From the perspective of Kube scheduler, it calculates the optimal node running Pod through a series of algorithms. When a new Pod appears for scheduling, the scheduler will make the optimal scheduling decision according to its resource description of Kubernetes cluster at that time. However, Kubernetes cluster is very dynamic. Due to the changes within the whole cluster, such as a node for maintenance, We first execute the eviction operation, and all pods on this node will be evicted to other nodes. However, after our maintenance is completed, the previous pods will not automatically return to this node, because once the Pod is bound, the node will not trigger rescheduling. Due to these changes, Kubernetes cluster may be in an unbalanced state for a period of time, Therefore, an equalizer is needed to rebalance the cluster.
Of course, we can manually balance some clusters, such as manually deleting some pods and triggering rescheduling, but obviously this is a cumbersome process and not a way to solve the problem. In order to solve the problem that the cluster resources cannot be fully utilized or wasted in actual operation, the descscheduler component can be used to schedule and optimize the Pod of the cluster. Descscheduler can help us rebalance the cluster state according to some rules and configuration policies. Its core principle is to find the Pod that can be removed and expel them according to its policy configuration, Instead of scheduling the expelled Pod, it relies on the default scheduler. Currently, the supported strategies are:
- RemoveDuplicates
- LowNodeUtilization
- RemovePodsViolatingInterPodAntiAffinity
- RemovePodsViolatingNodeAffinity
- RemovePodsViolatingNodeTaints
- RemovePodsViolatingTopologySpreadConstraint
- RemovePodsHavingTooManyRestarts
- PodLifeTime
These policies can be enabled or disabled. As a part of the policy, you can also configure some parameters related to the policy. By default, all policies are enabled. In addition, there are some general configurations, as follows:
- nodeSelector: limits the nodes to be processed
- evictLocalStoragePods: evict Pods using LocalStorage
- ignorePvcPods: whether to ignore the configured PVC Pods. The default is False
- maxNoOfPodsToEvictPerNode: the maximum number of evicted Pods allowed by the node
We can configure it through DeschedulerPolicy as shown below:
apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" nodeSelector: prod=dev evictLocalStoragePods: true maxNoOfPodsToEvictPerNode: 40 ignorePvcPods: false strategies: # Configuration policy ...
install
Descscheduler can run in k8s cluster in the form of Job, CronJob or Deployment. Similarly, we can use Helm Chart to install descscheduler:
➜ helm repo add descheduler https://kubernetes-sigs.github.io/descheduler/
Through Helm Chart, we can configure descscheduler to run in the mode of CronJob or Deployment. By default, descscheduler will run in a critical pod to avoid being expelled by itself or kubelet. We need to ensure that there is a priority class of system cluster critical in the cluster:
➜ kubectl get priorityclass system-cluster-critical NAME VALUE GLOBAL-DEFAULT AGE system-cluster-critical 2000000000 false 87d
Installing with Helm Chart will run in the form of CronJob by default, and the execution cycle is schedule: "*/2 * * *", so the descheduler task will be executed every two minutes. The default configuration strategy is as follows:
apiVersion: v1
kind: ConfigMap
metadata:
name: descheduler
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
LowNodeUtilization:
enabled: true
params:
nodeResourceUtilizationThresholds:
targetThresholds:
cpu: 50
memory: 50
pods: 50
thresholds:
cpu: 20
memory: 20
pods: 20
RemoveDuplicates:
enabled: true
RemovePodsViolatingInterPodAntiAffinity:
enabled: true
RemovePodsViolatingNodeAffinity:
enabled: true
params:
nodeAffinityType:
- requiredDuringSchedulingIgnoredDuringExecution
RemovePodsViolatingNodeTaints:
enabled: true
By configuring the strategies of DeschedulerPolicy, you can specify the execution policies of descheduler. These policies can be enabled or disabled. We will introduce them in detail below. Here we can use the default policy and install it directly with the following commands:
➜ helm upgrade --install descheduler descheduler/descheduler --set image.repository=cnych/descheduler,podSecurityPolicy.create=false -n kube-system Release "descheduler" does not exist. Installing it now. NAME: descheduler LAST DEPLOYED: Fri Jan 21 10:35:55 2022 NAMESPACE: kube-system STATUS: deployed REVISION: 1 NOTES: Descheduler installed as a cron job.
