The source code of the question comes from: Data analysis - the most complete SQL interview questions in the whole network (after the interview, the interview is no longer empty) - it is divided into well-known Internet manufacturers and different industry backgrounds (such as e-commerce and games) I often test the three parts of the knowledge points (real SQL questions) _bilibili biliwelcome everyone to exchange and study together. The courseware materials will be continuously updated in the data frog SQL interview question exchange group ~ group add ing method - add V: lkx941013, remarks: SQL video will be continuously updated https://www.bilibili.com/video/BV1Rh411B7sN?p=15&share_source=copy_web [724 supplement] after a long time, I'll reorganize and review again| ᴥ• ́ ) ✧
https://www.bilibili.com/video/BV1Rh411B7sN?p=15&share_source=copy_web [724 supplement] after a long time, I'll reorganize and review again| ᴥ• ́ ) ✧
catalogue
1, Retention rate (data to be supplemented)
2, Calculate the median, mean and mode
3, Request stores with sales records for three consecutive days in the sales_record table
5, The cumulative problem is to calculate the annual cumulative value and the total cumulative value
1, Retention rate (data to be supplemented)
To study the activity of app, it is necessary to make statistics on the retention of uid of active users on a certain day in the following week (calculate secondary retention, three retention and seven retention)
Index definition:
Number of active users in a day: number of active users to reuse in a day
Number of users retained in n days: the number of active users on the n-th day after an active user on a certain day
N-day active retention rate: number of users retained on n-day / number of active users on a certain day
Data table name: act_user_info
| Field name | Field type | remarks |
|---|---|---|
| uid | STRING | User unique ID |
| app_name | STRING | apply name |
| duration | BIGINT | Enable duration, summary by day |
| times | BIGINT | Activation times, summary by day |
| dayno | STRING | Table partition fields, such as 2018-05-01 |
The results obtained are shown in the table below
| date | Number of active users | Retained amount of the next day | Three day retention | Seven day retention | Next day retention rate | Three day retention rate | Seven day retention rate |
|---|---|---|---|---|---|---|---|
| 20180501 | 4 | 2 | 1 | 0 | 50% | 25% | 0% |
requirement:
1. The number of active users is an integer
2. The retention rate is expressed as a percentage and the results are kept to two decimal places
3. Only one sql or hive sql is completed
4. Just write the code to implement the query
Reference answer:
-- a.Calculate the number of active users in a day and remove the duplicate SELECT dayno,COUNT(DISTINCT uid)AS Number of active users FROM act_user_info WHERE app_name='camera' GROUP BY dayno; -- b.Find the number of users to be retained in the next day, first join Two sub tables, comparing the current day and the second day n Daily user information SELECT* FROM(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day1 FROM act_user_info WHERE app_name='camera')a INNER JOIN(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day2 FROM