Learn more about Spring cache of SpringBoot series
- Why cache
- Why use Spring Cache
- How to use Spring Cache
- Common notes
- Analyze the operation process of annotation combined with source code
- Problems caused by using cache
- summary
Why cache
Using cache is a "cost-effective" performance optimization method, especially for programs with a large number of repeated queries. Generally speaking, for WEB back-end applications, there are two places that take a lot of time: one is to query the database, and the other is to call the API of other services (because other services eventually have to do time-consuming operations such as querying the database).
There are also two types of duplicate queries. One is that we don't write the code well in the application. The for loop may be queried with repeated parameters every time. In this case, the smarter programmers will reconstruct this code, use the Map to temporarily put the found things in memory, and check whether there is any in the Map before subsequent query. In fact, this is a cache idea.
Another type of duplicate query is caused by a large number of identical or similar requests. For example, the article list on the home page of information websites, the commodity list on the home page of e-commerce websites, articles hot searched by social media such as microblog, etc. when a large number of users request the same interface and the same data, if they check the database every time, it is an unbearable pressure on the database. Therefore, we usually cache high-frequency queries, which we call "hot spots".
Why use Spring Cache
As mentioned earlier, caching has many benefits, so everyone is ready to add caching to their applications. However, a search on the Internet found that there are too many caching frameworks, each with its own advantages, such as Redis, Memcached, Guava, Caffeine and so on.
If our program wants to use caching, it needs to be coupled with these frameworks. Smart architects are already using interfaces to reduce coupling, using object-oriented abstraction and polymorphism to separate business code from specific frameworks.
However, we still need to explicitly call cache related interfaces and methods in the code, insert data into the cache at the right time, and read data from the cache at the right time.
Think about the applicable scenario of AOP. Isn't that what AOP should do naturally?
Yes, Spring Cache is an example of this framework. It uses AOP to realize the annotation based caching function, and makes a reasonable abstraction. The business code does not care what caching framework is used at the bottom. It can realize the caching function by simply adding an annotation. Moreover, Spring Cache also provides many default configurations. Users can use the last very good caching function in 3 seconds.
How to use Spring Cache
Using spring cache is divided into three simple steps: adding dependencies, opening cache, and adding cache annotations.
Add dependency
gradle:
implementation 'org.springframework.boot:spring-boot-starter-cache'
maven:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>Enable cache
Add the @ EnableCaching annotation to the startup class to enable the use of caching.
@SpringBootApplication
@EnableCaching
public class CachingApplication {
public static void main(String[] args) {
SpringApplication.run(CachingApplication.class, args);
}
}Add cache annotation
Add the @ Cacheable annotation to the method to be cached to cache the return value of this method.
@Override
@Cacheable("books")
public Book getByIsbn(String isbn) {
simulateSlowService();
return new Book(isbn, "Some book");
}
// Don't do this at home
private void simulateSlowService() {
try {
long time = 3000L;
Thread.sleep(time);
} catch (InterruptedException e) {
throw new IllegalStateException(e);
}
}test
@Override
public void run(String... args) {
logger.info(".... Fetching books");
logger.info("isbn-1234 -->" + bookRepository.getByIsbn("isbn-1234"));
logger.info("isbn-4567 -->" + bookRepository.getByIsbn("isbn-4567"));
logger.info("isbn-1234 -->" + bookRepository.getByIsbn("isbn-1234"));
logger.info("isbn-4567 -->" + bookRepository.getByIsbn("isbn-4567"));
logger.info("isbn-1234 -->" + bookRepository.getByIsbn("isbn-1234"));
logger.info("isbn-1234 -->" + bookRepository.getByIsbn("isbn-1234"));
}Test it, you can find. The first and second calls (the second parameter is different from the first) to the getByIsbn method will wait for 3 seconds, and the next four calls will return immediately.
Common notes
Spring Cache has several common annotations, namely @ Cacheable, @ CachePut, @ CacheEvict, @ Caching, @ CacheConfig. Except for the last CacheConfig, the other four can be used at the class or method level. If they are used on a class, they will take effect on all public methods of the class. These annotations are introduced below.
@Cacheable
@The Cacheble annotation indicates that this method has the function of caching, and the return value of the method will be cached. Before calling the method next time, it will check whether there is a value in the cache. If so, it will be returned directly without calling the method. If not, call the method and cache the results. This annotation is generally used for query methods.
