Basic and Advanced Applications of Dubbo
- Load Balancing, Cluster Fault Tolerance, Service Degradation
- Local stub, local disguise, asynchronous call
load balancing
Dubbo supports four strategies:
polling
- Polling, set the polling rate according to the weight after the convention.
- There is a problem with slow providers accumulating requests, such as the second machine being slow but not hung, being stuck when the request is transferred to the second machine, and over time all requests are stuck in the second machine.
- If A, B and C services have the same weight, ABCABC will be invoked sequentially.
- If A= 1/2, B=1/4, C=1/4 services have different weights, then AABCAABC calls on sequentially;
random
- Random, set random probability by weight.
- The probability of collision on a section is high, but the larger the call volume, the more evenly distributed, and the weights used by probability are more evenly distributed, which is conducive to dynamically adjusting provider weights.
- If the weights of A, B and C are the same, the average call rate of A, B and C is 1/3, and the call order is out of order.
- A= 1/2, B=1/4, C=1/4 services have different weights, A calls rate is 1/2, BC 1/4, call order is out of order
Consistent Hashing
- Consistency Hash, requests for the same parameters are always sent to the same provider.
- When a provider hangs up, requests originally sent to that provider are spread out to other providers based on virtual nodes without causing drastic changes.
Note that the same parameters are used: when calling the same interface with a consistency hash, requests that pass the same parameters (get a record with ID = 1) are consistently sent to the same server;
Minimum number of active calls
-
The minimum number of active calls, the random number of the same active number, the active number refers to the difference between the counts before and after the call.
-
Causes slower providers to receive fewer requests because the slower providers have a greater difference in count before and after invocation.
-
A, B and C servers are all processing one request at the same time, so the number of active servers is 1. After a period of time, only A's requests are processed, the number of active servers is -1, and the number of active servers is 0. Then a new request is sent for A to process, A has the smallest number of activities, 0, BC is 1;
-
logic
- Consumers cache all providers of the service they call, e.g. as p1, p2, p3 service providers, there are attributes in each provider that are marked as active, default bit 0
- If the load balancing strategy is leastactive when consumers adjust services
- The consumer will determine the active of all cached service providers, choose the most, if all are the same, then randomly
- After selecting a service provider, assuming bit p2, Dubbo will pair p2.active+1
- Then actually make a request to call the service
- After the consumer receives the response result, it responds to p2.active-1
- This completes the current active tuning count for a service provider without affecting service tuning performance
Use
The @Reference annotation's loadbalance property configuration (all lowercase) can also be configured through the Admin Console;
@Reference(version = "default", loadbalance = "consistenthash")
private DemoService demoService;
Question 1: Why are load statistics placed on the client Consumer instead of the service provider Provider?
Reason: Unable to count/difficult to count; One machine can't know the active number of another machine. It can go to other servers through HTTP requests to get the active number. This obviously does not show that if there are 1000 clusters, then one thousand HTTP requests need to be sent, which takes time directly in seconds and is not feasible.
Question 2: Why are load statistics placed on the client Consumer instead of the registry?
Reason: Question 1, each time you process a request, you need to tell the registry that the number of active + 1, the number of active after processing the request, -1, is equivalent to two HTTP requests, which takes time. Another reason is that each machine has to interact with the registry to process requests, even a cluster registry cannot handle such a large amount of concurrency.
Service Timeout
Service timeouts can be configured on both service providers and service consumers, which are different.
Consumers invoke a service in three steps:
- Consumer Send Request (Network Transport)
- Server Execution Service
- Server Return Response (Network Transport)
If timeout is configured on only one side of the service side and the consumer side, there is no ambiguity.
- Configuration indicates the time-out for the consumer to invoke the service. If the consumer has not received the response result after the time-out, the consumer will throw the time-out exception.
- Configured on the server side, the server side does not throw exceptions. After the server executes the service, it checks the execution time of the service and prints a timeout log if it exceeds timeout. The service will be executed normally.
