Hello, I'm a side dish.
A man who hopes to become a man who talks about architecture with cow X! If you want to be the person I want to be, or pay attention and be a partner, so that the dishes are no longer lonely!
This article mainly introduces Selenium
If necessary, refer to
If helpful, don't forget to like ❥
The official account of WeChat has been opened, and the dishes have been remembered.
Hello, everyone. This is the predecessor of Xiaocai Liangji, said the vegetable farmer. Don't get lost because your name is changed and your avatar is changed~
Recently, in order to expand the language, I learned about the playing methods of Python this week. After learning, I found that, alas, it's really fragrant. I don't know if you think the language is a little interesting when you first learn a language. You want to try everything.
When it comes to python, everyone's reaction may be crawlers and automated testing. It's rare to talk about using Python for web development. Relatively speaking, java is the most commonly used language for web development in China. However, it doesn't mean that Python is not suitable for web development. As far as I know, the commonly used web frameworks include Django and flash~
Django is a very heavy framework. It provides many convenient tools and packages many things. It doesn't need to make too many wheels by itself
The advantage of Flask is small, but its disadvantage is also small. Its flexibility means that it needs to build more wheels or spend more time on configuration
However, the focus of this article is not to introduce the web development of Python or the basic introduction of python, but to talk about the introduction of automated testing and crawler of Python~
In my opinion, if you have development experience in other languages, it's a small dish. It's recommended to start with a case and learn while watching. In fact, the syntax and the like are the same (we'll learn python in combination with java later). The code can basically read eight or nine times, but if you don't have any language development experience, The small dish is still recommended to study systematically from the beginning. Videos and books are good choices. Here we recommend Mr. Liao Xuefeng's blog. The content is very good Python tutorial
1, Automated testing
python can do many things, and can do many interesting things
To learn a language, of course, you have to find some interesting points to learn faster. For example, you want to climb the pictures or videos of so and so website, right~
What is automated testing? That is automation + testing. As long as you write a script (. py file) and run it, it will automatically help you run the process of testing in the background. Then, using automated testing, there is a good tool that can help you complete it, Selenium
Selenium is a web automated testing tool that can easily simulate the operation of real users on browsers. It supports various mainstream browsers, such as IE, Chrome, Firefox, Safari, Opera, etc. here, Python is used for demonstration. It does not mean that selenium only supports python. It has a client driver of multiple programming languages, Grammar introduction ~ let's do a simple example demonstration!