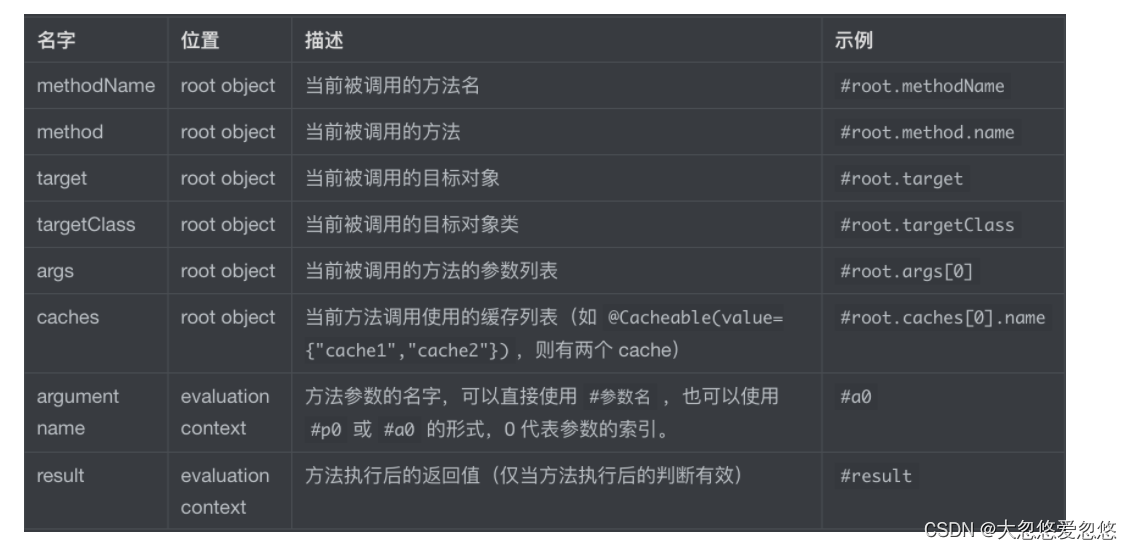
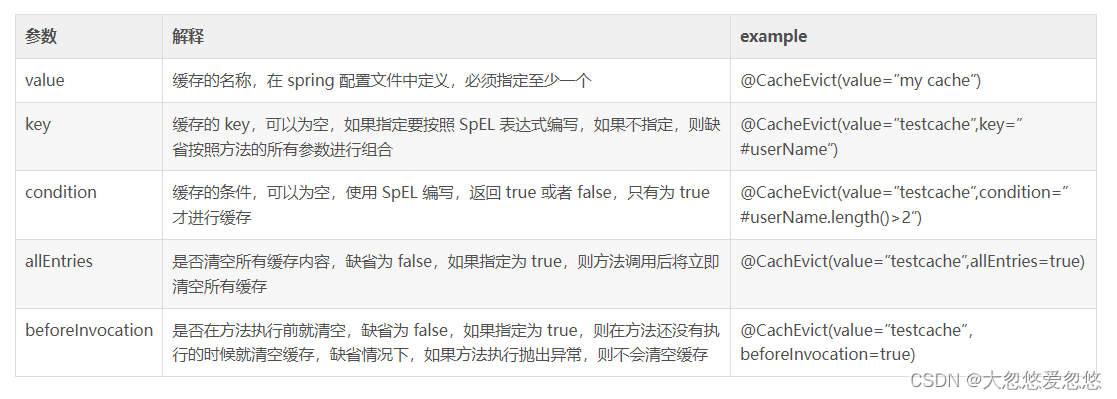
- Value and cacheNames: two equivalent parameters (cacheNames is newly added to Spring 4 as an alias for value), which are used to specify the collection name stored in the cache. Since @ CacheConfig has been added in Spring 4, the value attribute that was originally required in Spring 3 has also become a non required item
- Key: and cacheNames form a key. It is not required. By default, all parameters of the function are combined as the key value. If you configure it yourself, you need to use a spiel expression, such as @ Cacheable(key = "#p0"): use the first parameter of the function as the cached key value. For more details about spiel expressions, please refer to Official documents
- Condition: the condition of the cache object. It is not necessary. It also needs to use the spel expression. Only the content that meets the expression condition can be cached, for example: @ cacheable (key = "#p0", condition = "#p0. Length() < 3"), which means that the cache will only be cached when the length of the first parameter is less than 3. If this configuration is made, the AAA user above will not be cached, Readers can experiment and try by themselves to judge before function call, so the result is always null
- unless: another cache condition parameter, which is not required and requires a SpEL expression. The difference from the condition parameter lies in its judgment timing. The condition is judged only after the function is called, so it can be judged by the result.
- keyGenerator: used to specify the key generator, not required. If we need to specify a custom key generator, we need to implement the org.springframework.cache.interceptor.KeyGenerator interface and use this parameter to specify it. Note that this parameter and key are mutually exclusive
- cacheManager: used to specify which cache manager to use. It is not required. Use only when there are multiple
- cacheResolver: used to specify which cache parser to use, not required. You need to implement your own cache parser through the org.springframework.cache.interceptor.CacheResolver interface, and specify it with this parameter.
