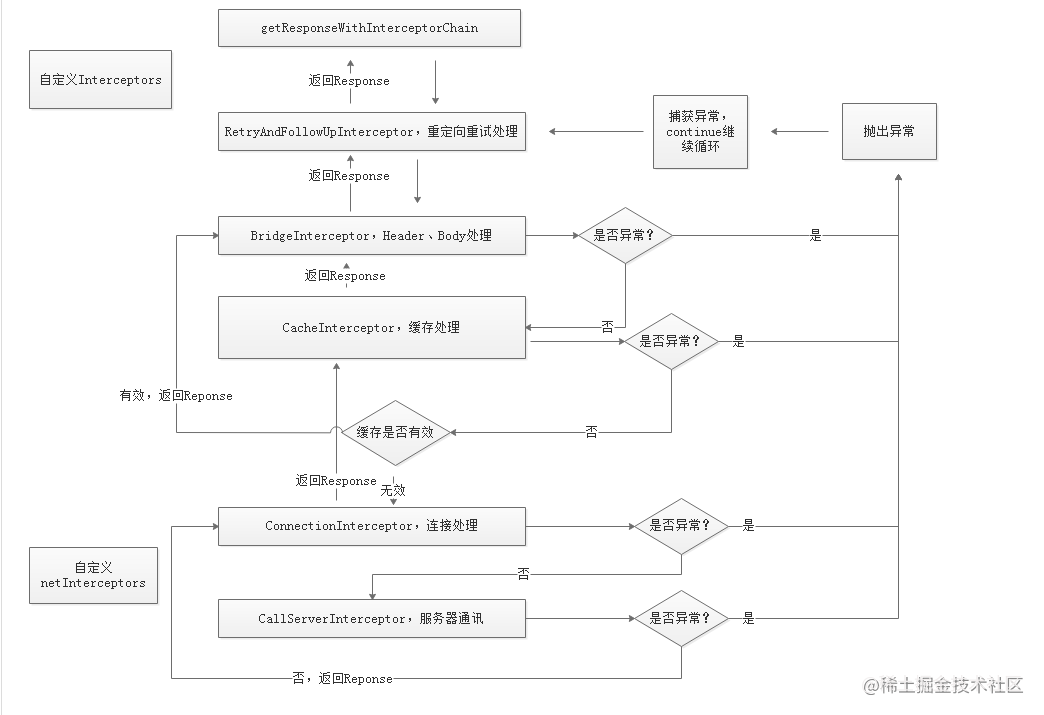
4. What is the difference between application interceptor and network interceptor?
From the perspective of the entire responsible link, the application interceptor is the first interceptor to execute, that is, the original request after the user sets the request attribute. The network interceptor is located between ConnectInterceptor and CallServerInterceptor. At this time, the network link is ready and only waiting for the request data to be sent. They mainly have the following differences
- First, the application interceptor precedes RetryAndFollowUpInterceptor and CacheInterceptor, so in case of error retry or network redirection, the network interceptor may execute multiple times, because it is equivalent to making a second request, but the application interceptor will always be triggered only once. In addition, if the cache is hit in the CacheInterceptor, the network request does not need to be sent, so there will be a short circuit to the network interceptor.
- Second, each interceptor should call realchain at least once, except for the CallServerInterceptor Proceed method. In fact, in the application interceptor layer, the proceed method can be called multiple times (local exception retry) or not (interrupt), but the connection of the network interceptor layer is ready, and the proceed method can be called only once.
- Finally, from the usage scenario, the application interceptor is usually used to count the initiation of network requests from clients because it is only called once; One call of network interceptor means that a network communication will be initiated, so it can usually be used to count the data transmitted on the network link.