1) Pre preparation
In order to ensure the smooth demonstration, we need to make some pre preparations, otherwise the browser may not open normally~
Step 1
Check the browser version. We use Edge below. We can enter it in the URL input box edge://version View the browser version, and then go to the corresponding driver store to install the corresponding version of the driver Microsoft Edge - Webdriver (windows.net)
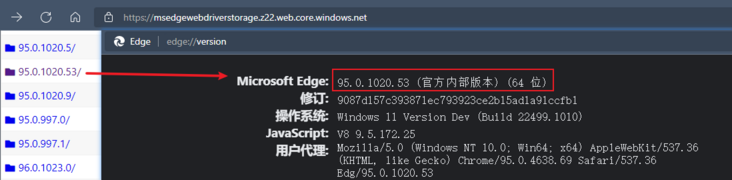
Step 2
Then we unzip the downloaded driver file to the Scripts folder under your python installation directory

2) Browser operation
To get ready, let's look at the following simple code:
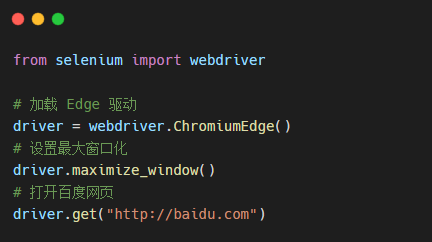
In addition, the guide package has only 4 lines of code in total, and python autoTest.py is input at the terminal, and the following demonstration effects are obtained:
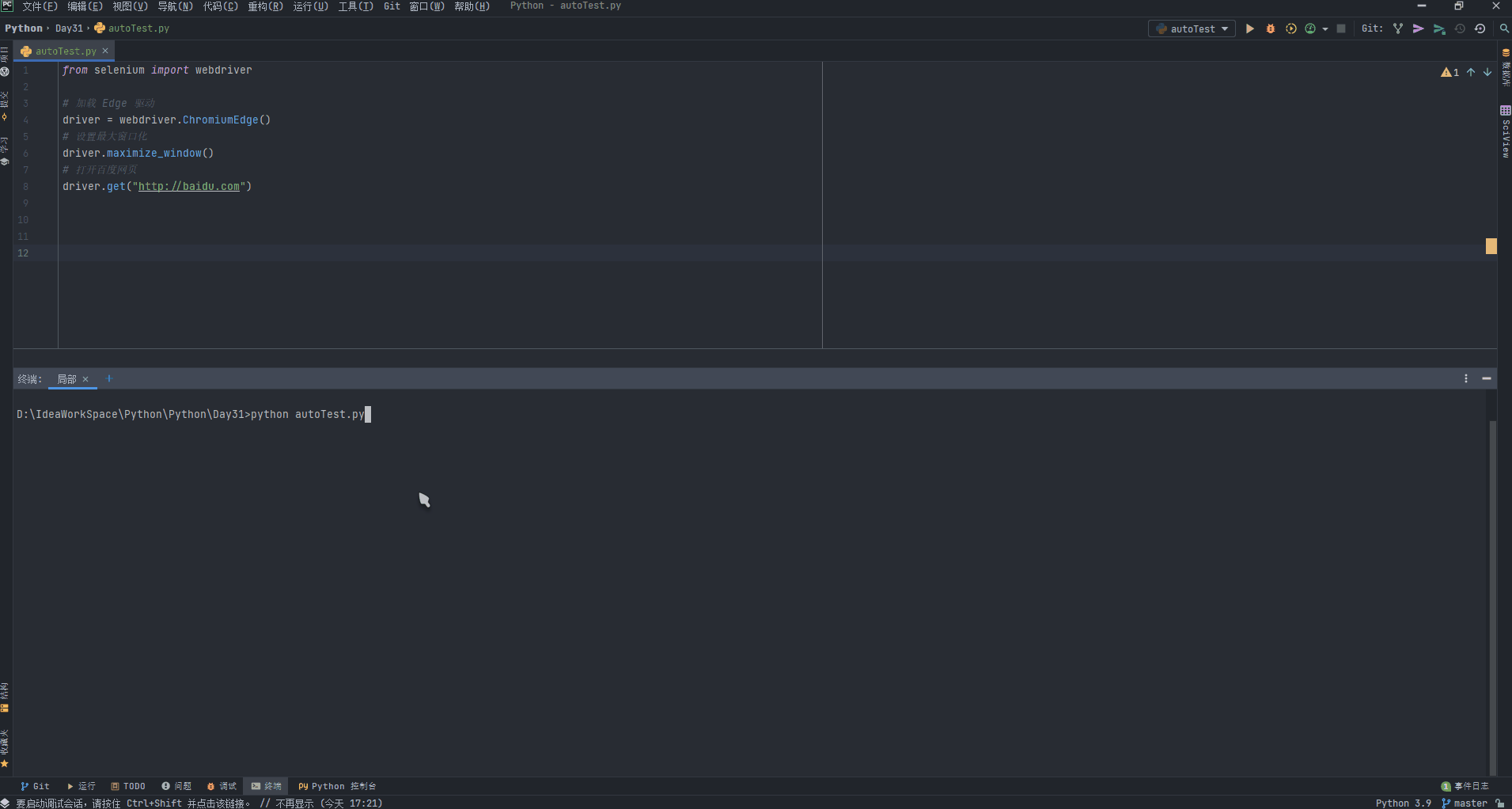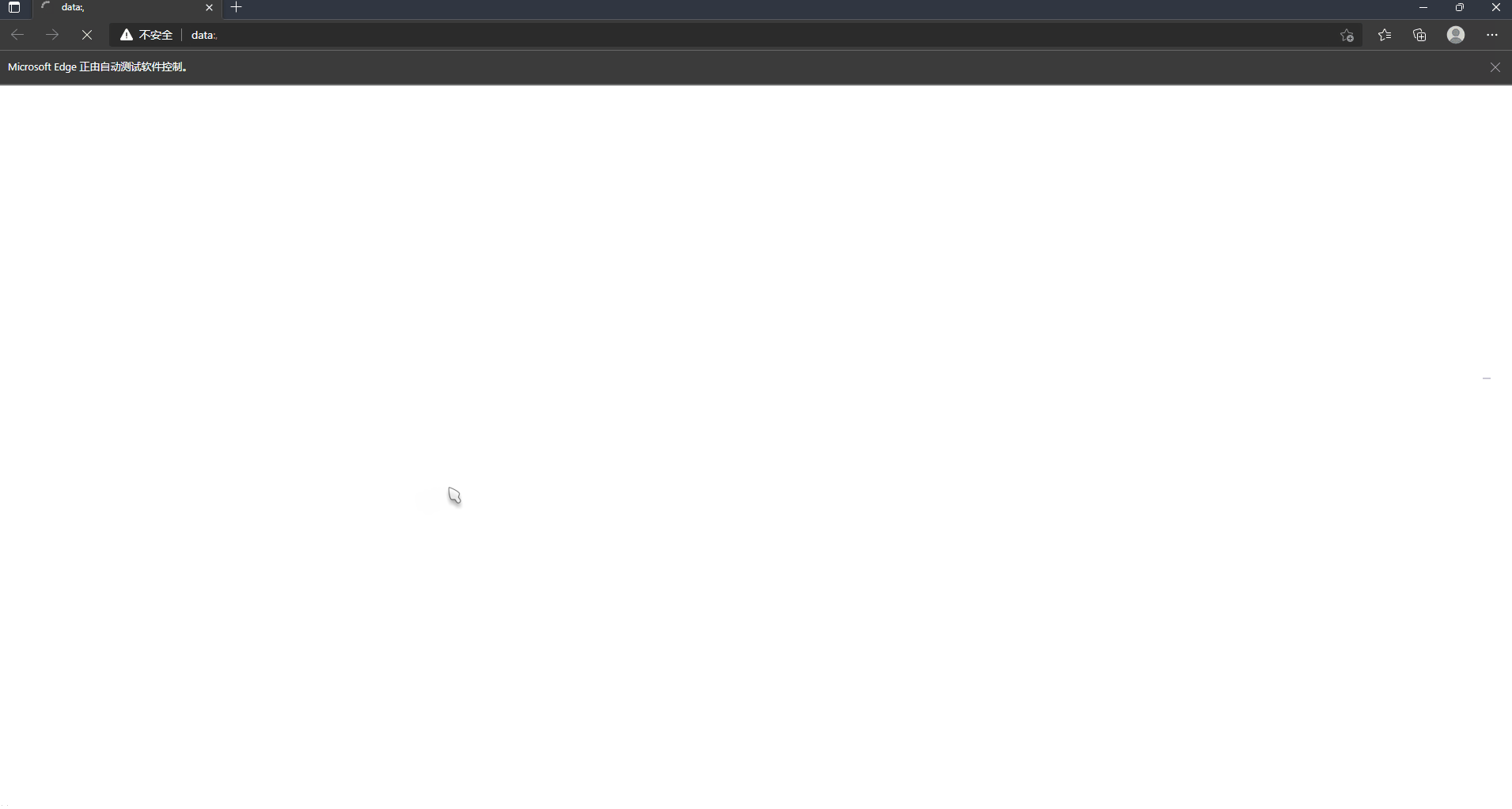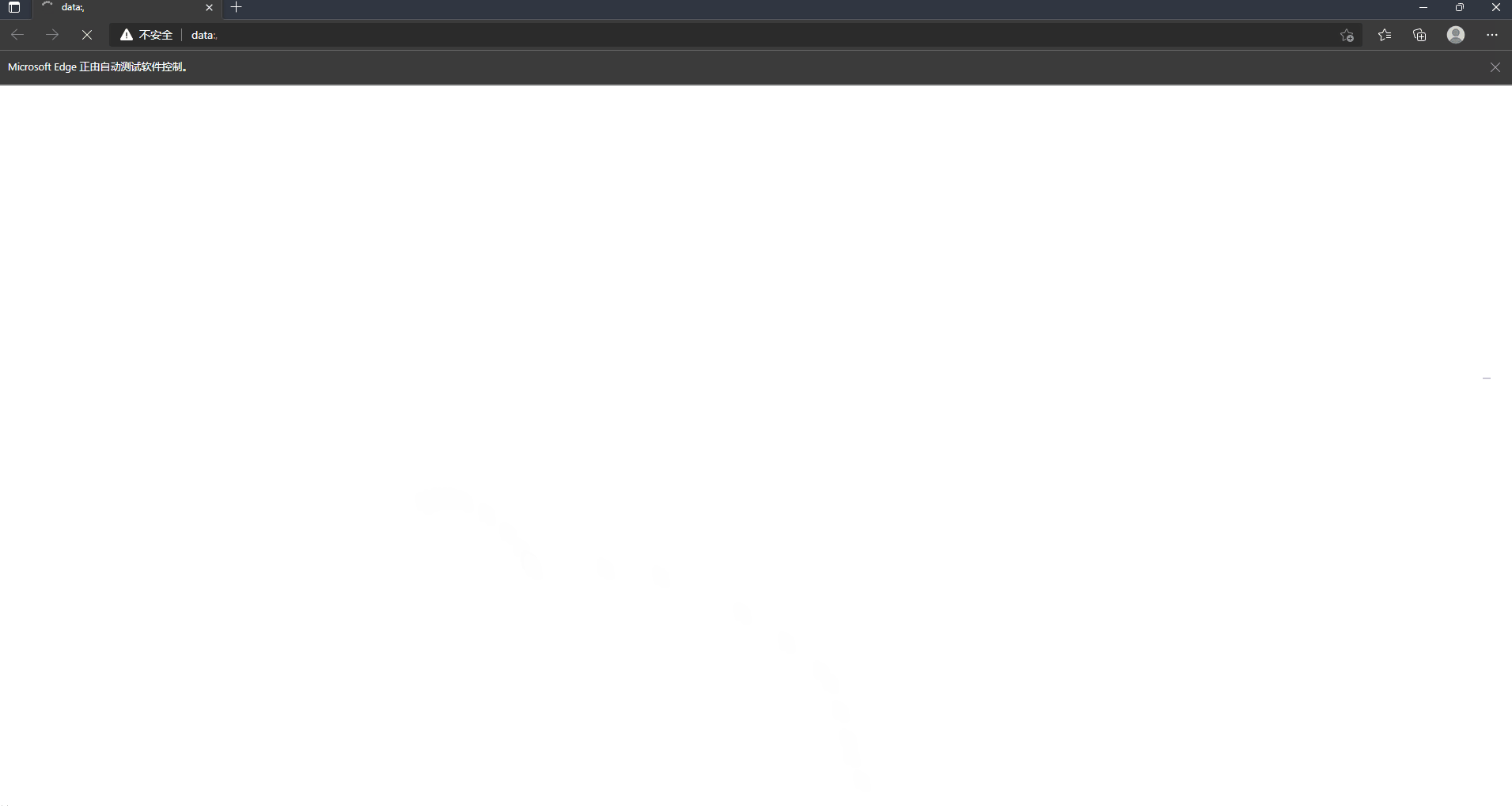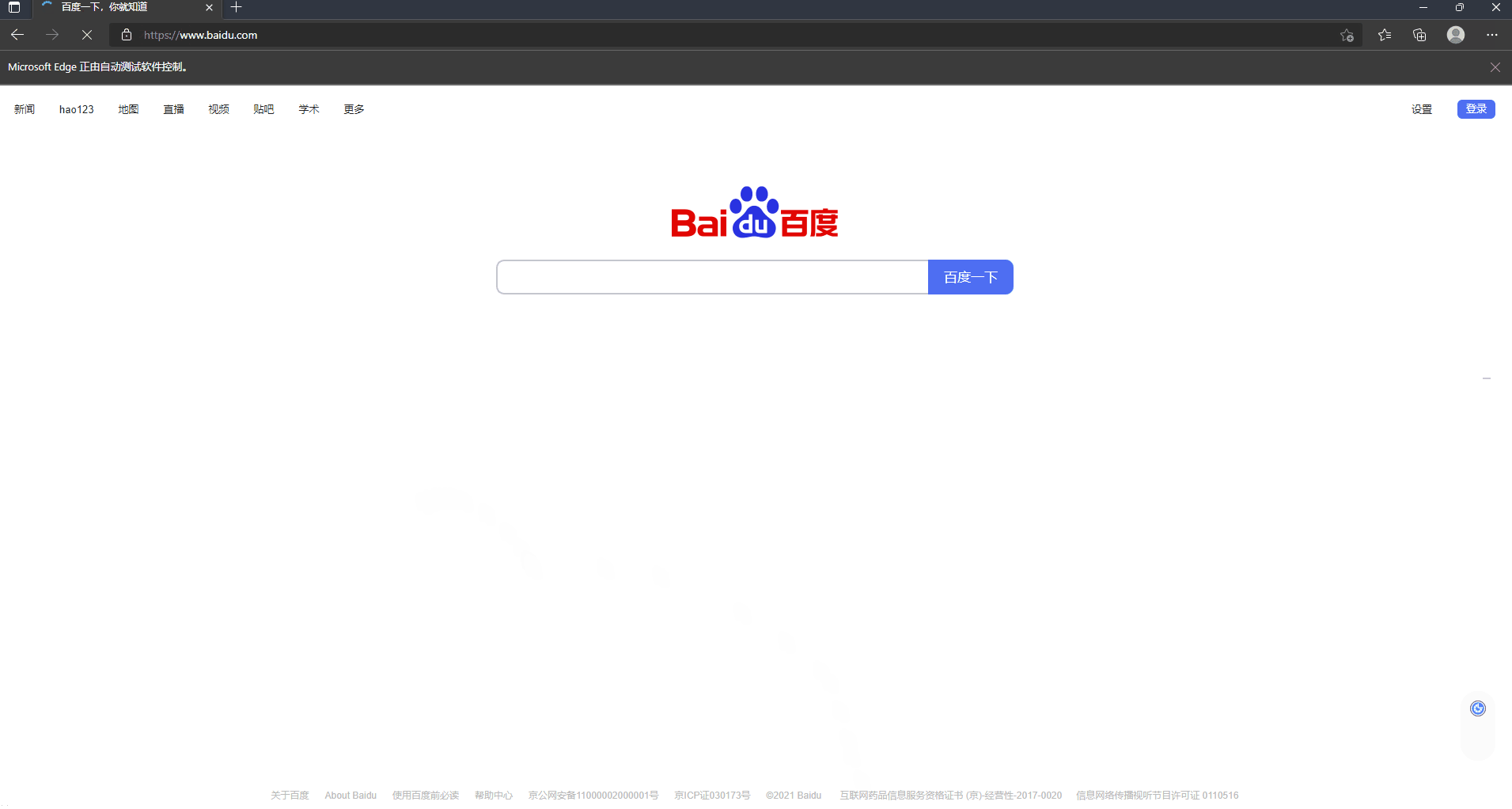
You can see that the script has realized three automatic operations: automatically opening the browser, automatically enlarging the window and automatically opening Baidu web page, which have brought our learning one step closer. Do you think it's a little interesting ~ let you gradually sink below!