Function and configuration method

/** * Obtain Tasklog * @param id * @return according to ID */
@Cacheable(value = CACHE_KEY, key = "#id",condition = "#result != null")
public Tasklog findById(String id){
System.out.println("FINDBYID");
System.out.println("ID:"+id);
return taskLogMapper.selectById(id);
}The spel expression in the cache can take values
@CachePut
@CachePut is mainly used for method configuration. It can cache the results according to the request parameters of the method. Unlike @ Cacheable, it will trigger the call of the real method every time
Function and configuration method

/** * Add tasklog * @param tasklog * @return */
@CachePut(value = CACHE_KEY, key = "#tasklog.id")
public Tasklog create(Tasklog tasklog){
System.out.println("CREATE");
System.err.println (tasklog);
taskLogMapper.insert(tasklog);
return tasklog;
}@CacheEvict
@CachEvict is mainly used for method configuration and can empty the cache according to certain conditions
It is generally used in the method of updating or deleting.
Function and configuration method
/** * Delete tasklog according to ID * @ param ID */
@CacheEvict(value = CACHE_KEY, key = "#id")
public void delete(String id){
System.out.println("DELETE");
System.out.println("ID:"+id);
taskLogMapper.deleteById(id);
}@Caching
The mechanism of Java annotation determines that only one same annotation can take effect on a method. Sometimes, one method may operate multiple caches (this is more common in delete cache operations and less common in add operations).
Of course, Spring Cache also takes this situation into account. The @ Caching annotation is used to solve this kind of situation. You can see it from the source code.
public @interface Caching {
Cacheable[] cacheable() default {};
CachePut[] put() default {};
CacheEvict[] evict() default {};
}Sometimes we may combine multiple Cache annotations; For example, after the user is successfully added, we need to add id – > user; username—>user; email - > user's Cache; At this point, you need @ Caching to combine multiple annotation labels
@Caching(put = {
@CachePut(value = "user", key = "#user.id"),
@CachePut(value = "user", key = "#user.username"),
@CachePut(value = "user", key = "#user.email")
})
public User save(User user) {
}@CacheConfig
The four annotations mentioned above are commonly used by Spring Cache. Each annotation has many configurable properties.
However, these annotations usually work on methods, and some configurations may be common to a class. In this case, @ CacheConfig can be used. It is a class level annotation. cacheNames, keyGenerator, cacheManager, cacheResolver, etc. can be configured at the class level.
For example:
All @ Cacheable() has an attribute of value = "xxx". Obviously, if there are many methods, it is very tiring to write. If it can be declared at one time, it will be easy. Therefore, with the configuration of @ CacheConfig, @ CacheConfig is a class level annotation that allows to share the cache names. If you write another name in your method, Then the name of the method still prevails.
@CacheConfig is a class level annotation.
/** * Test service layer */
@Service
@CacheConfig(cacheNames= "taskLog")
public class TaskLogService {
@Autowired private TaskLogMapper taskLogMapper;
@Autowired private net.sf.ehcache.CacheManager cacheManager;
/** * Cached key */
public static final String CACHE_KEY = "taskLog";
/** * Add tasklog * @param tasklog * @return */
@CachePut(key = "#tasklog.id")
public Tasklog create(Tasklog tasklog){
System.out.println("CREATE");
System.err.println (tasklog);
taskLogMapper.insert(tasklog);
return tasklog;
}
/** * Obtain Tasklog * @param id * @return according to ID */
@Cacheable(key = "#id")
public Tasklog findById(String id){
System.out.println("FINDBYID");
System.out.println("ID:"+id);
return taskLogMapper.selectById(id);
}
}Custom cache annotation
For example, the previous @ Caching combination will make the annotation on the method look messy. At this time, you can use custom annotation to combine these annotations into one annotation, such as:
@Caching(put = {
@CachePut(value = "user", key = "#user.id"),
@CachePut(value = "user", key = "#user.username"),
@CachePut(value = "user", key = "#user.email")
})
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface UserSaveCache {
}In this way, we can use the following code in the method, and the whole code is relatively clean.
