5. Detailed explanation of pod
5.1 Pod introduction
5.1.1 Pod structure
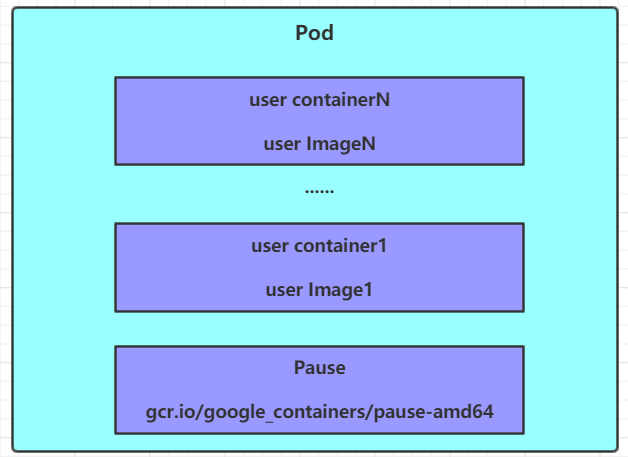
Each Pod can contain one or more containers, which can be divided into two categories:
-
The number of containers where the user program is located can be more or less
-
Pause container, which is a root container for each Pod. It has two functions:
-
It can be used as a basis to evaluate the health status of the whole Pod
-
The Ip address can be set on the root container, and other containers can use this Ip (Pod IP) to realize the network communication within the Pod
Here is Pod Internal communications, Pod The communication between is realized by virtual two-layer network technology. Our current environment uses Flannel
-
5.1.2 definition of pod
The following is a list of Pod resources:
apiVersion: v1 #Required, version number, e.g. v1
kind: Pod #Required, resource type, such as Pod
metadata: #Required, metadata
name: string #Required, Pod name
namespace: string #The namespace to which the Pod belongs. The default is "default"
labels: #Custom label list
- name: string
spec: #Required, detailed definition of container in Pod
containers: #Required, container list in Pod
- name: string #Required, container name
image: string #Required, the image name of the container
imagePullPolicy: [ Always|Never|IfNotPresent ] #Get the policy of the mirror
command: [string] #The list of startup commands of the container. If not specified, the startup commands used during packaging shall be used
args: [string] #List of startup command parameters for the container
workingDir: string #Working directory of the container
volumeMounts: #Configuration of storage volumes mounted inside the container
- name: string #Refer to the name of the shared storage volume defined by the pod. The volume name defined in the volumes [] section is required
mountPath: string #The absolute path of the storage volume mount in the container should be less than 512 characters
readOnly: boolean #Is it read-only mode
ports: #List of port library numbers to be exposed
- name: string #Name of the port
containerPort: int #The port number that the container needs to listen on
hostPort: int #The port number that the host of the Container needs to listen to. It is the same as the Container by default
protocol: string #Port protocol, support TCP and UDP, default TCP
env: #List of environment variables to be set before the container runs
- name: string #Environment variable name
value: string #Value of environment variable
resources: #Setting of resource limits and requests
limits: #Resource limit settings
cpu: string #Cpu limit, in the number of core s, will be used for the docker run -- Cpu shares parameter
memory: string #Memory limit. The unit can be Mib/Gib. It will be used for the docker run --memory parameter
requests: #Settings for resource requests
cpu: string #Cpu request, initial available quantity of container startup
memory: string #Memory request, initial available number of container starts
lifecycle: #Lifecycle hook
postStart: #This hook is executed immediately after the container is started. If the execution fails, it will be restarted according to the restart policy
preStop: #Execute this hook before the container terminates, and the container will terminate regardless of the result
livenessProbe: #For the setting of health check of each container in the Pod, when there is no response for several times, the container will be restarted automatically
exec: #Set the inspection mode in the Pod container to exec mode
command: [string] #Command or script required for exec mode
httpGet: #Set the health check method of containers in Pod to HttpGet, and specify Path and port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #Set the health check mode of containers in the Pod to tcpSocket mode
port: number
initialDelaySeconds: 0 #The time of the first detection after the container is started, in seconds
timeoutSeconds: 0 #Timeout for container health check probe waiting for response, unit: seconds, default: 1 second
periodSeconds: 0 #Set the periodic detection time for container monitoring and inspection, in seconds, once every 10 seconds by default
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Restart strategy of Pod
nodeName: <string> #Setting NodeName means that the Pod is scheduled to the node node with the specified name
nodeSelector: obeject #Setting NodeSelector means scheduling the Pod to the node containing the label
imagePullSecrets: #The secret name used to Pull the image, specified in the format of key: secret key
- name: string
hostNetwork: false #Whether to use the host network mode. The default is false. If it is set to true, it means to use the host network
volumes: #Define a list of shared storage volumes on this pod
- name: string #Shared storage volume name (there are many types of volumes)
emptyDir: {} #The storage volume of type emtyDir is a temporary directory with the same life cycle as Pod. Null value
hostPath: string #The storage volume of type hostPath represents the directory of the host where the Pod is mounted
path: string #The directory of the host where the Pod is located will be used for the directory of mount in the same period
secret: #For the storage volume of type secret, mount the cluster and the defined secret object inside the container
scretname: string
items:
- key: string
path: string
configMap: #The storage volume of type configMap mounts predefined configMap objects inside the container
name: string
items:
- key: string
path: string
#Tip: # Here, you can view the configurable items of each resource through a command # kubectl explain resource type view the first level attributes that can be configured for a resource # kubectl explain resource type. View the sub attributes of the attribute [root@k8s-master01 ~]# kubectl explain pod KIND: Pod VERSION: v1 FIELDS: apiVersion <string> kind <string> metadata <Object> spec <Object> status <Object> [root@k8s-master01 ~]# kubectl explain pod.metadata KIND: Pod VERSION: v1 RESOURCE: metadata <Object> FIELDS: annotations <map[string]string> clusterName <string> creationTimestamp <string> deletionGracePeriodSeconds <integer> deletionTimestamp <string> finalizers <[]string> generateName <string> generation <integer> labels <map[string]string> managedFields <[]Object> name <string> namespace <string> ownerReferences <[]Object> resourceVersion <string> selfLink <string> uid <string>
In kubernetes, the primary attributes of almost all resources are the same, mainly including five parts:
- The apiVersion version is internally defined by kubernetes. The version number must be available through kubectl API versions
- kind type is internally defined by kubernetes. The version number must be available through kubectl API resources
- Metadata metadata, mainly resource identification and description, commonly used are name, namespace, labels, etc
- spec description, which is the most important part of configuration, contains a detailed description of various resource configurations
- Status status information, the contents of which do not need to be defined, is automatically generated by kubernetes
Among the above attributes, spec is the focus of next research. Continue to look at its common sub attributes:
- Containers < [] Object > container list, used to define container details
- NodeName schedules the pod to the specified Node according to the value of nodeName
- NodeSelector < map [] > select and schedule the Pod to the Node containing these label s according to the information defined in NodeSelector
- Whether the hostNetwork uses the host network mode. The default is false. If it is set to true, it indicates that the host network is used
- Volumes < [] Object > storage volume is used to define the storage information hung on the Pod
- restartPolicy is the restart policy, which indicates the processing policy of Pod in case of failure
5.2 Pod configuration
This section mainly studies the pod.spec.containers attribute, which is also the most critical configuration in pod configuration.