If you have a timeout on both the service side and the consumer side, that's more complicated, assume
- Service Execution 5s
- Consumer timeout=3s
- Server-side timeout=6s
Then when the consumer invokes the service, the consumer receives a timeout exception (because the consumer has timed out), the server finishes executing normally, and prints the timeout log (the server has not timed out).
Timeout Configuration
- Client Configuration
The timeout property configuration of the @Reference annotation can also be configured through the Admin Console;
@Reference(version = "timeout", timeout = 3000)
private DemoService demoService;
- Admin Desk Settings
Configured through the timeout property of the @Service annotation, or through the Admin Desk;
@Service(version = "timeout", timeout = 4000)
public class TimeoutDemoService implements DemoService {
@Override
public String sayHello(String name) {
System.out.println("Executed timeout service" + name);
// Service Execution 5 seconds
// The service timeout is 3 seconds, but after 5 seconds, the server will finish the task
// Service timeout is when a warn is thrown if the service execution time exceeds the specified timeout time
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end of execution" + name);
URL url = RpcContext.getContext().getUrl();
return String.format("%s: %s, Hello, %s", url.getProtocol(), url.getPort(), name); // Normal Access
}
}
Cluster fault tolerance
The fault tolerance scheme provided by Dubbo when a cluster call fails;
When a service consumer invokes a service, there are multiple service providers in the service. After load balancing, one of them is selected for invocation, but after an error is invoked, Dubbo adopts a follow-up processing strategy.
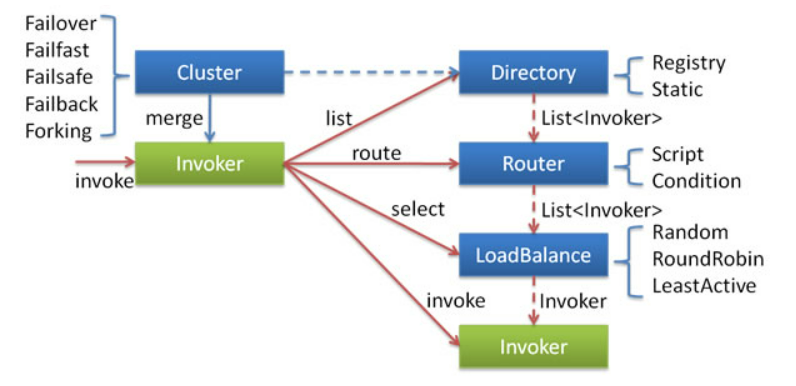
failover Retry
By default, failover retries, fail automatic switching, and when failures occur, retry other servers. Usually used for read operations, but retrying can cause longer latencies. Retries="2" can be used to set the number of retries (excluding the first). Default is 2 times;
- Server Settings
@Service(cluster = "failover" , retries = 2)
public class DemoServiceImpl implements DemoInterface {
@Override
public User getUser() {
return new User("zqh");
}
}
- Consumer Settings
@Reference(cluster = "failover" ,retries = 2)
private DemoInterface demoService;
Failfast Cluster Fast Failure
Quick fail, make only one call, fail immediately error. Usually used for write operations that are not idempotent, such as adding records.
- Consumer settings:
@Reference(cluster = "failfast")
- Server Settings
@Service(cluster = "failfast")
Failsafe Cluster Fail Security
Failure security, when an exception occurs, directly ignored. Usually used for operations such as writing audit logs.
- Consumer settings:
@Reference(cluster = "failsafe ")
- Server Settings
@Service(cluster = "failsafe ")
Failback Cluster Failure Auto Recovery
Failure auto-recovery, background record failed requests, periodic resend. Typically used for message notification operations.
- Consumer settings:
@Reference(cluster = "failback ")
- Server Settings
@Service(cluster = "failback ")
Forking Cluster Parallel Call
Multiple servers are called in parallel and returned with only one success. Usually used for read operations with high real-time requirements, but more service resources are wasted. You can set the maximum number of parallels by forks="2".
- Consumer settings:
@Reference(cluster = "forking")
- Server Settings
@Service(cluster = "forking")
Broadcast Cluster Broadcast calls individually
Broadcast calls all providers, one by one, and any one will fail. Usually used to notify all providers to update local resource information such as caches or logs.
