
grammar
In the previous article, we wrote a simple lexical analyzer. See the article for details( Kotlin writes an interpreter (1) - lexical analysis ), with words, how to combine these words into correct sentences? Here is what grammar analysis should do. First, what is grammar? In short, grammar is the rules of using words to form sentences. For example, our common sentence structure in Chinese is generally composed of subject + predicate + object. For example, Xiao Ming plays games, in which Xiao Ming belongs to noun according to the part of speech. Here, as the subject, play is a verb according to the part of speech, belonging to predicate, and the game is a noun according to the part of speech, belonging to object. The purpose of grammar analysis is to judge whether it meets the corresponding grammar requirements according to the sequence of lexical units obtained from previous lexical analysis.
Context free syntax
How to express a grammar? In the compiler process, we often use a symbolic representation called context free grammar. Context free grammar describes a series of rules to represent how statements are formed. Take the above grammatical rules of subject predicate object as an example.
Sentence - > subject predicate object
Subject predicate
Subject - > NOUN
Predicate - > verb
Object - > NOUN | adjective
In the above description, a series of grammatical rules are described, each of which represents a production, the left side of the arrow is the production head, the right side of the arrow is the production, all italics represent non terminators, which are used to represent a grammatical variable, non italics represent terminators, and each word is a terminator, | represents or, The purpose of grammar analysis is to judge whether the input word stream is a legal statement in the programming language according to the input word stream and the corresponding grammar rules.
Another knowledge point is what is context free. When applying a production formula for derivation, part of the result that has been deduced before and after is context. Context free means that as long as there is a production in the definition of grammar, no matter what the string before and after a non terminator is, the corresponding production can be used for derivation. For example, if there are contextual constraints, this sentence is actually a sick sentence. It should be people playing with water, but according to our grammar rules, water can be used as the subject, play can be used as the predicate, and people can be used as the object. It is a sentence in line with our grammar rules.
Four arithmetic syntax expression
Next, let's talk about the grammatical expression of the four operations. First, let's talk about the syntax of addition and subtraction
exp->factor((+|-)factor)*
factor->NUMBER
Where exp and factor are non terminators, NUMBER, +, - are terminators, and * represents 0 or more ((+ | -) factors in front.
For the derivation of 2 + 3
exp
|
factor((+|-)factor)*
|
factor+factor
|
NUMBER+NUMBER
|
2+3
The above shows a complete derivation process of exp syntax. As long as the final derivation result is consistent with the lexical stream data of lexical analyzer, the syntax is correct.
Associativity
Considering the expression of 1 + 2 + 3, it is actually the same as (1 + 2) + 3 in calculation, and 1-2-3 and (1-2) - 3 are the same. Even multiplication and even division are similar. For 2, when there are the same operators on its left and right sides (such as +), we need to determine which operator is applicable to 2. We specify + as the operator of left combination, and 2 and + on the left are combined together, which is equivalent to (1 + 2) + 3, We call this kind of symbol left combined. In addition to left combined, naturally there are right combined.
priority
The priority of primary school students should know that multiplication and division first, and then addition and subtraction. 2 + 3 * 7 is equivalent to 2 + (3 * * 7) rather than (2 + 3) * 7. From the perspective of priority, the priority of multiplication and division is higher than that of addition and subtraction.
grammatical representation
For the design of priority syntax, one rule is to define a non terminator for each priority. The body of the non terminal product shall contain the arithmetic operator of this level and the non terminator of the next higher priority. Create an additional non terminating factor for the basic unit of expression (in our case, an integer). The general rule is that if you have n priorities, you will need a total of N + 1 non terminators: one non terminator for each priority, plus one non terminator for the basic expression unit. So our final four arithmetic syntax production formulas are as follows.