[root@k8s-master01 ~]# kubectl explain pod.spec.containers KIND: Pod VERSION: v1 RESOURCE: containers <[]Object> # Array, representing that there can be multiple containers FIELDS: name <string> # Container name image <string> # The mirror address required by the container imagePullPolicy <string> # Image pull strategy command <[]string> # The list of startup commands of the container. If not specified, the startup commands used during packaging shall be used args <[]string> # List of parameters required for the container's start command env <[]Object> # Configuration of container environment variables ports <[]Object> # List of port numbers that the container needs to expose resources <Object> # Setting of resource limits and resource requests
5.2.1 basic configuration
Create the pod-base.yaml file as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-base
namespace: dev
labels:
user: heima
spec:
containers:
- name: nginx
image: nginx:1.17.1
- name: busybox
image: busybox:1.30
The above defines a relatively simple Pod configuration with two containers:
- Nginx: created with the nginx image of version 1.17.1, (nginx is a lightweight web container)
- Busybox: created with the busybox image of version 1.30, (busybox is a small collection of linux commands)

# Create Pod [root@k8s-master01 pod]# kubectl apply -f pod-base.yaml pod/pod-base created # View Pod status # READY 1/2: indicates that there are 2 containers in the current Pod, of which 1 is ready and 1 is not ready # RESTARTS: the number of RESTARTS. Because one container failed, Pod has been restarting trying to recover it [root@k8s-master01 pod]# kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pod-base 1/2 Running 4 95s # You can view internal details through describe # At this point, a basic Pod has been running, although it has a problem for the time being [root@k8s-master01 pod]# kubectl describe pod pod-base -n dev
5.2.2 image pulling
Create the pod-imagepullpolicy.yaml file as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-imagepullpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
imagePullPolicy: Never # Used to set the image pull policy
- name: busybox
image: busybox:1.30

imagePullPolicy is used to set the image pull policy. kubernetes supports configuring three kinds of pull policies:
- Always: always pull images from remote warehouses (always download remotely)
- IfNotPresent: if there is a local image, the local image is used. If there is no local image, the image is pulled from the remote warehouse (if there is a local image, there is no remote download)
- Never: only use the local image, never pull from the remote warehouse, and report an error if there is no local image (always use the local image)
Default value Description:
If the image tag is a specific version number, the default policy is IfNotPresent
If the image tag is: latest (final version), the default policy is always
# Create Pod [root@k8s-master01 pod]# kubectl create -f pod-imagepullpolicy.yaml pod/pod-imagepullpolicy created # View Pod details # At this time, it is obvious that the nginx image has a process of Pulling image "nginx:1.17.1" [root@k8s-master01 pod]# kubectl describe pod pod-imagepullpolicy -n dev ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned dev/pod-imagePullPolicy to node1 Normal Pulling 32s kubelet, node1 Pulling image "nginx:1.17.1" Normal Pulled 26s kubelet, node1 Successfully pulled image "nginx:1.17.1" Normal Created 26s kubelet, node1 Created container nginx Normal Started 25s kubelet, node1 Started container nginx Normal Pulled 7s (x3 over 25s) kubelet, node1 Container image "busybox:1.30" already present on machine Normal Created 7s (x3 over 25s) kubelet, node1 Created container busybox Normal Started 7s (x3 over 25s) kubelet, node1 Started container busybox
5.2.3 start command
In the previous case, there has always been a problem that has not been solved, that is, the busybox container has not been running successfully. What is the reason for the failure of this container?
Originally, busybox is not a program, but a collection of tool classes. After the kubernetes cluster starts management, it will close automatically. The solution is to keep it running, which requires command configuration.
Create the pod-command.yaml file as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-command
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","touch /tmp/hello.txt;while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done;"]

Command, which is used to run a command after the initialization of the container in the pod.
Explain the meaning of the above command a little:
"/ bin/sh", "- c", execute the command with sh
touch /tmp/hello.txt; Create a / TMP / hello.txt file
while true; do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done; Write the current time to the file every 3 seconds
# Create Pod [root@k8s-master01 pod]# kubectl create -f pod-command.yaml pod/pod-command created # View Pod status # At this time, it is found that both pod s are running normally [root@k8s-master01 pod]# kubectl get pods pod-command -n dev NAME READY STATUS RESTARTS AGE pod-command 2/2 Runing 0 2s # Enter the busybox container in the pod to view the contents of the file # Add a command: kubectl exec pod name - n namespace - it -c container name / bin/sh execute the command inside the container # Using this command, you can enter the interior of a container and then perform related operations # For example, you can view the contents of a txt file [root@k8s-master01 pod]# kubectl exec pod-command -n dev -it -c busybox /bin/sh / # tail -f /tmp/hello.txt 14:44:19 14:44:22 14:44:25
Special note:
Found above command The function of starting commands and passing parameters can be completed. Why do you provide one here args Options for passing parameters?This is actually the same as docker It doesn't matter, kubernetes Medium command,args The two are actually to achieve coverage Dockerfile in ENTRYPOINT The function of.