Here are some common methods for browser operation:
| method | explain |
|---|---|
| webdriver.xxx() | Used to create browser objects |
| maximize_window() | window maximizing |
| get_window_size() | Get browser size |
| set_window_size() | Set browser size |
| get_window_position() | Get browser location |
| set_window_position(x, y) | Set browser location |
| close() | Close current tab / window |
| quit() | Close all tabs / windows |
Of course, these are the basic routine operations of Selenium, and the better ones are still ahead~
When we open the browser, of course, what we want to do is not just open the web page. After all, the programmer's ambition is unlimited! We also want to automatically operate page elements, so we need to talk about Selenium's positioning operation
3) Positioning element
The element positioning of the page is not new to the front end. Element positioning can be easily realized with JS, such as the following:
- Locate by id
document.getElementById("id")
- Locate by name
document.getElementByName("name")
- Positioning by tag name
document.getElementByTagName("tagName")
- Positioning through class
document.getElementByClassName("className")
- Positioning via css selector
document.querySeletorAll("css selector")
The above methods can realize the selection and positioning of elements. Of course, the protagonist of our section is Selenium. As the main automatic test tool, how can it be weak ~ there are 8 ways to realize the positioning of page elements, as follows:
- id location
driver.find_element_by_id("id")
When we open Baidu page, we can find that the id of the input box is kw,
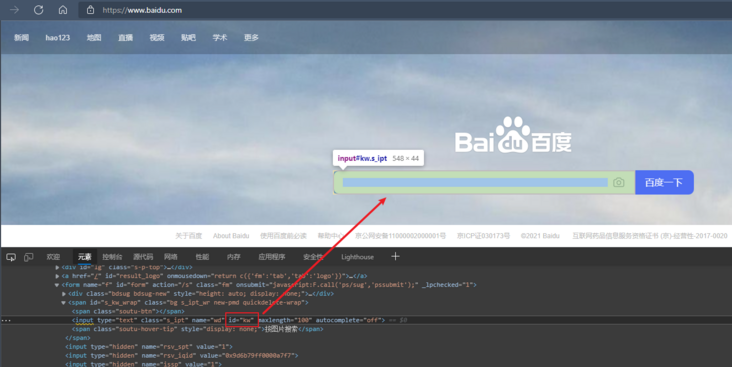
After knowing the element ID, we can use the ID to locate the element as follows
from selenium import webdriver
# Load Edge driver
driver = webdriver.ChromiumEdge()
# Set maximize window
driver.maximize_window()
# Open Baidu web page
driver.get("http://baidu.com")
# Locate element by id
i = driver.find_element_by_id("kw")
# Enter a value into the input box
i.send_keys("Vegetable farmer said")
- name attribute value positioning
driver.find_element_by_name("name")
Name positioning is similar to id. It is all necessary to find the value of name and then call the corresponding api.
from selenium import webdriver
# Load Edge driver
driver = webdriver.ChromiumEdge()
# Set maximize window
driver.maximize_window()
# Open Baidu web page
driver.get("http://baidu.com")
# Locate element by id
i = driver.find_element_by_name("wd")
# Enter a value into the input box
i.send_keys("Vegetable farmer said")- Class name positioning
driver.find_element_by_class_name("className")
The positioning method is the same as that of id and name. You need to find the corresponding className and then locate it~
- Tag name positioning
driver.find_element_by_tag_name("tagName")
This method is rarely used in our daily life, because in HTML, functions are defined by tags. For example, input is input and table is table... Each element is actually a tag. A tag is often used to define a class of functions. There may be multiple div, input, table, etc. in a page, so it is difficult to accurately locate elements by using tag~
- css selector
driver.find_element_by_css_selector("cssVale")
This approach requires five selectors connected to css
Five selectors
- element selector
The most common css selector is the element selector. In HTML documents, this selector usually refers to an HTML element, such as:
html {background-color: black;}
p {font-size: 30px; backgroud-color: gray;}
h2 {background-color: red;}- Class selector
. add the class name to form a class selector, for example:
.deadline { color: red;}
span.deadline { font-style: italic;}- id selector
ID selectors are somewhat similar to class selectors, but the difference is significant. First, an element cannot have multiple classes like a class attribute. An element can only have a unique ID attribute. Use the ID selector method to # add the ID value to the pound number, for example:
#top { ...}- attribute selectors
We can select elements according to their attributes and attribute values, for example:
a[href][title] { ...}- descendent selector
It is also called context selector. It uses the document DOM structure for css selection. For example:
body li { ...}
h1 span { ...}Of course, the selector here is just a brief introduction. For more information, please refer to the document by yourself~
After understanding the selector, we can happily locate the css selector:
from selenium import webdriver
# Load Edge driver
driver = webdriver.ChromiumEdge()
# Set maximize window
driver.maximize_window()
# Open Baidu web page
driver.get("http://baidu.com")
# Locate the element through the id selector
i = driver.find_elements_by_css_selector("#kw")
# Enter a value into the input box
i.send_keys("Vegetable farmer said")- Link text positioning
