
About redis Stream
redis stream implements most of the functions of message queues, including:
news ID Serialization generation of Message traversal Blocking and non blocking reads of messages Packet consumption of messages ACK Confirmation mechanism
After this combination, I realized that I didn't know the message queue.
You can think about it first. If we want to implement a message queue ourselves, we have all these guiding ideas. How should we write it?
Let me mention a little more about the general environment:
Message queue is to be placed in the scenario of large concurrency to realize peak shaving and decoupling in business.
After thinking about it, let's take a look at the implementation of redis.
Stream structure
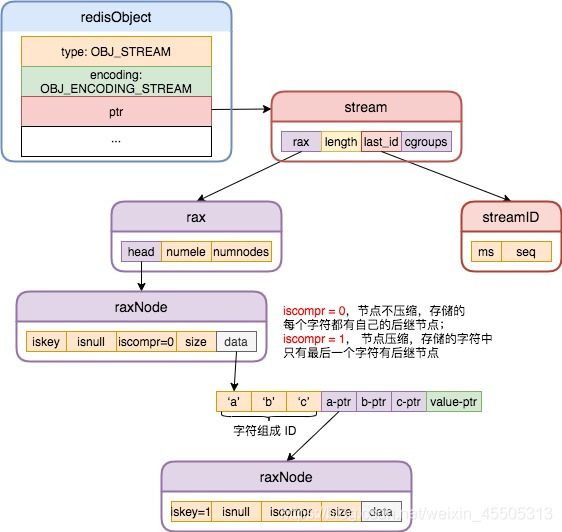
This figure is familiar to you first. The implementation of Redis Stream depends on Rax and listpack. Each message flow contains a Rax structure, with the message ID as the key and the listpack section as the value.
For those who do not understand these two data domains, you can take a look at the first two articles in this series.
typedef struct stream {
rax *rax; //Since the message ID starts with the timestamp, there will be a lot of duplication in storing the message content
//The rax value of rax points to listpack, and the rax key is the smallest message ID in the message flow
uint64_t length; /* Number of elements inside this stream. */
streamID last_id; /* Zero if there are yet no items. */
rax *cgroups; //Store the consumption group information. The key value is the name of the consumption group, and the value points to streamCG
} stream; //The Stream structure stores all the information of a message flow
StreamID is defined as follows:
/* Stream item ID: a 128 bit number composed of a milliseconds time and
* a sequence counter. IDs generated in the same millisecond (or in a past
* millisecond if the clock jumped backward) will use the millisecond time
* of the latest generated ID and an incremented sequence. */
typedef struct streamID {
uint64_t ms; /* Unix time in milliseconds. */
uint64_t seq; /* Sequence number. */
} streamID;
For this design, you can think about quicklist, which is also a sparse index method. The purpose is to reduce the movement of data when deleting messages.
StreamCG stores the consumption group information, which is similar to the above Stream:
/* Consumer group. */
typedef struct streamCG {
streamID last_id; /* Last delivered (not acknowledged) ID for this
group. Consumers that will just ask for more
messages will served with IDs > than this. */
rax *pel; /* Pending entries list. This is a radix tree that
has every message delivered to consumers (without
the NOACK option) that was yet not acknowledged
as processed. The key of the radix tree is the
ID as a 64 bit big endian number, while the
associated value is a streamNACK structure.*/
rax *consumers; /* A radix tree representing the consumers by name
and their associated representation in the form
of streamConsumer structures. */
} streamCG;
pel: all information to be confirmed in the group
Consumers: all consumers in the group. The Rax value points to the streamConsumer structure.
