pandas Library (reference from https://www.jianshu.com/p/6acafa350208
https://blog.csdn.net/zengxiantao1994/article/details/75200110 (there are also many learning videos on the beep station)
pandas provides high-performance and easy-to-use data types and analysis tools, which can be used to process csv, tsv, txt, mysql (relational database table), excel, html and other files
First, introduce
import pandas as pd
1. Read data (reference from https://www.bilibili.com/video/BV1UJ411A7Fs?p=2)
# Read the CSV file named ratings
fpath = ".../ratings.csv" # Write the path
ratings = pd.read_csv(fpath) # Read data
ratings.head() # View the first few rows of data: index, column name and data body from left to right
ratings.shape # Output rows and columns
ratings.columns # View a list of column names
ratings.index # View index columns
ratings.dtypes # View the data type of each column
# Read the txt file (split by - instead of comma), and the file is pvuv
fpath = ".../access_pvuv.txt"
pvuv = pd.read_csv(
fpath,
sep = "\t" # Specify address separator \ t
header = None # Unmarked line
names = ['pdate','pv','uv'] # Set column naming
)
# Read excel file
fpath =
pvuv = pd.read(fpath)
# Read MySQL
import pymysql
comn = pymysql.commect(
host = '127.0.0.1',
user = 'root',
password = '12345678',
database = 'test',
charset = 'utf8'
)
mysql_page = pd.read_sql("select*from crazyant_pvuv",con = conn) # The first is an sql statement, and the second is to establish a connection
mysql_page
2. Data structure
There are two data types, Series and DataFrame
Series one-dimensional data, one row or one column
(1) The data list can generate simple series (with or without labels)
(2) Dictionary creation Series
(3) Label index can be queried
DataFrame is a two-dimensional array
(1) Create a dataframe from multiple dictionary sequences
(2) Query series from dataframe
If only one row and one column are queried, PD. Is returned Series
If multiple rows and columns are queried, PD DataFrame
3. Data query
df.loc method
(1) Use the value of a single label
(2) Batch query using value list
(3) Range query using numerical range
(4)!!! Query with conditional expression!!
Returns a Boolean value
(5) Call function query
4. New data column
(1) Direct replication method
The temperature is listed as C, which is required to be removed. Replace c with empty.
df.loc[:,"wencha"] = df["bWendu"] - df["yWendu"] # Add a new temperature difference column, which is the highest temperature minus the lowest temperature
(2)df.apply method
Pass a function to return series
(3)df.assign method
Without modifying df itself, a new object is returned
(4) Assign values respectively according to conditional selection
5. Data statistics function
(1) Summary statistics (value type)
df. Discriminate() calculates the minimum, maximum and average values
Average: df["column name"]. mean()
Maximum: df["column name"]. max()
Minimum value: df["column name"]. min()
(2) Unique de duplication and number of columns by value (not used for numerical columns, but for enumeration and classification columns)
De duplication: df["column name"]. unique
Count by value: df ["column name"]. value_counts()
Count by value is the statistics of how many times each name appears, which will be output from large to small.
(3) Correlation coefficient and covariance


Covariance matrix: DF cov()
Correlation coefficient matrix: DF corr()
View the correlation coefficient of two columns separately: df ["column name"]. corr(df ["column name"])
6. Pandas's handling of missing values of functions( https://www.bilibili.com/video/BV1UJ411A7Fs?p=7)
isnull and notnull: detect whether it is empty
dropna: delete missing values:
- axis: delete row or column, {0 or 'index', 1 or 'columns'}, default 0
- how: if it is equal to any, any value will be deleted if it is empty. If it is equal to all, all values will be deleted if they are empty
- inplace: if True, modify the current df; otherwise, return a new df
fillna: fill in null values
- Value: the value used for filling. It can be a single value or a dictionary (key is the column name and value is the value)
- method: equal to fill, fill forword fill with the previous non empty value; Equal to bfill, backword fill is filled with the last non empty value
- axis: Fill by row or column, {0 or 'index', 1 or 'columns'}
- inplace: if True, modify the current df; otherwise, return a new df
7. SettingWithCopyWarning alarm resolution
8. Data sorting
Series:
import pandas as pd # Series sort pd.Series.sort_values(ascending=True,inplace=False) # Ascending: the default is True ascending sorting and False descending sorting. inplace: modify original Series #Sorting of DataFrame pd.DataFrame.sort_values(by,ascending=True,inplace=False) # by: string or list, single column sorting or multi column sorting; ascending: Boolean or list; inplace: modify the original DataFrame # Multi column sorting pd.DataFrame.sort_values(by=["Column name"."Column name"])
9. String processing
First get the str attribute of Series and use various string processing functions.