driver.find_element_by_link_text("linkText")
This method is specially used to locate text links. For example, we can see that there are link elements such as news, hao123, map... On Baidu's home page
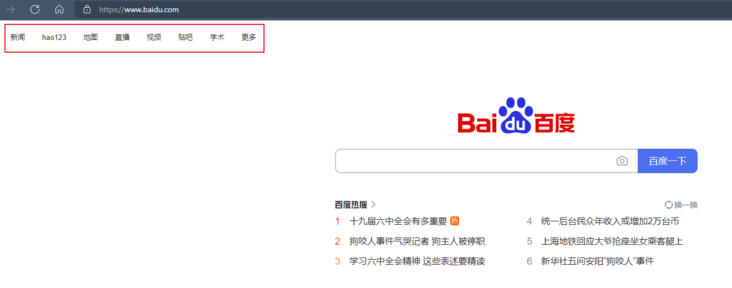
Then we can use the link text to locate
from selenium import webdriver
# Load Edge driver
driver = webdriver.ChromiumEdge()
# Set maximize window
driver.maximize_window()
# Open Baidu web page
driver.get("http://baidu.com")
# Locate the element through the link text and click
driver.find_element_by_link_text("hao123").click()
- Partial link text
driver.find_element_by_partial_link_text("partialLinkText")
This way is right_ Text, sometimes a hyperlink text is very long. If we input all the text, it will be troublesome and unsightly
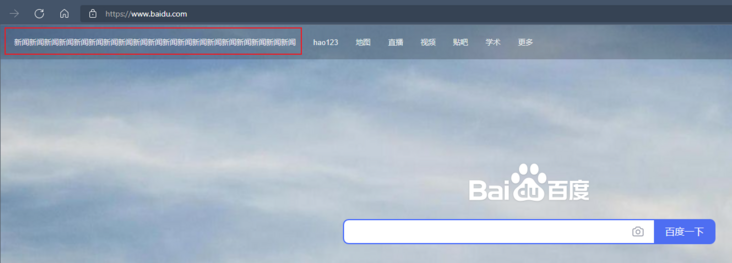
In fact, we only need to intercept some strings to let selenium understand what we want to select, so we use partial_ link_ TextThis way~

- xpath path expression
driver.find_element_by_xpath("xpathName")
The positioning methods described above are that in an ideal state, each element has a unique attribute of id or name or class or hyperlink text, so we can locate them through this unique attribute value. However, sometimes the element we want to locate does not have id,name,class attributes, or these attribute values of multiple elements are the same, or when the page is refreshed, these attribute values will change. At this time, we can only locate it through xpath or CSS. Of course, you don't need to calculate the value of xpath. We just need to open the page, find the corresponding element in F 12, and right-click to copy xpath
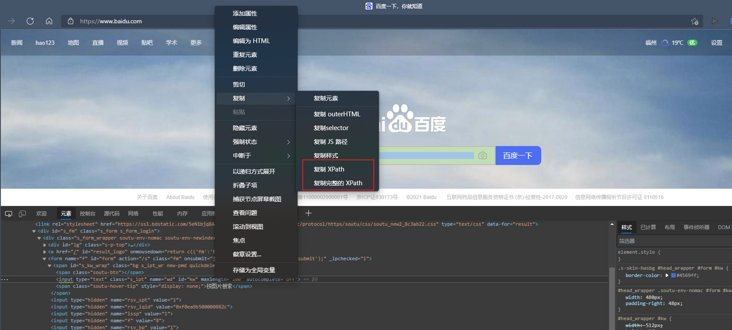
Then locate in the code:
from selenium import webdriver
# Load Edge driver
driver = webdriver.ChromiumEdge()
# Set maximize window
driver.maximize_window()
# Open Baidu web page
driver.get("http://www.baidu.com")
driver.find_element_by_xpath("//*[@ id ='kw '] ". Send_keys (" vegetable farmer's Day ")4) Element operation
Of course, what we want to do is not just the selection of elements, but the operation after selecting elements. In the above demonstration, we have actually carried out two operations: click() and send_keys("value"). Here we continue to introduce several other operations~
| Method name | explain |
|---|---|
| click() | Click element |
| send_keys("value") | Analog key input |
| clear() | Clear the contents of elements, such as input boxes |