@UserSaveCache
public User save(User user){}Complete application case
1. Annotate the startup class and enable the cache function
@SpringBootApplication
@EnableCaching//Enable use cache
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}2. Customize a pojo object
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Tasklog
{
@JsonProperty("id")
private Integer id;
@JsonProperty("name")
private String name;
@JsonProperty("age")
private Integer age;
}3. User defined annotation
@Caching(put = {
@CachePut(value = "taskLog", key = "#tasklog.id"),
@CachePut(value = "taskLog", key = "#tasklog.name"),
@CachePut(value = "taskLog", key = "#tasklog.age")
})
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface CustomCache {
}4.service layer writing
/** * Test service layer */
@Service
//The key in the cache consists of cacheNames::key
@CacheConfig(cacheNames = "taskLog")
public class TaskLogService {
//map of simulated database
private static Map<Integer, Object> map=new ConcurrentHashMap<>();
static
{
map.put(1,new Tasklog(1,"Big flicker and children",18));
}
/**
* Cached key
*/
public static final String CACHE_KEY = "taskLog";
/**
* Add tasklog * @param tasklog * @return
*/
//Trigger the call of the real method and cache the request results
@CachePut(key = "#tasklog.id")
public Tasklog create(Tasklog tasklog) {
System.out.println("CREATE");
System.err.println(tasklog);
map.put(tasklog.getId(),tasklog);
return tasklog;
}
@CustomCache//Custom annotation - three key s will be generated
public Tasklog createByCustom(Tasklog tasklog) {
System.out.println("CREATE");
System.err.println(tasklog);
map.put(tasklog.getId(),tasklog);
return tasklog;
}
/**
* Obtain Tasklog * @param id * @return according to ID
*/
//If there is a corresponding key in the cache, do not call the method. Otherwise, call the method and cache the return value
@Cacheable(key = "#id")
public Tasklog findById(Integer id)
{
System.out.println("FINDBYID");
System.out.println("ret:" + map.get(id));
return (Tasklog) map.get(id);
}
/** * Delete tasklog according to ID * @ param ID */
@CacheEvict(value = CACHE_KEY, key = "#id")
public void delete(Integer id){
System.out.println("DELETE");
map.remove(id);
}
}4.controller layer
@RestController
@RequestMapping(value ="/rest")
public class TaskLogController
{
@Autowired
private TaskLogService taskLogService;
/**
* Add tasklog
*/
@PutMapping("task")
public Tasklog create(Tasklog tasklog) {
return taskLogService.create(tasklog);
}
@PutMapping("task_C")
public Tasklog createCustom(Tasklog tasklog) {
return taskLogService.createByCustom(tasklog);
}
/**
* Get Tasklog by ID
*/
@GetMapping("task")
public Tasklog findById(@RequestParam Integer id) {
return taskLogService.findById(id);
}
/**
* Delete Tasklog by ID
*/
@DeleteMapping("task")
public String delById(@RequestParam Integer id) {
taskLogService.delete(id);
return "Delete succeeded";
}
}Analyze the operation process of annotation combined with source code
The aforementioned annotations @ Cacheable, @ CachePut, @ CacheEvict, @ CacheConfig have some configurable properties. These configured properties can be found in the abstract class CacheOperation and its subclasses. They are probably related as follows:
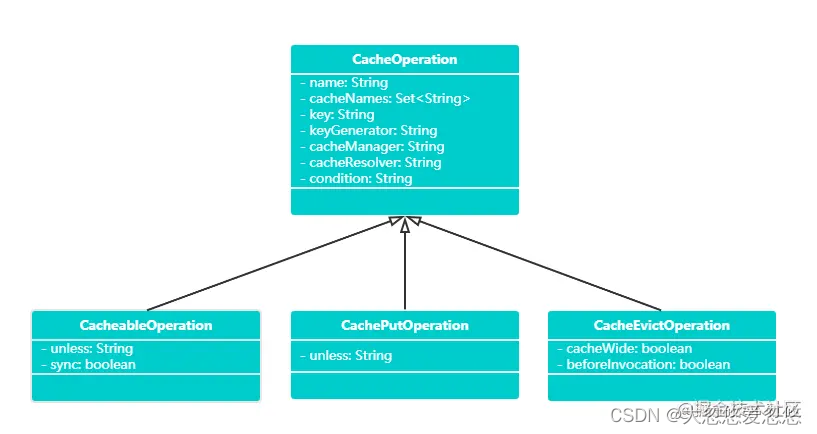
The class responsible for parsing each annotation is the SpringCacheAnnotationParser class:



... each annotation corresponds to a corresponding parsing method
When was the spring cache annotation parser called? Very simply, we can make a breakpoint on a method of this class and debug it, such as the parseCacheableAnnotation method.
