Comparison process
In LevelDB, there are two main types of comparison:
- Minor compact: This is the process of immutable persistence to Level 0. The most important requirement here is high performance, because once it is blocked, memtable cannot be written, but is there any way to convert it to immutable.
- major compaction: it is responsible for merging sstable and on the disk. Every time it is merged, the data in sstable will fall to the lower Level, and the data will be merged to the lower Level slowly
The following effects can be achieved through comparison:
- Data in memory is persisted to disk
- Clean up honor data
- The data in the file layer below Level 0 can be kept in order through compaction, so that the data can be searched through bisection. At the same time, the number of files to be searched can be reduced and the reading efficiency can be improved
minor compaction
The following minor competition was also introduced just now. In order to improve the speed of data persistence, the repetition and order of different files will not be considered when persisting immutable, which also makes the process a little easier.
1) Time to trigger minor compaction
When the size of memtable in memory is less than the configured threshold, the data will be directly updated to memtable. After exceeding the size, the memtable will be converted to immutable. At this time, a background thread will be responsible for persisting the immutable to the SSTable file of disk Level 0.
This process is implemented in the previously described DBImpl::MakeRoomForWrite:
Status DBImpl::MakeRoomForWrite(bool force) {
...
//Convert memtable to immutable
imm_ = mem_;
has_imm_.store(true, std::memory_order_release);
//Apply for a new memtable
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
//Trigger merge operation
MaybeScheduleCompaction();
}
}
return s;
}
Here we can see that the function dbimpl:: maybschedulecomposition is called, which will add DBImpl::BGWork to the execution schedule of the background thread. This DBImpl::BGWork will call DBImpl::BackgroundCall, and this DBImpl::BackgroundCall will call the function dbimpl:: backgroundcomparison. In this function, the merge function DBImpl::CompactMemTable will be called.
2) Drop immutable memtable into SSTable
DBImpl::CompactMemTable will call the function WriteLevel0Table, in which immutable will be dropped:
void DBImpl::CompactMemTable() {
mutex_.AssertHeld();
assert(imm_ != nullptr);
// Save the contents of the memtable as a new Table
VersionEdit edit;
Version* base = versions_->current();
base->Ref();
Status s = WriteLevel0Table(imm_, &edit, base);
base->Unref();
if (s.ok() && shutting_down_.load(std::memory_order_acquire)) {
s = Status::IOError("Deleting DB during memtable compaction");
}
// Replace immutable memtable with the generated Table
if (s.ok()) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
//Record edit information
s = versions_->LogAndApply(&edit, &mutex_);
}
if (s.ok()) {
// Commit to the new state
//Release imm_ space
imm_->Unref();
imm_ = nullptr;
has_imm_.store(false, std::memory_order_release);
//Clean up invalid files
RemoveObsoleteFiles();
} else {
RecordBackgroundError(s);
}
}
While WriteLevel0Table drops immutable, it will record the file information into edit, which saves the meta information of the file. It should be mentioned here that if the newly generated SSTable file is not always placed on the Level 0 layer, if the key of the newly generated SSTable does not overlap with all the files on the current Level 1 layer, the file will be directly placed on the Level 1 layer.
Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit,
Version* base) {
mutex_.AssertHeld();
const uint64_t start_micros = env_->NowMicros();
//Generate sstable number to build file name
FileMetaData meta;
meta.number = versions_->NewFileNumber();
pending_outputs_.insert(meta.number);
Iterator* iter = mem->NewIterator();
Log(options_.info_log, "Level-0 table #%llu: started",
(unsigned long long)meta.number);
Status s;
{
mutex_.Unlock();
//Update all data in memtable to XXX LDB file tracking
//Meta record key range, file_size and other meta information
s = BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);
mutex_.Lock();
}
Log(options_.info_log, "Level-0 table #%llu: %lld bytes %s",
(unsigned long long)meta.number, (unsigned long long)meta.file_size,
s.ToString().c_str());
delete iter;
pending_outputs_.erase(meta.number);
// Note that if file_size is zero, the file has been deleted and
// should not be added to the manifest.