After deployment, a CronJob resource object will be created to balance the cluster state:
➜ kubectl get cronjob -n kube-system NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE descheduler */2 * * * * False 1 27s 31s ➜ kubectl get job -n kube-system NAME COMPLETIONS DURATION AGE descheduler-27378876 1/1 72s 79s ➜ kubectl get pods -n kube-system -l job-name=descheduler-27378876 NAME READY STATUS RESTARTS AGE descheduler-27378876--1-btjmd 0/1 Completed 0 2m21s
Under normal circumstances, a corresponding Job will be created to execute the descscheduler task. We can know what balancing operations have been done by viewing the log:
➜ kubectl logs -f descheduler-27378876--1-btjmd -n kube-system I0121 02:37:10.127266 1 named_certificates.go:53] "Loaded SNI cert" index=0 certName="self-signed loopback" certDetail="\"apiserver-loopback-client@1642732630\" [serving] validServingFor=[apiserver-loopback-client] issuer=\"apiserver-loopback-client-ca@1642732629\" (2022-01-21 01:37:09 +0000 UTC to 2023-01-21 01:37:09 +0000 UTC (now=2022-01-21 02:37:10.127237 +0000 UTC))" I0121 02:37:10.127324 1 secure_serving.go:195] Serving securely on [::]:10258 I0121 02:37:10.127363 1 tlsconfig.go:240] "Starting DynamicServingCertificateController" I0121 02:37:10.138724 1 node.go:46] "Node lister returned empty list, now fetch directly" I0121 02:37:10.172264 1 nodeutilization.go:167] "Node is overutilized" node="master1" usage=map[cpu:1225m memory:565Mi pods:16] usagePercentage=map[cpu:61.25 memory:15.391786081415567 pods:14.545454545454545] I0121 02:37:10.172313 1 nodeutilization.go:164] "Node is underutilized" node="node1" usage=map[cpu:675m memory:735Mi pods:16] usagePercentage=map[cpu:16.875 memory:9.542007959787252 pods:14.545454545454545] I0121 02:37:10.172328 1 nodeutilization.go:170] "Node is appropriately utilized" node="node2" usage=map[cpu:975m memory:1515Mi pods:15] usagePercentage=map[cpu:24.375 memory:19.66820054018583 pods:13.636363636363637] I0121 02:37:10.172340 1 lownodeutilization.go:100] "Criteria for a node under utilization" CPU=20 Mem=20 Pods=20 I0121 02:37:10.172346 1 lownodeutilization.go:101] "Number of underutilized nodes" totalNumber=1 I0121 02:37:10.172355 1 lownodeutilization.go:114] "Criteria for a node above target utilization" CPU=50 Mem=50 Pods=50 I0121 02:37:10.172360 1 lownodeutilization.go:115] "Number of overutilized nodes" totalNumber=1 I0121 02:37:10.172374 1 nodeutilization.go:223] "Total capacity to be moved" CPU=1325 Mem=3267772416 Pods=39 I0121 02:37:10.172399 1 nodeutilization.go:226] "Evicting pods from node" node="master1" usage=map[cpu:1225m memory:565Mi pods:16] I0121 02:37:10.172485 1 nodeutilization.go:229] "Pods on node" node="master1" allPods=16 nonRemovablePods=13 removablePods=3 I0121 02:37:10.172495 1 nodeutilization.go:236] "Evicting pods based on priority, if they have same priority, they'll be evicted based on QoS tiers" I0121 02:37:10.180353 1 evictions.go:130] "Evicted pod" pod="default/topo-demo-6bbf65d967-lzlfh" reason="LowNodeUtilization" I0121 02:37:10.181506 1 nodeutilization.go:269] "Evicted pods" pod="default/topo-demo-6bbf65d967-lzlfh" err=<nil> I0121 02:37:10.181541 1 nodeutilization.go:294] "Updated node usage" node="master1" CPU=1225 Mem=592445440 Pods=15 I0121 02:37:10.182496 1 event.go:291] "Event occurred" object="default/topo-demo-6bbf65d967-lzlfh" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerLowNodeUtilization" ......
From the log, we can clearly know which Pods are expelled because of what strategy.