1 If command and args It's not written, so use it Dockerfile Configuration of.
2 If command Yes, but args No, so Dockerfile The default configuration will be ignored and the entered configuration will be executed command
3 If command No, but args Yes, so Dockerfile Configured in ENTRYPOINT The command will be executed using the current args Parameters of
4 If command and args It's all written, so Dockerfile The configuration of is ignored and cannot be executed command And add args parameter
5.2.4 environmental variables
Create the pod-env.yaml file as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-env
namespace: dev
spec:
containers:
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","while true;do /bin/echo $(date +%T);sleep 60; done;"]
env: # Set environment variable list
- name: "username"
value: "admin"
- name: "password"
value: "123456"
env, environment variable, used to set the environment variable in the container in pod.
# Create Pod [root@k8s-master01 ~]# kubectl create -f pod-env.yaml pod/pod-env created # Enter the container and output the environment variable [root@k8s-master01 ~]# kubectl exec pod-env -n dev -c busybox -it /bin/sh / # echo $username admin / # echo $password 123456
This method is not recommended. It is recommended to store these configurations separately in the configuration file. This method will be described later.
5.2.5 port setting
This section describes the port settings of containers, that is, the ports option of containers.
First, look at the sub options supported by ports:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.ports KIND: Pod VERSION: v1 RESOURCE: ports <[]Object> FIELDS: name <string> # The port name, if specified, must be unique in the pod containerPort<integer> # Port on which the container will listen (0 < x < 65536) hostPort <integer> # The port on which the container is to be exposed on the host. If set, only one copy of the container can be run on the host (generally omitted) hostIP <string> # Host IP to which the external port is bound (generally omitted) protocol <string> # Port protocol. Must be UDP, TCP, or SCTP. The default is TCP.
Next, write a test case to create pod-ports.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-ports
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports: # Sets the list of ports exposed by the container
- name: nginx-port
containerPort: 80
protocol: TCP
# Create Pod
[root@k8s-master01 ~]# kubectl create -f pod-ports.yaml
pod/pod-ports created
# View pod
# You can see the configuration information clearly below
[root@k8s-master01 ~]# kubectl get pod pod-ports -n dev -o yaml
......
spec:
containers:
- image: nginx:1.17.1
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
name: nginx-port
protocol: TCP
......
To access the programs in the container, you need to use Podip:containerPort
5.2.6 resource quota
To run a program in a container, it must occupy certain resources, such as cpu and memory. If the resources of a container are not limited, it may eat a lot of resources and make other containers unable to run. In this case, kubernetes provides a quota mechanism for memory and cpu resources. This mechanism is mainly implemented through the resources option. It has two sub options:
- Limits: used to limit the maximum resources occupied by the container at runtime. When the resources occupied by the container exceed the limits, it will be terminated and restarted
- requests: used to set the minimum resources required by the container. If the environment resources are insufficient, the container will not start
You can set the upper and lower limits of resources through the above two options.
Next, write a test case to create pod-resources.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-resources
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources: # Resource quota
limits: # Limit resources (upper limit)
cpu: "2" # CPU limit, in core s
memory: "10Gi" # Memory limit
requests: # Requested resources (lower limit)
cpu: "1" # CPU limit, in core s
memory: "10Mi" # Memory limit
Here is a description of the units of cpu and memory:
- cpu: core number, which can be integer or decimal
- Memory: memory size, which can be in the form of Gi, Mi, G, M, etc
# Run Pod
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created
# It is found that the pod is running normally
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev
NAME READY STATUS RESTARTS AGE
pod-resources 1/1 Running 0 39s
# Next, stop Pod
[root@k8s-master01 ~]# kubectl delete -f pod-resources.yaml
pod "pod-resources" deleted
# Edit pod and change the value of resources.requests.memory to 10Gi
[root@k8s-master01 ~]# vim pod-resources.yaml
# Start the pod again
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created
# Check the Pod status and find that the Pod failed to start
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev -o wide
NAME READY STATUS RESTARTS AGE
pod-resources 0/1 Pending 0 20s
# Check the details of pod and you will find the following prompt
[root@k8s-master01 ~]# kubectl describe pod pod-resources -n dev
......
Warning FailedScheduling 35s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.(insufficient memory)
5.3 Pod life cycle
We generally call the period from the creation to the end of a pod object as the life cycle of a pod. It mainly includes the following processes:
- pod creation process
- Run the init container process
- Run main container
- After the container is started (post start), before the container is terminated (pre stop)
- Survivability probe and readiness probe of container
- pod termination process
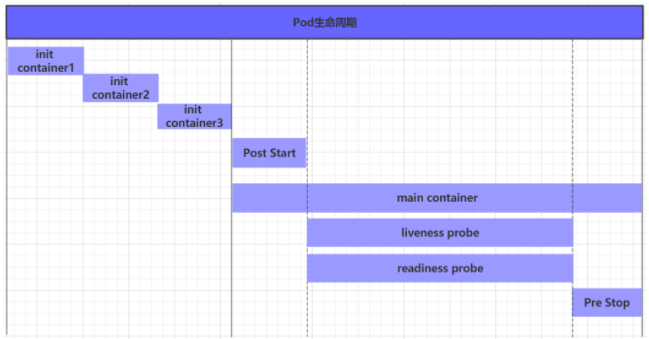
In the whole life cycle, Pod will have five states (phases), as follows:
- Pending: apiserver has created the pod resource object, but it has not been scheduled or is still in the process of downloading the image
- Running: the pod has been scheduled to a node, and all containers have been created by kubelet
- Succeeded: all containers in the pod have been successfully terminated and will not be restarted
- Failed: all containers have been terminated, but at least one container failed to terminate, that is, the container returned an exit status with a value other than 0
- Unknown: apiserver cannot normally obtain the status information of pod object, which is usually caused by network communication failure
5.3.1 creation and termination
Creation process of pod
-
Users submit the pod information to be created to apiServer through kubectl or other api clients
-
apiServer starts to generate the information of the pod object, stores the information in etcd, and then returns the confirmation information to the client
-
apiServer starts to reflect the changes of pod objects in etcd, and other components use the watch mechanism to track and check the changes on apiServer
-
The scheduler finds that a new pod object needs to be created, starts assigning hosts to the pod and updates the result information to apiServer
-
The kubelet on the node finds that a pod has been dispatched, tries to call docker to start the container, and sends the result back to apiServer
-
apiServer stores the received pod status information into etcd
Termination process of pod
- The user sends a command to apiServer to delete the pod object
- The pod object information in apiserver will be updated over time. Within the grace period (30s by default), pod is regarded as dead