act_user_info WHERE app_name='camera')b ON a.uid=b.uid -- Make logical judgment and screen out users who are active on the first day and active on the second day SELECT a.day1,CASE WHEN day2-day1=1 THEN a.uid END AS uid FROM(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day1 FROM act_user_info WHERE app_name='camera')a INNER JOIN(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day2 FROM act_user_info WHERE app_name='camera')b ON a.uid=b.uid; -- Statistics of de duplication users by date grouping id,Calculate the number of users retained in the next day SELECT a.day1,COUNT(DISTINCT CASE WHEN day2-day1=1 THEN a.uid END)Number of users retained in the next day FROM(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day1 FROM act_user_info WHERE app_name='camera')a INNER JOIN(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day2 FROM act_user_info WHERE app_name='camera')b ON a.uid=b.uid GROUP BY a.day1; -- The three-day and seven day algorithms are the same logic -- c.n Daily active retention rate=n Number of users retained per day/Number of active users in a day -- available concat Splice value and percentage symbol SELECT day1 date,COUNT(DISTINCT a.uid)Number of active users, COUNT(DISTINCT CASE WHEN day2-day1=1 THEN a.uid END)Number of users retained in the next day, COUNT(DISTINCT CASE WHEN day2-day1=2 THEN a.uid END)Number of users retained in three days, COUNT(DISTINCT CASE WHEN day2-day1=6 THEN a.uid END)Number of users retained in seven days, CONCAT(COUNT(DISTINCT CASE WHEN day2-day1=1 THEN a.uid END)/COUNT(DISTINCT a.uid)*100,'%')Next day retention rate, CONCAT(COUNT(DISTINCT CASE WHEN day2-day1=2 THEN a.uid END)/COUNT(DISTINCT a.uid)*100,'%')Three day retention rate, CONCAT(COUNT(DISTINCT CASE WHEN day2-day1=6 THEN a.uid END)/COUNT(DISTINCT a.uid)*100,'%')Seven day retention rate FROM(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day1 FROM act_user_info WHERE app_name='camera')a INNER JOIN(SELECT uid,DATE_FORMAT(dayno,'%Y%m%d')AS day2 FROM act_user_info WHERE app_name='camera')b ON a.uid=b.uid GROUP BY a.day1;
2, Calculate the median, mean and mode
(odd and even numbers shall be considered in calculating the median)
CREATE TABLE emp_salary(emp_name VARCHAR(20),emp_salary VARCHAR(20),from_date DATE, to_date DATE); INSERT INTO emp_salary VALUES (1001,15000,'2020-03-01','2020-03-31'), (1002,12000,'2020-03-01','2020-03-31'), (1003,14000,'2020-03-01','2020-03-31'), (1004,15000,'2020-03-01','2020-03-31');
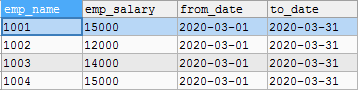
1. Ask for the mode of employee salary
SELECT emp_salary,COUNT(*)AS cnt FROM emp_salary GROUP BY emp_salary HAVING COUNT(*)>=ALL(SELECT COUNT(*) FROM emp_salary GROUP BY emp_salary);
Here, the ALL() function is added: ALL is compared with each one (greater than the maximum or less than the minimum); ANY is greater than ANY one (greater than the minimum and less than the maximum).
2. Calculate the average salary of employees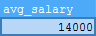
SELECT SUM(emp_salary)/COUNT(*) AS avg_salary FROM emp_salary;
3. Seek the median salary of employees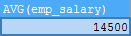
