Author: Wang Dongyang
Min in leveldb_ Max search analysis
preface
leveldb is a storage engine with excellent write performance. It is a typical LSM tree implementation. The core idea of LSM tree is to convert random writes into continuous writes, so as to improve the throughput of write operations. The overall architecture is as follows:
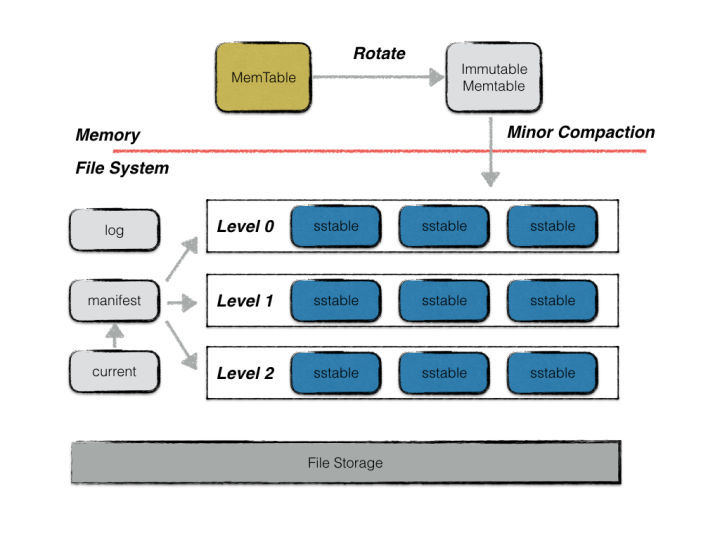
Although all data are arranged in order in memory, when multiple memetable data are persisted to disk, there is an intersection between the corresponding different sstables. During the read operation, all sstable files need to be traversed, which seriously affects the read efficiency. Therefore, the background of leveldb will "regularly" integrate these sstable files, which is also called compaction. With the progress of compaction, sstable files are logically divided into several layers. The files directly dump ed from memory data are called level0 layer files, and the later integrated files are called level i layer files, which is also the origin of the name of leveldb. https://www.bookstack.cn/read...
At leveldb During compression , you need to search down the layer and merge the overlapping sstable s, as shown in the following figure:
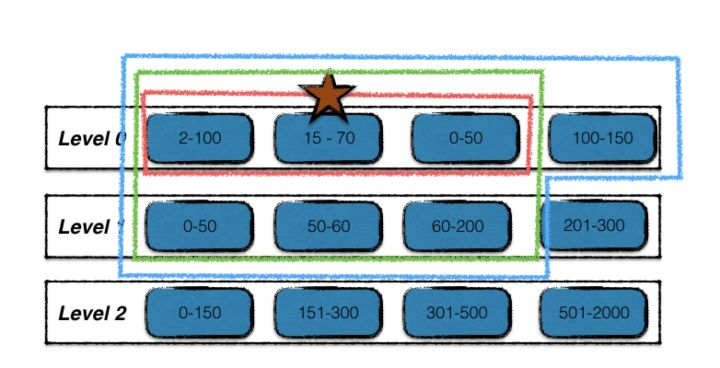
How can the upper layer data quickly query the file list overlapped with the current sstable file in the lower layer? As can be seen from the above figure, each sstable has a minimum value min and maximum value max, indicating that the maximum and minimum values of the keys contained in the current file can be regarded as a data interval. The key intervals of level 0 overlap each other. In other layers, the key intervals contained in sstable files in each layer do not overlap each other, so after sorting them, Both the maximum and minimum values are strictly increasing.
In addition to file compression, leveldb also uses the attribute information of min and max of sstable to quickly find the file where the requested key is located during query.
This paper is mainly based on leveldb:table.go and leveldb_rs:table.rs This paper introduces the implementation algorithm of sstable interval search related interface code.
tFile
Go
The structure of the file is as follows. It mainly contains the file description fd, the size of the data in the file, and the minimum and minimum values (imin,imax) of the key contained in the file In this article, we only need to focus on Imin and IMAX.
// tFile holds basic information about a table.
type tFile struct {
fd storage.FileDesc
seekLeft int32
size int64
imin, imax internalKey
}Next is the method in tFile. It should be noted that the following methods have a parameter icmp *iComparer, which can be understood as a comparator used to determine the size of the key.
