As a component of the core of Kotlin, the cost of starting the Kotlin collaboration process is not high. I have reviewed the following demo s with reference to the examples on the official website. Kotlin Chinese website.
Flow among them, you can spend more time, which is still very interesting.
Start a collaborative process
fun main() {
GlobalScope.launch {
println(123)
}
Thread.sleep(10)
}In blocking mode, wait for the execution of the cooperation process before executing the follow-up
GlobalScope.launch {
delay(1000)
println(123)
}.join()
println(1231)delay
Special suspend function, which will not cause function blocking, but will suspend the coroutine
Collaboration scope builder
runBlocking
Will block the current thread until the collaboration ends. Generally used for testing
runBlocking {
launch(Dispatchers.IO) {
Log.e("demo", Thread.currentThread().name)
delay(10000)
println("!23")
}
}coroutineScope
Just hanging will release the underlying thread for other purposes and will not block the thread. So we call it the suspend function
coroutineScope {
launch(Dispatchers.IO) {
Log.e("demo", Thread.currentThread().name)
delay(10000)
println("!23")
}
}Structured concurrency
Although the collaboration process is very simple to use, when we use globalscope When we start a new process, we will forget that it is a top-level process, but we will continue to use this method when we start a new process. Therefore, in practical application, we prefer to start the collaboration within the specified scope where the operation is executed, rather than using it arbitrarily
Cancellation and timeout of collaboration
cancelAndJoin
Cancel a collaboration and wait for the end
runBlocking {
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (i < 5) { // A loop that performs calculations just to occupy the CPU
// Print messages twice per second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // Wait for a while
println("main: I'm tired of waiting!")
job.cancelAndJoin() // Cancel a job and wait for it to finish
println("main: Now I can quit.")
}withTimeout
Throw an exception after timeout
//Timeout throw exception
withTimeout(1300L) {
delay(1400)
}withTimeoutOrNull
Throw null pointer after timeout
//Timeout throw exception
withTimeoutOrNull(1300L){
delay(1400)
}Release resources in finally
coroutineScope {
val a = launch {
try {
repeat(1000) { i ->
println("Daily printing")
delay(500)
}
} finally {
println("Recycling resources")
}
}
delay(1000) //Delay for some time
println("Delayed end")
a.cancelAndJoin() //Cancel a job and wait for it to finish
}Suspend the coroutine again in finally
In our practical application, it may be necessary to suspend a cancelled collaboration in finally, so the corresponding code can be wrapped in **withContext(NoCancellable) * *
coroutineScope {
val a = launch {
try {
repeat(1000) { i ->
println("Daily printing")
delay(500)
}
} finally {
withContext(NonCancellable){
println("Suspend a canceled collaboration")
delay(1000)
println("Pending cancellation")
}
}
}
delay(1000)
println("Delayed end")
a.cancelAndJoin() //Cancel a job and wait for it to finish
}Timeout throw exception
Set the timeout and throw an exception if it exceeds the expected time. Can be used for countdown, etc
coroutineScope {
try {
withTimeout(1000){
println("Over 2000 ms Fail")
delay(2000)
}
}catch (e:TimeoutCancellationException){
println(e.message)
println("Okay, okay, I see")
}
}Over 2000 ms Fail Timed out waiting for 1000 ms Okay, okay, I see
Timeout throw null pointer
In some cases, you may not want to throw an exception directly, you can let it throw a null pointer
coroutineScope {
val time = withTimeoutOrNull(1000) {
println("Over 2000 ms Fail")
delay(2000)
}
println(time) //null
}Over 2000 ms Fail null
Combining pending functions
Call pending functions in default order
measureTimeMillis
suspend fun main() {
val time = measureTimeMillis {
playGame()
playPP()
}
println("Yes $time ms")
}
suspend fun playGame() {
delay(1000)
println("Beat beans for 1 second")
}
suspend fun playPP() {
delay(1000)
println("Hit the ass for 1 second")
}Beat beans for 1 second Hit the ass for 1 second After 2031 ms
async
Concurrent execution
In the above example, we execute in order, but in our actual development, we mostly want to execute in parallel. We can implement it with the help of async.
