The business scenario is multi label classification prediction. It is rumored that xgboost won the champion of most non xx data in the kaggle field, so it tried ox knife xgboost for the first time.
xgboost model training reported an error. Baidu turned around and didn't find the corresponding solution. Finally, it tried out the solution by guessing the possible blocking points and trying to crack them one by one.
In line with the principle of opening up wasteland, sharing and promoting exchanges, I would like to write this post.
Background and content of error reporting
The error prompt line is "xgb.train(plst, dtrain, num_rounds)":
# xgboost model training model = xgb.train(plst, dtrain, num_rounds)
Key tips for error reporting,
Simple version:
SoftmaxMultiClassObj: label must be in [0, num_class)
Complex version:
"xgboost.core.XGBoostError: [14:54:48] /opt/concourse/worker/volumes/live/7a2b9f41-3287-451b-6691-43e9a6c0910f/volume/xgboost-split_1619728204606/work/src/objective/multiclass_obj.cu:120: SoftmaxMultiClassObj: label must be in [0, num_class)."
Details of error message are shown in Figure 2 below:


The complete code is as follows:
# Model call
import time
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # Accuracy
import matplotlib.pyplot as plt
import matplotlib
# %matplotlib inline
from sklearn.datasets import load_iris
from sklearn.datasets import load_boston
# # Record sample data set
# iris = load_iris()
# X, y = iris.data, iris.target
# print('X: \n',X,'\nY: \n',y)
# print('X.shape: \n',X.shape,'\ny.shape: \n',y.shape)
# Record sample data set
X, y = dt_sample, dt_label
print('X: \n',X,'\nY: \n',y)
print('X.shape: \n',X.shape,'\ny.shape: \n',y.shape)
# Data set segmentation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565)
# Algorithm parameters
params = {
# General parameters
'booster': 'gbtree',
'nthread': 4,
'silient': 0,
# 'num_feature': 5, # If the feature dimension used in the Boosting process is set to the number of features, xgboost will be set automatically without manual setting.
'seed': 1000,
# Task parameters
'objective': 'multi:softmax', # Multi classification problem
'num_class': 6, #Total number of categories, 6 in combination with multi softmax
# Lifting parameters
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'eta': 0.1,
# 'eval_metric': 'auc'
}
plst = params.items()
print("plst: \n", plst)
plst = list(params.items())
print("list(plst): \n", plst)
# Generate dataset format
dtrain = xgb.DMatrix(X_train, y_train)
#The number of iterations. For the classification problem, the number of iterations of each category. Therefore, the total number of base learners = number of iterations * number of categories
num_rounds = 500
# xgboost model training
model = xgb.train(plst, dtrain, num_rounds)
# Predict the test set
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
print("y_pred: \n", y_pred)
# Calculation accuracy
accuracy = accuracy_score(y_test, y_pred)
print('accuarcy:%.2f%%' % (accuracy * 100))
# Show important features
plot_importance(model)
plt.show()
Solution
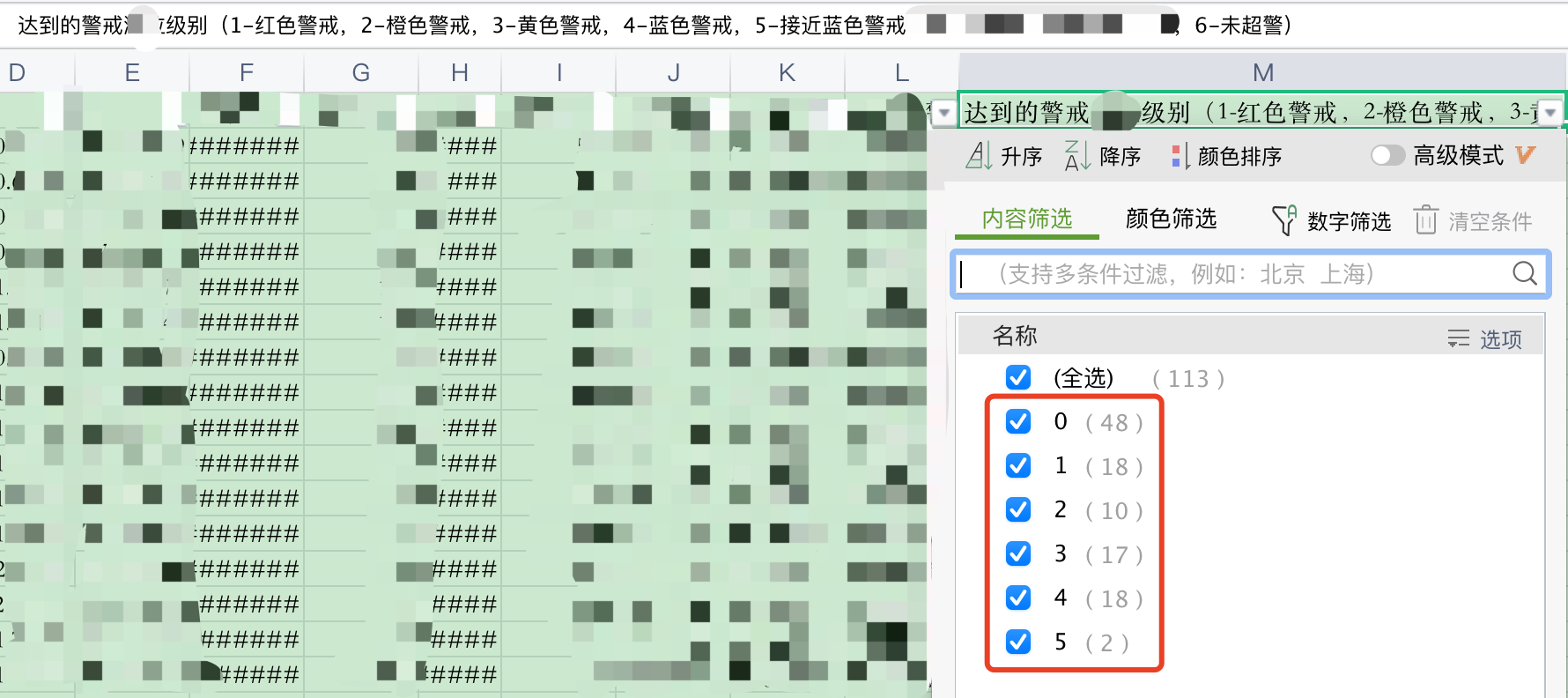
Change the data value range of the label label column to be predicted in the data source from 1 ~ 6 (i.e. 1, 2, 3, 4, 5, 6) to 0 ~ 5 (i.e. 0, 1, 2, 3, 4, 5). The same code can be successfully run again without change.
