Preface
In the previous articles, PCA and SVD dimensionality reduction are shared. Today, another dimensionality reduction method, auto encoding, is shared.
What is self coding
Self coding is a data compression algorithm. The characteristics of encoder and decoder are as follows:
- For specific data
- Lossy compression
- Automatic learning The encoder and decoder of self coding are realized by neural network.
- Self coding is for specific data, which means that it can only compress similar data. If you train with pictures, then you can't compress sound.
- Self coding is lossy compression. Input and output are not exactly the same when training. The purpose of training is to find the parameters of minimum loss.
- Self coding is automatic learning. This advantage is that you don't need too much domain knowledge. For example, you can give you a bunch of graphs to train. You can throw in the train no matter what the graph is. Of course, the effect or speed can't be guaranteed.
Self coding consists of two important parts: encoder and decoder.
The network structure is as follows:
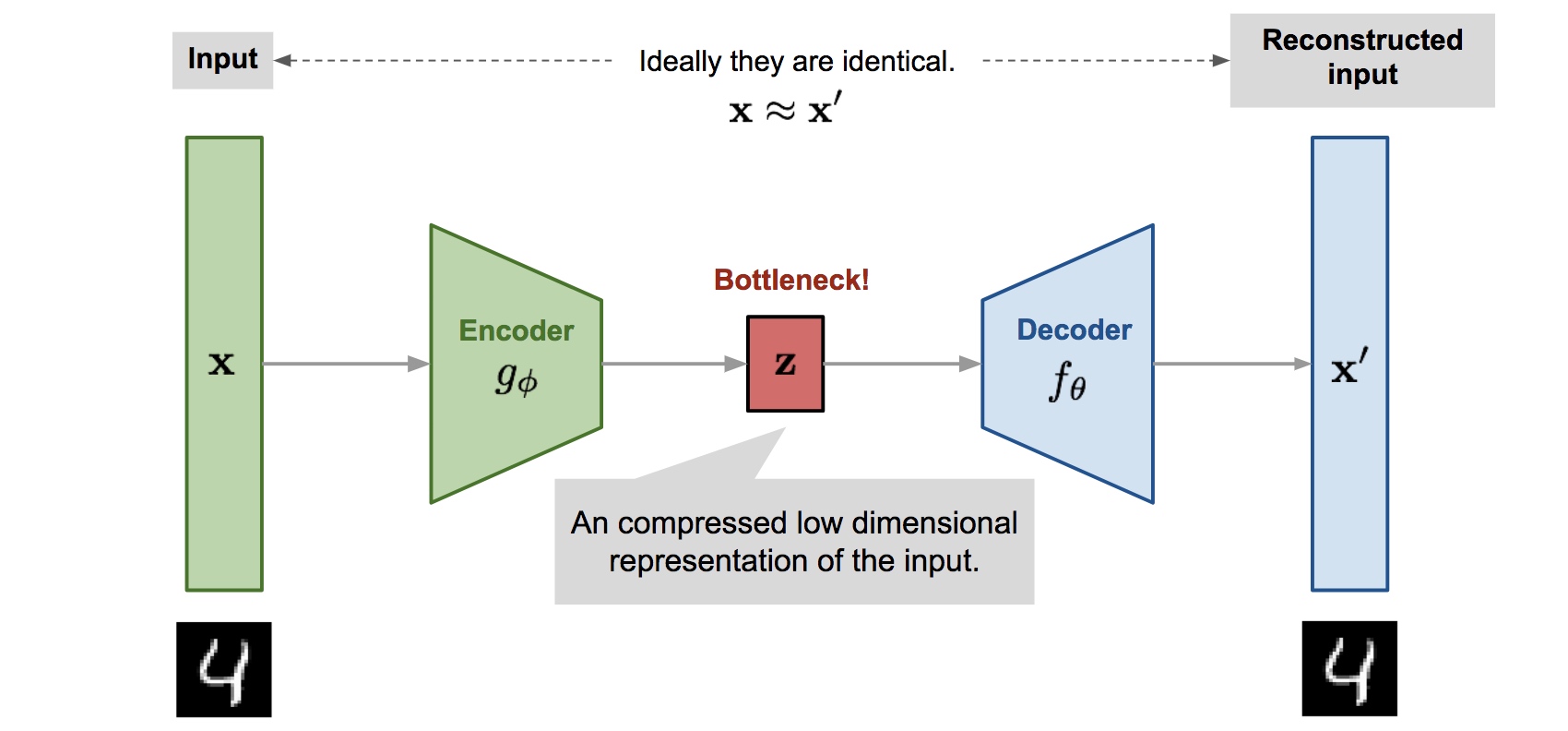
- encoder: compress the input data to the specified dimension
- decoder: restore the compressed data to the original data The main task of training is to find the parameters of encoder and decoder so as to minimize the difference between the original data and the decoded result data, that is, to minimize the loss.
