1, Seluth overview
Spring Cloud Sleuth The main function is to provide tracking solutions in distributed systems, and compatible support zipkin,You just need to pom The corresponding dependencies can be introduced into the file.
2, Getting started with link tracking Seluth
1. Configuration dependency
Add the following dependencies to all items to be tracked:
<!--sleuth Link tracking-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2. Modify the configuration file and add log output configuration
Each micro service needs to add the above configuration. Start the microservice. After calling, we can observe it on the console sleuth Log output for.

Of which 2707 c11b7b2daffd yes TraceId,Followed by SpanId,One global is called in turn TraceId,String call links. By carefully analyzing the log of each microservice, it is not difficult to see the specific process of the request. Viewing log files is not a good method. When there are more and more microservices, there will be more and more log files Zipkin The logs can be aggregated for visual display and full-text retrieval.
logging:
level:
root: INFO
org.springframework.web.servlet.DispatcherServlet: DEBUG
org.springframework.cloud.sleuth: DEBUG
3, Zipkin overview
Zipkin yes Twitter An open source project based on Google Dapper realization, It is committed to collecting service timing data to solve the delay problem in microservice architecture, including data collection, storage, search and presentation. We can use it to collect the tracking data of the request link on each server and provide the tracking data through it REST API Interface to assist us in querying tracking data to realize the monitoring program of distributed system, Thus, the problem of increasing delay in the system can be found in time, and the root cause of the system performance bottleneck can be found out. In addition to development oriented API In addition to the interface, it also provides convenient UI Component to help us intuitively search tracking information and analyze request link details For example, you can query the processing time of each user's request within a certain period of time. Zipkin Pluggable data storage mode is provided: InMemory,MySql,Cassandra as well as Elasticsearch. Zipkin Divided into two ends, one is Zipkin Server, one is Zipkin Client, which is the application of microservices. The client will configure the server URL Address, once a call between services occurs, will be configured in the microservice Sleuth Listen to your listener, And generate the corresponding Trace and Span Send the information to the server. There are two main ways to send, one is HTTP Message mode and message bus mode, such as RabbitMQ.
Either way, we need to:
- An Eureka service registry. Here we use the previous Eureka project as the registry.
- A Zipkin server.
- Multiple microservices in which Zipkin clients are configured.
4, Deployment and configuration of Zipkin Server
1. Zipkin Server download
from spring boot 2.0 From the beginning, the government no longer supported the use of self built Zipkin Server Instead of service link tracking, it directly provides compiled links jar Bag for us to use. It can be downloaded from the official website,Download address: Click:
Download Zipkin's webUI
What we download here is zipkin-server-2.12.9-exec.jar
2. Start
Find the downloaded Directory: open the command line and enter the following command java -jar zipkin-server-2.12.9-exec.jar start-up Zipkin Server,As shown in the figure below, it indicates success.
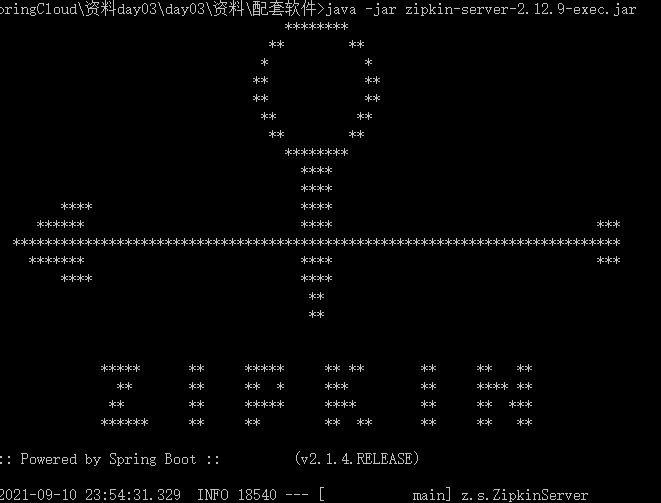
- The default request port of Zipkin Server is 9411
- The startup parameters of Zipkin Server can be provided by the official yml profile lookup
- Enter in the browser http://127.0.0.1:9411 You can enter the management background of Zipkin Server
5, Client Zipkin+Sleuth integration
It is not an intuitive scheme to analyze the calling link of microservices by viewing logs zipkin It can intuitively display the calling relationship between microservices.
(1) Client add dependency
Clients refer to micro services that need to be tracked
<!--introduce zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
(2) Modify the client configuration file and add the following contents under the spring configuration node of the yml file:
#Information about configuring zipkin
zipkin:
base-url: http://127.0.0.1:9411 # set the request address of zipking server
sender:
type: web #The data transmission mode is set to send data to the server in the form of http
sleuth:
sampler:
probability: 1 #Set the sampling ratio of zipkin. 1 means 100% extraction, and 0.1 means only 10% extraction
The zipkin server address is specified. The percentage to be sampled is set below. The default value is 0.1, i.e. 10%. 1 is configured here to record all sleuth information in order to collect more data (for test only). In the distributed system, too frequent sampling will affect the system performance, so an appropriate value should be adopted for the configuration here.