PS: in fact, there seems to be a data processing process for all classifications, even the classification of Chinese names. Convert all classifications into values of 0 ~ N, and then input them into xgboost trainer. There is no time to take a closer look. If there is no accident, it should be one-hot (you can use the search engine to confirm by yourself).
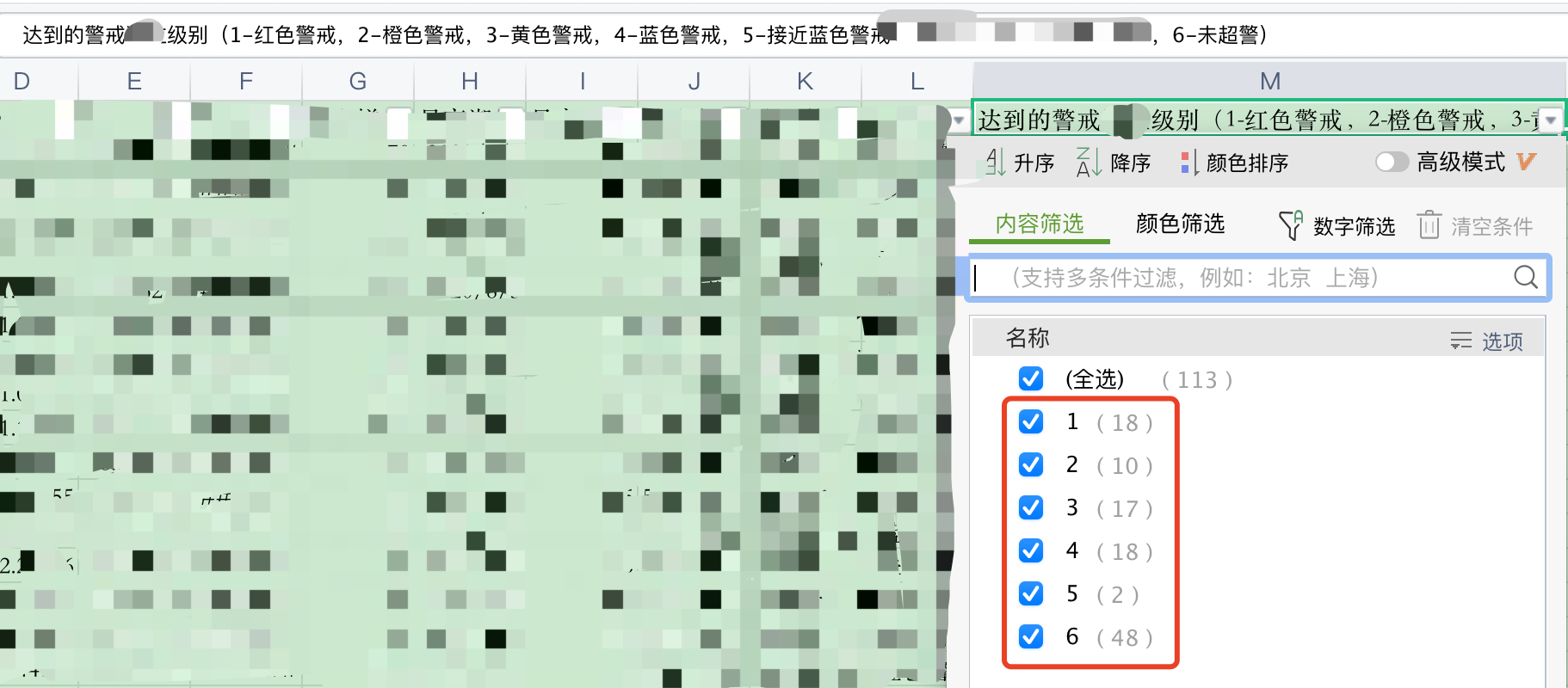
Before the tag column attached with data source is changed: the value is 1 ~ 6 (error reported in model training)
After the data source label column is changed: the value is 0 ~ 5 (the model training is normal)
Solving process
According to the prompt "label must be in [0, num_class)", this seems to prompt the label data, that is, the multi label classification results to be predicted.
Before error reporting, the value range of label data is 1 ~ 6, i.e. 6 numbers such as 1, 2, 3, 4, 5 and 6.
Guess there are several possibilities.
The first one: the data set form used for import is different from the data set form / format required by xgboost trainer, such as the difference between dataframe and xgb dedicated data set DMatrix.
The second method is to import the data of the data set used without box splitting, one-hot and other processing. After trying, it is the second kind.
complete.