int level = 0;
if (s.ok() && meta.file_size > 0) {
const Slice min_user_key = meta.smallest.user_key();
const Slice max_user_key = meta.largest.user_key();
if (base != nullptr) {
//Select the appropriate level for the newly generated sstable. In fact, this is the process of comparing the maximum key with the minimum key
level = base->PickLevelForMemTableOutput(min_user_key, max_user_key);
}
//Level and file meta are recorded to edit, which is actually recorded to a vector < [int] level, [filemetadata] File >
edit->AddFile(level, meta.number, meta.file_size, meta.smallest,
meta.largest);
}
CompactionStats stats;
stats.micros = env_->NowMicros() - start_micros;
stats.bytes_written = meta.file_size;
stats_[level].Add(stats);
return s;
}
3) Record the edit information to version
After the WriteLevel0Table is executed, the newly generated edit information will be recorded in Version (version is the meta information of the whole LevelDB). The current version is the latest state of the database, and subsequent operations will be based on this state.
void DBImpl::CompactMemTable() {
...
// Replace immutable memtable with the generated Table
if (s.ok()) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
//Record edit information
s = versions_->LogAndApply(&edit, &mutex_);
}
if (s.ok()) {
// Commit to the new state
//Release imm_ space
imm_->Unref();
imm_ = nullptr;
has_imm_.store(false, std::memory_order_release);
//Clean up invalid files
RemoveObsoleteFiles();
} else {
RecordBackgroundError(s);
}
}
major compaction
An obvious advantage of the design of major competition is that it can clean up redundant data and save disk space, because the data previously marked for deletion can be cleaned up in the process of major competition.
The data files in Level 0 are out of order, but after being merged into Level 1, the data becomes orderly, which reduces the number of files to be queried in the read operation. Therefore, another advantage of major compaction is that it can improve the reading efficiency.
1) Time to trigger major compaction
- Level 0: the number of SSTable files exceeds the specified number
- Level i: the total sstable size of level i exceeds 10iMB. The higher the level, the colder the data, and the smaller the probability of reading.
- There is also a seek limit for sstable files. If the file seeks multiple times but no data is found, it should be merged.
The above logic is embodied in the function VersionSet::Finalize,
void VersionSet::Finalize(Version* v) {
// Precomputed best level for next compaction
int best_level = -1;
double best_score = -1;
for (int level = 0; level < config::kNumLevels - 1; level++) {
double score;
if (level == 0) {
//If it is level 0, directly judge whether there are more than 4 level 0 files, kL0_CompactionTrigger=4
score = v->files_[level].size() /
static_cast<double>(config::kL0_CompactionTrigger);
} else {
// TotalFileSize gets the total file size of this layer
const uint64_t level_bytes = TotalFileSize(v->files_[level]);
// Other layers calculate whether the file space occupied by this layer is greater than the limit
score =
static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level);
}
if (score > best_score) {
best_level = level;
best_score = score;
}
}
//The current number of layers and score are recorded here. If the score is greater than 1, it means to merge
v->compaction_level_ = best_level;
v->compaction_score_ = best_score;
}
2) compaction process
- Select the appropriate level and sstable for merging. This process takes place in versionset:: pickcomparison
Filter files by size_compaction rule, or seek_ The compaction rule calculates the files that should be merged.