/* A specific consumer in a consumer group. */
typedef struct streamConsumer {
mstime_t seen_time; /* Last time this consumer was active. */
sds name; /* Consumer name. This is how the consumer
will be identified in the consumer group
protocol. Case sensitive. */
rax *pel; /* Consumer specific pending entries list: all
the pending messages delivered to this
consumer not yet acknowledged. Keys are
big endian message IDs, while values are
the same streamNACK structure referenced
in the "pel" of the conumser group structure
itself, so the value is shared. */
} streamConsumer;
The pel s in both places point to the message information to be confirmed. The following structure stores these information:
/* Pending (yet not acknowledged) message in a consumer group. */
typedef struct streamNACK {
mstime_t delivery_time; /* Last time this message was delivered. */
uint64_t delivery_count; /* Number of times this message was delivered.*/
streamConsumer *consumer; /* The consumer this message was delivered to
in the last delivery. */
} streamNACK;
So far, the context of the whole Stream has been clear. Look at another iterator.
For such a troublesome structure, you must customize an iterator!!!
And this iterator is not simple.
/* We define an iterator to iterate stream items in an abstract way, without
* caring about the radix tree + listpack representation. Technically speaking
* the iterator is only used inside streamReplyWithRange(), so could just
* be implemented inside the function, but practically there is the AOF
* rewriting code that also needs to iterate the stream to emit the XADD
* commands. */
typedef struct streamIterator {
stream *stream; //The message flow that the iterator is currently traversing
streamID master_id; /* ID of the master entry at listpack head. */
uint64_t master_fields_count; /* Master entries # of fields. */
unsigned char *master_fields_start; /* Master entries start in listpack. */
unsigned char *master_fields_ptr; /* Master field to emit next. */
int entry_flags; /* Flags of entry we are emitting. */
int rev; /* True if iterating end to start (reverse). */
uint64_t start_key[2]; /* Start key as 128 bit big endian. */
uint64_t end_key[2]; /* End key as 128 bit big endian. */
raxIterator ri; /* Rax iterator. */
unsigned char *lp; /* Current listpack. */
unsigned char *lp_ele; /* Current listpack cursor. */
unsigned char *lp_flags; /* Current entry flags pointer. */
/* Buffers used to hold the string of lpGet() when the element is
* integer encoded, so that there is no string representation of the
* element inside the listpack itself. */
unsigned char field_buf[LP_INTBUF_SIZE];
unsigned char value_buf[LP_INTBUF_SIZE];
} streamIterator;
Stream operation
Add message
/* Adds a new item into the stream 's' having the specified number of
* field-value pairs as specified in 'numfields' and stored into 'argv'.
* Returns the new entry ID populating the 'added_id' structure.
*
* If 'use_id' is not NULL, the ID is not auto-generated by the function,
* but instead the passed ID is used to add the new entry. In this case
* adding the entry may fail as specified later in this comment.
*
* The function returns C_OK if the item was added, this is always true
* if the ID was generated by the function. However the function may return
* C_ERR if an ID was given via 'use_id', but adding it failed since the
* current top ID is greater or equal. */
int streamAppendItem(stream *s, robj **argv, int64_t numfields, streamID *added_id, streamID *use_id) {
/* Generate the new entry ID. */
streamID id;
if (use_id)
id = *use_id;
else
streamNextID(&s->last_id,&id);
/* Check that the new ID is greater than the last entry ID
* or return an error. Automatically generated IDs might
* overflow (and wrap-around) when incrementing the sequence
part. */
if (streamCompareID(&id,&s->last_id) <= 0) return C_ERR;
/* Add the new entry. */
raxIterator ri;
raxStart(&ri,s->rax);
raxSeek(&ri,"$",NULL,0);
size_t lp_bytes = 0; /* Total bytes in the tail listpack. */
unsigned char *lp = NULL; /* Tail listpack pointer. */
/* Get a reference to the tail node listpack. */
if (raxNext(&ri)) {
lp = ri.data;
lp_bytes = lpBytes(lp);
}
raxStop(&ri);
/* We have to add the key into the radix tree in lexicographic order,
* to do so we consider the ID as a single 128 bit number written in
* big endian, so that the most significant bytes are the first ones. */
uint64_t rax_key[2]; /* Key in the radix tree containing the listpack.*/
streamID master_id; /* ID of the master entry in the listpack. */
/* Create a new listpack and radix tree node if needed. Note that when
* a new listpack is created, we populate it with a "master entry". This
* is just a set of fields that is taken as references in order to compress
* the stream entries that we'll add inside the listpack.
