But anyway, crawler technology is innocent, and it is still worth our developers to learn about it. Before learning, we still need to understand the relevant concepts.
What is a reptile
Web crawler: also known as web spider, web robot, is a program or script that automatically grabs World Wide Web information according to certain rules. Therefore, it is necessary for students who want to learn to listen to the teacher's class and receive python fulio. Students who want to learn can go to Wai Xin of Mengya teacher (homonym): 762 in the front row, 459 in the middle row and 510 in the back row. Just combine the above three groups of letters in order, and she will arrange learning.
In the era of big data, to conduct data analysis, we must first have a data source, but where the data source comes from, spend money to buy it, have no budget, and can only be retrieved from other websites.
Subdivided, the industry is divided into two categories: reptiles and anti reptiles.
Anti crawler: as the name suggests, it is to prevent you from being a crawler on my website or APP.
Crawler engineers and anti crawler engineers are a pair of little partners who love each other and often lose their jobs because each other has to work overtime to write code. For example, the following picture, let's feel it carefully:
Basic principles of reptiles
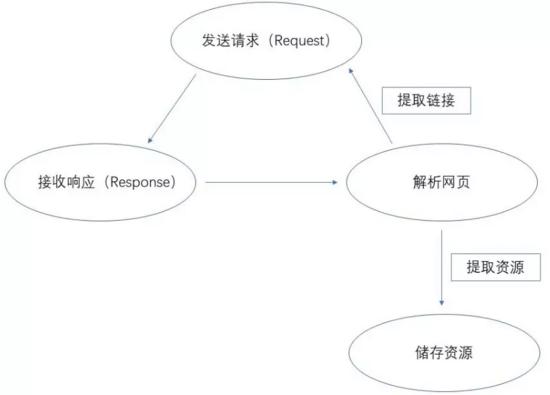
As shown in the figure above, the first step of the crawler is to request the web page to be crawled to obtain the corresponding returned results, then use some methods to parse the response content, extract the desired content resources, and finally save the extracted resources.
It's actually easy to get started with Python, but we have to keep learning. It's difficult to keep learning every day. I believe many people give up after learning for a week. Why? In fact, there are no good learning materials for you to learn. It is difficult for you to adhere to. This is the python introductory learning materials collected by Xiaobian. Pay attention to, forward, and send private letters to Xiaobian "01" for free! I hope it will help you. Therefore, it is necessary for students who want to learn to listen to the teacher's class and receive Python fulio. Students who want to learn can go to miss Mengya's Wai Xin (homonym): 762 in the front row, 459 in the middle row and 510 in the back row. Just combine the above three groups of letters in order and she will arrange learning.
Crawler tools and language selection
1, Crawler tool
I believe everyone knows that if you want to do a good job, you must first use your tools. Some commonly used tools are essential to improve efficiency. Here are some tools I personally recommend: Chrome, Charles, Postman and XPath helper
2, Reptile language
Current mainstream Java and node JS, C#, python and other development languages can implement crawlers.
Therefore, in terms of language selection, you can choose the best language to write crawler scripts.
At present, python is the most used crawler, because python syntax is concise and easy to modify. Moreover, there are many crawler related libraries in python, which can be used after taking them, and there are many online materials.
Use of Python crawler Selenium Library
1, Basic knowledge
First, to use Python as a crawler, you need to learn the basic knowledge of python, as well as HTML, CSS, JS, Ajax and other related knowledge. Here, some crawler related libraries and frameworks in Python are listed:
1.1,urllib and urllib21. 2,Requests1. 3,Beautiful Soup1. 4,Xpath Grammar and lxml Library 1. 5,PhantomJS1. 6,Selenium1. 7,PyQuery1. 8,Scrapy......
Because of the limited time, this article only introduces the crawler technology of Selenium library, such as automated testing, and other library and framework materials. Interested partners can learn by themselves. Therefore, it is necessary for students who want to learn to listen to the teacher's class and receive python fulio. Students who want to learn can go to Wai Xin of Mengya teacher (homonym): 762 in the front row, 459 in the middle row and 510 in the back row. Just combine the above three groups of letters in order, and she will arrange learning.