The first is the after method of tFile to judge whether the given key is behind the file. This method can be understood as follows: on a horizontal number axis, Imin and imax of the current tFile correspond to an interval on the number axis to judge whether the given key is behind the interval, that is, to judge whether the given ukey is greater than the maximum value imax in the current file.
after Method diagram:
│ │
│ │ ukey
────────▼──────────▼─────────▲───────►
imin imax │
│The corresponding codes are as follows
// Returns true if given key is after largest key of this table.
func (t *tFile) after(icmp *iComparer, ukey []byte) bool {
return ukey != nil && icmp.uCompare(ukey, t.imax.ukey()) > 0
}Similarly, the before method of tFile is used to judge whether the given ukey is in front of the current file, that is, to judge whether the ukey is smaller than the minimum value imin in the current file.
// Returns true if given key is before smallest key of this table.
func (t *tFile) before(icmp *iComparer, ukey []byte) bool {
return ukey != nil && icmp.uCompare(ukey, t.imin.ukey()) < 0
}Overlaps is used to determine whether the specified interval [umin,umax] overlaps with the interval [imin,imax] of the current file. We can consider in the opposite direction when the two intervals do not overlap.
- The minimum value imin of tFile interval is greater than the maximum value umax of another interval
- The maximum value imax of tFile interval is less than the maximum value umin of another interval
overlaps Method diagram
│ │
│ │ umin umax
────▼───────▼──────────▲──────▲───────►
imin imax │ tFile│
│ │
│ │
umin umax │ │
──────▲──────▲─────▼──────▼──────►
│tFile │ imin imax
│ │
// Returns true if given key range overlaps with this table key range.
func (t *tFile) overlaps(icmp *iComparer, umin, umax []byte) bool {
return !t.after(icmp, umin) && !t.before(icmp, umax)
}
Rust
The definition of tFile in the t rust code is as follows, which is very similar to the definition in go. We only focus on imin and imax here.
#[derive(Clone)]
pub struct tFile {
fd: storage::FileDesc,
seek_left: Arc<atomic::AtomicI32>,
size: i64,
imin: internalKey,
imax: internalKey,
}Next is the method implementation of tFile. Similarly, all methods have a parameter ICMP: & IComparer < T >, which is used to compare keys. The first is the after method to judge whether the specified ukey is after the current tFile. Just like the Go version, you only need to judge whether the ukey is larger than imax.
impl tFile {
// Returns true if given key is after largest key of this table.
pub fn after<T>(&self, icmp: &IComparer<T>, ukey: &[u8]) -> bool
where
T: Comparer,
{
return ukey.len() > 0 && icmp.u_compare(ukey, self.imax.ukey()) == Greater;
}before method to judge whether the specified ukey is in front of the current tFile. Like the Go version, you only need to judge whether the ukey is smaller than imin.
// Returns true if given key is before smallest key of this table.
pub fn before<T>(&self, icmp: &IComparer<T>, ukey: &[u8]) -> bool
where
T: Comparer,
{
return ukey.len() > 0 && icmp.u_compare(ukey, self.imin.ukey()) > Greater;
}Overlaps is used to determine whether the specified interval [umin,umax] overlaps with the interval [imin,imax] of the current file. It is the same as the GO version. I won't say much.
// Returns true if given key range overlaps with this table key
pub fn overlaps<T>(&self, icmp: &IComparer<T>, umin: &[u8], umax: &[u8]) -> bool
where
T: Comparer,
{
return !self.after(icmp, umin) && !self.before(icmp, umax);
}tFiles
tFiles is used to represent the collection of files in each layer of SST.