PDB
The use of descscheduler will evict the Pod for rescheduling, but if all copies of a service are evicted, the service may be unavailable. If there is a single point of failure in the service itself, the service will be unavailable when evicted. In this case, we strongly recommend using anti affinity and multiple replicas to avoid a single point of failure. However, if the service itself is scattered on multiple nodes and these pods are evicted, the service will also be unavailable at this time, In this case, we can prevent all copies from being deleted at the same time by configuring the PDB (poddisruption budget) object. For example, we can set that at most one copy of an application is unavailable at the time of expulsion, so we can create a resource list as follows:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: pdb-demo
spec:
maxUnavailable: 1 # Set the maximum number of unavailable copies, or use minAvailable, which can be an integer or a percentage
selector:
matchLabels: # Match Pod Tags
app: demo
More details about PDB can be found in the official documents: https://kubernetes.io/docs/tasks/run-application/configure-pdb/ .
Therefore, if we use descscheduler to rebalance the cluster state, we strongly recommend creating a corresponding PodDisruptionBudget object for the application for protection.
strategy
PodLifeTime
This policy is used to evict Pods older than maxPodLifeTimeSeconds. You can configure which status Pods will be evicted through podStatusPhases. It is recommended to create a PDB for each application to ensure the availability of the application. For example, we can configure the following policy to evict Pods that have been running for more than 7 days:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"PodLifeTime":
enabled: true
params:
maxPodLifeTimeSeconds: 604800 # Pods runs for up to 7 days
RemoveDuplicates
This policy ensures that only one RS, Deployment or Job resource object associated with Pod runs on the same node. If there are more pods, these repeated pods will be expelled to better disperse the pods in the cluster. If some nodes crash for some reason, and the pods on these nodes drift to other nodes, resulting in multiple pods associated with RS running on the same node, this may happen. Once the failed node is ready again, this policy can be enabled to expel these duplicate pods.
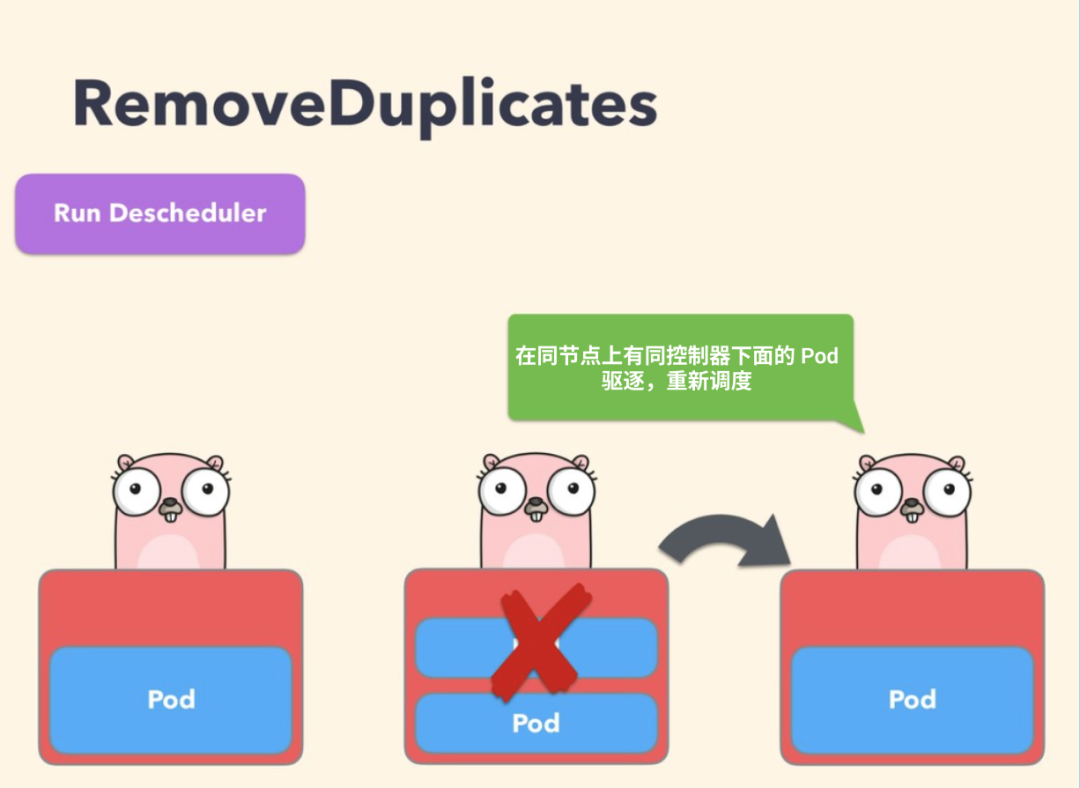
When configuring the policy, you can specify the parameter excludeownerkind to exclude types. Pod s under these types will not be expelled:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemoveDuplicates":
enabled: true
params:
removeDuplicates:
excludeOwnerKinds:
- "ReplicaSet"
LowNodeUtilization
This strategy is mainly used to find underutilized nodes and expel pods from other nodes so that Kube scheduler can reschedule them to underutilized nodes. The parameters of this policy can be configured through the field nodeResourceUtilizationThresholds.