2, Selenium Foundation
2.1 Selenium is an automated testing tool for testing websites. It supports various browsers, including Chrome, Firefox, Safari and other mainstream interface browsers. It also supports phantomJS no interface browser.
2.2 installation method
pip install Selenium Copy code
2.3. Eight methods of Selenium positioning elements
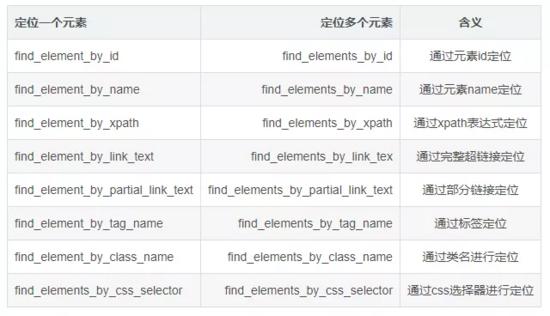
Crawler instance demo
The demand of this case is to capture the top 250 film information of Douban film.
url: https://movie.douban.com/top250 copy code
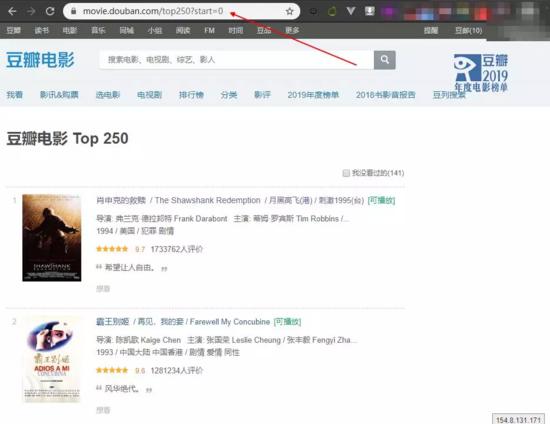
The development tool adopts PyCharm and the database adopts sqlServer2012.
Database table script:
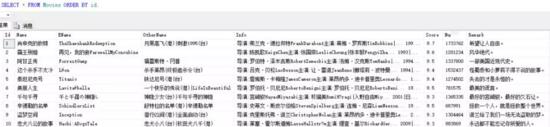
CREATE TABLE Movies( Id INT PRIMARY KEY IDENTITY(1,1), Name NVARCHAR(20) NOT NULL DEFAULT '', EName NVARCHAR(50) NOT NULL DEFAULT '', OtherName NVARCHAR(50) NOT NULL DEFAULT '', Info NVARCHAR(600) NOT NULL DEFAULT '', Score NVARCHAR(5) NOT NULL DEFAULT '0', Number NVARCHAR(20) NOT NULL DEFAULT '0', Remark NVARCHAR(200) NOT NULL DEFAULT '', createUser INT NOT NULL DEFAULT 0, createTime DATETIME DEFAULT GETDATE(), updateUser INT NOT NULL DEFAULT 0, updateTime DATETIME DEFAULT GETDATE());
The first step of the crawler is to analyze the url. After analysis, the url of the top 250 page of Douban movie has certain rules:
Each page displays 25 pieces of movie information. The url rules are as follows, and so on.