*
* Note that while we use the first added entry fields to create
* the master entry, the first added entry is NOT represented in the master
* entry, which is a stand alone object. But of course, the first entry
* will compress well because it's used as reference.
*
* The master entry is composed like in the following example:
*
* +-------+---------+------------+---------+--/--+---------+---------+-+
* | count | deleted | num-fields | field_1 | field_2 | ... | field_N |0|
* +-------+---------+------------+---------+--/--+---------+---------+-+
*
* count and deleted just represent respectively the total number of
* entries inside the listpack that are valid, and marked as deleted
* (deleted flag in the entry flags set). So the total number of items
* actually inside the listpack (both deleted and not) is count+deleted.
*
* The real entries will be encoded with an ID that is just the
* millisecond and sequence difference compared to the key stored at
* the radix tree node containing the listpack (delta encoding), and
* if the fields of the entry are the same as the master entry fields, the
* entry flags will specify this fact and the entry fields and number
* of fields will be omitted (see later in the code of this function).
*
* The "0" entry at the end is the same as the 'lp-count' entry in the
* regular stream entries (see below), and marks the fact that there are
* no more entries, when we scan the stream from right to left. */
/* First of all, check if we can append to the current macro node or
* if we need to switch to the next one. 'lp' will be set to NULL if
* the current node is full. */
if (lp != NULL) {
if (server.stream_node_max_bytes &&
lp_bytes >= server.stream_node_max_bytes)
{
lp = NULL;
} else if (server.stream_node_max_entries) {
int64_t count = lpGetInteger(lpFirst(lp));
if (count >= server.stream_node_max_entries) lp = NULL;
}
}
int flags = STREAM_ITEM_FLAG_NONE;
if (lp == NULL || lp_bytes >= server.stream_node_max_bytes) {
master_id = id;
streamEncodeID(rax_key,&id);
/* Create the listpack having the master entry ID and fields. */
lp = lpNew();
lp = lpAppendInteger(lp,1); /* One item, the one we are adding. */
lp = lpAppendInteger(lp,0); /* Zero deleted so far. */
lp = lpAppendInteger(lp,numfields);
for (int64_t i = 0; i < numfields; i++) {
sds field = argv[i*2]->ptr;
lp = lpAppend(lp,(unsigned char*)field,sdslen(field));
}
lp = lpAppendInteger(lp,0); /* Master entry zero terminator. */
raxInsert(s->rax,(unsigned char*)&rax_key,sizeof(rax_key),lp,NULL);
/* The first entry we insert, has obviously the same fields of the
* master entry. */
flags |= STREAM_ITEM_FLAG_SAMEFIELDS;
} else {
serverAssert(ri.key_len == sizeof(rax_key));
memcpy(rax_key,ri.key,sizeof(rax_key));
/* Read the master ID from the radix tree key. */
streamDecodeID(rax_key,&master_id);
unsigned char *lp_ele = lpFirst(lp);
/* Update count and skip the deleted fields. */
int64_t count = lpGetInteger(lp_ele);
lp = lpReplaceInteger(lp,&lp_ele,count+1);
lp_ele = lpNext(lp,lp_ele); /* seek deleted. */
lp_ele = lpNext(lp,lp_ele); /* seek master entry num fields. */
/* Check if the entry we are adding, have the same fields
* as the master entry. */
int64_t master_fields_count = lpGetInteger(lp_ele);
lp_ele = lpNext(lp,lp_ele);
if (numfields == master_fields_count) {
int64_t i;
for (i = 0; i < master_fields_count; i++) {
sds field = argv[i*2]->ptr;
int64_t e_len;
unsigned char buf[LP_INTBUF_SIZE];
unsigned char *e = lpGet(lp_ele,&e_len,buf);
/* Stop if there is a mismatch. */
if (sdslen(field) != (size_t)e_len ||
memcmp(e,field,e_len) != 0) break;
lp_ele = lpNext(lp,lp_ele);
}
/* All fields are the same! We can compress the field names
* setting a single bit in the flags. */
if (i == master_fields_count) flags |= STREAM_ITEM_FLAG_SAMEFIELDS;
}
}
/* Populate the listpack with the new entry. We use the following
* encoding:
*
* +-----+--------+----------+-------+-------+-/-+-------+-------+--------+
* |flags|entry-id|num-fields|field-1|value-1|...|field-N|value-N|lp-count|
* +-----+--------+----------+-------+-------+-/-+-------+-------+--------+
*
* However if the SAMEFIELD flag is set, we have just to populate
* the entry with the values, so it becomes:
*
* +-----+--------+-------+-/-+-------+--------+
* |flags|entry-id|value-1|...|value-N|lp-count|
* +-----+--------+-------+-/-+-------+--------+
*
* The entry-id field is actually two separated fields: the ms
* and seq difference compared to the master entry.
