Basic knowledge of linked list
LRU cache elimination algorithm
A classic application scenario of linked list is LRU cache elimination algorithm.
LRU least recently unused algorithm. The algorithm is used in the OS virtual memory part. According to the locality principle of the program, the virtual memory is designed. Only a few memory blocks are allocated to a process. When the memory blocks of the process are occupied, the data of a memory block is re read from the hard disk. At this time, which memory block is more appropriate to be swapped out? If the replacement algorithm is not adopted well, it will lead to the increase of page missing rate and frequent page missing interruptions in the process. The OS will frequently replace pages between memory and external memory, which affects the execution efficiency of the process. This phenomenon is also called "jitter". [the missing page rate of LRU replacement algorithm is relatively low!]
Caching is a technology to improve data reading performance. Common are CPU cache, database cache, browser cache, etc
CPU cache can be divided into registers, L1 cache, L2 cache and L3 cache
Database cache: the database itself has its own cache, and redis can also be used as bit database cache
Browser cache: a Cookie is essentially a file
The size of the cache is limited. When the cache is full, the data cleaning needs to be determined by the cache elimination strategy! There are three common strategies: FIFO (first in first out), least frequently used (LFU) and least recently used (LRU)
FIFO: just bought a pile of books and piled them together. ok, read the books on them first and put the finished books in another pile (double stack structure, like the browser moving forward and backward).
LFU: infrequently used books. So many books are not necessarily all good books. After reading and identifying... Lose it.
LRU: books that are not commonly used recently. After screening the good books and bad books, some of the remaining good books don't seem to be so useful to me now, so put them aside and read them later.
Linked list structure: single linked list, two-way linked list and circular linked list
Array: continuous memory space for storage, with high memory requirements
Linked list: do not need a continuous memory space, connect a group of scattered memory in series through a pointer
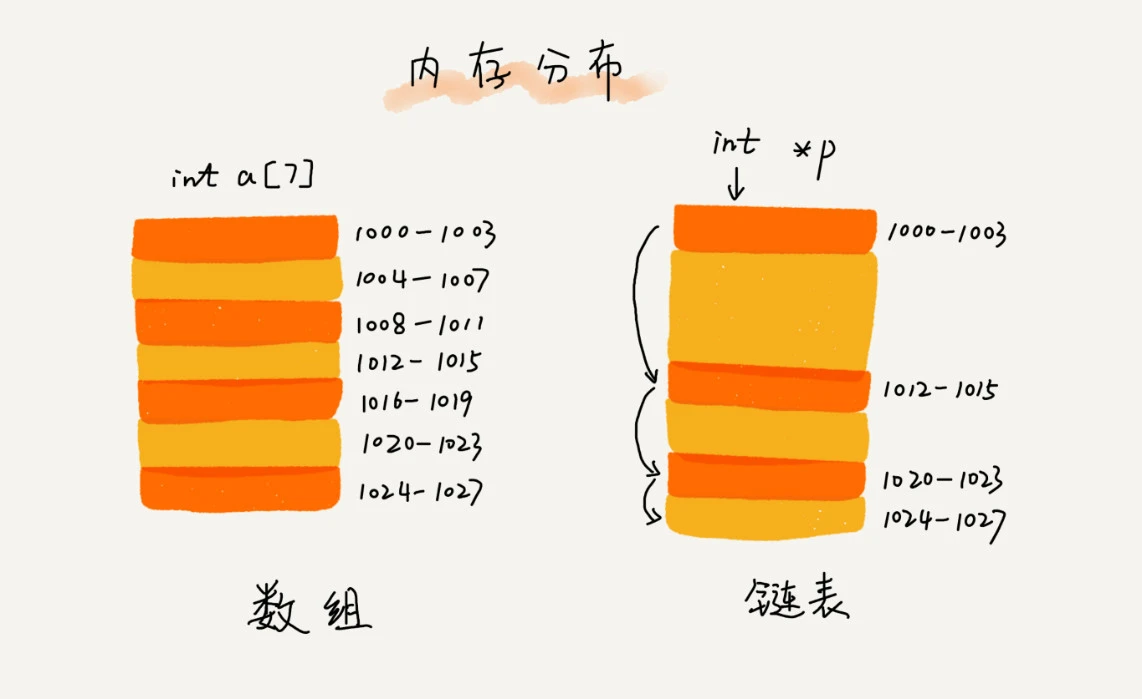
Single linked list: each node in the single linked list must have two functions: one is to store data, and the other is to record the address of the next node.