(3) Testing
Start each micro service and Zipkin Service. Send a microservice request through the browser. Open the Zipkin Service console, and we can track the calling process of each request according to the conditions
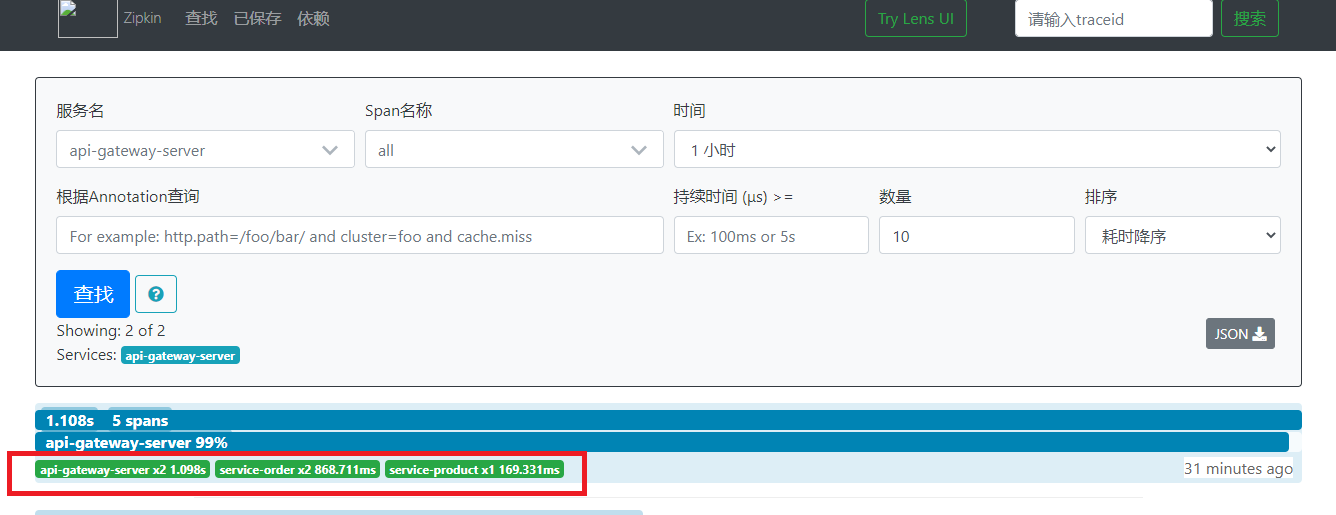
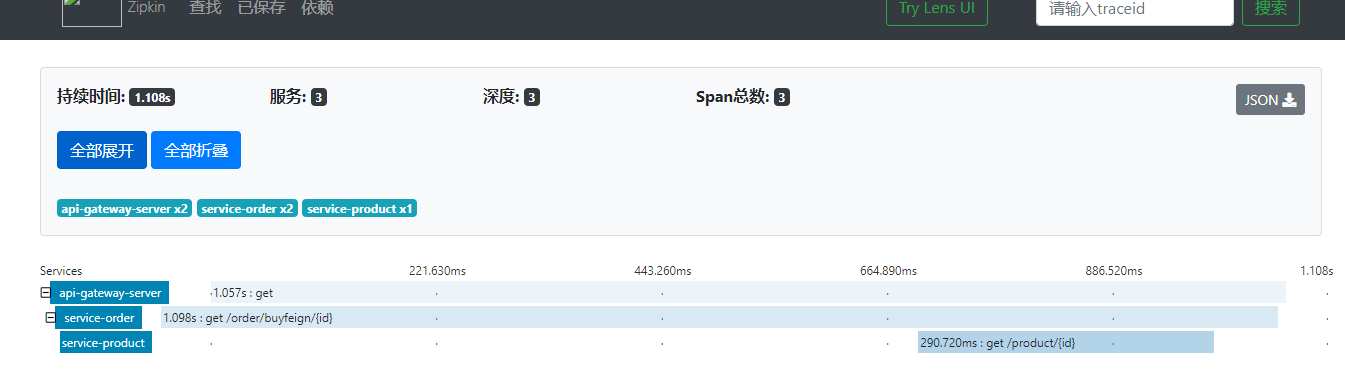
Click the trace to see the details of the request
Six link data persistence – store to MySQL database
1. Obtain the data table creation statement from the zipkin official website. The script is as follows:
/* SQLyog Ultimate v11.33 (64 bit) MySQL - 5.5.58 : Database - zipkin ********************************************************************* */ /*!40101 SET NAMES utf8 */; /*!40101 SET SQL_MODE=''*/; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; CREATE DATABASE /*!32312 IF NOT EXISTS*/`zipkin` /*!40100 DEFAULT CHARACTER SET utf8 */; USE `zipkin`; /*Table structure for table `zipkin_annotations` */ DROP TABLE IF EXISTS `zipkin_annotations`; CREATE TABLE `zipkin_annotations` ( `trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` bigint(20) NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` varchar(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` blob COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` int(11) NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` bigint(20) DEFAULT NULL COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` int(11) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` binary(16) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` smallint(6) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` varchar(255) DEFAULT NULL COMMENT 'Null when Binary/Annotation.endpoint is null', UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`span_id`,`a_key`,`a_timestamp`) COMMENT 'Ignore insert on duplicate', KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`span_id`) COMMENT 'for joining with zipkin_spans', KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTraces/ByIds', KEY `endpoint_service_name` (`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames', KEY `a_type` (`a_type`) COMMENT 'for getTraces', KEY `a_key` (`a_key`) COMMENT 'for getTraces', KEY `trace_id` (`trace_id`,`span_id`,`a_key`) COMMENT 'for dependencies job' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; /*Data for the table `zipkin_annotations` */ /*Table structure for table `zipkin_dependencies` */ DROP TABLE IF EXISTS `zipkin_dependencies`; CREATE TABLE `zipkin_dependencies` ( `day` date NOT NULL, `parent` varchar(255) NOT NULL, `child` varchar(255) NOT NULL, `call_count` bigint(20) DEFAULT NULL, UNIQUE KEY `day` (`day`,`parent`,`child`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; /*Data for the table `zipkin_dependencies` */ /*Table structure for table `zipkin_spans` */ DROP TABLE IF EXISTS `zipkin_spans`; CREATE TABLE `zipkin_spans` ( `trace_id_high` bigint(20) NOT NULL DEFAULT '0' COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` bigint(20) NOT NULL, `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `parent_id` bigint(20) DEFAULT NULL, `debug` bit(1) DEFAULT NULL, `start_ts` bigint(20) DEFAULT NULL COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` bigint(20) DEFAULT NULL COMMENT 'Span.duration(): micros used for minDuration and maxDuration query', UNIQUE KEY `trace_id_high` (`trace_id_high`,`trace_id`,`id`) COMMENT 'ignore insert on duplicate', KEY `trace_id_high_2` (`trace_id_high`,`trace_id`,`id`) COMMENT 'for joining with zipkin_annotations', KEY `trace_id_high_3` (`trace_id_high`,`trace_id`) COMMENT 'for getTracesByIds', KEY `name` (`name`) COMMENT 'for getTraces and getSpanNames', KEY `start_ts` (`start_ts`) COMMENT 'for getTraces ordering and range' ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED; /*Data for the table `zipkin_spans` */ /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */; /*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
2. Modify the startup parameters and start the zipkin server
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root
- STORAGE_TYPE: storage type
- MYSQL_HOST: mysql host address
- MYSQL_TCP_PORT: mysql port
- MYSQL_DB: mysql database name
- MYSQL_USER: mysql user name
- MYSQL_PASS: mysql password
Parameters can be obtained from the official website: configuration parameter
7, Collecting data based on Message Oriented Middleware
1. Prepare MQ server environment
2. Modify the zipkin client and send the message to the mq server in the form of rabbit
(1) Add the following dependencies to each project that needs to send a rabbit message:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency> <dependency> <groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit</artifactId> </dependency>
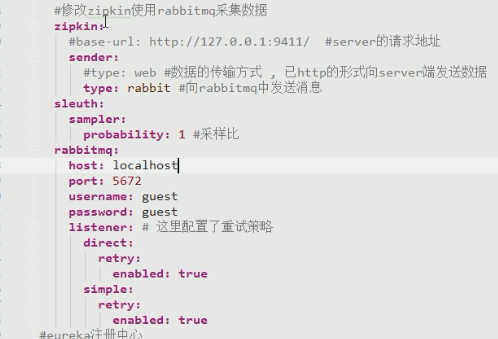
(2) Configure the message middleware rabbit mq address and other information
- Modify the delivery method of the message and change it to rabbit.
- Add related configuration of rabbitmq
# zipkin: # base-url: http://127.0.0.1: request address of 9411 / #zipkin server # sender: # #type: rabbit # type: web #By default, tracking data is sent to the zipkin server via http # sleuth: # sampler: # probability: 1.0 #Percentage of samples # rabbitmq: # host: localhost # port: 5672 # username: guest # password: guest # listener: # Retry policy is configured here # direct: # retry: # enabled: true # simple: # retry: # enabled: true
3. Modify the zipkin server and pull messages from rabbit
java -jar zipkin-server-2.12.9-exec.jar --RABBIT_ADDRESSES=127.0.0.1:5672