- Mark pod as terminating
- kubelet starts the closing process of pod while monitoring that the pod object is in the terminating state
- When the endpoint controller monitors the closing behavior of the pod object, it removes it from the endpoint list of all service resources matching this endpoint
- If the current pod object defines a preStop hook processor, it will start execution synchronously after it is marked as terminating
- The container process in the pod object received a stop signal
- After the grace period, if there are still running processes in the pod, the pod object will receive an immediate termination signal
- kubelet requests apiServer to set the grace period of this pod resource to 0 to complete the deletion operation. At this time, the pod is no longer visible to the user
5.3.2 initialize container
Initialization container is a container to be run before the main container of pod is started. It mainly does some pre work of the main container. It has two characteristics:
- The initialization container must run until it is completed. If an initialization container fails to run, kubernetes needs to restart it until it is completed successfully
- The initialization container must be executed in the defined order. If and only after the current one succeeds, the latter one can run
There are many application scenarios for initializing containers. The following are the most common:
- Provide tools, programs, or custom codes that are not available in the main container image
- The initialization container must be started and run serially before the application container, so it can be used to delay the startup of the application container until its dependent conditions are met
Next, make a case to simulate the following requirements:
Suppose you want to run nginx in the main container, but you need to be able to connect to the server where mysql and redis are located before running nginx
To simplify the test, specify the addresses of mysql(192.168.90.14) and redis(192.168.90.15) servers in advance
Create pod-initcontainer.yaml as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-initcontainer
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
initContainers:
- name: test-mysql
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.90.14 -c 1 ; do echo waiting for mysql...; sleep 2; done;']
- name: test-redis
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.90.15 -c 1 ; do echo waiting for reids...; sleep 2; done;']
# Create pod [root@k8s-master01 ~]# kubectl create -f pod-initcontainer.yaml pod/pod-initcontainer created # View pod status # It is found that the following containers will not run when the pod card starts the first initialization container root@k8s-master01 ~]# kubectl describe pod pod-initcontainer -n dev ........ Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 49s default-scheduler Successfully assigned dev/pod-initcontainer to node1 Normal Pulled 48s kubelet, node1 Container image "busybox:1.30" already present on machine Normal Created 48s kubelet, node1 Created container test-mysql Normal Started 48s kubelet, node1 Started container test-mysql # View pod dynamically [root@k8s-master01 ~]# kubectl get pods pod-initcontainer -n dev -w NAME READY STATUS RESTARTS AGE pod-initcontainer 0/1 Init:0/2 0 15s pod-initcontainer 0/1 Init:1/2 0 52s pod-initcontainer 0/1 Init:1/2 0 53s pod-initcontainer 0/1 PodInitializing 0 89s pod-initcontainer 1/1 Running 0 90s # Next, open a new shell, add two IPS to the current server, and observe the change of pod [root@k8s-master01 ~]# ifconfig ens33:1 192.168.90.14 netmask 255.255.255.0 up [root@k8s-master01 ~]# ifconfig ens33:2 192.168.90.15 netmask 255.255.255.0 up
5.3.3 hook function
Hook functions can sense the events in their own life cycle and run the user specified program code when the corresponding time comes.
kubernetes provides two hook functions after the main container is started and before it is stopped:
- post start: executed after the container is created. If it fails, the container will be restarted
- pre stop: executed before the container terminates. After the execution is completed, the container will terminate successfully. The operation of deleting the container will be blocked before it is completed
The hook processor supports defining actions in the following three ways:
-
Exec command: execute the command once inside the container
...... lifecycle: postStart: exec: command: - cat - /tmp/healthy ...... -
TCPSocket: attempts to access the specified socket in the current container
...... lifecycle: postStart: tcpSocket: port: 8080 ...... -
HTTPGet: initiates an http request to a url in the current container
...... lifecycle: postStart: httpGet: path: / #URI address port: 80 #Port number host: 192.168.5.3 #Host address scheme: HTTP #Supported protocols, http or https ......
Next, take the exec method as an example to demonstrate the use of the following hook function and create a pod-hook-exec.yaml file, which is as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
lifecycle:
postStart:
exec: # When the container starts, execute a command to modify the default home page content of nginx
command: ["/bin/sh", "-c", "echo postStart... > /usr/share/nginx/html/index.html"]
preStop:
exec: # Stop the nginx service before the container stops
command: ["/usr/sbin/nginx","-s","quit"]
# Create pod [root@k8s-master01 ~]# kubectl create -f pod-hook-exec.yaml pod/pod-hook-exec created # View pod [root@k8s-master01 ~]# kubectl get pods pod-hook-exec -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-hook-exec 1/1 Running 0 29s 10.244.2.48 node2 # Access pod [root@k8s-master01 ~]# curl 10.244.2.48 postStart...
5.3.4 container detection
Container detection is used to detect whether the application instances in the container work normally. It is a traditional mechanism to ensure service availability. If the status of the instance does not meet the expectation after detection, kubernetes will "remove" the problem instance and do not undertake business traffic. Kubernetes provides two probes to realize container detection, namely:
- liveness probes: Live probes are used to detect whether the application instance is currently in normal operation. If not, k8s the container will be restarted
- readiness probes: readiness probes are used to detect whether the application instance can receive requests. If not, k8s it will not forward traffic
livenessProbe decides whether to restart the container, and readinessProbe decides whether to forward the request to the container.
The above two probes currently support three detection modes:
-
Exec command: execute the command once in the container. If the exit code of the command is 0, the program is considered normal, otherwise it is not normal
...... livenessProbe: exec: command: - cat - /tmp/healthy ...... -
TCPSocket: will try to access the port of a user container. If this connection can be established, the program is considered normal, otherwise it is not normal
...... livenessProbe: tcpSocket: port: 8080 ...... -
HTTPGet: call the URL of the Web application in the container. If the returned status code is between 200 and 399, the program is considered normal, otherwise it is not normal
...... livenessProbe: httpGet: path: / #URI address port: 80 #Port number host: 127.0.0.1 #Host address scheme: HTTP #Supported protocols, http or https ......