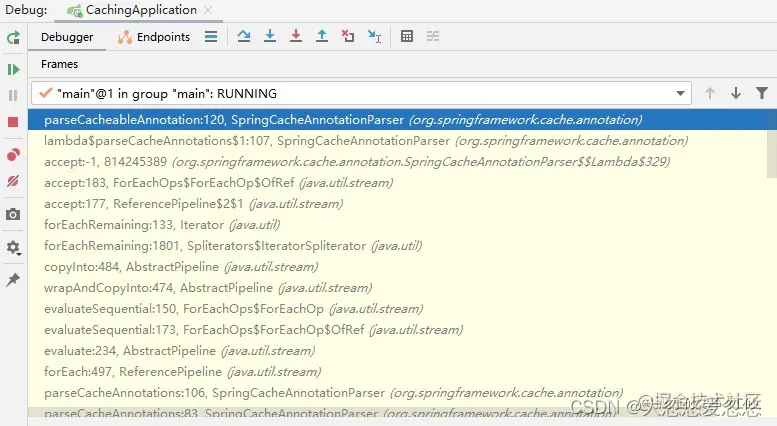
In the debug interface, we can see that the call chain is very long. In front of us is a familiar process of IOC registering beans until we see a BeanFactory called AbstractAutowireCapableBeanFactory, and then this class will look for whether there is an Advisor when creating beans. It happens that such an Advisor is defined in the Spring Cache source code: BeanFactory cacheoperationsourceadvisor.
The PointCut returned by the Advisor is a CacheOperationSourcePointcut, which replicates the matches method, obtains a CacheOperationSource and calls its getCacheOperations method. This CacheOperationSource is an interface, and the main implementation class is AnnotationCacheOperationSource. In the findCacheOperations method, we will call the SpringCacheAnnotationParser we started with.
This completes annotation based parsing.
Entrance: AOP based interceptor
What do we do when we actually call a method? As we know, a Bean using AOP will generate a proxy object. When it is actually called, it will execute a series of interceptors of the proxy object. Spring Cache uses an Interceptor called CacheInterceptor. If we add corresponding annotations to the cache, we will go to this Interceptor. This Interceptor inherits the CacheAspectSupport class and will execute the execute method of this class. This method is the core method we want to analyze.
@sync for Cacheable
Let's continue to look at the execute method mentioned earlier. This method will first determine whether it is synchronous. The synchronization configuration here uses the sync – (sync indicates whether to lock) attribute of @ Cacheable, which is false by default. If synchronization is configured, when multiple threads try to cache data with the same key, it will be a synchronous operation. ! [insert picture description here]( https://img-blog.csdnimg.cn/
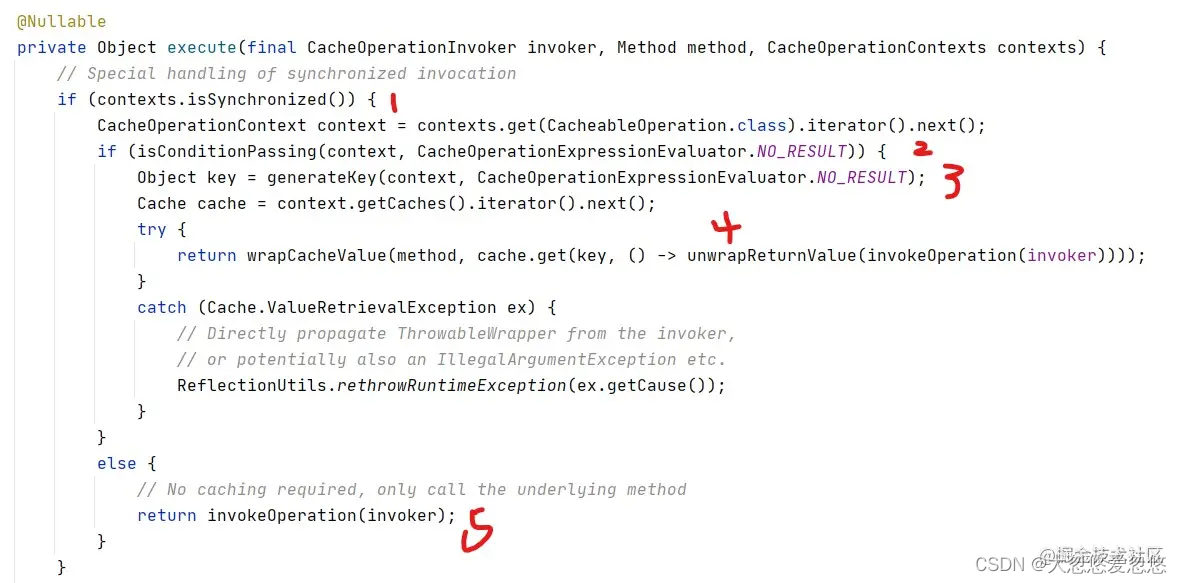
The above figure shows the old version, and the following is the latest version
private Object execute(final CacheOperationInvoker invoker, Method method, CacheAspectSupport.CacheOperationContexts contexts) {
//Determine whether it is synchronization
if (contexts.isSynchronized()) {
CacheAspectSupport.CacheOperationContext context = (CacheAspectSupport.CacheOperationContext)contexts.get(CacheableOperation.class).iterator().next();
//Judge whether the condition meets the conditions. If not, the method will be executed. Therefore, the condition is judged before the method is executed
if (!this.isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) {
return this.invokeOperation(invoker);
}
//Trying to get key
Object key = this.generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT);
//Generate a cache object
Cache cache = (Cache)context.getCaches().iterator().next();
try {
return this.wrapCacheValue(method, this.handleSynchronizedGet(invoker, key, cache));
} catch (ValueRetrievalException var10) {
ReflectionUtils.rethrowRuntimeException(var10.getCause());
}
}
this.processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT);
ValueWrapper cacheHit = this.findCachedItem(contexts.get(CacheableOperation.class));
List<CacheAspectSupport.CachePutRequest> cachePutRequests = new ArrayList();
if (cacheHit == null) {
this.collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests);
}
Object returnValue;
Object cacheValue;