What can I do with my own code
First of all, self coding can not be used to compress pictures. Self coding only compresses data dimensions, so that the data of these dimensions can also represent the original data. The purpose of picture compression is to extract some pixels, which looks like the original pictures as much as possible. It looks like it's different from the representativeness of data, not exactly the same. For example, in the following figure, is the color of the upper color block the same as that of the lower color block? It's the same with computers.

What can self coding be used for? The following content comes from Baidu Encyclopedia and is applied to dimension reduction and abnormal detection. The self encoder including convolutional layer can be applied to computer vision problems, including image denoising, neural style transfer and so on. Actually, I only care about dimensionality reduction~
Here is the code
The data here is still the user data of ktv app, with 3748 users and 16692 song records.
song_hot_matrix.shape # (3748, 16692)
The purpose of the training is to judge whether the user is male or female.
decades_hot_matrix.shape # (3748, 2)
Train an encoder first
The coding dimension here is 500 dimensions. In fact, the accuracy of 300 dimensions I tried is the same.
import os # Disable gpu os.environ["CUDA_VISIBLE_DEVICES"] = "-1" from keras.layers import Input, Dense from keras.models import Model from sklearn.model_selection import train_test_split train_X,test_X, train_Y, test_Y = train_test_split(song_hot_matrix, decades_hot_matrix, test_size = 0.2, random_state = 0) encoding_dim = 500 input_matrix = Input(shape=(song_hot_matrix.shape[1],)) encoded = Dense(encoding_dim, activation='relu')(input_matrix) decoded = Dense(song_hot_matrix.shape[1], activation='sigmoid')(encoded) autoencoder = Model(input_matrix, decoded) autoencoder.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # train embeding_model = autoencoder.fit(train_X, train_X, epochs=50, batch_size=256, shuffle=True, validation_data=(test_X, test_X)) # Get an encoder encoder = Model(input_img, encoded)
Result:
# 2998/2998 [==============================] - 2s 679us/step - loss: 0.0092 - accuracy: 0.9984 - val_loss: 0.0316 - val_accuracy: 0.9982 Epoch 49/50 # 2998/2998 [==============================] - 2s 675us/step - loss: 0.0091 - accuracy: 0.9984 - val_loss: 0.0313 - val_accuracy: 0.9982 Epoch 50/50 # 2998/2998 [==============================] - 2s 694us/step - loss: 0.0090 - accuracy: 0.9984 - val_loss: 0.0312 - val_accuracy: 0.9982
In terms of the loss of decoding, it is OK.
Training model with logistic regression
# Coding training data and test data train_X_em = encoder.predict(train_X) test_X_em = encoder.predict(test_X) # Using logistic regression training to judge gender model from keras.models import Sequential from keras.layers import Dense, Activation, Embedding,Flatten,Dropout train_count = np.shape(train_X)[0] # Building neural network model model = Sequential() model.add(Dense(input_dim=train_X_em.shape[1], units=train_Y.shape[1])) model.add(Activation('softmax')) # Select loss function and optimizer model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(train_X_em, train_Y, epochs=250, batch_size=256, shuffle=True, validation_data=(test_X_em, test_Y))
Result:
# 2998/2998 [==============================] - 0s 13us/step - loss: 0.4151 - accuracy: 0.8266 - val_loss: 0.4127 - val_accuracy: 0.8253 Epoch 248/250 # 2998/2998 [==============================] - 0s 13us/step - loss: 0.4149 - accuracy: 0.8195 - val_loss: 0.4180 - val_accuracy: 0.8413 Epoch 249/250 # 2998/2998 [==============================] - 0s 13us/step - loss: 0.4163 - accuracy: 0.8225 - val_loss: 0.4131 - val_accuracy: 0.8293 Epoch 250/250 # 2998/2998 [==============================] - 0s 13us/step - loss: 0.4152 - accuracy: 0.8299 - val_loss: 0.4142 - val_accuracy: 0.8293
Verification
def pred(song_list=[]): blong_hot_matrix = song_label_encoder.encode_hot_dict({"bblong":song_list}, True) blong_hot_matrix = encoder.predict(blong_hot_matrix) y_pred = model.predict_classes(blong_hot_matrix) return user_decades_encoder.decode_list(y_pred) print(pred(["All the way to the North", "Secret fragrance", "Chrysanthemum terrace"])) print(pred(["Don't talk", "Ordinary road", "Li Bai"])) print(pred(["Contented", "Summer Breeze ", "Tornado"])) print(pred(["Lover","Bye","Scoundrel","Leaving","Your appearance"])) print(pred(["Little love songs","I miss you so much","Incomparable Beauty "])) print(pred(["Apprehension","The Hottest Ethnic Trend","Little apple"])) print(pred(["Youth cultivation manual","Love starts","Pet","Magic Castle","kind"]))
Result
['male'] ['male'] ['male'] ['male'] ['female'] ['male'] ['female']
summary
Another data compression method, self coding, is used to compress the data. From the result, 500 dimensional features can represent the overall characteristics of the data.