Let's take liveness probes as an example to demonstrate:
Method 1: Exec
Create pod-liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-exec
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
exec:
command: ["/bin/cat","/tmp/hello.txt"] # Execute a command to view files
Create a pod and observe the effect
# Create Pod [root@k8s-master01 ~]# kubectl create -f pod-liveness-exec.yaml pod/pod-liveness-exec created # View Pod details [root@k8s-master01 ~]# kubectl describe pods pod-liveness-exec -n dev ...... Normal Created 20s (x2 over 50s) kubelet, node1 Created container nginx Normal Started 20s (x2 over 50s) kubelet, node1 Started container nginx Normal Killing 20s kubelet, node1 Container nginx failed liveness probe, will be restarted Warning Unhealthy 0s (x5 over 40s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/hello11.txt': No such file or directory # Observing the above information, you will find that the health check is carried out after the nginx container is started # After the check fails, the container is kill ed, and then restart is attempted (this is the function of the restart strategy, which will be explained later) # After a while, observe the pod information, and you can see that the RESTARTS is no longer 0, but has been growing [root@k8s-master01 ~]# kubectl get pods pod-liveness-exec -n dev NAME READY STATUS RESTARTS AGE pod-liveness-exec 0/1 CrashLoopBackOff 2 3m19s # Of course, next, you can modify it to an existing file, such as / tmp/hello.txt. Try again, and the result will be normal
Mode 2: TCPSocket
Create pod-liveness-tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcpsocket
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
tcpSocket:
port: 8080 # Trying to access port 8080
Create a pod and observe the effect
# Create Pod [root@k8s-master01 ~]# kubectl create -f pod-liveness-tcpsocket.yaml pod/pod-liveness-tcpsocket created # View Pod details [root@k8s-master01 ~]# kubectl describe pods pod-liveness-tcpsocket -n dev ...... Normal Scheduled 31s default-scheduler Successfully assigned dev/pod-liveness-tcpsocket to node2 Normal Pulled <invalid> kubelet, node2 Container image "nginx:1.17.1" already present on machine Normal Created <invalid> kubelet, node2 Created container nginx Normal Started <invalid> kubelet, node2 Started container nginx Warning Unhealthy <invalid> (x2 over <invalid>) kubelet, node2 Liveness probe failed: dial tcp 10.244.2.44:8080: connect: connection refused # Observing the above information, I found that I tried to access port 8080, but failed # After a while, observe the pod information, and you can see that the RESTARTS is no longer 0, but has been growing [root@k8s-master01 ~]# kubectl get pods pod-liveness-tcpsocket -n dev NAME READY STATUS RESTARTS AGE pod-liveness-tcpsocket 0/1 CrashLoopBackOff 2 3m19s # Of course, next, you can change it to an accessible port, such as 80. Try again, and the result will be normal
Method 3: HTTPGet
Create pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet: # It's actually a visit http://127.0.0.1:80/hello
scheme: HTTP #Supported protocols, http or https
port: 80 #Port number
path: /hello #URI address
Create a pod and observe the effect
# Create Pod [root@k8s-master01 ~]# kubectl create -f pod-liveness-httpget.yaml pod/pod-liveness-httpget created # View Pod details [root@k8s-master01 ~]# kubectl describe pod pod-liveness-httpget -n dev ....... Normal Pulled 6s (x3 over 64s) kubelet, node1 Container image "nginx:1.17.1" already present on machine Normal Created 6s (x3 over 64s) kubelet, node1 Created container nginx Normal Started 6s (x3 over 63s) kubelet, node1 Started container nginx Warning Unhealthy 6s (x6 over 56s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404 Normal Killing 6s (x2 over 36s) kubelet, node1 Container nginx failed liveness probe, will be restarted # Observe the above information and try to access the path, but it is not found. A 404 error occurs # After a while, observe the pod information, and you can see that the RESTARTS is no longer 0, but has been growing [root@k8s-master01 ~]# kubectl get pod pod-liveness-httpget -n dev NAME READY STATUS RESTARTS AGE pod-liveness-httpget 1/1 Running 5 3m17s # Of course, next, you can modify it to an accessible path, such as /. Try again, and the result will be normal
So far, the liveness Probe has been used to demonstrate three detection methods. However, looking at the child properties of liveness Probe, you will find that there are other configurations in addition to these three methods, which are explained here:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.livenessProbe FIELDS: exec <Object> tcpSocket <Object> httpGet <Object> initialDelaySeconds <integer> # How many seconds do you wait for the first probe after the container starts timeoutSeconds <integer> # Probe timeout. Default 1 second, minimum 1 second periodSeconds <integer> # The frequency at which the probe is performed. The default is 10 seconds and the minimum is 1 second failureThreshold <integer> # How many times does a continuous probe fail before it is considered a failure. The default is 3. The minimum value is 1 successThreshold <integer> # How many times are successive detections considered successful. The default is 1
Here are two slightly configured to demonstrate the following effects:
[root@k8s-master01 ~]# more pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /
initialDelaySeconds: 30 # Detection starts 30 s after the container is started
timeoutSeconds: 5 # The detection timeout is 5s
5.3.5 restart strategy
In the previous section, once there is a problem with the container detection, kubernetes will restart the pod where the container is located. In fact, this is determined by the pod restart strategy. There are three kinds of pod restart strategies, as follows:
- Always: automatically restart the container when it fails, which is also the default value.
- OnFailure: restart when the container terminates and the exit code is not 0
- Never: do not restart the container regardless of the status
The restart strategy is applicable to all containers in the pod object. The container that needs to be restarted for the first time will be restarted immediately when it needs to be restarted. The operation that needs to be restarted again will be delayed by kubelet for a period of time, and the delay length of repeated restart operations is 10s, 20s, 40s, 80s, 160s and 300s. 300s is the maximum delay length.