The first is based on the score just calculated. If the score is greater than 1, it means to merge. We put size_ Set compaction to true. After that, put the file meta information pointer FileMetaData into inputs[0].
const bool size_compaction = (current_->compaction_score_ >= 1);
const bool seek_compaction = (current_->file_to_compact_ != nullptr);
if (size_compaction) {
level = current_->compaction_level_;
assert(level >= 0);
assert(level + 1 < config::kNumLevels);
c = new Compaction(options_, level);
// Pick the first file that comes after compact_pointer_[level]
for (size_t i = 0; i < current_->files_[level].size(); i++) {
FileMetaData* f = current_->files_[level][i];
if (compact_pointer_[level].empty() ||
icmp_.Compare(f->largest.Encode(), compact_pointer_[level]) > 0) {
c->inputs_[0].push_back(f);
break;
}
}
if (c->inputs_[0].empty()) {
// Wrap-around to the beginning of the key space
c->inputs_[0].push_back(current_->files_[level][0]);
}
} else if (seek_compaction) {
level = current_->file_to_compact_level_;
c = new Compaction(options_, level);
c->inputs_[0].push_back(current_->file_to_compact_);
} else {
return nullptr;
}
For seek_compaction is to maintain an allowed for each new SSTable file_ The initial threshold of seek, which indicates the maximum number of seek miss es tolerated when allowed_ When the seeks decreases to less than 0, the corresponding file will be marked as requiring compact.
bool Version::UpdateStats(const GetStats& stats) {
FileMetaData* f = stats.seek_file;
if (f != nullptr) {
f->allowed_seeks--;
if (f->allowed_seeks <= 0 && file_to_compact_ == nullptr) {
file_to_compact_ = f;
file_to_compact_level_ = stats.seek_file_level;
return true;
}
}
return false;
}
- Expand the set of input files according to the overlap of key s
The basic idea of expanding the set of input files according to the key overlap is that all overlapping level+1 files should participate in compact. After obtaining these files, turn to see if you can continue to add level+1 files without adding level+1 files. The specific steps are as follows:
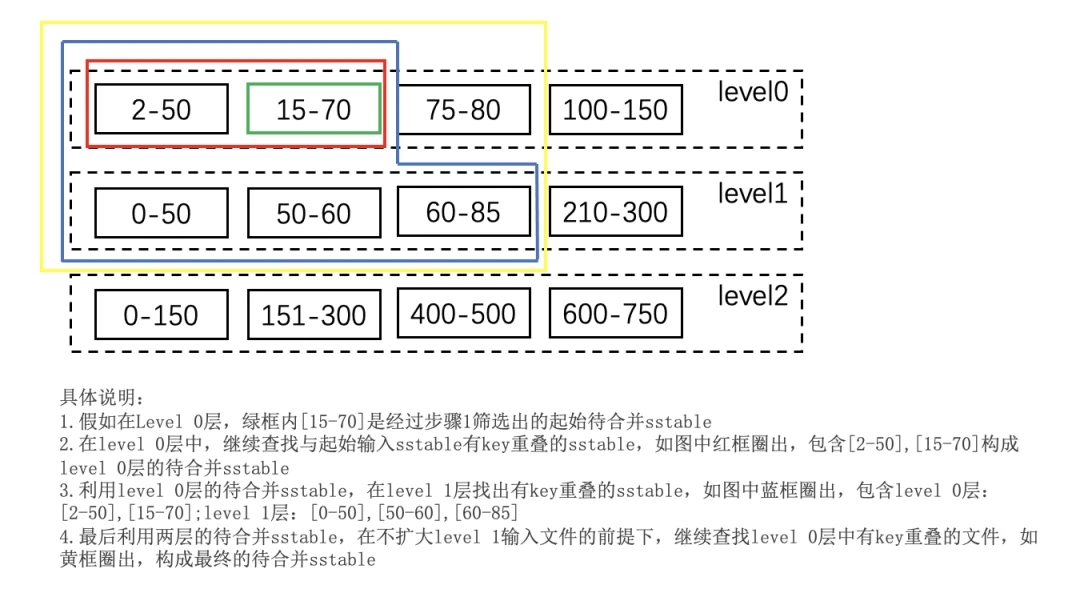
This process occurs in the function Version::GetOverlappingInputs and the function VersionSet::SetupOtherInputs. Among them, Version::GetOverlappingInputs is responsible for expanding the scope of Level 0 layer, and VersionSet::SetupOtherInputs is responsible for expanding the scope of other layers. All functions are called in versionset:: pickcomparison:
void Version::GetOverlappingInputs(int level, const InternalKey* begin,
const InternalKey* end,
std::vector<FileMetaData*>* inputs) {
assert(level >= 0);
assert(level < config::kNumLevels);
inputs->clear();
Slice user_begin, user_end;
if (begin != nullptr) {
user_begin = begin->user_key();
}
if (end != nullptr) {
user_end = end->user_key();
}
const Comparator* user_cmp = vset_->icmp_.user_comparator();
for (size_t i = 0; i < files_[level].size();) {
FileMetaData* f = files_[level][i++];
const Slice file_start = f->smallest.user_key();
const Slice file_limit = f->largest.user_key();
if (begin != nullptr && user_cmp->Compare(file_limit, user_begin) < 0) {
// "f" is completely before specified range; skip it
} else if (end != nullptr && user_cmp->Compare(file_start, user_end) > 0) {
// "f" is completely after specified range; skip it
} else {
inputs->push_back(f);
if (level == 0) {
// Level-0 files may overlap each other. So check if the newly
// added file has expanded the range. If so, restart search.