5. How does okhttp reuse TCP connections?
The main work of ConnectInterceptor is to establish a TCP connection. Establishing a TCP connection requires three handshakes and four waves. If each HTTP request needs to create a new TCP, it will consume more resources
And Http1 1 already supports keep alive, that is, multiple Http requests reuse a TCP connection, and OKHttp has also been optimized accordingly. Let's see how OKHttp multiplexes TCP connections
The code for finding connections in ConnectInterceptor will eventually call exchange finder The findconnection method is as follows:
# ExchangeFinder
//Find a connection to host a new data stream. The search order is assigned connections, connection pools, and new connections
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
synchronized (connectionPool) {
// 1. Try to use the connection assigned to the data flow (for example, when redirecting a request, you can reuse the last requested connection)
releasedConnection = transmitter.connection;
result = transmitter.connection;
if (result == null) {
// 2. If there are no allocated available connections, try to get them from the connection pool. (connection pool will be explained in detail later)
if (connectionPool.transmitterAcquirePooledConnection(address, transmitter, null, false)) {
result = transmitter.connection;
}
}
}
synchronized (connectionPool) {
if (newRouteSelection) {
//3. Now that you have the IP address, try to get it from the connection pool again. May match due to join merge. (routes are passed in here, and null is passed in above)
routes = routeSelection.getAll();
if (connectionPool.transmitterAcquirePooledConnection(address, transmitter, routes, false)) {
foundPooledConnection = true;
result = transmitter.connection;
}
}
// 4. If the second time is not successful, the newly created connection shall be handshaked with TCP + TLS to establish a connection with the server Blocking operation
result.connect(connectTimeout, readTimeout, writeTimeout, pingIntervalMillis,
connectionRetryEnabled, call, eventListener);
synchronized (connectionPool) {
// 5. In the last attempt to obtain from the connection pool, note that the last parameter is true, that is, multiplexing is required (http2.0)
//It means that if this time is http2 0, in order to ensure multiplexing, (because the above handshake operation is not thread safe), confirm again whether the same connection already exists in the connection pool at this time
if (connectionPool.transmitterAcquirePooledConnection(address, transmitter, routes, true)) {
// If it is obtained, close the connection we created and return the obtained connection
result = transmitter.connection;
} else {
//If the last attempt fails, the newly created connection will be stored in the connection pool
connectionPool.put(result);
}
}
return result;
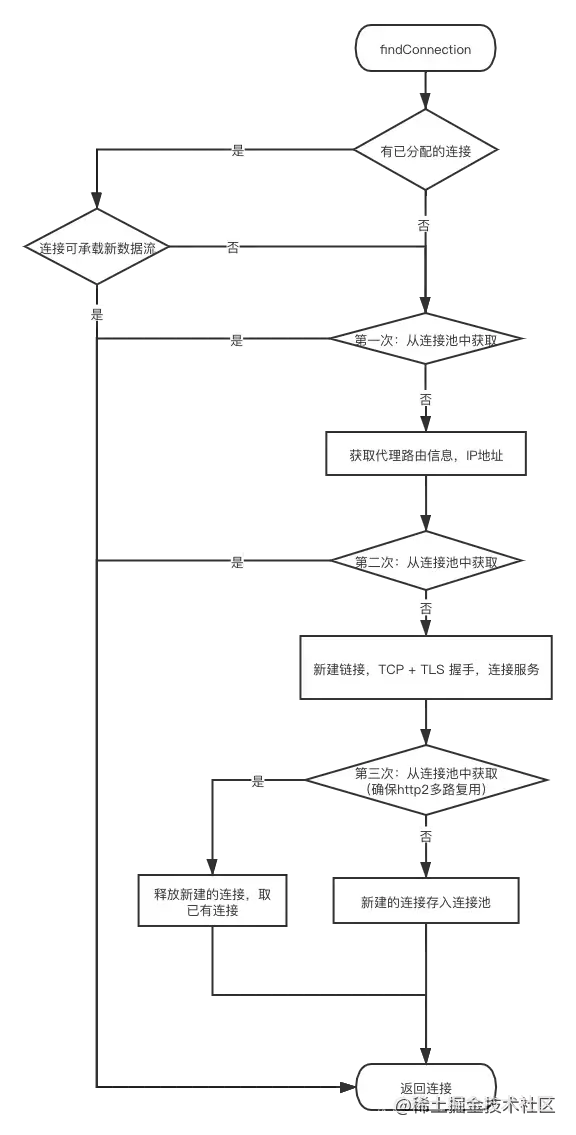
}The above code has been simplified. It can be seen that the connection interceptor uses five methods to find connections
- The connection assigned to the request is first attempted. (if the connection has been allocated, for example, the re request during redirection indicates that there has been a connection last time)
- If no allocated connections are available, try to get a match from the connection pool. Because there is no routing information at this time, the matching condition is that the address is consistent - the host, port, proxy, etc. are consistent, and the matching connection can accept new requests.