be careful
Conceptually, async It's similar to launch . It starts a separate coroutine, which is a lightweight thread and works concurrently with all other coroutines. The difference is that launch returns a Job And without any result value, async returns one Deferred ——A lightweight non blocking future, which represents a promise that will provide results later. You can use it await() gets its final result on a Deferred value, but Deferred is also a Job, so you can cancel it if necessary.
suspend fun main() {
measureTimeMillis {
coroutineScope {
async { playGame() }
async { playPP() }
}
}.let {
println("Time spent+ $it")
}
}
suspend fun playGame() {
delay(1000)
println("Beat beans for 1 second")
}
suspend fun playPP() {
delay(1000)
println("Hit the ass for 1 second")
}Beat beans for 1 second Hit the ass for 1 second Time spent+ 1084
Lazy start async
We can implement the lazy mode by changing the properties of async. In this mode, only through await or async's return value job Start to start Note: if await is called directly, the result will be sequential execution
suspend fun main() {
measureTimeMillis {
coroutineScope {
val game = async(start = LAZY) { playGame() }
val pp = async(start = LAZY) { playPP() }
game.start()
pp.start()
println("Start complete")
}
}.let(::println)
}
suspend fun playGame() {
delay(1000)
println("Beat beans for 1 second")
}
suspend fun playPP() {
delay(1000)
println("Hit the ass for 1 second")
}async style functions
We can define asynchronous style functions to call playGame and playPP asynchronously, and use async coprocessor builder with an explicit GlobalScope reference
suspend fun main() {
measureTimeMillis {
val somethingPlayGame = somethingPlayGame()
val somethingPlayPP = somethingPlayPP()
runBlocking {
somethingPlayGame.await()
somethingPlayPP.await()
}
}.let(::println)
}
fun somethingPlayGame() = GlobalScope.async {
playGame()
}
fun somethingPlayPP() = GlobalScope.async {
playPP()
}
suspend fun playGame() {
delay(1000)
println("Beat beans for 1 second")
}
suspend fun playPP() {
delay(1000)
println("Hit the ass for 1 second")
}Hit the ass for 1 second Beat beans for 1 second 1085
Note: This is not recommended. If val somethingPlayGame = somethingPlayGame() and somethingplaygame Await() has a logic error. The program will throw an exception, but somethingPlayPP is still executed in the background. However, because of the former exception, all coroutines will be closed, so the somethingPlayPP operation will also be terminated
The case is as follows:
...
suspend fun playGame() {
delay(500)
throw ArithmeticException("error")
println("Beat beans for 1 second")
}
...Exception in thread "main" java.lang.ArithmeticException: error at com.xiecheng_demo.java.TestKt.playGame(Test.kt:46) ....
Correct structured concurrency using async
Transfer according to the hierarchy of collaborative process
suspend fun main() {
runBlocking {
try {
test()
} catch (e: ArithmeticException) {
println("main-${e.message}")
}
}
}
suspend fun test() = coroutineScope {
async { playGame() }
async { playPP() }
}
suspend fun playGame() {
try {
delay(1000)
println("Beat beans for 1 second")
} finally {
println("I'm beating peas. In case of any abnormality...")
}
}
suspend fun playPP() {
delay(500)
throw ArithmeticException("Throw exception")
}I'm beating peas. In case of any abnormality... main-Throw exception
Note: if one of the child processes fails, the first playGame and the waiting parent process will be cancelled
Collaboration context and scheduler
A coroutine context is a collection of various elements. In fact, coroutine context is a context that stores the information of a coroutine
Scheduler
coroutineContext contains dispatchers, with which we can limit the working threads of the collaboration.
They are as follows:
- Dispatchers.Default thread
- Dispatchers. IO thread
- Dispatchers.Main main thread
- Dispatchers.Unconfined is unlimited and will run directly on the current thread
Subprocess
When a process is started by other processes in CoroutineScope, it will pass through CoroutineScope Coroutinecontext inherits the context, and the new collaboration will become the child operation of the parent collaboration. When a parent collaboration is cancelled, it also means that all child collaboration will be cancelled.
However, if you use globalscope If launch starts a child collaboration, it will be independent of the scope of the parent collaboration and run independently.
val a = GlobalScope.launch {
GlobalScope.launch {
println("use GlobalScope.launch start-up")
delay(1000)
println("GlobalScope.launch-Delayed end")
}
launch {
println("use launch start-up")
delay(1000)
println("launch-Delayed end")
}
}
delay(500)
println("Cancel parent launch")
a.cancel()
delay(1000)use GlobalScope.launch start-up use launch start-up Cancel parent launch GlobalScope.launch-Delayed end
join
Use join to wait for all subprocesses to complete the task.
suspend fun main() {
val a = GlobalScope.launch {
GlobalScope.launch {
println("use GlobalScope.launch start-up")
delay(1000)
println("GlobalScope.launch-Delayed end")
}
launch {
println("use launch start-up")
delay(1000)
println("launch-Delayed end")
}
}
a.join()
}In the main function above, globalscope The cooperative process started by the launch will be executed immediately and independently. If the join is not used, the main may be executed instantly, so the effect cannot be seen. Use the join method to pause the collaboration where the main is located until globalscope Launch execution completed.
Specify the process name
Use the + operator to specify
GlobalScope.launch(Dispatchers.Default+CoroutineName("test")){
println(Thread.currentThread().name)
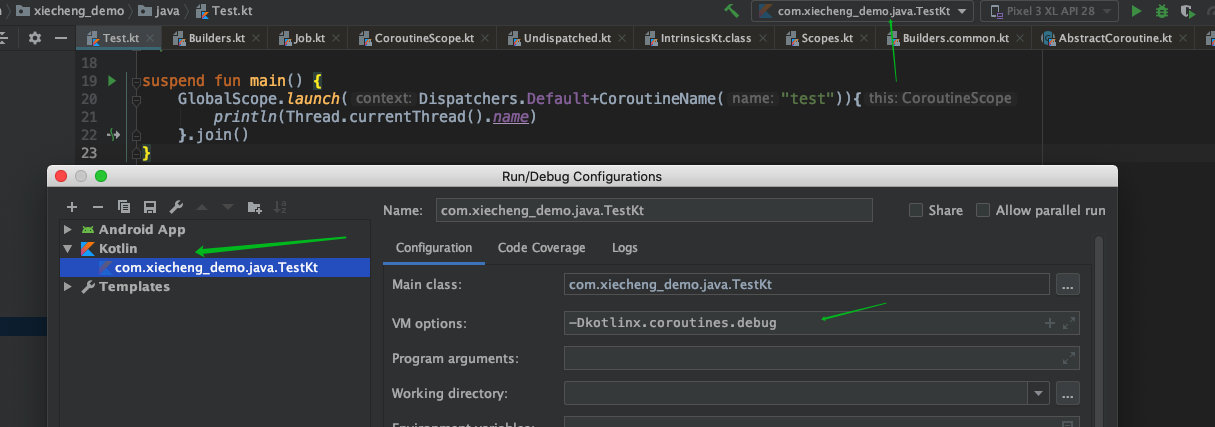
}.join()The jvm parameter - dkotlinx. DLL is used here coroutines. debug
How to configure jvm parameters: Android Studio,Intellij
Synergy scope
After we understand the above concepts, we begin to combine what we learned earlier. Define a global collaboration.
class Main4Activity : AppCompatActivity() {
private val mainScope = CoroutineScope(Dispatchers.Default)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main4)
btn_start.setOnClickListener {
mainScope.launch {
//After a wave of operation
launch(Dispatchers.Main) {
toast("one")
}
}
Log.e("demo","123")
mainScope.launch (Dispatchers.Main) {
delay(3000)
toastCenter("two")
}
}
btn_cancel.setOnClickListener {
onDestrxx()
}
}
fun onDestrxx() {
mainScope.cancel()
}
}We declare a CoroutineScope object in the Activity, and then create some scopes, so that when we destroy the Activity, we can destroy them all.