Create pod-restartpolicy.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-restartpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /hello
restartPolicy: Never # Set the restart policy to Never
Run Pod test
# Create Pod [root@k8s-master01 ~]# kubectl create -f pod-restartpolicy.yaml pod/pod-restartpolicy created # Check the Pod details and find that nginx container failed [root@k8s-master01 ~]# kubectl describe pods pod-restartpolicy -n dev ...... Warning Unhealthy 15s (x3 over 35s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404 Normal Killing 15s kubelet, node1 Container nginx failed liveness probe # Wait a little longer, and then observe the restart times of the pod. It is found that it has been 0 and has not been restarted [root@k8s-master01 ~]# kubectl get pods pod-restartpolicy -n dev NAME READY STATUS RESTARTS AGE pod-restartpolicy 0/1 Running 0 5min42s
5.4 Pod scheduling
By default, the Node on which a Pod runs is calculated by the Scheduler component using the corresponding algorithm. This process is not controlled manually. However, in actual use, this does not meet the needs of users, because in many cases, we want to control some pods to reach some nodes, so what should we do? This requires understanding the scheduling rules of kubernetes for Pod. Kubernetes provides four types of scheduling methods:
- Automatic scheduling: the node on which the Scheduler runs is completely calculated by a series of algorithms
- Directional scheduling: NodeName, NodeSelector
- Affinity scheduling: NodeAffinity, PodAffinity, PodAntiAffinity
- Stain tolerance scheduling: Taints, tolerance
5.4.1 directional dispatching
Directed scheduling refers to scheduling the pod to the desired node node by declaring nodeName or nodeSelector on the pod. Note that the scheduling here is mandatory, which means that even if the target node to be scheduled does not exist, it will be scheduled to the above, but the pod operation fails.
NodeName
NodeName is used to force the constraint to schedule the Pod to the Node with the specified Name. This method actually directly skips the Scheduler's scheduling logic and directly schedules the Pod to the Node with the specified Name.
Next, experiment: create a pod-nodename.yaml file
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # Specify scheduling to node1 node
#Create Pod [root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml pod/pod-nodename created #Check the NODE attribute of Pod scheduling. It is indeed scheduled to node1 NODE [root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodename 1/1 Running 0 56s 10.244.1.87 node1 ...... # Next, delete the pod and change the value of nodeName to node3 (no node3 node) [root@k8s-master01 ~]# kubectl delete -f pod-nodename.yaml pod "pod-nodename" deleted [root@k8s-master01 ~]# vim pod-nodename.yaml [root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml pod/pod-nodename created #Check again. It is found that the node3 node has been scheduled, but the pod cannot run normally because there is no node3 node [root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodename 0/1 Pending 0 6s <none> node3 ......
NodeSelector
NodeSelector is used to schedule the pod to the node node with the specified label added. It is implemented through kubernetes' label selector mechanism, that is, before the pod is created, the scheduler will use the MatchNodeSelector scheduling policy to match the label, find the target node, and then schedule the pod to the target node. The matching rule is a mandatory constraint.
Next, experiment:
1 first add labels for the node nodes respectively
[root@k8s-master01 ~]# kubectl label nodes node1 nodeenv=pro node/node2 labeled [root@k8s-master01 ~]# kubectl label nodes node2 nodeenv=test node/node2 labeled
2 create a pod-nodeselector.yaml file and use it to create a Pod
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselector
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeSelector:
nodeenv: pro # Specifies to schedule to a node with nodeenv=pro tag
#Create Pod [root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml pod/pod-nodeselector created #Check the NODE attribute of Pod scheduling. It is indeed scheduled to node1 NODE [root@k8s-master01 ~]# kubectl get pods pod-nodeselector -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodeselector 1/1 Running 0 47s 10.244.1.87 node1 ...... # Next, delete the pod and change the value of nodeSelector to nodeenv: xxxx (there is no node with this label) [root@k8s-master01 ~]# kubectl delete -f pod-nodeselector.yaml pod "pod-nodeselector" deleted [root@k8s-master01 ~]# vim pod-nodeselector.yaml [root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml pod/pod-nodeselector created #Check again. It is found that the pod cannot operate normally, and the value of Node is none [root@k8s-master01 ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-nodeselector 0/1 Pending 0 2m20s <none> <none> # Check the details and find the prompt of node selector matching failure [root@k8s-master01 ~]# kubectl describe pods pod-nodeselector -n dev ....... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
5.4.2 affinity scheduling
In the previous section, we introduced two directional scheduling methods, which are very convenient to use, but there are also some problems, that is, if there are no qualified nodes, the Pod will not be run, even if there is a list of available nodes in the cluster, which limits its use scenario.
Based on the above problem, kubernetes also provides an Affinity scheduling. It is extended on the basis of NodeSelector. Through configuration, it can give priority to the nodes that meet the conditions for scheduling. If not, it can also be scheduled to the nodes that do not meet the conditions, making the scheduling more flexible.
Affinity is mainly divided into three categories:
- node affinity: Aiming at nodes, it solves the problem of which nodes a pod can schedule
- Podaffinity: Aiming at pods, it solves the problem of which existing pods can be deployed in the same topology domain
- Pod anti affinity: Aiming at pod, it solves the problem that pod cannot be deployed in the same topology domain with existing pods
Description of affinity (anti affinity) usage scenarios:
Affinity: if two applications interact frequently, it is necessary to use affinity to make the two applications as close as possible, so as to reduce the performance loss caused by network communication.
Anti affinity: when the application is deployed with multiple replicas, it is necessary to use anti affinity to make each application instance scattered and distributed on each node, which can improve the high availability of the service.
NodeAffinity
First, let's take a look at the configurable items of NodeAffinity:
pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution Node The node must meet all the specified rules, which is equivalent to a hard limit
nodeSelectorTerms Node selection list
matchFields List of node selector requirements by node field
matchExpressions List of node selector requirements by node label(recommend)
key key
values value
operat or Relational character support Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution Priority scheduling to meet the specified rules Node,Equivalent to soft limit (inclination)
preference A node selector item associated with the corresponding weight
matchFields List of node selector requirements by node field
matchExpressions List of node selector requirements by node label(recommend)
key key
values value
operator Relational character support In, NotIn, Exists, DoesNotExist, Gt, Lt
weight Propensity weight, in range 1-100.