The underutilization of nodes can be determined by configuring the thresholds threshold parameter, and can be configured by the percentage of CPU, memory and Pods. If the utilization rate of a node is lower than all thresholds, it is considered that the node is underutilized.
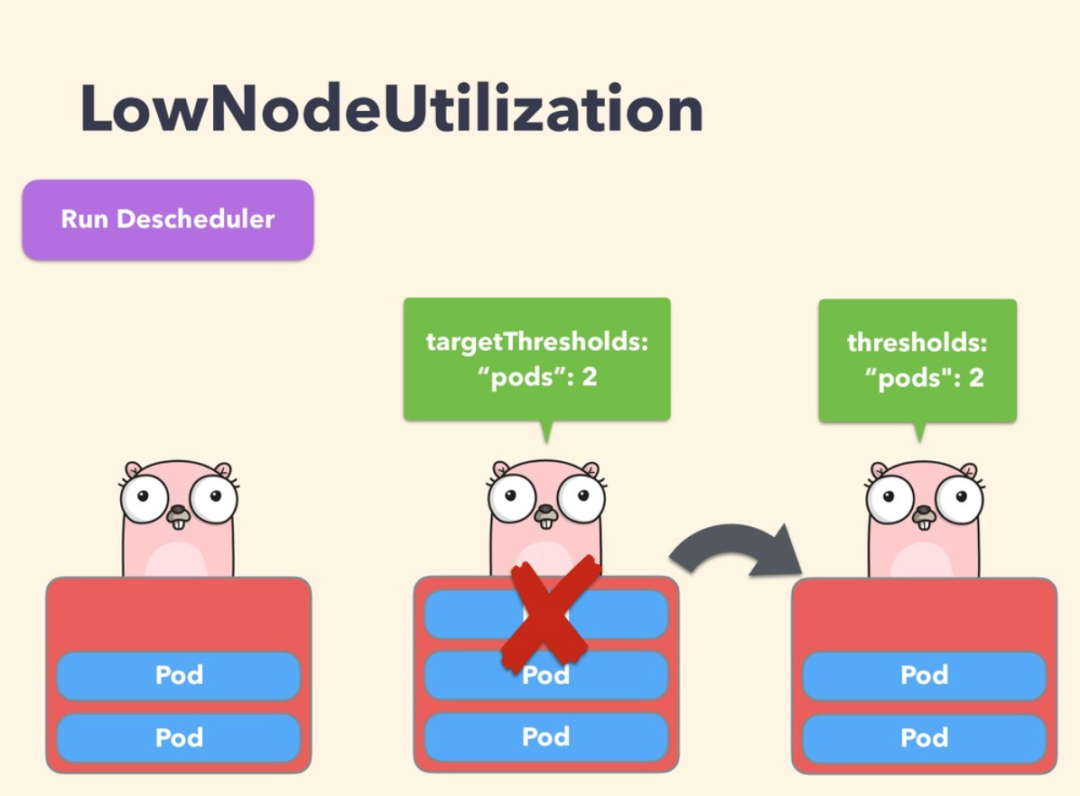
In addition, there is a configurable threshold targetThresholds, which is used to calculate the potential nodes that may expel Pods. This parameter can also be configured by configuring CPU, memory and the percentage of Pods. thresholds and targetThresholds can be dynamically adjusted according to your cluster requirements, as shown in the following example:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"LowNodeUtilization":
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
It should be noted that:
- Only the following three resource types are supported: cpu, memory and pods
- thresholds and targetThresholds must be configured with the same type
- The access of parameter value is 0-100 (percentage system)
- For the same resource type, the configuration of thresholds cannot be higher than that of targetThresholds
If no resource type is specified, it defaults to 100% to avoid nodes from being underutilized to over utilized. Another parameter associated with the LowNodeUtilization policy is numberOfNodes. This parameter can be configured to activate the policy only when the number of underutilized nodes is greater than the configured value. This parameter is very useful for large clusters. Some nodes may be frequently used or underused for a short time. By default, numberOfNodes is 0.