if (cacheHit != null && !this.hasCachePut(contexts)) {
cacheValue = cacheHit.get();
returnValue = this.wrapCacheValue(method, cacheValue);
} else {
returnValue = this.invokeOperation(invoker);
cacheValue = this.unwrapReturnValue(returnValue);
}
this.collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);
Iterator var8 = cachePutRequests.iterator();
while(var8.hasNext()) {
CacheAspectSupport.CachePutRequest cachePutRequest = (CacheAspectSupport.CachePutRequest)var8.next();
cachePutRequest.apply(cacheValue);
}
this.processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);
return returnValue;
}Let's take a look at the source code of the synchronization operation. If we judge that the current synchronization operation is required (1), we will first judge whether the current condition meets the condition (2). The condition here is also a configuration defined in @ Cacheable. It is an EL expression. For example, we can use this to cache books with id greater than 1:
@Override
@Cacheable(cacheNames = "books", condition = "#id > 1", sync = true)
public Book getById(Long id) {
return new Book(String.valueOf(id), "some book");
}If the conditions are not met, the cache will not be used and the results will not be put into the cache. Skip to 5 directly. Otherwise, try to obtain the key (3). When obtaining the key, it will first judge whether the user has defined the key, which is also an EL expression. If not, use the keyGenerator to generate a key:
@Nullable
protected Object generateKey(@Nullable Object result) {
if (StringUtils.hasText(this.metadata.operation.getKey())) {
EvaluationContext evaluationContext = createEvaluationContext(result);
return evaluator.key(this.metadata.operation.getKey(), this.metadata.methodKey, evaluationContext);
}
return this.metadata.keyGenerator.generate(this.target, this.metadata.method, this.args);
}We can manually specify the key s such as book-1 and book-2 generated according to the id in this way:
@Override
@Cacheable(cacheNames = "books", sync = true, key = "'book-' + #id")
public Book getById(Long id) {
return new Book(String.valueOf(id), "some book");
}The key here is an Object object Object. If we do not specify the key on the annotation, we will use the key generated by the keyGenerator. The default keyGenerator is SimpleKeyGenerator, which generates a SimpleKey Object. The method is also very simple. If there is no input parameter, an EMPTY Object is returned. If there is only one input parameter and it is not EMPTY or array, this parameter is used (note that the parameter itself is used here, not the SimpleKey Object. Otherwise, a SimpleKey is wrapped with all input parameters.
The value of the argument is used, not the name of the parameter
Source code:
@Override
public Object generate(Object target, Method method, Object... params) {
return generateKey(params);
}
/**
* Generate a key based on the specified parameters.
*/
public static Object generateKey(Object... params) {
if (params.length == 0) {
return SimpleKey.EMPTY;
}
if (params.length == 1) {
Object param = params[0];
if (param != null && !param.getClass().isArray()) {
return param;
}
}
return new SimpleKey(params);
}See here, you must have a question. Here, only input parameters are used, and there is no difference between class name and method name. If the input parameters of two methods are the same, isn't it a key conflict?
You feel right. You can try these two methods:
// Define a method where both parameters are strings
@Override
@Cacheable(cacheNames = "books", sync = true)
public Book getByIsbn(String isbn) {
simulateSlowService();
return new Book(isbn, "Some book");
}
@Override
@Cacheable(cacheNames = "books", sync = true)
public String test(String test) {
return test;
}
// Call both methods with the same parameter "test"
logger.info("test getByIsbn -->" + bookRepository.getByIsbn("test"));
logger.info("test test -->" + bookRepository.test("test"));You will find that the key s generated twice are the same, and then when you call the test method, the console will report an error:
Caused by: java.lang.ClassCastException: class com.example.caching.Book cannot be cast to class java.lang.String (com.example.caching.Book is in unnamed module of loader 'app'; java.lang.String is in module java.base of loader 'bootstrap') at com.sun.proxy.$Proxy33.test(Unknown Source) ~[na:na] at com.example.caching.AppRunner.run(AppRunner.java:23) ~[main/:na] at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:795) ~[spring-boot-2.3.2.RELEASE.jar:2.3.2.RELEASE] ... 5 common frames omitted
Book cannot be forcibly converted to String, because when we first call the getByIsbn method, the generated key is test, and then the book object with the return value is replaced into the cache. When we call the test method, the generated key is still test, and the book will be taken out, but the return value of the test method is String, so we will try to forcibly convert to String, and it is found that the forcibly conversion fails.
Customize a keyGenerator
@Component
public class MyKeyGenerator implements KeyGenerator {
@Override
public Object generate(Object target, Method method, Object... params) {
return target.getClass().getName() + method.getName() +
Stream.of(params).map(Object::toString).collect(Collectors.joining(","));
}
}Then you can use the custom MyKeyGenerator in the configuration. Run the program again, and the above problems will not occur.
@Override
@Cacheable(cacheNames = "books", sync = true, keyGenerator = "myKeyGenerator")
public Book getByIsbn(String isbn) {
simulateSlowService();
return new Book(isbn, "Some book");
}
@Override
@Cacheable(cacheNames = "books", sync = true, keyGenerator = "myKeyGenerator")
public String test(String test) {
return test;
}Next, we can see that we have obtained a Cache. This Cache will create a new CacheOperationContext when we call the execute method of cachespectsupport. In the construction method of this Context, cacheResolver will be used to parse the Cache in the annotation and generate Cache objects.
The default cacheResolver is SimpleCacheResolver, which obtains the configured cacheNames from the CacheOperation, and then uses the cacheManager to get a Cache. The cacheManager here is a container for managing Cache, and the default cacheManager is ConcurrentMapCacheManager. You can tell from the name that it is based on ConcurrentMap, and the bottom layer is ConcurrentHashMap.
What is cache here? Cache is an abstraction of "cache container", including get, put, evict, putIfAbsent and other methods used in cache.
Different cacheNames correspond to different Cache objects. For example, we can define two cacheNames on one method. Although we can also use value, which is an alias of cacheNames, if there are multiple configurations, cacheNames is more recommended because it has better readability.
@Override
@Cacheable(cacheNames = {"book", "test"})
public Book getByIsbn(String isbn) {
simulateSlowService();
return new Book(isbn, "Some book");
}The default Cache is ConcurrentMapCache, which is also based on ConcurrentHashMap.
However, there is a problem here. We go back to the code of the execute method above and find that if sync is set to true, it takes the first Cache instead of the remaining caches. Therefore, if you configure sync to true, only one cacheNames can be configured. If you configure multiple cacheNames, an error will be reported:
@Cacheable(sync=true) only allows a single cache on...
Continue to look down and find that the get(Object, Callcable) method of the Cache is called. This method will first try to use the key value in the Cache. If not, call the callable function and add it to the Cache. Spring Cache also expects the implementation class of the Cache to realize the "synchronization" function within this method.
So let's look back at the comment above the sync attribute in Cacheable. It says: if sync is true, there will be these restrictions:
- It doesn't support unless. As you can see from the code, it only supports condition, not unless. I don't know why... But the Interceptor code is written like this.
- There can only be one cache, because the code is dead. I guess this is to better support synchronization. It puts synchronization into the cache.
- No other Cache operations are not supported. The code is dead and only cacheable is supported. I guess this is also to support synchronization.
After the cache expires, if multiple threads request access to a data at the same time, they will go to the database at the same time, resulting in an instantaneous increase in the load of the database. Spring 4.3 provides a new parameter "sync" (boolean type, false by default) for the @ Cacheable annotation , when it is set to true, only one thread's request will go to the database, and other threads will wait until the cache is available. This setting can reduce instantaneous concurrent access to the database.
Lock: no lock by default; sync = true (lock to solve cache breakdown)
Other operations
What if sync is false?
Continue to look at the execute code, which has roughly gone through the following steps:
- Try to delete the cache before calling the method. The beforeInvocation configured in @ CacheEvict is false by default (if it is true, the cache will be deleted in this step); Attempt to get cache;
- If it is not available in step 2, try to obtain the annotation of cacheable and generate the corresponding CachePutRequest;
- If it is obtained in step 2 and there is no cacheput annotation, the value is directly obtained from the cache. Otherwise, the target method is called;
- Parse the CachePut annotation and also generate the corresponding CachePutRequest;
- Execute all cacheputrequests;
- Try to delete the cache after the method call. If the beforeInvocation configured by @ CacheEvict is false, the cache will be deleted
- So far, we have explained the timing of all configurations in combination with the source code.
Using other caching frameworks
If you want to use other caching frameworks, what should you do?
Through the above source code analysis, we know that if we want to use other caching frameworks, we only need to redefine the two beans CacheManager and CacheResolver.
In fact, Spring will automatically detect whether we have introduced the corresponding caching framework. If we have introduced Spring data redis, Spring will automatically use the RedisCacheManager and RedisCache provided by Spring data redis.
If we want to use Caffeine framework, we only need to introduce Caffeine, and Spring Cache will use CaffeineCacheManager and CaffeineCache by default.
implementation 'org.springframework.boot:spring-boot-starter-cache' implementation 'com.github.ben-manes.caffeine:caffeine'
Caffeine is a cache framework with very high performance. It uses the Window TinyLfu recycling strategy to provide an almost optimal hit rate.
Spring Cache also supports various configurations. In the CacheProperties class, it also provides special configurations of various mainstream caching frameworks, such as the expiration time of Redis (never expires by default).
private final Caffeine caffeine = new Caffeine(); private final Couchbase couchbase = new Couchbase(); private final EhCache ehcache = new EhCache(); private final Infinispan infinispan = new Infinispan(); private final JCache jcache = new JCache(); private final Redis redis = new Redis();
Problems caused by using cache
Double write inconsistency
Using cache will bring many problems, especially high concurrency, including cache penetration, cache breakdown, cache avalanche, double write inconsistency and so on.
One of the common solutions is to delete the cache before updating the database. Therefore, @ CacheEvict of Spring Cache will have a beforeInvocation configuration.
However, when using cache, there is usually a problem that the data in the cache is inconsistent with that in the database. Especially when calling the third-party interface, you will not know when it updates the data. However, business scenarios that use caching often do not require strong consistency of data. For example, for hot articles on the home page, we can invalidate the cache for one minute. In this way, even if it is not the latest hot ranking within one minute, it doesn't matter.
Take up extra memory
This is inevitable. Because there is always a place to put the cache. Whether concurrent HashMap, Redis or Caffeine, it will occupy additional memory resources to put the cache. But the idea of caching is to trade space for time. Sometimes taking up this extra space is very worthwhile for time optimization.
It should be noted here that the default spring cache uses ConcurrentHashMap, which does not automatically recycle key s. Therefore, if the default cache is used, the program will become larger and larger and will not be recycled. It may eventually lead to OOM.
Let's simulate the experiment:
@Component
public class MyKeyGenerator implements KeyGenerator {
@Override
public Object generate(Object target, Method method, Object... params) {
// Different key s are generated each time
return UUID.randomUUID().toString();
}
}
//Adjust it 100w times
for (int i = 0; i < 1000000; i++) {
bookRepository.test("test");
}Then set the maximum memory to 20M: -Xmx20M.
Let's test the default cache based on ConcurrentHashMap and find that it will report OOM soon.
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "main" Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "RMI TCP Connection(idle)"
We use Caffeine and configure its maximum capacity:
spring:
cache:
caffeine:
spec: maximumSize=100Run the program again and find that it runs normally without error.
Therefore, if the cache based on the same JVM memory is used, Caffeine is recommended, and the default implementation based on ConcurrentHashMap is strongly not recommended.
What is the appropriate situation for Redis, which needs to call the cache of third-party processes? If your application is distributed and you want other servers to use this cache after one server queries it, Redis based cache is recommended.
There is also a disadvantage of using Spring Cache, which shields the characteristics of the underlying cache. For example, it is difficult to have different expiration times for different scenarios (but it is not impossible. It can also be achieved by configuring different cachemanagers). But on the whole, the advantages outweigh the disadvantages. We can measure it ourselves and suit ourselves.
summary
More important source classes
- CacheAutoConfiguration automatic configuration of cache
- For example, redis cacheconfiguration
- CacheManager cache manager
- For example, look at redis cachemanager
- CacheProperties cache default configuration
- The idea search method is double-click shift or ctrl n
Principle fast carding
Process Description: CacheAutoConfiguration => RedisCacheConfiguration => Automatically configured RedisCacheManager => Initialize all caches => Each cache determines what configuration to use=> =>If RredisCacheConfiguration Use the existing configuration if there is one, and use the default configuration if there is no one( CacheProperties) =>If you want to change the configuration of the cache, just put one in the container RredisCacheConfiguration that will do =>Will be applied to the current RedisCacheManager In all cache partitions managed