-
Via broadcast. Fail. The percentage of percent configuration node calls that fail. When this percentage is reached, the BroadcastClusterInvoker will no longer call other nodes and throw an exception directly.
-
broadcast.fail.percent ranges from 0 to 100. By default, exceptions are thrown when all calls fail.
-
broadcast.fail.percent simply controls whether to continue calling other nodes after a failure and does not change the result (any error will cause an error).
-
Broadcast. Fail. The percent parameter is in dubbo2. Version 7.10 and above is valid.
-
broadcast.fail.percent=20 means that when 20% of node calls fail, an exception is thrown and no other nodes are called.
@Reference(cluster = "broadcast")
- Server Settings
@Service(cluster = "broadcast")
Cluster Fault Tolerance Maturity

service degradation
The action taken by a service consumer when invoking a service provider if the service provider misreports.
The difference between cluster fault tolerance and service degradation is:
- Cluster fault tolerance is cluster-wide
- Service demotion is the fault tolerance of a single service consumer/provider
Use
- Consumer side
@Reference(mock = "fail:return+null")
- Server
@Service(mock = "fail:return+null")
Both indicate that when a service call fails, it returns to null;
Local disguise
Is a mock, essentially the same as a service downgrade;
Use scenarios: Some undeveloped functionality requires mock data, which is false data returns;
- Service Provider
@Service(mock = "force:return+null")
Indicates that the consumer's method calls to the service all directly return null values without making remote calls. Used to shield callers from unavailability of unimportant services.
Local stub
After a remote service, the client usually has only the interface left, and the implementation is all on the server side, but sometimes the provider wants to perform some logic on the client side as well.
For example: make ThreadLocal caches, validate parameters in advance, fake fault-tolerant data after a call fails, and so on. At this time, you need to take Stub with the API. Client generates Proxy instance, passes Proxy to Stub 1 through the constructor, and then exposes Stub to user. Stub can decide whether to call Proxy or not.
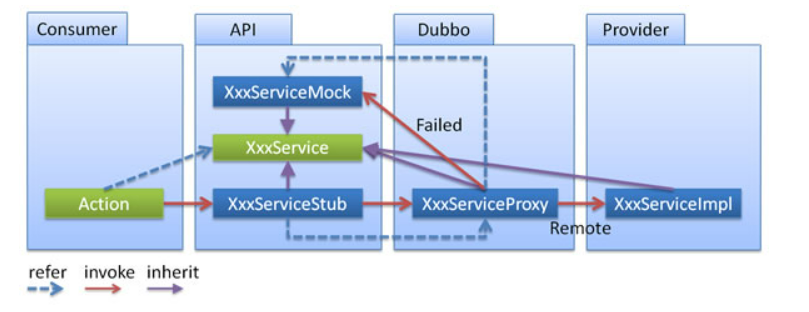
Use
package com.dubbo.consumer;
import com.tuling.DemoService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.ConfigurableApplicationContext;
import java.io.IOException;
@EnableAutoConfiguration
public class StubDubboConsumerDemo {
// @Reference(version = "timeout", timeout = 1000, stub = "com.tuling.DemoServiceStub")
@Reference(version = "timeout", timeout = 1000, stub = "true")
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(StubDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
System.out.println((demoService.sayHello("Zhou Yu")));
}
}
- @Reference(version = "timeout", timeout = 1000, stub = "true")
Dubbo generates class paths based on package name, class name + Stub to find class information, which is com.dubbo.DemoServiceStub, no error reported; You need to provide a constructor with an interface class type to pass in a real remote proxy object. Finally, the service is invoked through this object; - @Reference(version = "timeout", timeout = 1000, stub = "com.tuling.DemoServiceStub")
package com.dubbo;
public class DemoServiceStub implements DemoService {
private final DemoService demoService;
// Constructor passes in a real remote proxy object
public DemoServiceStub(DemoService demoService){
this.demoService = demoService;
}
@Override
public String sayHello(String name) {
// This code is executed on the client side, you can do ThreadLocal local caching on the client side, or pre-verify that the parameters are legal, etc.