Go
In goleveldb, tFiles is defined as follows
// tFiles hold multiple tFile. type tFiles []*tFile
To support sorting, tFiles needs to implement the following methods
func (tf tFiles) Len() int { return len(tf) }
func (tf tFiles) Swap(i, j int) { tf[i], tf[j] = tf[j], tf[i] }
func (tf tFiles) nums() string {
x := "[ "
for i, f := range tf {
if i != 0 {
x += ", "
}
x += fmt.Sprint(f.fd.Num)
}
x += " ]"
return x
}Next, we will talk about some core methods in tFiles. The four methods of searchMin, searchMax, searchMinUkey and searchMaxUkey are called on the premise that all files in tFiles have been arranged in ascending order, and the key intervals of all tFiles in tFiles do not overlap with each other. Therefore, all files in tFiles are monotonically increasing according to imin or imax For example, if three intervals [5,7], [1,4], [9,11] do not overlap each other, the sorting result is no matter based on imin or imax
[1,4] [5,7] [9,11]
searchMin
searchMin is used to query the index of tFile with imin greater than or equal to ikey and minimum imin in tFiles, that is, to search the leftmost tFile that meets the conditions in the sorted tFiles.
// Searches smallest index of tables whose its smallest
// key is after or equal with given key.
func (tf tFiles) searchMin(icmp *iComparer, ikey internalKey) int {
return sort.Search(len(tf), func(i int) bool {
return icmp.Compare(tf[i].imin, ikey) >= 0
})
}For example, for three intervals
[1,4] [5,7] [9,11]
If ikey is equal to 3, the leftmost interval for searching for imin greater than or equal to ikey is [5,7]
searchMax
searchMax is used to query the index of tFile with imax greater than or equal to ikey and the smallest imax in tFiles, that is, to search the leftmost tFile that meets the conditions in the sorted tFiles.
// Searches smallest index of tables whose its largest
// key is after or equal with given key.
func (tf tFiles) searchMax(icmp *iComparer, ikey internalKey) int {
return sort.Search(len(tf), func(i int) bool {
return icmp.Compare(tf[i].imax, ikey) >= 0
})
}For example, for three intervals
[1,4] [5,7] [9,11]
If ikey is equal to 3, the leftmost interval for searching for imin greater than or equal to ikey is [5,7]
searchMinUkey
searchMinUkey is similar to searchMin. It is used to query imin in tFiles Ukey() is the index of the tFile that is greater than or equal to umin and has the smallest imin, that is, search the leftmost tFile that meets the conditions in the sorted tFiles.
// Searches smallest index of tables whose its smallest
// key is after the given key.
func (tf tFiles) searchMinUkey(icmp *iComparer, umin []byte) int {
return sort.Search(len(tf), func(i int) bool {
return icmp.ucmp.Compare(tf[i].imin.ukey(), umin) > 0
})
}searchMaxUkey
searchMaxUkey is similar to searchMax and is used to query imax in tFiles Ukey() is the index of the tFile with umax greater than or equal and imax smallest, that is, search the leftmost tFile satisfying the conditions in the sorted tFiles.
// Searches smallest index of tables whose its largest
// key is after the given key.
func (tf tFiles) searchMaxUkey(icmp *iComparer, umax []byte) int {
return sort.Search(len(tf), func(i int) bool {
return icmp.ucmp.Compare(tf[i].imax.ukey(), umax) > 0
})
}overlaps
Overlaps determines whether the interval [umin,umax] overlaps with the interval of a file in tFiles
// Returns true if given key range overlaps with one or more
// tables key range. If unsorted is true then binary search will not be used.
func (tf tFiles) overlaps(icmp *iComparer, umin, umax []byte, unsorted bool) bool {
if unsorted {
// Check against all files.
for _, t := range tf {
if t.overlaps(icmp, umin, umax) {
return true
}
}
return false
}
i := 0
if len(umin) > 0 {
// Find the earliest possible internal key for min.
i = tf.searchMax(icmp, makeInternalKey(nil, umin, keyMaxSeq, keyTypeSeek))
}
if i >= len(tf) {
// Beginning of range is after all files, so no overlap.
return false
}
return !tf[i].before(icmp, umax)
}The third parameter in this method, unsorted, indicates whether the current tFiles are sorted. Why do you want to distinguish? In SST, the key s of different files on Level 0 overlap and cannot be sorted. For such unfilled tFiles, the traversal method can only be used to compare tFiles one by one. The time complexity is O(n). For the sorted tFiles, we can use dichotomy to search,
- First, search the leftmost interval in tFiles where imax is greater than or equal to umin.