For the purpose of saving code
Effect: after clicking btn1 and then btn2, only one toast will pop up, and the second toast will not pop up
Thread local data
Some local data can be transferred to the collaboration process through threadloadcl.
suspend fun main() {
val threadLocal = ThreadLocal<String>()
threadLocal.set("main")
GlobalScope.launch(Dispatchers.Default+threadLocal.asContextElement(value = "123")) {
println("thread-${Thread.currentThread().name},value=${threadLocal.get()}")
println("thread-${Thread.currentThread().name},value=${threadLocal.get()}")
}.join()
println("thread-${Thread.currentThread().name},value=${threadLocal.get()}")
delay(1000)
println("thread-${Thread.currentThread().name},value=${threadLocal.get()}")
}thread-DefaultDispatcher-worker-1 @coroutine#1,value=123 thread-DefaultDispatcher-worker-1 @coroutine#1,value=123 thread-main,value=main thread-kotlinx.coroutines.DefaultExecutor,value=null
You may wonder * *, why after delay, threadload Get *? Please note that a suspend is added in front of the main function, and the main function is equivalent to the coprocessor body. When we directly call globalscope When launching, it runs directly and independently. At this time, the internal coroutineContext is passed manually. When we call delay, we directly suspend the coroutine. At this time, the coroutineContext in our main function is null by default, so get is null
Asynchronous flow
The suspend function can return a single value asynchronously, and how to return multiple calculated values is exactly where flow is used
Use list to represent multiple values
fun foo(): List<Int> = listOf(1, 2, 3)
fun main() {
foo().forEach { value -> println(value) }
}1 2 3
We can see that the corresponding values are returned together in an instant. What if we need them to return individually?
Use Sequence to represent multiple values
Using Sequence can achieve synchronous return data, but it also blocks the thread
fun main() {
foo().forEach(::println)
}
fun foo():Sequence<Int> = sequence {
println(System.currentTimeMillis())
for (i in 1..3){
Thread.sleep(300)
//yield generates a value and suspends waiting for the next call
yield(i)
}
println(System.currentTimeMillis())
}1578822422344 1 //->Interval 300ms 2 //->Interval 300ms 3 //->Interval 300ms 1578822423255
Suspend function
The function that uses the suspend flag is the suspended function. For the compiler, suspend is just a sign.
In our code above, suspend is something we often see.
Flow
Using list to return results means that we will return all values at once. Although using Sequence can return synchronously, if there are time-consuming operations, our threads will be blocked.
flow is the solution to the above disadvantages.
fun main() {
runBlocking {
logThread()
launch {
logThread()
for (i in 1..3) {
println("lauch block+$i")
delay(100)
}
}
logThread()
foo().collect { value ->
println(value)
}
}
}
fun foo(): Flow<Int> = flow {
for (i in 1..3) {
delay(100)
emit(i)
}
}
fun logThread() = println("Current thread----${Thread.currentThread().name}")Current thread----main @coroutine#1
Current thread----main @coroutine#1
Current thread----main @coroutine#2 //lauch{}
lauch block+1
1
lauch block+2
2
lauch block+3
3Code in flow {} can be suspended Use emit() function Use the collect function to collect values. (it can be considered as startup)
Cancel Flow
Canceling a Flow is actually canceling the collaboration process. We can't cancel the Flow directly, but we can achieve the goal by canceling the collaboration process where the Flow is located.
Observing the above demo, if we print the thread in foo() method, we will find that the thread is the same as runBlocking, that is, foo() uses runBlocking context.
We changed the code as follows:
fun main(){
...
withTimeoutOrNull(200){
foo().collect { value ->
println(value)
}
}
...