RemovePodsViolatingInterPodAntiAffinity
This strategy can ensure that the Pod violating the anti affinity of Pod is deleted from the node. For example, if there is a Pod on a node, and podB and podC (running on the same node) have anti affinity rules that prohibit them from running on the same node, then podA will be expelled from the node so that podB and podC can operate normally. When podB and podC have been running on the node, the anti affinity rule will be created to send such a problem.
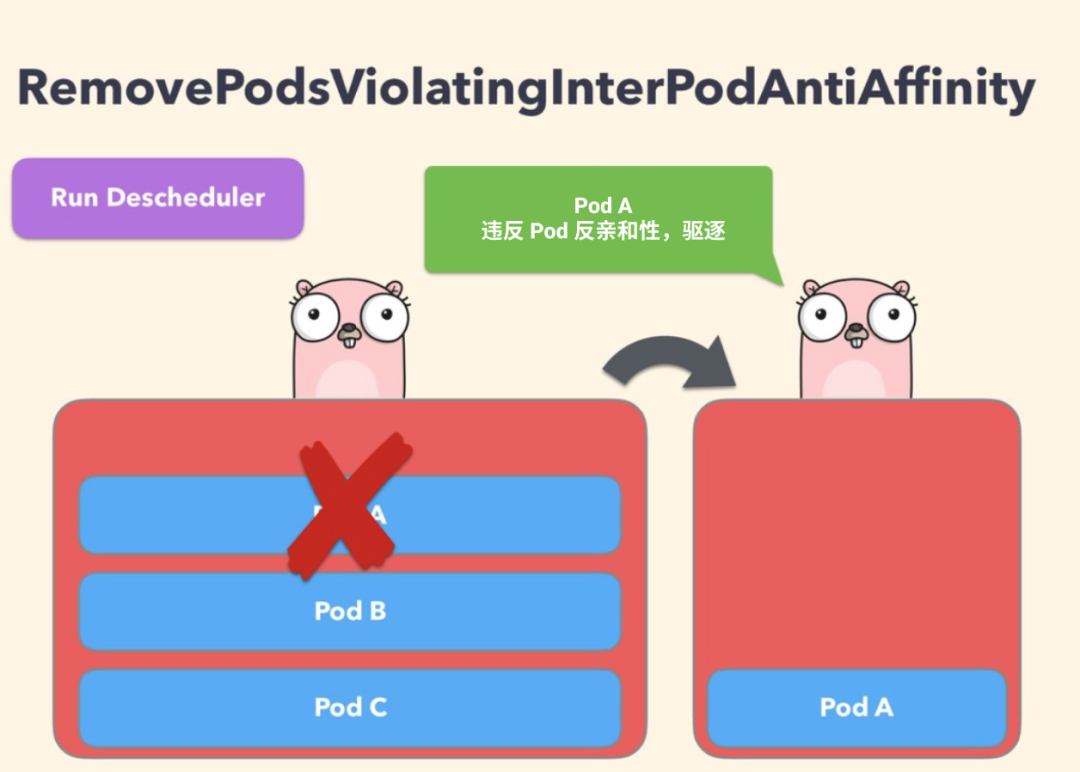
To disable this policy, configure it to false directly:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingInterPodAntiAffinity":
enabled: false
RemovePodsViolatingNodeTaints
This policy can ensure that the Pod violating the NoSchedule stain is deleted from the node. For example, a Pod named podA is allowed to be scheduled to the node with the stain configuration by configuring tolerance key=value:NoSchedule. If the stain of the node is subsequently updated or deleted, the stain will no longer be satisfied by the tolerance of Pods, and then will be expelled:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingNodeTaints":
enabled: true
RemovePodsViolatingNodeAffinity
This policy ensures that pods that violate node affinity are deleted from the node. For example, a Pod named podA is scheduled to node nodeA, which meets the node affinity rule requiredduringschedulingignored duringexecution. However, as time goes by, node nodeA no longer meets the rule. If another node nodeB that meets the node affinity rule is available, podA will be expelled from node nodeA, The following is an example of policy configuration:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingNodeAffinity":
enabled: true
params:
nodeAffinityType:
- "requiredDuringSchedulingIgnoredDuringExecution"
RemovePodsViolatingTopologySpreadConstraint
This strategy ensures that Pods violating topological distribution constraints are expelled from nodes. Specifically, it attempts to expel the minimum number of Pods required to balance the topological domain into maxSkew of each constraint, but this strategy needs k8s version higher than 1.18 to be used.