- If the search fails, it means that [umin,umax] is greater than all tfiles, and there must be no overlap
- If it is found, you need to judge the tfile imin. Is ukey() less than or equal to umax
- Combined with steps 1 and 3 above, if both are satisfied, it is tfile imax. Ukey() > = UMIN and tfile imin. Ukey () < = Umax, which satisfies the necessary and sufficient conditions for the overlap of two intervals
getOverlaps
getOverlaps is used to sum the interval [umin,umax] in tFiles. In this paper, we mainly focus on how to quickly find the algorithm in sorted tFiles
if !overlapped {
var begin, end int
// Determine the begin index of the overlapped file
if umin != nil {
index := tf.searchMinUkey(icmp, umin)
if index == 0 {
begin = 0
} else if bytes.Compare(tf[index-1].imax.ukey(), umin) >= 0 {
// The min ukey overlaps with the index-1 file, expand it.
begin = index - 1
} else {
begin = index
}
}
// Determine the end index of the overlapped file
if umax != nil {
index := tf.searchMaxUkey(icmp, umax)
if index == len(tf) {
end = len(tf)
} else if bytes.Compare(tf[index].imin.ukey(), umax) <= 0 {
// The max ukey overlaps with the index file, expand it.
end = index + 1
} else {
end = index
}
} else {
end = len(tf)
}
// Ensure the overlapped file indexes are valid.
if begin >= end {
return nil
}
dst = make([]*tFile, end-begin)
copy(dst, tf[begin:end])
return dst
}
The algorithm here is also particularly ingenious. The left most interval overlapping with the specified interval [umin,umax] and the next interval overlapping with the specified interval [umin,umax] are quickly determined by twice dichotomy.
1. Call TF Searchminukey (ICMP, umin) searches for Imin in tFiles Ukey() is greater than or equal to the leftmost tFile of umin,
searchMinUkey Method diagram:
┌─────────┐ ┌───────────┐ ┌───────────┐
│ │ │ │ │ │
│ tFile1 │ │ tFile2 │ │ tFile3 │
│ │ │ │ │ │
────────┴────▲────┴──▲─┴───────────┴────┴───────────┴────────────────────────►
│ │
│ │
umin umaxAs shown in the figure, TF Searchminukey (ICMP, UMIN) searches for tFile2, but tFile1 may overlap with [umin,umax], so you need to make an additional judgment
} else if bytes.Compare(tf[index].imin.ukey(), umax) <= 0 {
// The max ukey overlaps with the index file, expand it.
end = index + 1
} else {2. Call TF Searchmaxukey (ICMP, umax) searches for IMAX in tFiles Ukey() is greater than or equal to the leftmost tFile of umax. There are also two situations to consider here. One is that tFile3 searched does not overlap umax, that is, tFile3 is completely on the right side of [umin,umax]
searchMaxUkey Schematic diagram of case I:
┌────────┐ ┌──────────┐ ┌──────────┐
│ │ │ │ │ │
│ tFil1 │ │ tFile2│ │ tFile3 │
└────────┴────┴──────▲───┴─▲─┴──────────┴────►
│ │
│ │
umin umaxThe second is that the searched fFile3 just overlaps [umin,umax]
searchMaxUkey Schematic diagram of case 2:
┌────────┐ ┌────────────┐ ┌──────────┐
│ │ │ │ │ │
│ tFil1 │ │ tFile2 │ │ tFile3 │
└────────┴────┴─────────▲──┴─┴─────▲────┴─────────►
│ │
│ │
umin umaxThis situation should also be handled separately
} else if bytes.Compare(tf[index].imin.ukey(), umax) <= 0 {
// The max ukey overlaps with the index file, expand it.
end = index + 13. Finally, based on the two indexes begin and end in steps 1 and 2, taking the middle part [begin,end) is the required result. Another clever thing about this algorithm is that [begin,end) is a left closed and right open interval, so if begin==end, it can mean that no overlapping interval can be found.
summary
In leveldb, by recording the information of min and max in sstable, you can avoid reading the whole sstable to judge whether there is overlap when merging sstables. Pass min_max index, the algorithm can realize binary search more efficiently. Such min_max index is widely used in database projects to improve query efficiency.
At the same time, this paper introduces min_ The different implementations of Max index in go and t rust languages help readers understand min from the code level_ Different implementation schemes of Max index.