}
...Current thread----main @coroutine#1 Current thread----main @coroutine#2 lauch block+1 1 lauch block+2 lauch block+3
Why is lauch still running? As we have said before, launch {} runs a coroutine independently and has nothing to do with the parent coroutine. Therefore, launch {} is not affected by cancellation at this time
Flow builder
flowOf
Defines a stream that emits a fixed set of values
flowOf("123","123").collect{
value ->
println(value)
}asFlow
Used to convert various sets and sequences into Flow
(1..3).asFlow().collect{value-> println(value)}Transitional flow operator
map
Data conversion using map
runBlocking {
(1..3).asFlow()
.map {
delay(1000)
"f-$it"
}
.collect { value -> println(value) }
}Conversion Operators
transform
Using transform, we can emit a string and track the response before executing an asynchronous request
runBlocking {
(1..3).asFlow()
.transform {
request ->
emit("test-$request")
//time-consuming operation
delay(500)
emit(request)
}
.collect { value -> println(value) }
}test-1 1 test-2 2 test-3 3
Length limiting operator
When the flow touches the corresponding limit, its execution will be cancelled. The cancellation operation in the collaboration process is always executed by throwing an exception, so that all resource management function (try{},finally {} blocks will run normally when cancelled
take
Gets the number of launches of the specified number. When the upper limit is reached, the launch will be stopped
runBlocking {
(1..3).asFlow()
.take(1)
.collect { value -> println(value) }
}1 //There was only one result
End flow operator
toList
//toList
runBlocking {
(1..3).asFlow()
.toList().let(::println)
}[1, 2, 3]
toSet
//toSet
runBlocking {
(1..3).asFlow()
.toSet().let(::println)
}[1, 2, 3]
first
Reduce the flow to a single value. That is, only the first data is sent
runBlocking {
(1..3).asFlow()
.first().let(::println)
}1
single
Reduce the flow to a single value. That is, only the first data is sent. The difference is that if more than one data is sent, an IllegalStateException will be thrown
//single
runBlocking {
flowOf(1,2).single().let(::println)
//flowOf(1).single().let(::println)
}1 Exception in thread "main" java.lang.IllegalStateException: Expected only one element
reduce
Data accumulation
runBlocking {
(1..3).asFlow()
.reduce { a, b -> a + b }.let(::println)
}6
fold
The convection is accumulated and the data is accumulated. Unlike reduce, fold can be assigned an initial value
runBlocking {
(1..3).asFlow()
.fold(10) {acc, i -> acc + i }.let(::println)
}16
The flow is continuous
In kotlin, flows are executed sequentially. Each transition operator from upstream to downstream processes each emitted value and then passes it to the end operator.
The simple understanding is to execute from top to bottom. The following operators will be executed only when the upstream conditions are met.
(1..5).asFlow()
.filter {
println("filter=$it")
it % 2 == 0
}
.map {
println("map=$it")
"map-$it"
}
.collect {
println(
"collect-$it"
)
}filter=1 filter=2 map=2 collect-map-2 filter=3 filter=4 map=4 collect-map-4 filter=5
Examples of errors in Flow
In a workflow, withContext is usually used to switch the context (it is not accurate to simply understand the switching thread, because the context of the workflow contains a lot of data, such as value, which is usually used to switch threads). However, the code in the flow {} builder must follow the context saving attribute (that is, it is not allowed to change the context), And it is not allowed to transmit data from other contexts (it is not allowed to transmit from other launch {}).
But it can be changed through flowOn
Error case 1: change context
fun main() {
runBlocking {
flow {
withContext(Dispatchers.Default) {
for (i in 1..3) {
delay(100)
emit(i)
}
}
}.collect().let(::println)
}
}Exception in thread "main" java.lang.IllegalStateException: Flow invariant is violated:
Flow was collected in [CoroutineId(1), "coroutine#1":BlockingCoroutine{Active}@1f88ae32, BlockingEventLoop@32db9536],
but emission happened in [CoroutineId(1), "coroutine#1":DispatchedCoroutine{Active}@77a8c47e, DefaultDispatcher].
Please refer to 'flow' documentation or use 'flowOn' instead
...Error case 2: transmitting data from another context
fun main() {
runBlocking {
flow {
launch {
emit(123)
emit(123)
emit(123)
}
delay(100)
}.collect {
println(it)
}
}
}Exception in thread "main" java.lang.IllegalStateException: Flow invariant is violated:
Emission from another coroutine is detected.
Child of "coroutine#2":StandaloneCoroutine{Active}@379619aa, expected child of "coroutine#1":BlockingCoroutine{Active}@cac736f.
FlowCollector is not thread-safe and concurrent emissions are prohibited.
To mitigate this restriction please use 'channelFlow' builder instead of 'flow'
at
...flowOn
Used to change the context of stream emission.
fun main() {
runBlocking {
logThread()
flow {
for (i in 1..3) {
logThread()
emit(i)
delay(10)
}
}.flowOn(Dispatchers.IO).collect {
println(it)
}
}
}Current thread----main @coroutine#1 Current thread----DefaultDispatcher-worker-1 @coroutine#2 1 Current thread----DefaultDispatcher-worker-1 @coroutine#2 2 Current thread----DefaultDispatcher-worker-1 @coroutine#2 3
Here, we collect data in the main thread and transmit data in the IO thread. It also means that our collection and launch are in two processes at this time.
Buffer
The emission and collection of streams are usually performed in sequence. Through the above, we found that running different parts of the stream in different processes will greatly reduce the time. But now if we don't use flowOn, the time taken to emit a stream and collect a stream will add up.
For example, it takes 100ms to transmit a stream and 200ms to collect, so it takes at least 900ms to send three streams and collect+
fun main() {
runBlocking {
val start=System.currentTimeMillis()
flow {
for (i in 1..3) {
emit(i)
delay(100)
}
}.collect {
delay(300)
println(it)
}
println("Spend time-${System.currentTimeMillis()-start}ms")
}
}1 2 3 Spend time-1230ms
We can use the buffer operator on the stream to run data transmission and collection concurrently, rather than sequentially
The change code is as follows:
fun main() {
runBlocking {
val start = System.currentTimeMillis()
flow {
for (i in 1..3) {
logThread()
emit(i)
delay(100)
}
}.buffer().collect {
logThread()
delay(300)
println(it)
}
println("Spend time-${System.currentTimeMillis() - start}ms")
}
}Current thread----main @coroutine#2 Current thread----main @coroutine#1 Current thread----main @coroutine#2 Current thread----main @coroutine#2 1 Current thread----main @coroutine#1 2 Current thread----main @coroutine#1 3 Spend time-961ms
We found that, in fact, buffer switches threads internally, that is, buffer and flowOn use the same caching mechanism, but buffer does not significantly change the context.
merge
conflate
Used to skip intermediate values and process only the latest values.
fun main() {
measureTimeMillis {
runBlocking {
(1..5).asFlow()
.conflate()
.buffer()
.collect {
delay(100)
println(it)
}
}
}.let{
println("Spend time-${it}ms")
}
}1 5 Spend time-325ms
Process latest value
collectLatest & conf
Cancel the slow collector and restart it every time a new value is emitted.
fun main() {
measureTimeMillis {
runBlocking {
(1..5).asFlow()
.collectLatest {
println(it)
delay(100)
println("Re launch-$it")
}
}
}.let {
println("Spend time-${it}ms")
}
}1 2 3 4 5 Re launch-5 Spend time-267ms
Combined flow
zip
Combine related values in two streams
fun main() {
measureTimeMillis {
val strs= flowOf("one","two","three")
runBlocking {
(1..5).asFlow()
.zip(strs){
a,b ->
"$a -> $b"
}.collect { println(it) }
}
}.let {
println("Spend time-${it}ms")
}
}1 -> one 2 -> two 3 -> three Spend time-120ms
Combine
suspend fun main() {
val nums = (1..3).asFlow().onEach { delay(300) } // Transmit digital 1 3. 300 ms interval
val strs = flowOf("one", "two", "three").onEach { delay(400) } // The string is emitted every 400 milliseconds
val startTime = System.currentTimeMillis() // Record start time
nums.combine(strs) { a, b -> "$a -> $b" } // Use "zip" to combine individual strings
.collect { value -> // Collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
}1 -> one at 472 ms from start 2 -> one at 682 ms from start 2 -> two at 874 ms from start 3 -> two at 987 ms from start 3 -> three at 1280 ms from start
Channel channel
- Non blocking communication infrastructure
- Similar to BlockingQueue+suspend
Provides a method to transfer data in Flow
Channel classification
classification | describe |
|---|---|
RENDEZVOUS | See you later, hang up after the send call until the receive arrives |
UNLIMITED | Unlimited capacity, returned directly after the send call |
CONFLATED | Keep up-to-date. reveive can only get the value of the latest send |
BUFFERED | Default capacity. You can set the default size through the program parameters. The default size is 64 |
FIXED | Fixed capacity, execute cache size through parameters |
Channel foundation
suspend fun main() {
runBlocking {
val channel = Channel<Int>()
launch {
// Here may be asynchronous logic that consumes a lot of CPU operations. We will only square the integer five times and send it
for (x in 1..5) channel.send(x * x)
}
// Here we print the received integers five times:
repeat(5) { println(channel.receive()) }
println("Done!")