exp->term((+|-)term)*
term->factor((|/)factor)
factor->NUMBER
Abstract syntax tree
In this issue, our parser will produce an abstract syntax analysis tree. The abstract syntax tree is a data structure of the tree and an intermediate expression form of the compiler. The interpreter in the next article is used to analyze the abstract syntax tree and generate the corresponding results. For the arithmetic expression 1 + 2 * (3 + 4), the corresponding abstract syntax tree is
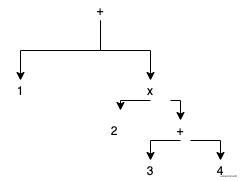
Because when we write the interpreter for calculation, we will get all elements by subsequent traversal of the abstract syntax tree, so as long as we ensure that the depth of the algorithm with high priority is deeper than that of others, we can ensure that it is calculated first.
code
Syntax tree node representation
open class AST {
}
class BinOp(val left: AST, val op: Token, val right: AST) : AST() {
override fun toString(): String {
val sb = StringBuilder()
sb.append(op.value).append("\n").append(left.toString()).append(" ").append(right.toString())
return sb.toString()
}
}
class Num(val token: Token) : AST() {
override fun toString(): String = token.value
}
Here, first define a base class node AST, each operator corresponds to a BinOp node, there are two member variables, and each number corresponds to a Num node
Syntax parser
class Parser(val lexer: Lexer) {
private var curToken: Token = lexer.getNextToken()
fun parse(): AST = exp()
private fun eat(tokenType: TokenType) {
if (tokenType == curToken.tokenType) {
curToken = lexer.getNextToken()
} else {
throw RuntimeException("TokenType yes ${tokenType.value}Syntax format error")
}
}
private fun exp(): AST {
var node = term()
while (TokenType.MIN == curToken.tokenType || TokenType.PLUS == curToken.tokenType) {
val tmpToken = curToken
if (TokenType.MIN == curToken.tokenType) {
eat(TokenType.MIN)
} else {
eat(TokenType.PLUS)
}
node = BinOp(node, tmpToken, term())
}
return node
}
fun term(): AST {
var node = factor()
while (TokenType.MUL == curToken.tokenType || TokenType.DIV == curToken.tokenType) {
val tmpToken = curToken
if (TokenType.MUL == curToken.tokenType) {
eat(TokenType.MUL)
} else if (TokenType.DIV == curToken.tokenType) {
eat(TokenType.DIV)
}
node = BinOp(node, tmpToken, factor())
}
return node
}
fun factor(): AST {
val tmpToken = curToken
return when {
TokenType.NUMBER == curToken.tokenType -> {
eat(TokenType.NUMBER)
Num(tmpToken)
}
TokenType.LBRACKETS==curToken.tokenType -> {
eat(TokenType.LBRACKETS)
val node = exp()
eat(TokenType.RBRACKETS)
node
}
else -> {
throw RuntimeException("TokenType yes ${curToken.value}Syntax format error")
}
}
}
}
Here are the guidelines for converting syntax into source code. By following them, you can literally convert the syntax to a valid parser:
1. Each rule R defined in the syntax will become a method with the same name, and the reference to the rule will become a method call: R(), such as exp(),term(),factor()
2. Replace (a1 | a2 | aN) with an if elif else statement, as in exp
if (TokenType.MIN == curToken.tokenType) { eat(TokenType.MIN) } else { eat(TokenType.PLUS) }
3. Replace (...) * with a while statement, which can cycle zero or more times, such as in exp
while (TokenType.MIN == curToken.tokenType || TokenType.PLUS == curToken.tokenType)
4. When the terminator is encountered (here is NUMBER), call the eat () method. The working mode of the eat method is to obtain a new token from the lexical analyzer and assign it to the curToken internal variable if the token type of the parameter is the same as that of the current token.
Test code
fun main() {
while (true) {
val scanner = Scanner(System.`in`)
val text = scanner.nextLine()
val lexer = Lexer(text)
// var nextToken = lexer.getNextToken()
// while (TokenType.EOF != nextToken.tokenType) {
// println(nextToken.toString())
// nextToken = lexer.getNextToken()
// }
val parser = Parser(lexer)
val ast = parser.parse()
println(ast)
}
}

Related articles
The code has been uploaded to github and will be updated in the future CompilerDemo
Kotlin writes an interpreter (1) - lexical analysis
Tomorrow is may day. I wish you guys a happy may day

Pay attention to my official account: old arsenic on skateboards