By default, this policy only deals with hard constraints. If the parameter includeSoftConstraints is set to True, soft constraints will also be supported.
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingTopologySpreadConstraint":
enabled: true
params:
includeSoftConstraints: false
RemovePodsHavingTooManyRestarts
This policy ensures that Pods with too many restarts are deleted from the node. Its parameters include podRestartThreshold (this is the number of restarts that should evict the Pod) and InitContainers. It determines whether the restart of the initialization container should be considered in the calculation. The policy configuration is as follows:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsHavingTooManyRestarts":
enabled: true
params:
podsHavingTooManyRestarts:
podRestartThreshold: 100
includingInitContainers: true
Filter Pods
When evicting Pods, sometimes it is not necessary for all Pods to be evicted. Descscheduler provides two main ways to filter: namespace filtering and priority filtering.
Namespace filtering
This policy can configure whether to include or exclude certain namespaces. You can use this policy:
- PodLifeTime
- RemovePodsHavingTooManyRestarts
- RemovePodsViolatingNodeTaints
- RemovePodsViolatingNodeAffinity
- RemovePodsViolatingInterPodAntiAffinity
- RemoveDuplicates
- RemovePodsViolatingTopologySpreadConstraint
For example, if only Pods in some command spaces are expelled, the include parameter can be used for configuration, as shown below:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"PodLifeTime":
enabled: true
params:
podLifeTime:
maxPodLifeTimeSeconds: 86400
namespaces:
include:
- "namespace1"
- "namespace2"
Or to exclude Pods in some command spaces, you can use the exclude parameter to configure, as shown below:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"PodLifeTime":
enabled: true
params:
podLifeTime:
maxPodLifeTimeSeconds: 86400
namespaces:
exclude:
- "namespace1"
- "namespace2"
Priority filtering
All policies can be configured with a priority threshold. Only pods below this threshold will be expelled. We can specify this threshold by setting the thresholdpriorityclassigname (setting the threshold to the value of the specified priority category) or thresholdPriority (directly setting the threshold) parameters. By default, the threshold is set to the value of the PriorityClass class system cluster critical.
For example, use thresholdPriority:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"PodLifeTime":
enabled: true
params:
podLifeTime:
maxPodLifeTimeSeconds: 86400
thresholdPriority: 10000
Or use thresholdpriorityclassigname for filtering:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"PodLifeTime":
enabled: true
params:
podLifeTime:
maxPodLifeTimeSeconds: 86400
thresholdPriorityClassName: "priorityclass1"
However, it should be noted that thresholdPriority and thresholdpriorityclassigname cannot be configured at the same time. If the specified priority class does not exist, the descscheduler will not create it and will cause an error.
matters needing attention
When using descheduler to drive out Pods, you should pay attention to the following points:
- Critical pods will not be expelled, such as those whose priorityclassigname is set to system cluster critical or system node critical
- Pods not managed by RS, Deployment or Job will not be expelled
- Pods created by DaemonSet will not be evicted
- Pod s using LocalStorage will not be evicted unless evictLocalStoragePods: true is set
- Pods with PVC will not be evicted unless ignorePvcPods: true is set
- Under the policies of LowNodeUtilization and RemovePodsViolatingInterPodAntiAffinity, Pods are expelled from low to high priority. If the priority is the same, Pods of Besteffort type are expelled before those of bursable and Guaranteed types
- annotations with descscheduler alpha. kubernetes. All Pods in the IO / evict field can be expelled. This comment is used to override the check to prevent expulsion. The user can choose which Pods to expel
- If the Pods expulsion fails, you can set -- v=4 to find the reason from the descscheduler log. If the expulsion violates the PDB constraint, such Pods will not be expelled