}
}1 4 9 16 Done!
channel closure and iteration
suspend fun main() {
runBlocking {
val channel = Channel<Int>()
launch {
// Here may be asynchronous logic that consumes a lot of CPU operations. We will only square the integer five times and send it
for (x in 1..5) {
channel.send(x * x)
}
channel.close()
println("Is the channel closed+${channel.isClosedForSend}")
}
for (i in channel) {
println(i)
}
println("Did you receive all the data+${channel.isClosedForReceive}")
}
}1 4 9 16 25
consumeEach
To replace the for loop
suspend fun main() {
runBlocking {
val channel = Channel<Int>()
launch {
// Here may be asynchronous logic that consumes a lot of CPU operations. We will only square the integer five times and send it
for (x in 1..5) {
channel.send(x * x)
}
channel.close()
}
channel.consumeEach(::println)
}
}Co process Builder of Channel
- Produce starts a producer collaboration and returns to ReceiveChannel
- actor: start a consumer collaboration and return to SendChannel (temporarily abandoned)
- The corresponding Channel of the above collaboration Builder is automatically closed
Produce
suspend fun main() {
val receiveChannel = GlobalScope.produce(capacity = Channel.UNLIMITED) {
for (i in 0..3) {
send(i)
}
}
GlobalScope.launch {
receiveChannel.consumeEach(::println)
}.join()
}0 1 2 3
actor
suspend fun main() {
val sendChannel = GlobalScope.actor<Int>(capacity = Channel.UNLIMITED) {
channel.consumeEach(::println)
}
GlobalScope.launch {
for (i in 1..3){
sendChannel.send(i)
}
}.join()
}BroadcastChannel
- Channel elements can only be consumed by one consumer
- The elements of BroadcastChannel can be distributed to all subscribers
- BroadcastChannel does not support RENDEZVOUS
suspend fun main() {
val broadcastChannel = GlobalScope.broadcast {
for (i in 1..3)
send(i)
}
List(3) {
GlobalScope.launch {
val receiveChannel = broadcastChannel.openSubscription()
println("-----$it")
receiveChannel.consumeEach(::println)
}
}.joinAll()
}-----2 -----0 -----1 1 1 1 2 2 3 3 2 3
Select (experimental)
- It is a concept of IO multiplexing
- Multiplexing for suspending functions in koltin
The Select expression can wait for multiple pending functions at the same time and Select the first available function
Use in Channel
suspend fun main() {
runBlocking {
val fizz = fizz()
val buzz = buzz()
repeat(7) {
selectFizzBuzz(fizz, buzz)
}
coroutineContext.cancelChildren()
}
}
suspend fun selectFizzBuzz(fizz: ReceiveChannel<String>, buzz: ReceiveChannel<String>) {
select<Unit> {
// < unit > means that the select expression does not return any results
fizz.onReceive { value ->
// This is the first select clause
println("fizz -> '$value'")
}
buzz.onReceive { value ->
// This is the second select clause
println("buzz -> '$value'")
}
}
}
@ExperimentalCoroutinesApi
fun CoroutineScope.fizz() = produce {
while (true) {
delay(300)
send("Fizz")
}
}
@ExperimentalCoroutinesApi
fun CoroutineScope.buzz() = produce {
while (true) {
delay(500)
send("Buzz")
}
}fizz -> 'Fizz' buzz -> 'Buzz' fizz -> 'Fizz' fizz -> 'Fizz' buzz -> 'Buzz' fizz -> 'Fizz' buzz -> 'Buzz'
Using the receive suspend function, we can receive data from one of the two channels, but select allows us to receive data from both channels at the same time using its onReceive clause. Note: onReceiver will fail to execute the closed channel and throw an exception. We can use onReceiveOrNull clause to perform specific operations when closing the channel