Application field: 1 Use the Series bool classes such as startwith and contain of str to perform conditional queries.
2. Chain operation that requires multiple str processing.
3. Processing using regular expressions.
10. Understanding of axis parameters( https://www.jianshu.com/p/4f18e8327872)
0/index refers to a row, and aggregation refers to cross rows. 1/columns refers to a column, and aggregation refers to cross columns
import numpy as np
df = pd.DataFrame(
np.arange(12).reshape(3,4),
columns = ['A','B','C','D']
)
df.drop("A", axis=1) # Delete column
df.drop(1, axis=0) # Delete row
df.mean(axis=1) # If an axis is specified, it will move. It is similar to being traversed by for. Other axes mean unchanged. 1 refers to the column, which is the average number of output columns.
df.sum(axis=0) # Sum each column of data
df.sum(axis=1) # Sum each row of data
Note here that after deleting, summing and averaging operations, you need to assign the operation result to the data of another dataframe.
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.arange(12).reshape(3,4),
columns = ['A','B','C','D']
)
a=df.mean(axis=1)
print(df)
print(a)
The result is:

11. Purpose of Pandas index
Purpose: more convenient data query; Performance improvement; Automatic data alignment; More powerful data structure support
(1) First five lines of query
df.loc[500].head(5)
(2) improve query performance:
If the index is unique, Pandas will use the hash table to optimize, and the time complexity is O(1)
If it is not unique, it will be queried by dichotomy, and the performance is O(logN)
If it is completely random, the whole table must be scanned for each query, and the query performance is O(N)
(3) Automatic alignment, automatic alignment when the list is added or subtracted
# index auto align data
s1 = pd.Series([1,2,3],index=list("abc"))
s2 = pd.Series([2,3,4],index=list("bcd"))
print(s1+s2)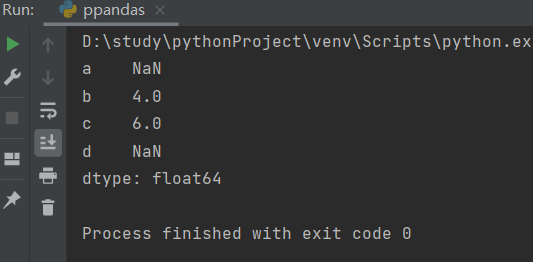
(4) data structure support
Categorialindex, an Index based on classified data, improves performance.
MultiIndex, a multi-dimensional index, is used for groupby, mostly the results after aggregation, etc.
DatetimeIndex, time type index, powerful date and time method support.
12. Merge syntax (merge)
Quantity alignment of merge
One to one, the associated keywords are unique
One to many, the associated keywords are unique on the left and not unique on the right
Many to many, the associated keywords are not unique, and the number of results is M*N
The difference between the four join s
13. Pandas realizes data merging concat
Application scenario: batch merge Excel with the same format, add rows to DataFrame, and add columns to DataFrame.
That is, merge multiple Pandas objects (DataFrame\Series) into one along an axis (axis=0/1) using a merge method (inner/outer).
pandas.concat(objs,axis=0,join='outer',ignore_index=False) # objs refers to the objects to be merged. When axis is 0, it is merged by row, and when axis is 1, it is merged by column. join is alignment, ignore_index refers to whether the original index is ignored. # append only merges by row, not by column DataFrame.append(other,ignore_index=False) # other refers to a single dataframe, series,dict or list.
Use join=inner to filter out mismatched columns; Using axis=1 is equivalent to adding a new column
The list parameter of concat is very flexible. It can be series or dataframe.