*
* The lp-count field is a number that states the number of listpack pieces
* that compose the entry, so that it's possible to travel the entry
* in reverse order: we can just start from the end of the listpack, read
* the entry, and jump back N times to seek the "flags" field to read
* the stream full entry. */
lp = lpAppendInteger(lp,flags);
lp = lpAppendInteger(lp,id.ms - master_id.ms);
lp = lpAppendInteger(lp,id.seq - master_id.seq);
if (!(flags & STREAM_ITEM_FLAG_SAMEFIELDS))
lp = lpAppendInteger(lp,numfields);
for (int64_t i = 0; i < numfields; i++) {
sds field = argv[i*2]->ptr, value = argv[i*2+1]->ptr;
if (!(flags & STREAM_ITEM_FLAG_SAMEFIELDS))
lp = lpAppend(lp,(unsigned char*)field,sdslen(field));
lp = lpAppend(lp,(unsigned char*)value,sdslen(value));
}
/* Compute and store the lp-count field. */
int64_t lp_count = numfields;
lp_count += 3; /* Add the 3 fixed fields flags + ms-diff + seq-diff. */
if (!(flags & STREAM_ITEM_FLAG_SAMEFIELDS)) {
/* If the item is not compressed, it also has the fields other than
* the values, and an additional num-fileds field. */
lp_count += numfields+1;
}
lp = lpAppendInteger(lp,lp_count);
/* Insert back into the tree in order to update the listpack pointer. */
if (ri.data != lp)
raxInsert(s->rax,(unsigned char*)&rax_key,sizeof(rax_key),lp,NULL);
s->length++;
s->last_id = id;
if (added_id) *added_id = id;
return C_OK;
}
Process analysis:
1. Get the node where the last key of rax is located. Because the rax tree is stored in the order of message id, the last key node stores the last inserted message.
2. Check whether the node can insert this new message.
3. If the node can no longer insert a new message (listpack is empty or the maximum storage value has been reached), initialize the new listpack; if it can still be used, compare whether the inserted message is completely consistent with the fields corresponding to the master message in the listpack. If it is completely consistent, it indicates that the message can reuse the master field.
4. Insert the message content to be inserted into the new listpack or the listpack corresponding to the last key node of the original rax.
New consumption group
/* Create a new consumer group in the context of the stream 's', having the
* specified name and last server ID. If a consumer group with the same name
* already existed NULL is returned, otherwise the pointer to the consumer
* group is returned. */
streamCG *streamCreateCG(stream *s, char *name, size_t namelen, streamID *id) {
if (s->cgroups == NULL) s->cgroups = raxNew();
if (raxFind(s->cgroups,(unsigned char*)name,namelen) != raxNotFound)
return NULL;
streamCG *cg = zmalloc(sizeof(*cg));
cg->pel = raxNew();
cg->consumers = raxNew();
cg->last_id = *id;
raxInsert(s->cgroups,(unsigned char*)name,namelen,cg,NULL);
return cg;
}
Add a new consumption group for the message flow, take the name of the consumption group as the key, and put the streamCG structure of the consumption group as value into rax.
removal message
/* Remove the current entry from the stream: can be called after the
* GetID() API or after any GetField() call, however we need to iterate
* a valid entry while calling this function. Moreover the function
* requires the entry ID we are currently iterating, that was previously
* returned by GetID().