-- Arrange the numbers from small to large. If the total number is odd, take the value in the middle. If the total number is even, take the average of the two numbers in the middle SELECT AVG(emp_salary) FROM(SELECT emp_salary,ROW_NUMBER() OVER(ORDER BY emp_salary)AS rn,COUNT(*) OVER()AS n FROM emp_salary)t WHERE rn IN(FLOOR(n/2)+1,IF(MOD(n,2)=0,FLOOR(n/2),FLOOR(n/2)+1))
Here, COUNT(*)OVER() calculates the total count, and FLOOR() supplements:
round() converts the original value to the specified number of decimal places according to rounding. round(1.45,0) = 1;round(1.55,0)=2
floor() is rounded down to the specified decimal places, for example: floor(1.45,0)= 1;floor(1.55,0) = 1
ceiling() rounds up to the specified decimal places, for example: ceiling(1.45,0) = 2;ceiling(1.55,0)=2
MOD(N,M) means to return the residual value of N divided by M. MOD(n,2)=1 is an odd number and MOD(n,2)=1 is an even number
3, Request stores with sales records for three consecutive days in the sales_record table
Table creation:
CREATE TABLE sales_record (shopid VARCHAR(11),dt DATE,sale INT);
INSERT INTO sales_record VALUES
('A','2017-10-11',300),
('A','2017-10-12',200),
('A','2017-10-13',100),
('A','2017-10-15',300),
('A','2017-10-16',150),
('A','2017-10-17',340),
('A','2017-10-18',360),
('A','2017-10-19',400),
('B','2017-10-11',200),
('B','2017-10-12',200),
('B','2017-10-15',600),
('C','2017-10-11',350),
('C','2017-10-13',250),
('C','2017-10-14',300),
('C','2017-10-15',400),
('C','2017-10-16',200),
('D','2017-10-13',500),
('E','2017-10-14',600),
('E','2017-10-15',500),
('D','2017-10-14',600);Reference answer: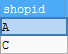
-- Solution I join2 second SELECT DISTINCT t1.shopid FROM sales_record t1 LEFT JOIN sales_record t2 ON t1.shopid=t2.shopid LEFT JOIN sales_record t3 ON t3.shopid=t2.shopid WHERE t1.dt=t2.dt-1 AND t2.dt=t3.dt-1; -- Solution two pass lead deviation SELECT DISTINCT shopid1 FROM(SELECT t1.shopid AS shopid1,t1.dt AS dt1,t1.sale AS sale1,LEAD(t1.dt,1)OVER(PARTITION BY t1.shopid ORDER BY dt)AS dt2,LEAD(t1.dt,2)OVER(PARTITION BY t1.shopid ORDER BY dt)AS dt3 FROM sales_record t1)t2 WHERE dt1=dt2-1 AND dt2=dt3-1; -- Solution 3: when the continuous date is long, the general practice is: the date minus the order of the same number of days is continuous SELECT DISTINCT shopid FROM(SELECT shopid,COUNT(1)AS COUNT FROM(SELECT shopid,dt,sale,rn,DATE_SUB(dt,INTERVAL rn DAY)AS dt_sub FROM(SELECT shopid,dt,sale,ROW_NUMBER() OVER(PARTITION BY shopid ORDER BY dt)rn FROM sales_record)a)s1 GROUP BY shopid,dt_sub)s2 WHERE s2.count>=3;
Some contents of table t2 in solution 2 are displayed here. dt2 and dt3 are LEAD() respectively, and the date data of the last row and the last two rows of dt1 are returned
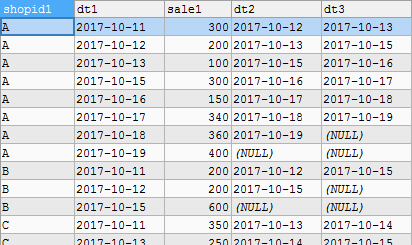
In solution 3, DATE_SUB(dt,INTERVAL rn DAY) represents the date subtraction order. If the same value is obtained, it is continuous.
Supplement: date_sub (date expression, INTERVAL expr type) A time value (time interval) will be subtracted from a date / time value; date_add (date expression, INTERVAL expr type) A time value (time interval) will be added to a date / time value. Some contents of table s2 are shown here:
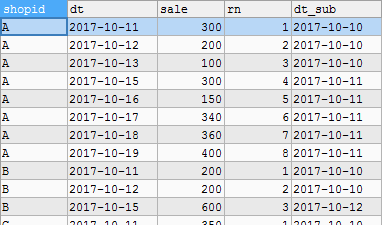
Just change the last condition where S2. Count > = n to find stores with sales records for N consecutive days.
4, Continuous clock in
Count the continuous clock in days of each employee up to now
In the table, uid is the user id, tdate is the date, is_flag is to record whether the user clocked in the current day, 1 is clocked in, 0 is not clocked in
We hope to get the following results:
| uid | flag_days |
|---|---|
| 1 | 3 |
| 2 | 5 |
Data preparation:
-- establish t surface
CREATE TABLE `t`(uid VARCHAR(255),tdate VARCHAR(255),is_flag VARCHAR(255));
-- insert data
INSERT INTO t VALUES('1','2020-02-01','1');
INSERT INTO t VALUES('1','2020-02-02','0');
INSERT INTO t VALUES('1','2020-02-03','1');
INSERT INTO t VALUES('1','2020-02-04','1');
INSERT INTO t VALUES('1','2020-02-05','0');
INSERT INTO t VALUES('1','2020-02-06','1');
INSERT INTO t VALUES('1','2020-02-07','1');
INSERT INTO t VALUES('1','2020-02-08','1');
INSERT INTO t VALUES('2','2020-02-01','1');
INSERT INTO t VALUES('2','2020-02-02','0');
INSERT INTO t VALUES('2','2020-02-03','0');
INSERT INTO t VALUES('2','2020-02-04','1');
INSERT INTO t VALUES('2','2020-02-05','1');
INSERT INTO t VALUES('2','2020-02-06','1');
INSERT INTO t VALUES('2','2020-02-07','1');
INSERT INTO t VALUES('2','2020-02-08','1');Reference answer
--Number SELECT uid,tdate,ROW_NUMBER()OVER(PARTITION BY uid ORDER BY tdate)rn FROM t WHERE is_flag=1 --Generate continuous dates according to the number, and then group and sum them SELECT uid,tdate,rn,DATE_SUB(tdate,INTERVAL rn DAY)dt_sub FROM(SELECT uid,tdate,ROW_NUMBER()OVER(PARTITION BY uid ORDER BY tdate)rn FROM t WHERE is_flag=1)t1 --Group consecutive days SELECT uid,COUNT(*) flag_days FROM(SELECT uid,tdate,rn,DATE_SUB(tdate,INTERVAL rn DAY) dt_sub FROM(SELECT uid,tdate,ROW_NUMBER()OVER(PARTITION BY uid ORDER BY tdate)rn FROM t WHERE is_flag=1)t1)t2 GROUP BY uid,dt_sub --Maximum consecutive days SELECT uid,MAX(flag_days)flag_days FROM(SELECT uid,COUNT(*) flag_days FROM(SELECT uid,tdate,rn,DATE_SUB(tdate,INTERVAL rn DAY) dt_sub FROM(SELECT uid,tdate,ROW_NUMBER()OVER(PARTITION BY uid ORDER BY tdate)rn FROM t WHERE is_flag=1)t1)t2 GROUP BY uid,dt_sub )t3 GROUP BY uid;
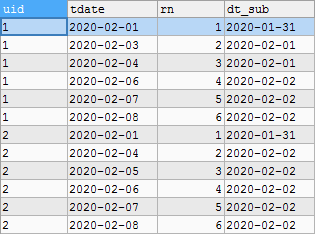 t1
t1
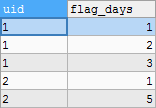 t3
t3
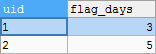 result
result
5, The cumulative problem is to calculate the annual cumulative value and the total cumulative value
--Build table
DROP TABLE temp
CREATE TABLE temp(DATE DATE,VALUE INT);
--insert data
INSERT INTO temp VALUES
('2018/11/23',10),
('2018/11/25',12),
('2018/12/31',3),
('2019/2/9',53),
('2019/3/31',23),
('2019/7/8',11),
('2019/7/31',10);Reference answer:
-- Calculate annual cumulative value and total cumulative value -- Aggregation by month and year value SELECT YEAR(DATE)AS YEAR,MONTH(DATE) MONTH,SUM(VALUE)AS VALUE FROM temp GROUP BY YEAR(DATE),MONTH(DATE) -- Calculate annual accumulation and total accumulation SELECT YEAR,MONTH, SUM(VALUE) OVER(PARTITION BY YEAR ORDER BY YEAR,MONTH)AS ysum, SUM(VALUE) OVER(ORDER BY YEAR,MONTH)AS cum_sum FROM(SELECT YEAR(DATE)AS YEAR,MONTH(DATE) MONTH,SUM(VALUE)AS VALUE FROM temp GROUP BY YEAR(DATE),MONTH(DATE))t;
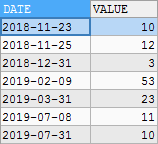 subject
subject
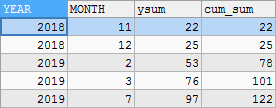 result
result