Instructions for using relation characters:
- matchExpressions:
- key: nodeenv # Match the node with nodeenv as the key with label
operator: Exists
- key: nodeenv # The key of the matching tag is nodeenv and the value is "xxx" or "yyy"
operator: In
values: ["xxx","yyy"]
- key: nodeenv # The key of the matching tag is nodeenv and the value is greater than "xxx"
operator: Gt
values: "xxx"
Next, first demonstrate the required duringschedulingignored duringexecution,
Create pod-nodeaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #Affinity settings
nodeAffinity: #Set node affinity
requiredDuringSchedulingIgnoredDuringExecution: # Hard limit
nodeSelectorTerms:
- matchExpressions: # Match the label of the value of env in ["xxx","yyy"]
- key: nodeenv
operator: In
values: ["xxx","yyy"]
# Create pod [root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml pod/pod-nodeaffinity-required created # View pod status (failed to run) [root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodeaffinity-required 0/1 Pending 0 16s <none> <none> ...... # View Pod details # If the scheduling fails, the node selection fails [root@k8s-master01 ~]# kubectl describe pod pod-nodeaffinity-required -n dev ...... Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector. Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector. #Next, stop the pod [root@k8s-master01 ~]# kubectl delete -f pod-nodeaffinity-required.yaml pod "pod-nodeaffinity-required" deleted # Modify the file and set values: ["XXX", "YYY"] ---- > ["pro", "YYY"] [root@k8s-master01 ~]# vim pod-nodeaffinity-required.yaml # Restart [root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml pod/pod-nodeaffinity-required created # At this time, it is found that the scheduling is successful and the pod has been scheduled to node1 [root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE ...... pod-nodeaffinity-required 1/1 Running 0 11s 10.244.1.89 node1 ......
Next, let's demonstrate the required duringschedulingignored duringexecution,
Create pod-nodeaffinity-preferred.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeaffinity-preferred
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #Affinity settings
nodeAffinity: #Set node affinity
preferredDuringSchedulingIgnoredDuringExecution: # Soft limit
- weight: 1
preference:
matchExpressions: # The tag matching the value of env in ["xxx","yyy"] (not available in the current environment)
- key: nodeenv
operator: In
values: ["xxx","yyy"]
# Create pod [root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-preferred.yaml pod/pod-nodeaffinity-preferred created # View the pod status (running successfully) [root@k8s-master01 ~]# kubectl get pod pod-nodeaffinity-preferred -n dev NAME READY STATUS RESTARTS AGE pod-nodeaffinity-preferred 1/1 Running 0 40s
NodeAffinity Precautions for rule setting:
1 If defined at the same time nodeSelector and nodeAffinity,Then both conditions must be met, Pod To run on the specified Node upper
2 If nodeAffinity Multiple specified nodeSelectorTerms,Then only one of them can match successfully
3 If one nodeSelectorTerms Multiple in matchExpressions ,Then a node must meet all requirements to match successfully
4 If one pod Where Node stay Pod Its label has changed during operation and is no longer in compliance with this requirement Pod The system will ignore this change
PodAffinity
PodAffinity mainly implements the function of making the newly created pod and the reference pod in the same area with the running pod as the reference.
First, let's take a look at the configurable items of PodAffinity:
pod.spec.affinity.podAffinity
requiredDuringSchedulingIgnoredDuringExecution Hard limit
namespaces Specify reference pod of namespace
topologyKey Specify scheduling scope
labelSelector tag chooser
matchExpressions List of node selector requirements by node label(recommend)
key key
values value
operator Relational character support In, NotIn, Exists, DoesNotExist.
matchLabels Refers to multiple matchExpressions Mapped content
preferredDuringSchedulingIgnoredDuringExecution Soft limit
podAffinityTerm option
namespaces
topologyKey
labelSelector
matchExpressions
key key
values value
operator
matchLabels
weight Propensity weight, in range 1-100
topologyKey Used to specify the dispatch time scope,for example:
If specified as kubernetes.io/hostname,That is to Node The node is a differentiated range
If specified as beta.kubernetes.io/os,Then Node The operating system type of the node
Next, demonstrate the requiredDuringSchedulingIgnoredDuringExecution,
1) First, create a reference Pod, pod-podaffinity-target.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-target
namespace: dev
labels:
podenv: pro #Set label
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # Specify the target pod name on node1
# Start target pod [root@k8s-master01 ~]# kubectl create -f pod-podaffinity-target.yaml pod/pod-podaffinity-target created # View pod status [root@k8s-master01 ~]# kubectl get pods pod-podaffinity-target -n dev NAME READY STATUS RESTARTS AGE pod-podaffinity-target 1/1 Running 0 4s
2) Create pod-podaffinity-required.yaml as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #Affinity settings
podAffinity: #Set pod affinity
requiredDuringSchedulingIgnoredDuringExecution: # Hard limit
- labelSelector:
matchExpressions: # Match the label of the value of env in ["xxx","yyy"]
- key: podenv
operator: In
values: ["xxx","yyy"]
topologyKey: kubernetes.io/hostname
The above configuration means that the new pod must be on the same Node as the pod with the label nodeenv=xxx or nodeenv=yyy. Obviously, there is no such pod now. Next, run the test.
# Start pod [root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml pod/pod-podaffinity-required created # Check the pod status and find that it is not running [root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev NAME READY STATUS RESTARTS AGE pod-podaffinity-required 0/1 Pending 0 9s # View details [root@k8s-master01 ~]# kubectl describe pods pod-podaffinity-required -n dev ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that the pod didn't tolerate. # Next, modify values: ["XXX", "YYY"] ---- > values: ["pro", "YYY"] # This means that the new pod must be on the same Node as the pod with the label nodeenv=xxx or nodeenv=yyy [root@k8s-master01 ~]# vim pod-podaffinity-required.yaml # Then recreate the pod to see the effect [root@k8s-master01 ~]# kubectl delete -f pod-podaffinity-required.yaml pod "pod-podaffinity-required" de leted [root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml pod/pod-podaffinity-required created # It is found that the Pod is running normally at this time [root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev NAME READY STATUS RESTARTS AGE LABELS pod-podaffinity-required 1/1 Running 0 6s <none>
The preferred during scheduling ignored during execution of PodAffinity will not be demonstrated here.