| submit() | Submit Form |
| text | Gets the text content of the element |
| is_displayed | Determine whether the element is visible |
Is there a similar feeling after reading it? Isn't this the basic operation of js ~!
5) Practical exercise
After learning the above operations, we can simulate the shopping operation of a Xiaomi mall. The code is as follows:
from selenium import webdriver
item_url = "https://www.mi.com/buy/detail?product_id=10000330"
# Load Edge driver
driver = webdriver.ChromiumEdge()
# Set maximize window
driver.maximize_window()
# Open the product shopping page
driver.get(item_url)
# The implicit wait setting prevents the network from blocking and the page is not loaded in time
driver.implicitly_wait(30)
# Select address
driver.find_element_by_xpath("//*[@id='app']/div[3]/div/div/div/div[2]/div[2]/div[3]/div/div/div[1]/a").click()
driver.implicitly_wait(10)
# Click to manually select the address
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div["
"1]/div/div/div[2]/span[1]").click()
# Choose Fujian
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[13]").click()
driver.implicitly_wait(10)
# Select city
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[1]").click()
driver.implicitly_wait(10)
# Selection area
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[1]").click()
driver.implicitly_wait(10)
# Select Street
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div/div/div/div/div/div/div["
"1]/div[2]/span[1]").click()
driver.implicitly_wait(20)
# Click Add to cart
driver.find_element_by_class_name("sale-btn").click()
driver.implicitly_wait(20)
# Click to go shopping cart settlement
driver.find_element_by_xpath("//*[@id='app']/div[2]/div/div[1]/div[2]/a[2]").click()
driver.implicitly_wait(20)
# Click to settle
driver.find_element_by_xpath("//*[@id='app']/div[2]/div/div/div/div[1]/div[4]/span/a").click()
driver.implicitly_wait(20)
# Click agree agreement
driver.find_element_by_xpath("//*[@id='stat_e3c9df7196008778']/div[2]/div[2]/div/div/div/div[3]/button[1]").click()The effects are as follows:
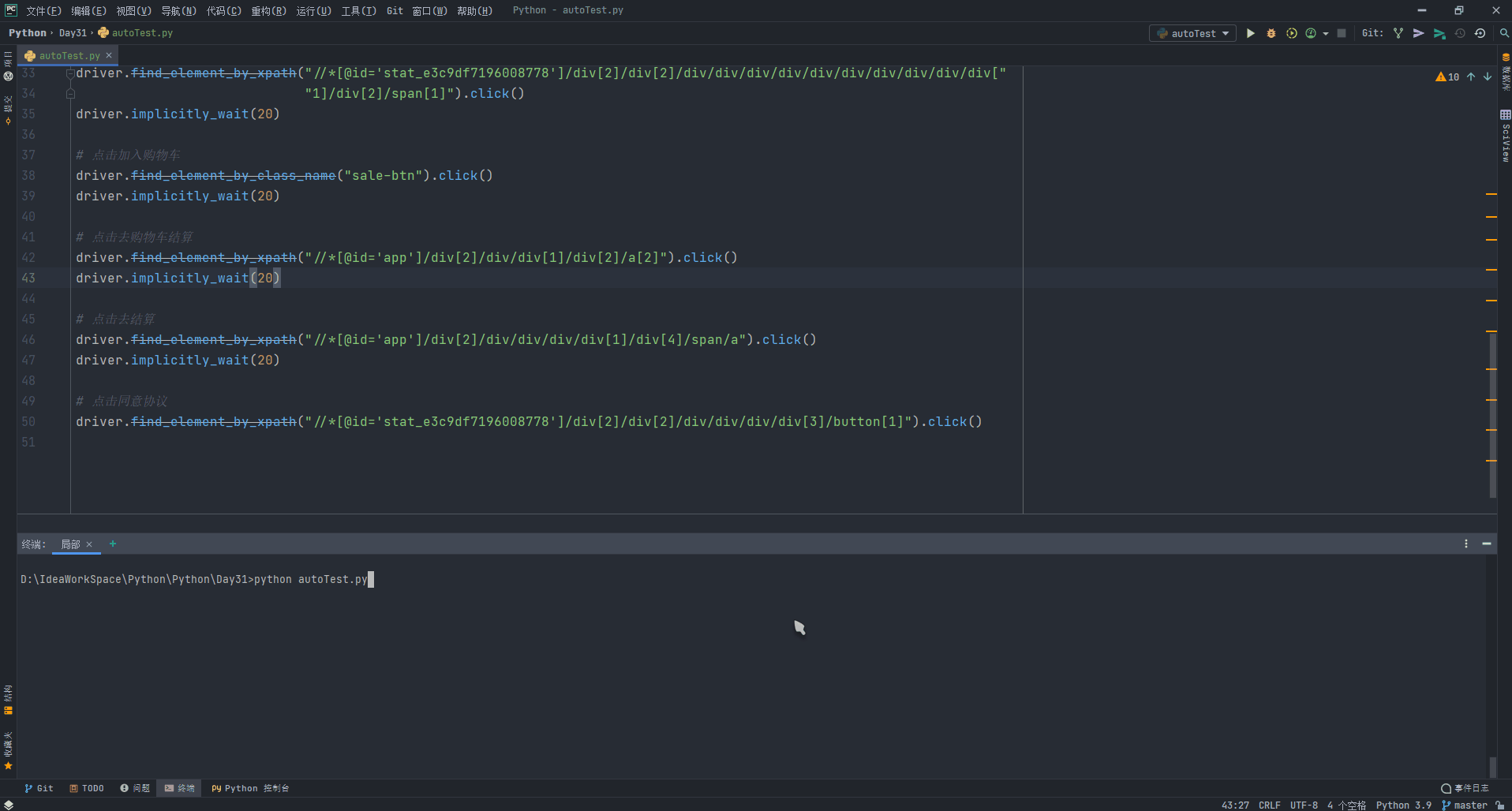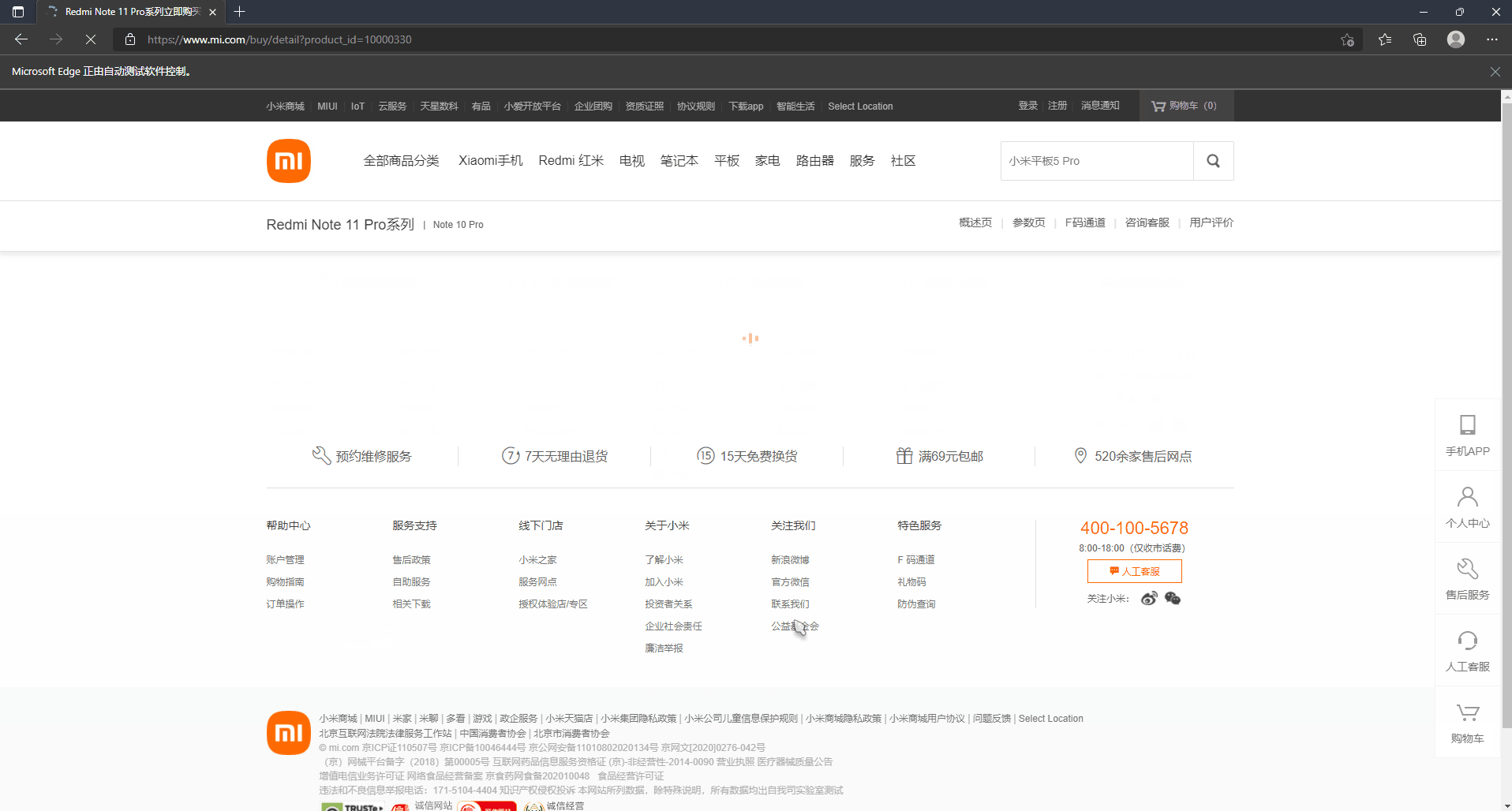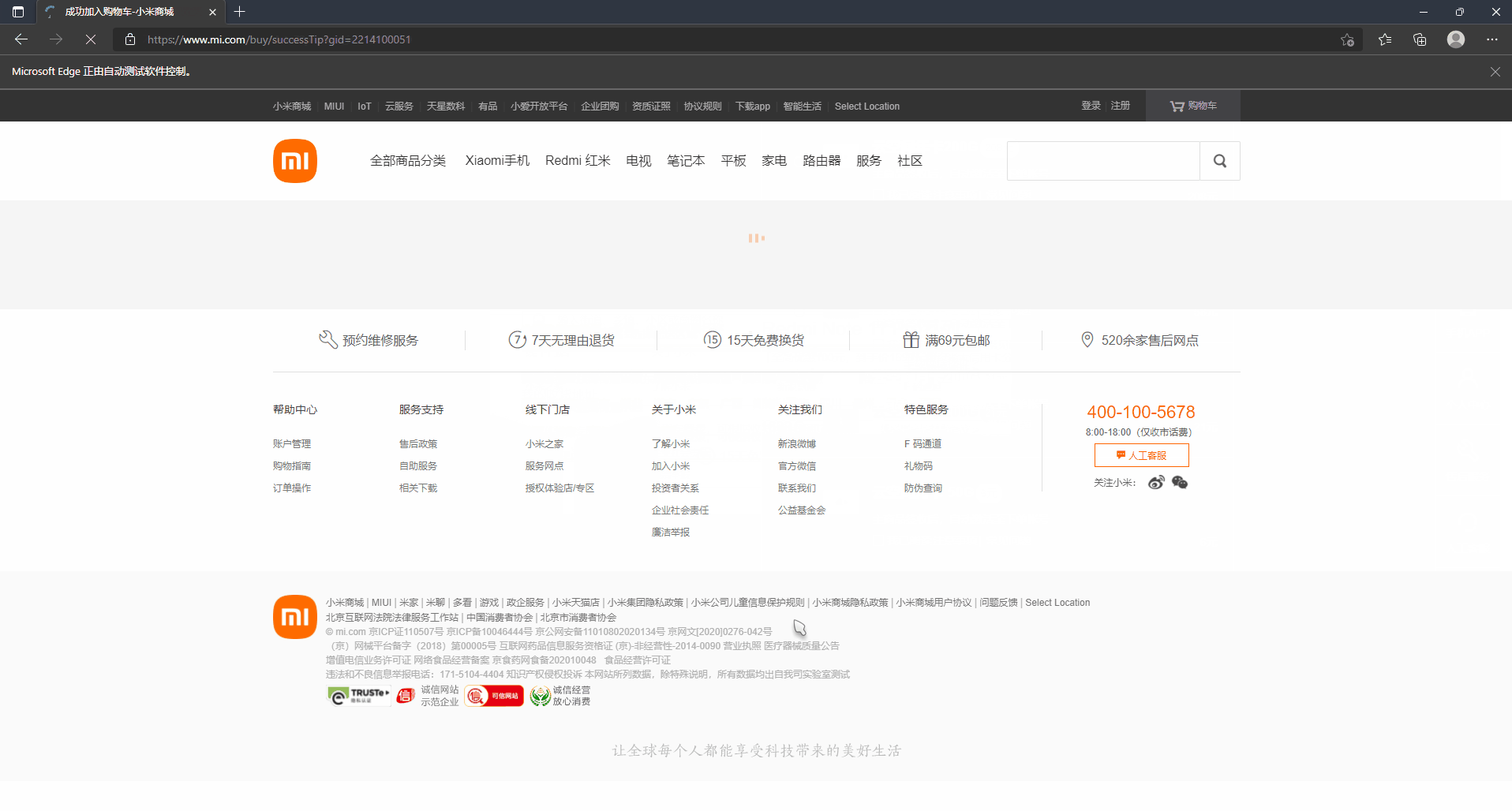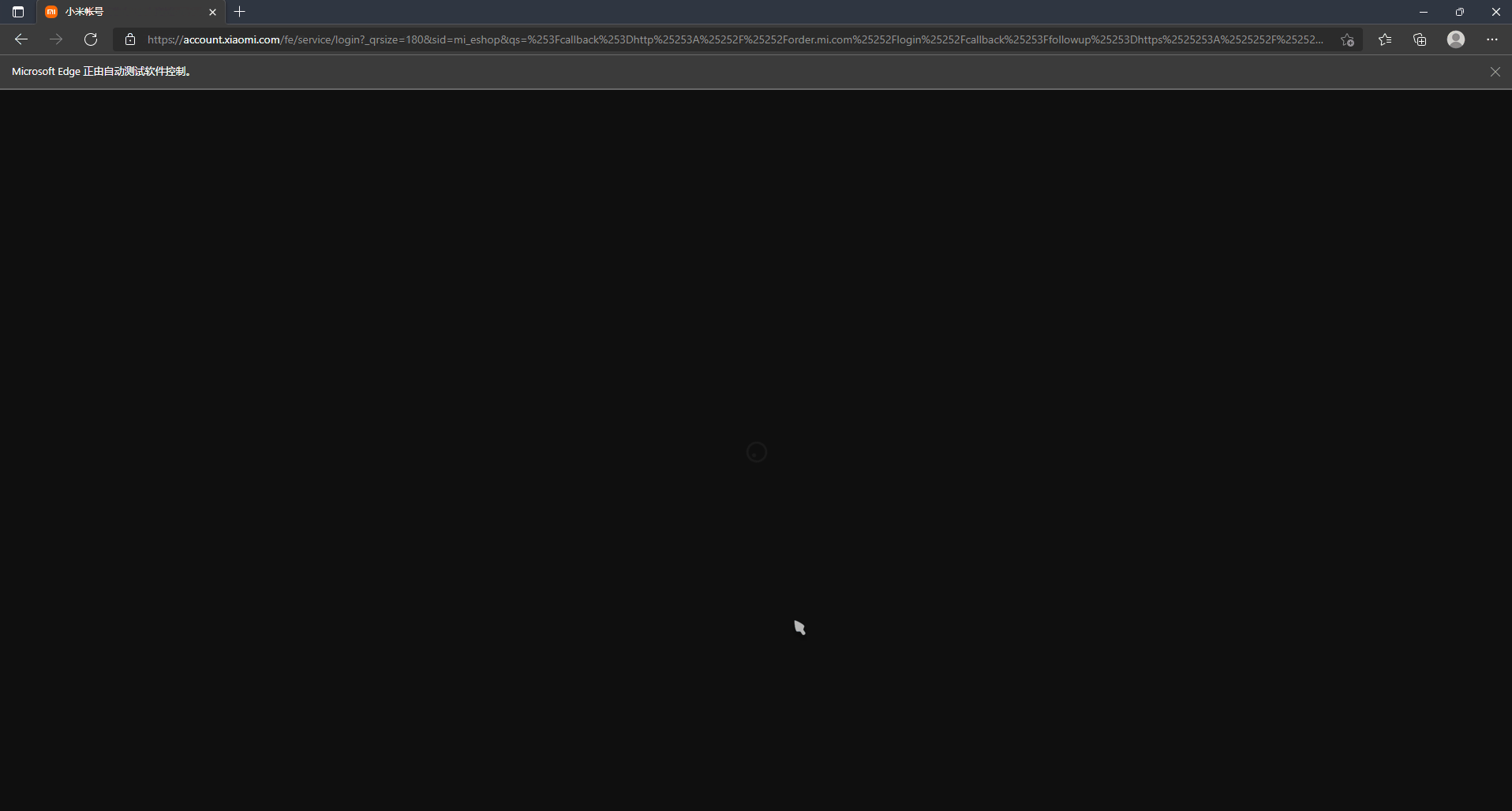
This is the practice of our learning results. Of course, if we encounter a second kill, we can also write a script to practice ~. If there is no goods, we can add a while loop to poll and visit!