*
* Note that after calling this function, next calls to GetField() can't
* be performed: the entry is now deleted. Instead the iterator will
* automatically re-seek to the next entry, so the caller should continue
* with GetID(). */
void streamIteratorRemoveEntry(streamIterator *si, streamID *current) {
unsigned char *lp = si->lp;
int64_t aux;
/* We do not really delete the entry here. Instead we mark it as
* deleted flagging it, and also incrementing the count of the
* deleted entries in the listpack header.
*
* We start flagging: */
int flags = lpGetInteger(si->lp_flags);
flags |= STREAM_ITEM_FLAG_DELETED;
lp = lpReplaceInteger(lp,&si->lp_flags,flags);
/* Change the valid/deleted entries count in the master entry. */
unsigned char *p = lpFirst(lp);
aux = lpGetInteger(p);
if (aux == 1) {
/* If this is the last element in the listpack, we can remove the whole
* node. */
lpFree(lp);
raxRemove(si->stream->rax,si->ri.key,si->ri.key_len,NULL);
} else {
/* In the base case we alter the counters of valid/deleted entries. */
lp = lpReplaceInteger(lp,&p,aux-1);
p = lpNext(lp,p); /* Seek deleted field. */
aux = lpGetInteger(p);
lp = lpReplaceInteger(lp,&p,aux+1);
/* Update the listpack with the new pointer. */
if (si->lp != lp)
raxInsert(si->stream->rax,si->ri.key,si->ri.key_len,lp,NULL);
}
/* Update the number of entries counter. */
si->stream->length--;
/* Re-seek the iterator to fix the now messed up state. */
streamID start, end;
if (si->rev) {
streamDecodeID(si->start_key,&start);
end = *current;
} else {
start = *current;
streamDecodeID(si->end_key,&end);
}
streamIteratorStop(si);
streamIteratorStart(si,si->stream,&start,&end,si->rev);
/* TODO: perform a garbage collection here if the ration between
* deleted and valid goes over a certain limit. */
}
This operation only sets the flag bit of the message to be removed as deleted, and will not really delete it. Nodes are released from rax only when an entire listpack is deleted.
Crop information flow
What's the meaning of this? For example: I only left the last ten messages. That's what I mean.
/* Trim the stream 's' to have no more than maxlen elements, and return the
* number of elements removed from the stream. The 'approx' option, if non-zero,
* specifies that the trimming must be performed in a approximated way in
* order to maximize performances. This means that the stream may contain
* more elements than 'maxlen', and elements are only removed if we can remove
* a *whole* node of the radix tree. The elements are removed from the head
* of the stream (older elements).
*
* The function may return zero if:
*
* 1) The stream is already shorter or equal to the specified max length.
* 2) The 'approx' option is true and the head node had not enough elements
* to be deleted, leaving the stream with a number of elements >= maxlen.
*/
int64_t streamTrimByLength(stream *s, size_t maxlen, int approx) {
if (s->length <= maxlen) return 0;
raxIterator ri;
raxStart(&ri,s->rax);
raxSeek(&ri,"^",NULL,0);
int64_t deleted = 0;
while(s->length > maxlen && raxNext(&ri)) {
unsigned char *lp = ri.data, *p = lpFirst(lp);
int64_t entries = lpGetInteger(p);
/* Check if we can remove the whole node, and still have at
* least maxlen elements. */
if (s->length - entries >= maxlen) {
lpFree(lp);
raxRemove(s->rax,ri.key,ri.key_len,NULL);
raxSeek(&ri,">=",ri.key,ri.key_len);
s->length -= entries;
deleted += entries;
continue;
}
/* If we cannot remove a whole element, and approx is true,
* stop here. */
if (approx) break;
/* Otherwise, we have to mark single entries inside the listpack
* as deleted. We start by updating the entries/deleted counters. */
int64_t to_delete = s->length - maxlen;
serverAssert(to_delete < entries);
lp = lpReplaceInteger(lp,&p,entries-to_delete);
p = lpNext(lp,p); /* Seek deleted field. */
int64_t marked_deleted = lpGetInteger(p);
lp = lpReplaceInteger(lp,&p,marked_deleted+to_delete);
p = lpNext(lp,p); /* Seek num-of-fields in the master entry. */
/* Skip all the master fields. */
int64_t master_fields_count = lpGetInteger(p);
p = lpNext(lp,p); /* Seek the first field. */
for (int64_t j = 0; j < master_fields_count; j++)
p = lpNext(lp,p); /* Skip all master fields. */
p = lpNext(lp,p); /* Skip the zero master entry terminator. */
/* 'p' is now pointing to the first entry inside the listpack.