- If it is not obtained from the connection pool, the incoming routes try to obtain it again, mainly for http2 0, http2 0 can reuse square COM and square CA connection
- If it is not obtained the second time, create a RealConnection instance, shake hands with TCP + TLS, and establish a connection with the server.
- At this time, in order to ensure http2 The multiplexing of 0 connections will be matched from the connection pool for the third time. Because the handshake process of the newly established connection is non thread safe, the same connection may be newly stored in the connection pool at this time.
- If it is matched the third time, use the existing connection and release the newly created connection; If not, the new connection is stored in the connection pool and returned.
The above is the operation of the connection interceptor trying to reuse the connection. The flow chart is as follows:
6. How to clear okhttp idle connections?
As mentioned above, we will establish a TCP connection pool, but if there are no tasks, idle connections should be cleared in time. How does OKHttp do it?
# RealConnectionPool
private val cleanupQueue: TaskQueue = taskRunner.newQueue()
private val cleanupTask = object : Task("$okHttpName ConnectionPool") {
override fun runOnce(): Long = cleanup(System.nanoTime())
}
long cleanup(long now) {
int inUseConnectionCount = 0;//Number of connections in use
int idleConnectionCount = 0;//Number of idle connections
RealConnection longestIdleConnection = null;//Connection with the longest idle time
long longestIdleDurationNs = Long.MIN_VALUE;//Maximum idle time
//Traversal connection: find the connection to be cleaned up and find the time for the next cleaning up (the maximum idle time has not yet been reached)
synchronized (this) {
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
//If the connection is in use, continue. The number of connections in use + 1
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
//Number of idle connections + 1
idleConnectionCount++;
// Assign the longest idle time and the corresponding connection
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
//If the maximum idle time is greater than 5 minutes or the idle number is greater than 5, remove and close the connection
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
// else, return how long you have left to reach 5 minutes, and then wait this time to clean up
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
//If the connection is not free, try cleaning up in 5 minutes
return keepAliveDurationNs;
} else {
// No connection, no cleaning
cleanupRunning = false;
return -1;
}
}
//Close removed connections
closeQuietly(longestIdleConnection.socket());
//After closing the removal, immediately carry out the next attempt to clean up