if (begin != nullptr && user_cmp->Compare(file_start, user_begin) < 0) {
user_begin = file_start;
inputs->clear();
i = 0;
} else if (end != nullptr &&
user_cmp->Compare(file_limit, user_end) > 0) {
user_end = file_limit;
inputs->clear();
i = 0;
}
}
}
}
}
After the level and level+1 layers are merged and compressed, the final file is to be placed in level+1 layer. Obtain the compressed key range [all_start, all_limit] in the method SetupOtherInputs, and query the SSTable of the overlap of level+2 and level+1 layers for storage and grandparents_ Yes.
- Multiple Merge
Multi way merging will sort out the data in the sstable to be merged selected in the previous step in order. After sorting in order, it will enter the function dbimpl:: docompactionwork (the call point is in dbimpl:: backgroundcomparison). This function will call the VersionSet::MakeInputIterator function and return an iterator object. By traversing the iterator object, you can get all the ordered key sets.
Iterator* VersionSet::MakeInputIterator(Compaction* c) {
ReadOptions options;
options.verify_checksums = options_->paranoid_checks;
options.fill_cache = false;
// Level-0 files have to be merged together. For other levels,
// we will make a concatenating iterator per level.
// TODO(opt): use concatenating iterator for level-0 if there is no overlap
const int space = (c->level() == 0 ? c->inputs_[0].size() + 1 : 2);
//list stores all iterators
Iterator** list = new Iterator*[space];
int num = 0;
for (int which = 0; which < 2; which++) {
if (!c->inputs_[which].empty()) {
//Level 0
if (c->level() + which == 0) {
const std::vector<FileMetaData*>& files = c->inputs_[which];
for (size_t i = 0; i < files.size(); i++) {
list[num++] = table_cache_->NewIterator(options, files[i]->number,
files[i]->file_size);
}
} else {
// Create concatenating iterator for the files from this level
list[num++] = NewTwoLevelIterator(
new Version::LevelFileNumIterator(icmp_, &c->inputs_[which]),
&GetFileIterator, table_cache_, options);
}
}
}
assert(num <= space);
Iterator* result = NewMergingIterator(&icmp_, list, num);
delete[] list;
return result;
}
The following process is to traverse the keys in all SSTable files that need to be Compact. Valid keys are written to the new SSTable file, and invalid keys are discarded. Delete the useless SSTable after writing. The detailed description has been commented in the code.
//Compact works.
//1. Create the input[0] and input[1] files of the Compact to be accessed as iterators
//2.Seek to the minimum keys of the iterator, and start cyclic access to these keys and Compact.
//3. During the cycle, if there is immutable, give priority to Compact.
//4. Judge whether the key corresponding to the file currently preparing Compact needs to stop Compact in advance, and land the current file as SSTable.