try {
return demoService.sayHello(name); // safe null
} catch (Exception e) {
// You can tolerate errors and do any AOP blocking
return "Fault Tolerant Data";
}
}
}
Asynchronous call
Beginning with 2.7.0, all of Dubbo's asynchronous programming interfaces are based on CompletableFuture
NIO-based non-blocking implements parallel invocation. Clients can complete parallel invocation of multiple remote services without starting multithreads, which is less expensive than multithreading.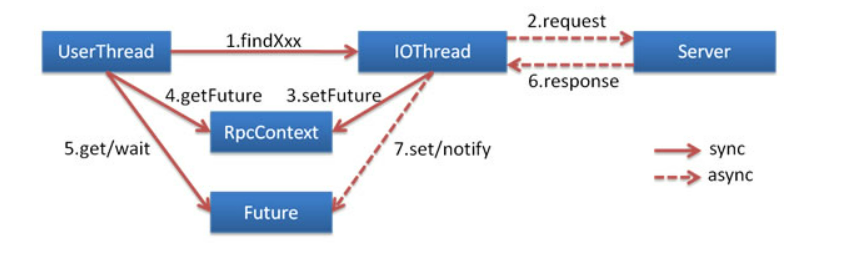
Interface method:
public interface AsyncService {
CompletableFuture<String> sayHello(String name);
}
Consumer:
@EnableAutoConfiguration
public class AsyncDubboConsumerDemo {
@Reference(version = "async")
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(AsyncDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
// The call returns directly to CompletableFuture
CompletableFuture<String> future = demoService.sayHelloAsync("Asynchronous call"); // 5
future.whenComplete((v, t) -> {
if (t != null) {
t.printStackTrace();
} else {
System.out.println("Response: " + v);
}
});
System.out.println("It's over");
}
}
Provider:
@Service(version = "async")
public class AsyncDemoService implements DemoService {
@Override
public String sayHello(String name) {
System.out.println("Synchronization service executed" + name);
URL url = RpcContext.getContext().getUrl();
return String.format("%s: %s, Hello, %s", url.getProtocol(), url.getPort(), name); // Normal Access
}
@Override
public CompletableFuture<String> sayHelloAsync(String name) {
System.out.println("Asynchronous service executed" + name);
return CompletableFuture.supplyAsync(() -> {
return sayHello(name);
});
}
}
The new asynchronous programming in Java8, asynchronous programming, is easy to see.
REST in Dubbo
Official Rest Description
Note that Dubbo's REST is also a protocol supported by Dubbo.
When we provide a service with Dubbo and consumers want to invoke the service without using Dubbo, then we can have our service support the REST protocol so that consumers can invoke our service through REST.
Note: If a service is available only with the REST protocol, the service must define an access path with the @Path annotation
Use
@Service
@Path("demo")
public class RestDemoService implements DemoService {
@GET
@Path("say")
@Produces({ContentType.APPLICATION_JSON_UTF_8, ContentType.TEXT_XML_UTF_8})
@Override
public String sayHello(@QueryParam("name") String name) {
System.out.println("Executed rest service" + name);
URL url = RpcContext.getContext().getUrl();
return String.format("%s: %s, Hello, %s", url.getProtocol(), url.getPort(), name); // Normal Access
}
}
Like Spring MVC, people who learn this don't have Spring MVC (I can't coagulate)
Other
- Dynamic Configuration
Official address: http://dubbo.apache.org/zh/docs/v2.7/user/examples/config-rule/
Modify the configuration of the service through the console without restarting the server; - Service Routing
Official address: http://dubbo.apache.org/zh/docs/v2.7/user/examples/routing-rule/
Actions are similar to those of gateways (generally by architects) - Admin Desk
GitHub address: https://github.com/apache/dubbo-admin
Summary
Dubbo has many applications, there are at least dozens of official websites, there are no more to learn and there are important things to learn.