PodAntiAffinity
PodAntiAffinity mainly implements the function of taking the running pod as the reference, so that the newly created pod and the reference pod are not in the same area.
Its configuration mode and options are the same as those of podaffinity. There is no detailed explanation here. Just make a test case.
1) Continue to use the target pod in the previous case
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE LABELS pod-podaffinity-required 1/1 Running 0 3m29s 10.244.1.38 node1 <none> pod-podaffinity-target 1/1 Running 0 9m25s 10.244.1.37 node1 podenv=pro
2) Create pod-podandiaffinity-required.yaml as follows:
apiVersion: v1
kind: Pod
metadata:
name: pod-podantiaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #Affinity settings
podAntiAffinity: #Set pod affinity
requiredDuringSchedulingIgnoredDuringExecution: # Hard limit
- labelSelector:
matchExpressions: # Match the label of the value of podenv in ["pro"]
- key: podenv
operator: In
values: ["pro"]
topologyKey: kubernetes.io/hostname
The above configuration means that the new pod must not be on the same Node as the pod with the label nodeenv=pro. Run the test.
# Create pod [root@k8s-master01 ~]# kubectl create -f pod-podantiaffinity-required.yaml pod/pod-podantiaffinity-required created # View pod # It is found that the schedule is on node2 [root@k8s-master01 ~]# kubectl get pods pod-podantiaffinity-required -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE .. pod-podantiaffinity-required 1/1 Running 0 30s 10.244.1.96 node2 ..
5.4.3 stain and tolerance
Taints
The previous scheduling methods are based on the point of view of the Pod. By adding attributes to the Pod, we can determine whether the Pod should be scheduled to the specified Node. In fact, we can also decide whether to allow the Pod to be scheduled from the point of view of the Node by adding stain attributes to the Node.
After the Node is tainted, there is a mutually exclusive relationship between the Node and the Pod, and then the Pod scheduling is rejected, and the existing Pod can even be expelled.
The format of the stain is: key = value: effect. Key and value are the labels of the stain. Effect describes the function of the stain. The following three options are supported:
- PreferNoSchedule: kubernetes will try to avoid scheduling pods to nodes with this stain unless there are no other nodes to schedule
- NoSchedule: kubernetes will not schedule the Pod to the Node with the stain, but will not affect the existing Pod on the current Node
- NoExecute: kubernetes will not schedule the Pod to the Node with the stain, but will also drive the existing Pod on the Node away

Examples of commands for setting and removing stains using kubectl are as follows:
# Set stain kubectl taint nodes node1 key=value:effect # Remove stains kubectl taint nodes node1 key:effect- # Remove all stains kubectl taint nodes node1 key-
Next, demonstrate the effect of the stain:
- Prepare node node1 (to make the demonstration effect more obvious, temporarily stop node node2)
- Set a stain for node1 node: tag=heima:PreferNoSchedule; Then create pod1 (pod1 can)
- Modify node1 node to set a stain: tag=heima:NoSchedule; Then create pod2 (pod1 is normal and pod2 fails)
- Modify to set a stain for node1 node: tag=heima:NoExecute; Then create pod3 (all three pods fail)
# Set stain for node1 (PreferNoSchedule) [root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:PreferNoSchedule # Create pod1 [root@k8s-master01 ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev [root@k8s-master01 ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1 # Set stain for node1 (cancel PreferNoSchedule and set NoSchedule) [root@k8s-master01 ~]# kubectl taint nodes node1 tag:PreferNoSchedule- [root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:NoSchedule # Create pod2 [root@k8s-master01 ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev [root@k8s-master01 ~]# kubectl get pods taint2 -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1 taint2-544694789-6zmlf 0/1 Pending 0 21s <none> <none> # Set stain for node1 (cancel NoSchedule and set NoExecute) [root@k8s-master01 ~]# kubectl taint nodes node1 tag:NoSchedule- [root@k8s-master01 ~]# kubectl taint nodes node1 tag=heima:NoExecute # Create pod3 [root@k8s-master01 ~]# kubectl run taint3 --image=nginx:1.17.1 -n dev [root@k8s-master01 ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED taint1-7665f7fd85-htkmp 0/1 Pending 0 35s <none> <none> <none> taint2-544694789-bn7wb 0/1 Pending 0 35s <none> <none> <none> taint3-6d78dbd749-tktkq 0/1 Pending 0 6s <none> <none> <none>
Tip:
use kubeadm The cluster will be set up by default master Add a stain mark to the node,therefore pod It won't be scheduled master On node.
Tolerance
The above describes the role of stains. We can add stains on nodes to reject pod scheduling. However, what should we do if we want to schedule a pod to a node with stains? This requires tolerance.

Stain means rejection, tolerance means neglect. Node rejects the pod through stain, and pod ignores rejection through tolerance
Let's look at the effect through a case:
- In the previous section, the node1 node has been marked with the stain of NoExecute. At this time, the pod cannot be scheduled
- In this section, you can add tolerance to the pod and then schedule it
Create pod-tolerance.yaml as follows
apiVersion: v1
kind: Pod
metadata:
name: pod-toleration
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
tolerations: # Add tolerance
- key: "tag" # The key to the stain to be tolerated
operator: "Equal" # Operator
value: "heima" # The value of tolerated stains
effect: "NoExecute" # Add the tolerance rule, which must be the same as the stain rule of the mark
# Add pod before tolerance [root@k8s-master01 ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED pod-toleration 0/1 Pending 0 3s <none> <none> <none> # Add pod after tolerance [root@k8s-master01 ~]# kubectl get pods -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED pod-toleration 1/1 Running 0 3s 10.244.1.62 node1 <none>
Let's take a look at the detailed configuration of tolerance:
[root@k8s-master01 ~]# kubectl explain pod.spec.tolerations ...... FIELDS: key # Corresponding to the key of the stain to be tolerated, null means to match all the keys value # The value corresponding to the stain to be tolerated operator # The key value operator supports Equal and Exists (default) effect # For the effect corresponding to the stain, null means to match all effects tolerationSeconds # Tolerance time, which takes effect when the effect is NoExecute, indicates the residence time of the pod on the Node