* We have to run entry after entry, marking entries as deleted
* if they are already not deleted. */
while(p) {
int flags = lpGetInteger(p);
int to_skip;
/* Mark the entry as deleted. */
if (!(flags & STREAM_ITEM_FLAG_DELETED)) {
flags |= STREAM_ITEM_FLAG_DELETED;
lp = lpReplaceInteger(lp,&p,flags);
deleted++;
s->length--;
if (s->length <= maxlen) break; /* Enough entries deleted. */
}
p = lpNext(lp,p); /* Skip ID ms delta. */
p = lpNext(lp,p); /* Skip ID seq delta. */
p = lpNext(lp,p); /* Seek num-fields or values (if compressed). */
if (flags & STREAM_ITEM_FLAG_SAMEFIELDS) {
to_skip = master_fields_count;
} else {
to_skip = lpGetInteger(p);
to_skip = 1+(to_skip*2);
}
while(to_skip--) p = lpNext(lp,p); /* Skip the whole entry. */
p = lpNext(lp,p); /* Skip the final lp-count field. */
}
/* Here we should perform garbage collection in case at this point
* there are too many entries deleted inside the listpack. */
entries -= to_delete;
marked_deleted += to_delete;
if (entries + marked_deleted > 10 && marked_deleted > entries/2) {
/* TODO: perform a garbage collection. */
}
/* Update the listpack with the new pointer. */
raxInsert(s->rax,ri.key,ri.key_len,lp,NULL);
break; /* If we are here, there was enough to delete in the current
node, so no need to go to the next node. */
}
raxStop(&ri);
return deleted;
}
The approx parameter means whether there can be deviation.
1. If the current node is deleted and there are more messages, delete.
2. If the current node is deleted, and the message is not enough, it can be deleted again.
----a. If approx is not 0, it does not move
----b. If approx is not set, the "deleted" flag is set until just enough.
Release consumer group
/* Free a consumer group and all its associated data. */
void streamFreeCG(streamCG *cg) {
raxFreeWithCallback(cg->pel,(void(*)(void*))streamFreeNACK);
raxFreeWithCallback(cg->consumers,(void(*)(void*))streamFreeConsumer);
zfree(cg);
}
Find element
1. Find the message through the iterator
2. Find the consumption group through the interface
3. Find consumer: if it does not exist, select Add
/* Lookup the consumer with the specified name in the group 'cg': if the
* consumer does not exist it is automatically created as a side effect
* of calling this function, otherwise its last seen time is updated and
* the existing consumer reference returned. */
streamConsumer *streamLookupConsumer(streamCG *cg, sds name, int flags) {
int create = !(flags & SLC_NOCREAT);
int refresh = !(flags & SLC_NOREFRESH);
streamConsumer *consumer = raxFind(cg->consumers,(unsigned char*)name,
sdslen(name));
if (consumer == raxNotFound) {
if (!create) return NULL;
consumer = zmalloc(sizeof(*consumer));
consumer->name = sdsdup(name);
consumer->pel = raxNew();
raxInsert(cg->consumers,(unsigned char*)name,sdslen(name),
consumer,NULL);
}
if (refresh) consumer->seen_time = mstime();
return consumer;
}