return 0;
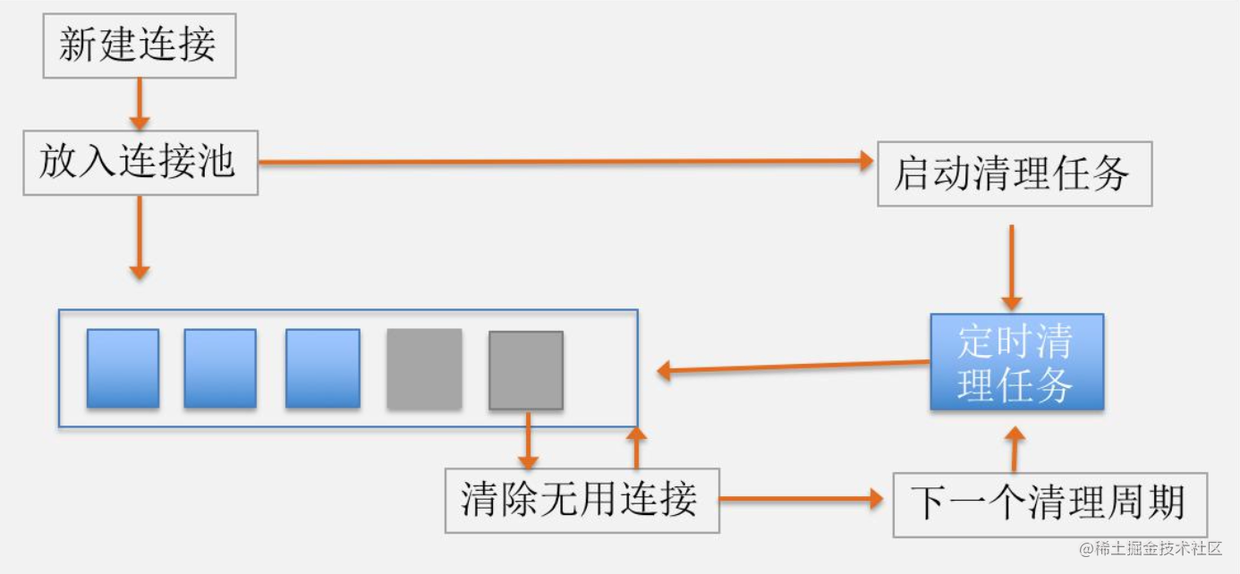
}The idea is still very clear:
- The scheduled task starts when a connection is added to the connection pool
- If there is an idle connection, if the longest idle time is greater than 5 minutes or the number of idle connections is greater than 5, remove and close the longest idle connection; If the idle number is no more than 5 and the maximum idle time is no more than 5 minutes, return to the remaining time of 5 minutes, and then wait for this time to clean up.
- If there is no free connection, wait 5 minutes before trying to clean up.
- No connection, no cleanup.
The process is shown in the figure below:
7. What are the advantages of okhttp?
- It is easy to use. The appearance mode is used in the design to hide the complexity of the whole system and expose the subsystem interface through a client OkHttpClient.
- It has strong expansibility, and can complete various user-defined requirements by customizing application interceptors and network interceptors
- Powerful, support Spdy and http1 10. Http2, and WebSocket
- Reuse the underlying TCP(Socket) through the connection pool to reduce the request delay
- Seamless support for GZIP to reduce data traffic
- Support data caching to reduce repeated network requests
- Support request failure, automatic retry of other ip addresses of the host, and automatic redirection
8. What design patterns are used in okhttp framework?
- Builder mode: the builder mode is used in the construction of OkHttpClient and Request
- Appearance mode: OkHttp uses the appearance mode to hide the complexity of the whole system and expose the subsystem interface through a client OkHttpClient.
- Responsibility chain mode: the core of OKHttp is the responsibility chain mode, which completes the configuration of requests through the responsibility chain composed of five default interceptors
- Meta sharing mode: the core of meta sharing mode is reuse in the pool. OKHttp uses the connection pool when reusing TCP connections. At the same time, it also uses the thread pool in asynchronous requests
summary
This paper mainly combs the knowledge points related to OKHttp principle and answers the following questions:
- What is the overall process of OKHttp requests?
- How does the OKHttp distributor work?
- How does the OKHttp interceptor work?
- What is the difference between an application interceptor and a network interceptor?
- How does OKHttp reuse TCP connections?
- How to clear OKHttp idle connections?
- What are the advantages of OKHttp?
- What design patterns are used in the OKHttp framework?
If it helps you, welcome to like it, thank you~
Related videos:
This article is transferred from https://juejin.cn/post/7020027832977850381 , in case of infringement, please contact to delete.