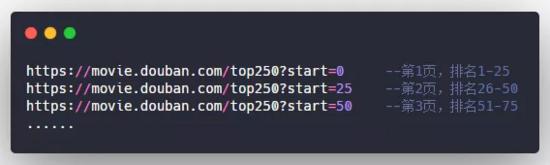
Then, analyze the web page source code:
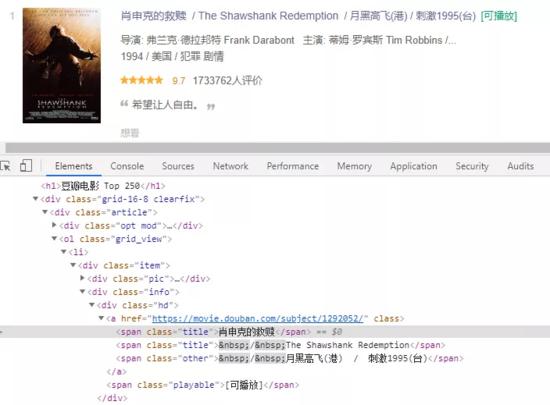
Finally, write the crawler script:
import importlibimport randomimport sysimport timeimport pymssqlfrom selenium import webdriverfrom selenium.webdriver.
common.by import By
# Anti crawler settings -- forged IP and requests
ip = ['111.155.116.210', '115.223.217.216', '121.232.146.39', '221.229.18.230', '115.223.220.59', '115.223.244.146', '180.118.135.26', '121.232.199.197', '121.232.145.101', '121.31.139.221', '115.223.224.114']
headers =
{
"User-Agent": "Mozilla/5.0
(Windows NT 10.0; WOW64) AppleWebKit/537.36
(KHTML, like Gecko)
Chrome/63.0.3239.84 Safari/537.36",
'X-Requested-With': 'XMLHttpRequest',
'X-Forwarded-For': ip[random.randint(0, 10)],
'Host': ip[random.randint(0, 10)]
}
importlib.reload(sys)try:
conn = pymssql.connect
(host="127.0.0.1", user="sa",
password="123",
database="MySchool",charset="utf8")except pymssql.OperationalError as msg:
print
("error: Could not Connection SQL Server!please check your dblink configure!")
sys.exit()else:
cur = conn.cursor()def main():
for n in range(0, 10):
count = n*25
url = 'https://movie.douban.com/top250?start='+str(count)
j = 1
# if(n == 7):
# j = 5
for i in range(j, 26):
driver = webdriver.PhantomJS(desired_capabilities=headers)
# Encapsulate browser information
driver.set_page_load_timeout(15)
driver.get(url) # Load web page
# data = driver.page_source # Get web page text
# driver.save_screenshot('1.png') # Screenshot saving
name = driver.find_elements(By.XPATH, "//ol/li["+str(i)+"]/div/div/div/a/span")[0].text.replace('\'', '')
ename = driver.find_elements(By.XPATH, "//ol/li["+str(i)+"]/div/div/div/a/span")
[1].text.replace("/", "").replace(" ", "").replace('\'', '')
try:
otherName = driver.find_elements(By.XPATH, "//ol/li["+str(i)+"]/div/div/div/a/span")[2].text.lstrip(' / ').replace("/", "|").replace(" ", "").replace('\'', '')
except:
otherName = ''
info = driver.find_elements(By.XPATH, "//ol/li["+str(i)+"]/div/div/div/p")[0].text.replace("/", "|").replace(" ", "").replace('\'', '')
score = driver.find_elements(By.XPATH, "//ol/li["+str(i)+"]/div/div/div/div/span[2]")[0].text.replace('\'', '')
number = driver.find_elements(By.XPATH, "//ol/li["+str(i)+"]/div/div/div/div/span[4]")
[0].text.replace("Human evaluation", "").replace('\'', '')
remark = driver.find_elements(By.XPATH, "//ol/li["+str(i)+"]/div/div/div/p/span")[0].text.replace('\'', '')
sql = "insert into Movies(Name,EName,OtherName,Info,Score,Number,Remark) values('"+name + \
"','"+ename+"','"+otherName+"','"+info + \ "','"+score+"','"+number+"','"+remark+"') "
try:
cur.execute(sql)
conn.commit()
print("The first"+str(n)+"Page, page"+str(i)+"Movie information added successfully")
time.sleep(30)
except: conn.rollback()
print("Failed to add:"+sql)
driver.quit()if __name__ == '__main__': main()
Achievement display: