Today's learning includes packages, logging modules, hashlib modules, openpyxl modules, and concepts of deep and shallow copies.
package
In learning module, we have known four forms of module, one of which is package.
What is a bag?
It is a combination of a series of module files, expressed as a folder, which usually has a _int_ py file inside, and the essence of the package is actually a module.
Steps for first importing packages:
Generate an execution file namespace first
Create the namespace of the _int_ py file under the package
2. Execute the code in the _int_ py file below the package and place the resulting name in the _int_ py file namespace below the package.
3. Get a name in the execution file that points to the _int_ py file namespace under the package
* In the import statement, there must be a package (folder) on the left of the. number.
# When you're a package designer
1. When there are too many modules, file management should be done separately.
2. In order to avoid the problem of module renaming later, you can use relative import between each module (the files in the package should be # imported module).
# If a developer who stands on a package uses absolute paths to manage his own module, it only needs to import modules in turn based on the path of the package forever.
# The user standing on the package must add the folder path where the package is located to the system path (******)
python2 must have _init_.py file if you want to import package
Python 3 will not report errors if there is no _init_.py file under the package to be imported
Don't delete _init_ py files at will when you delete unnecessary files in your program.
logging module
There are five levels and four objects in the log module.
#5 Grade logging.debug('debug Journal') # 10 logging.info('info Journal') # 20 logging.warning('warning Journal') # 30 logging.error('error Journal') # 40 logging.critical('critical Journal') # 50 #Four objects #1.logger Object: Responsible for generating logs #2.filter Object: Filter logs (understand) #3.handler Object: Control the location of log output (file)/Terminal) #4.formmater Object: To specify the format of log content
#Log configuration """ //The values of the following two variables need to be modified manually """ logfile_dir = os.path.dirname(__file__) # log Catalogue of documents logfile_name = 'a3.log' # log file name # If there is no defined log directory, create one if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log Full path of file logfile_path = os.path.join(logfile_dir, logfile_name) # log Configuration Dictionary LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, # Filter logs 'handlers': { #Print logs to terminals 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # Print to screen 'formatter': 'simple' }, #Logs printed to files,collect info Logs above 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # Save to file 'formatter': 'standard', 'filename': logfile_path, # log file 'maxBytes': 1024*1024*5, # Log size 5 M 'backupCount': 5, 'encoding': 'utf-8', # Log file encoding, no longer need to worry about Chinese log The code is out of order. }, }, 'loggers': { #logging.getLogger(__name__)Get it logger To configure '': { 'handlers': ['default', 'console'], # Here are the two definitions above. handler Add all, that is log Data is written to the file and printed to the screen. 'level': 'DEBUG', 'propagate': True, # Up (higher) level Of logger)transmit }, # This is used by default when the key does not exist k:v To configure }, } # Configuration using log dictionary logging.config.dictConfig(LOGGING_DIC) # Configuration in Autoloading Dictionary logger1 = logging.getLogger('asajdjdskaj') logger1.debug('Good without impetuosity, hard work will bear fruit')
hashlib module
#hashlib Module (Encryption Module) import hashlib # This encryption process cannot be decrypted md = hashlib.md5() # Generate an object to help you create ciphertext md.update('hello'.encode('utf-8')) # Pass plaintext data to the object update Only acceptable bytes Type of data md.update(b'morning') # Pass plaintext data to the object update Only acceptable bytes Type of data print(md.hexdigest()) # Getting ciphertext corresponding to plaintext data
In addition to our commonly used md5, there are other algorithms, but for different algorithms, the use of the same method, the longer the length of ciphertext, the more complex the internal corresponding algorithm. But ciphertext is too long, there are two drawbacks. One is the longer the time consumed, the other is the larger the space occupied. Usually, using MD5 is enough.
md = hashlib.md5() #md.update(b'are') # The incoming content can be passed in several times, so long as the incoming content is the same, the ciphertext generated must be the same. md.update(b'a') md.update(b'r') md.update(b'e') print(md.hexdigest()) """ hashlib Modular application scenarios 1.Password Storage 2.Check the consistency of document content """
#Salting treatment # The company itself manually adds some content before each data needs to be encrypted import hashlib md = hashlib.md5() md.update(b'oldboy.com') # Salting treatment md.update(b'hello') # Real content print(md.hexdigest()) #Dynamic Salting import hashlib def get_md5(data): md = hashlib.md5() md.update('Salting'.encode('utf-8')) md.update(data.encode('utf-8')) return md.hexdigest() password = input('password>>>:') res = get_md5(password) print(res)
openpyxl module
openpyxl Fire Operating excel Table Module
Before version 03, the suffix name of excel file is xls
After version 03, the suffix name of excel file is xlsx
Other modules that operate excel:
xlwd writes excel.xlrt reads Excel
xlwd and xlrt support both excel files before version 03 and excel files after version 03
openpyxl only supports xlsx after version 03
from openpyxl import Workbook wb = Workbook() # Mr. A becomes a workbook wb1 = wb.create_sheet('index',0) # Create a form page that can be digitally controlled at the back wb2 = wb.create_sheet('index1') wb1.title ='login' # Later, you can use form page object points title Modify the form page name wb1['A3'] = 666 # in list A3 Position Add Number wb1['A4'] = 444 wb1.cell(row=6,column=3,value=8888) # Add value 8888 in row 6, column 3 of the list wb1['A5'] = '=sum(A3:A4)' # To list A3 and A4 The position is added and the result is output to A5 upper wb.save('test.xlsx') # Save the new ones excel Pay attention to confirm whether the file is closed before saving. Failure to close will result in an error.
from openpyxl import load_workbook # read file wb = load_workbook('test.xlsx',read_only=True,data_only=True) print(wb) print(wb.sheetnames) # ['login', 'Sheet', 'index1'] print(wb['login']['A3'].value) # Read out the file login in A3 The Value of Location
Deep and shallow copies
l1 = [1,2,3,[4,5,6]] l2 = l1 print(id(l1),id(l2)) # value copy
#shallow copy import copy l1 = [1,2,3,[4,5,6]] l2 = copy.copy(l1) print(l1,l2) # The same value print(id(l1),id(l2)) # Addresses are different l1[0]=0 print(l1,l2) # l1=[0, 2, 3, [4, 5, 6]],l2=[1, 2, 3, [4, 5, 6]] l1[3].append(7) print(l1,l2) # l1=[0, 2, 3, [4, 5, 6, 7]],l2=[1, 2, 3, [4, 5, 6, 7]]
Shallow copy illustration
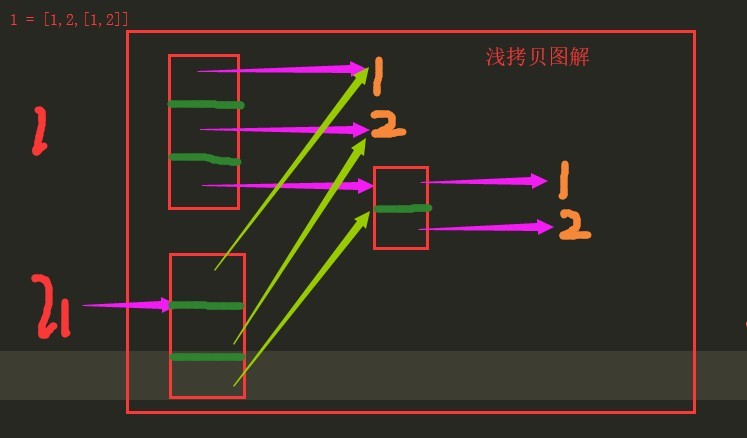
For shallow copies, only a space is created to store a new list in memory, but the elements in the new list are common to the elements in the original list. When the original list contains variable types, the shallow copy points to the original variable types, so when the elements in the original list are issued. Change, shallow copies will change with it.
#deep copy l2 = copy.deepcopy(l1) l1[3].append(7) print(l1,l2) # l1 = [1, 2, 3, [4, 5, 6, 7]],l2=[1, 2, 3, [4, 5, 6]]
Deep copy graphics
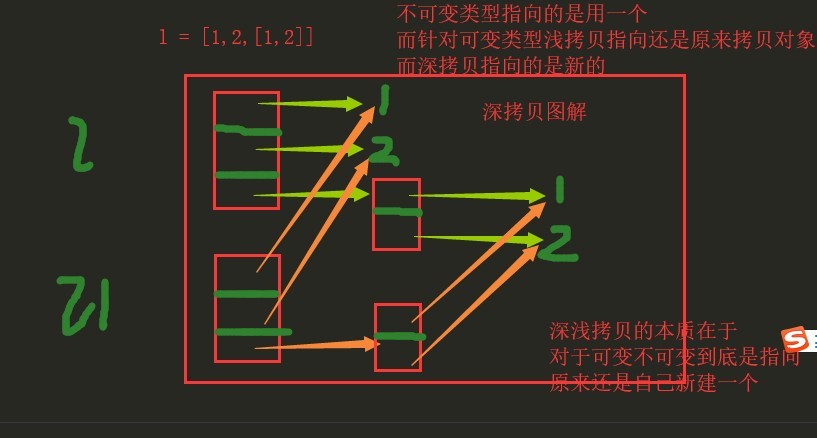
For deep copy, lists are recreated in memory, variable data types in lists are recreated, and invariant data types in lists are common.
Summary: In deep and shallow copies, immutable data types are common, but shallow copies only point to variable data types, while deep copies are completely new.