2, Reptile test
Above, we have realized how to use Selenium to realize automatic testing, and the use must be legal ~ next, we will show another powerful function of python, that is, for crawlers
Before learning about reptiles, we need to understand several necessary tools
1) Page Downloader
python standard library has provided urllib, urllib, httplib and other modules for http requests, but the api is not easy to use and elegant ~. It requires a lot of work and coverage of various methods to complete the simplest tasks. Of course, this is unbearable for programmers. Heroes from all sides develop all kinds of easy-to-use third-party libraries for use~
- request
request is a python based http library using Apache S2 license. It is highly encapsulated on the basis of python built-in modules, so that users can more easily complete all the operations available to the browser when making network requests~
- scrapy
The difference between request and sweep may be that sweep is a relatively heavyweight framework. It belongs to website level crawler, while request is a page level crawler. The concurrency and performance are not as good as sweep
2) Page parser
- BeautifulSoup
BeautifulSoup is a module used to receive an HTML or XML string, format it, and then use the method provided by it to quickly find the specified element, making it easy to find the specified element in HTML or XML.
- scrapy.Selector
Selector is based on parsel, a relatively advanced encapsulation, which selects a part of an HTML file through a specific XPath or CSS expression. It is built on the lxml library, which means that they are very similar in speed and parsing accuracy.
For details, please refer to Scripy document , the presentation was quite detailed
3) Data storage
When we climb down the content, we need a corresponding storage source to store it
Specific database operations will be introduced in subsequent web development blog posts~
- txt text
Common operations using file
- sqlite3
SQLite, a lightweight database, is an ACID compliant relational database management system, which is contained in a relatively small C library
- mysql
Without too much introduction, I understand everything. I'm an old lover of web development
4) Practical exercise
Web crawler is actually called network data collection, which is easier to understand. It requests data from the network server (HTML form) through programming, then parses HTML and extracts the data you want.
We can simply divide it into four steps:
- Get html data according to the given url
- Parse html to obtain target data
- Store data
Of course, all this needs to be based on your understanding of the simple syntax of python and the basic operation of html~
Next, we use the combination of request + beautiful Soup + text for operation practice. Suppose we want to climb the python tutorial content of teacher Liao Xuefeng~
# Import requests Library
import requests
# Import file operation Library
import codecs
import os
from bs4 import BeautifulSoup
import sys
import json
import numpy as np
import importlib
importlib.reload(sys)
# Assign a request header to the request to simulate the chrome browser
global headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'}
server = 'https://www.liaoxuefeng.com/'
# Liao Xuefeng python tutorial address
book = 'https://www.liaoxuefeng.com/wiki/1016959663602400'
# Define storage location
global save_path
save_path = 'D:/books/python'
if os.path.exists(save_path) is False:
os.makedirs(save_path)
# Get chapter content
def get_contents(chapter):
req = requests.get(url=chapter, headers=headers)
html = req.content
html_doc = str(html, 'utf8')
bf = BeautifulSoup(html_doc, 'html.parser')
texts = bf.find_all(class_="x-wiki-content")
# Get the content of div tag id attribute content \ xa0 is an uninterrupted white space & nbsp;
content = texts[0].text.replace('\xa0' * 4, '\n')
return content
# write file
def write_txt(chapter, content, code):
with codecs.open(chapter, 'a', encoding=code)as f:
f.write(content)
# Main method
def main():
res = requests.get(book, headers=headers)
html = res.content
html_doc = str(html, 'utf8')
# HTML parser
soup = BeautifulSoup(html_doc, 'html.parser')
# Get all chapters
a = soup.find('div', id='1016959663602400').find_all('a')
print('Total number of articles: %d ' % len(a))
for each in a:
try:
chapter = server + each.get('href')
content = get_contents(chapter)
chapter = save_path + "/" + each.string.replace("?", "") + ".txt"
write_txt(chapter, content, 'utf8')
except Exception as e:
print(e)
if __name__ == '__main__':
main()After we run the program, we can see the tutorial content we crawled in the D:/books/python location!
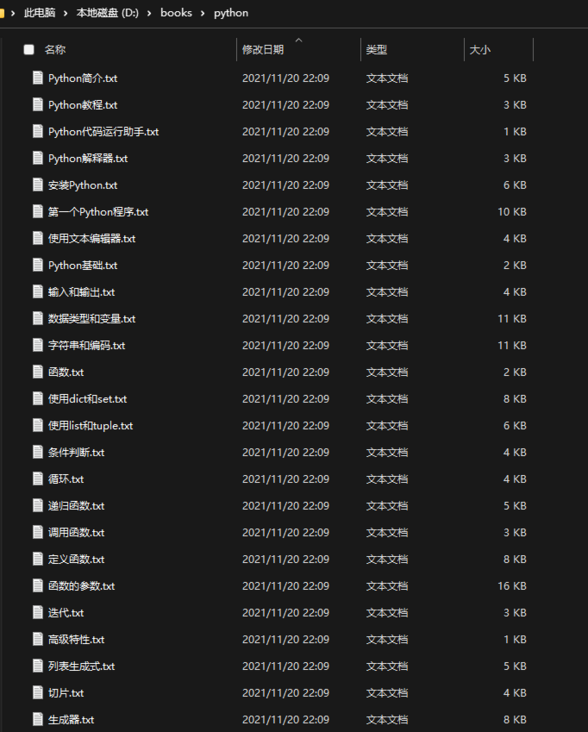
In this way, we have simply realized the crawler, but the crawler needs to be careful ~!
In this two-dimensional automated test and crawler, we have learned about the use of python, hoping to stimulate your interest~
Don't talk, don't be lazy, and make a program ape with niux as the architecture together with the dishes ~ pay attention and be a partner, so that the dishes are no longer lonely. See you later!
If you work harder today, you can say less begging words tomorrow!
I am a small dish, a man who grows stronger with you. 💋
The official account of WeChat has been opened, and the dishes have been remembered.