Status DBImpl::DoCompactionWork(CompactionState* compact) {
const uint64_t start_micros = env_->NowMicros();
int64_t imm_micros = 0; // Micros spent doing imm_ compactions
Log(options_.info_log, "Compacting %d@%d + %d@%d files",
compact->compaction->num_input_files(0), compact->compaction->level(),
compact->compaction->num_input_files(1),
compact->compaction->level() + 1);
assert(versions_->NumLevelFiles(compact->compaction->level()) > 0);
assert(compact->builder == nullptr);
assert(compact->outfile == nullptr);
if (snapshots_.empty()) {
compact->smallest_snapshot = versions_->LastSequence();
} else {
//If a snapshot is used externally (GetSnapShot), the corresponding SnapShotImpl object of the snapshot will be placed
//In the snapshot list (that is, the sequence_number is saved), when comparing
//When you encounter data that can be cleaned up, you also need to judge the SEQ of the data to be cleaned up_ Number cannot be greater than the number in these snapshots
//sequence_number, otherwise it will affect the exaggerated data.
compact->smallest_snapshot = snapshots_.oldest()->sequence_number();
}
Iterator* input = versions_->MakeInputIterator(compact->compaction);
// Release mutex while we're actually doing the compaction work
mutex_.Unlock();
//Here, the loop traversal of the input iterator is to get the smallest key in the iterator each time,
//Key refers to InternalKey, and key comparator refers to InternalKeyComparator,
//InternalKey is compared with the user in the InternalKey_ Key press BytewiseComparator to compare.
//In user_ When the key is the same, compare by SequenceNumber. The value of SequenceNumber is larger than that of SequenceNumber,
//So for abc_456_1,abc_123_2,abc_456_1 is less than abc_123_2. For the same user_key operation,
//The latest operation on this key is smaller than the previous operation on this key.
input->SeekToFirst();
Status status;
ParsedInternalKey ikey;
std::string current_user_key;
bool has_current_user_key = false;
SequenceNumber last_sequence_for_key = kMaxSequenceNumber;
while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) {
// Prioritize immutable compaction work
//Check and preferentially compact the existing immutable memtable.
if (has_imm_.load(std::memory_order_relaxed)) {
const uint64_t imm_start = env_->NowMicros();
mutex_.Lock();
if (imm_ != nullptr) {
CompactMemTable();
// Wake up MakeRoomForWrite() if necessary.
background_work_finished_signal_.SignalAll();
}
mutex_.Unlock();
imm_micros += (env_->NowMicros() - imm_start);
}
Slice key = input->key();
//If the generation threshold of the internal size and the internalparent layer exceeds the current threshold,
//Then stop the current SSTable check, directly land and stop traversal.
if (compact->compaction->ShouldStopBefore(key) &&
compact->builder != nullptr) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
// Handle key/value, add to state, etc.
//Determine whether to discard the current key
bool drop = false;
if (!ParseInternalKey(key, &ikey)) {
//Failed to resolve key.
//For key s that fail to resolve, they are not discarded here and stored directly.
//The purpose is not to hide such errors and store them in SSTable,
//Facilitate subsequent logic processing.
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
//InternalKey parsing succeeded.
if (!has_current_user_key ||
user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) !=0) {
//The two internalkeys detected before and after are different,
//Then record the first key,
//And last_ sequence_ for_ Set key to maximum.
// First occurrence of this user key
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
last_sequence_for_key = kMaxSequenceNumber;
}
//If the two keys are different, last_sequence_for_key will be assigned as kMaxSequenceNumber,
if (last_sequence_for_key <= compact->smallest_snapshot) {
//Enter this logic to explain last_sequence_for_key is not the maximum value kMaxSequenceNumber,
//That is, the user of the current key_ Key (an old user key) and the user of the previous key_ The key is the same.
//So just throw it away here.
// Hidden by an newer entry for same user key
drop = true; // (A)
} else if (ikey.type == kTypeDeletion &&
ikey.sequence <= compact->smallest_snapshot &&
compact->compaction->IsBaseLevelForKey(ikey.user_key)) {
//If the InternalKey meets the following three conditions, it can be discarded directly.
//1. It's a Deletionkey.
//2.sequence <= small_snaphshot.
//3. The current level of compact is level-n and level-n+1,
// If there is no user corresponding to this InternalKey in the layer above level-n+1_ Key.
//It can be deleted based on the above three situations.
//Why use this condition (IsBaseLevelForKey) to judge?
//for instance:
//If you are at a higher level, there is also a user corresponding to this InternalKey_ key,
//When you delete the current InternalKey, there will be two problems:
//Question 1: when the deleted key is read again, the old expired key will be read (the type of the key is non deletion). This is a problem.
//Question 2: when merging again, but the key (the type of the key is non deletion) is read for the first time, last_sequence_for_key will be set to kMaxSequenceNumber,
// So it won't be discarded.
//The above two problems seem to be OK when the type of all userkey s of the old key is delete,
//But this is a minority after all. In principle, for the normal operation of the system, every time we discard a key marked kTypeDeletion,
//It must be ensured that there is no expired key in the database, otherwise it must be retained until it is merged with the expired key, and then discarded
// For this user key:
// (1) there is no data in higher levels
// (2) data in lower levels will have larger sequence numbers
// (3) data in layers that are being compacted here and have
// smaller sequence numbers will be dropped in the next
// few iterations of this loop (by rule (A) above).
// Therefore this deletion marker is obsolete and can be dropped.
drop = true;
}
last_sequence_for_key = ikey.sequence;
}
#if 0
Log(options_.info_log,
" Compact: %s, seq %d, type: %d %d, drop: %d, is_base: %d, "
"%d smallest_snapshot: %d",
ikey.user_key.ToString().c_str(),
(int)ikey.sequence, ikey.type, kTypeValue, drop,
compact->compaction->IsBaseLevelForKey(ikey.user_key),
(int)last_sequence_for_key, (int)compact->smallest_snapshot);
#endif
//Write key s that are not discarded
if (!drop) {
//1. Open SSTable file
// Open output file if necessary
if (compact->builder == nullptr) {
status = OpenCompactionOutputFile(compact);
if (!status.ok()) {
break;
}
}
//For the key to be written, from input_ When removed,
//It should be the current entire input_ The smallest key in (here should reflect the benefits of iterator encapsulation).
//That is, writing to SSTable is in ascending order.
if (compact->builder->NumEntries() == 0) {
compact->current_output()->smallest.DecodeFrom(key);
}
compact->current_output()->largest.DecodeFrom(key);
compact->builder->Add(key, input->value());
//If the SSTable to be generated has exceeded a specific threshold, the SSTable file will be landed.
// Close output file if it is big enough
if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
}
input->Next();
}
if (status.ok() && shutting_down_.load(std::memory_order_acquire)) {
status = Status::IOError("Deleting DB during compaction");
}
if (status.ok() && compact->builder != nullptr) {
status = FinishCompactionOutputFile(compact, input);
}
if (status.ok()) {
status = input->status();
}
delete input;
input = nullptr;
CompactionStats stats;
stats.micros = env_->NowMicros() - start_micros - imm_micros;
for (int which = 0; which < 2; which++) {
for (int i = 0; i < compact->compaction->num_input_files(which); i++) {
stats.bytes_read += compact->compaction->input(which, i)->file_size;
}
}
for (size_t i = 0; i < compact->outputs.size(); i++) {
stats.bytes_written += compact->outputs[i].file_size;
}
mutex_.Lock();
stats_[compact->compaction->level() + 1].Add(stats);
if (status.ok()) {
status = InstallCompactionResults(compact);
}
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log, "compacted to: %s", versions_->LevelSummary(&tmp));
return status;
}
reference
[1] Principle analysis of LevelDB: how does data reading, writing and merging happen? (add content to the original text)
[2] [leveldb] Compact (XXIII): major Compact