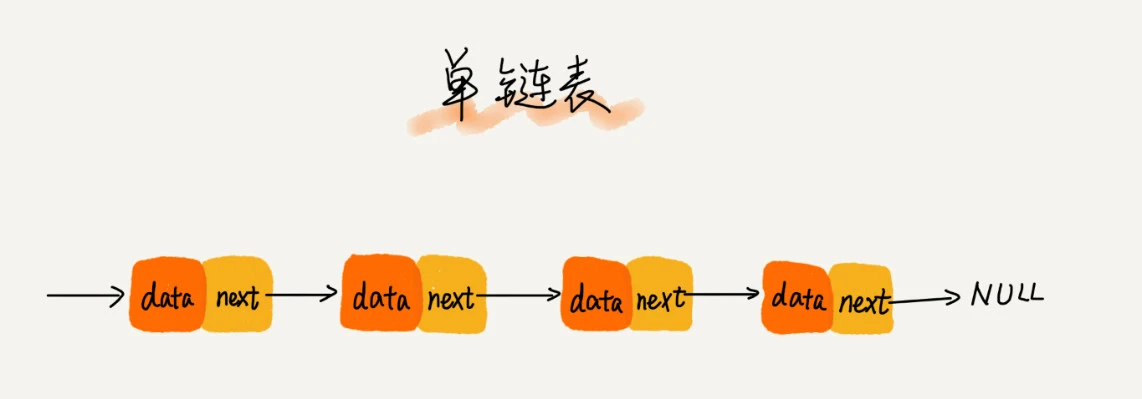
Insertion and deletion of single linked list:
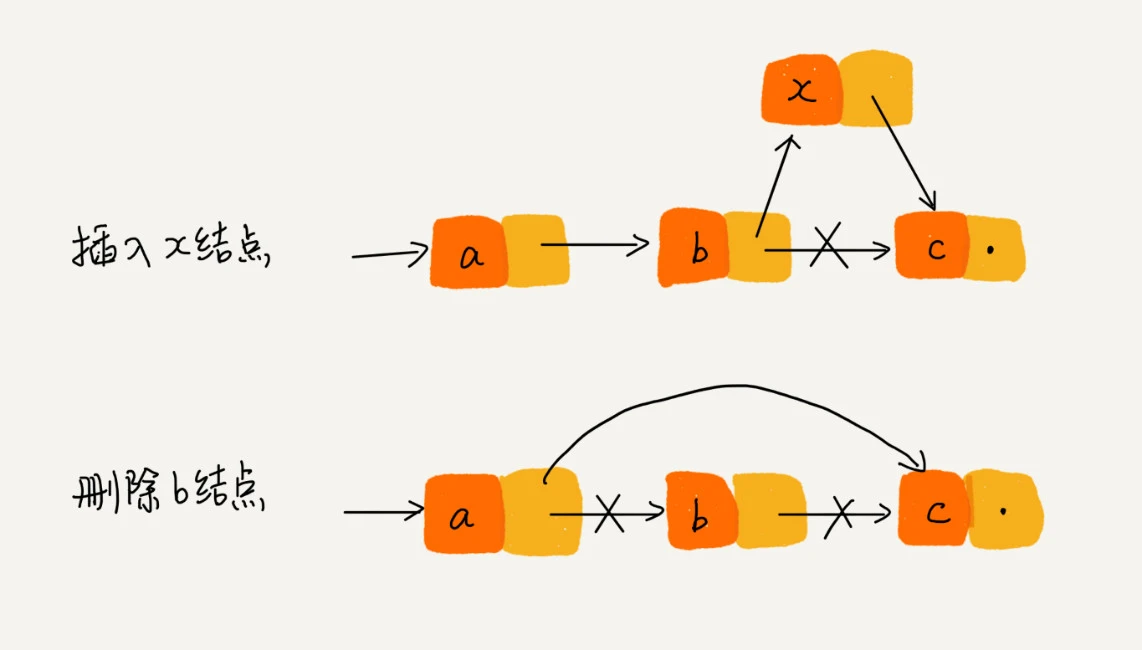
Circular linked list: the difference between circular linked list and single linked list. The memory address of the next node stored in the last node of the single linked list is empty, and the memory address of the next node stored in the last node of the circular linked list is the memory address of the chain header node
Bidirectional linked list: the bidirectional linked list needs two additional spaces to store the addresses of subsequent nodes and predecessor nodes.
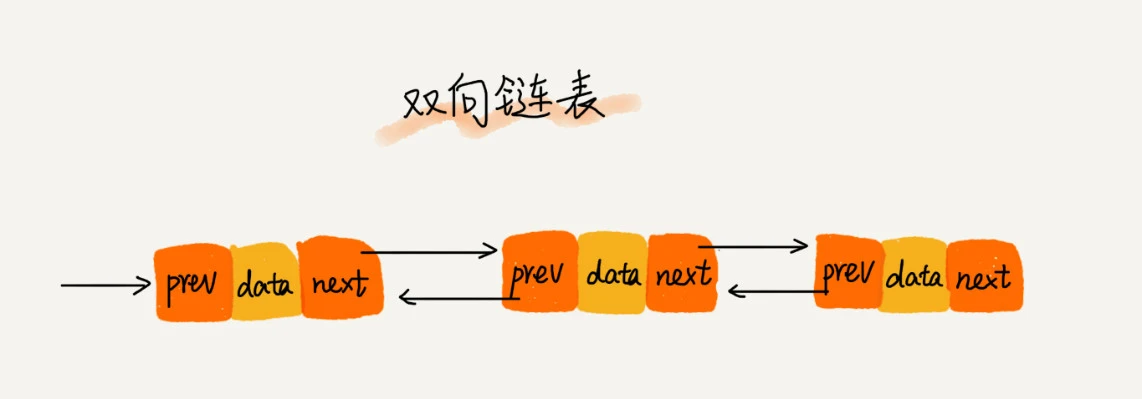
The two-way linked list is generally more efficient (the time complexity of inserting and deleting a single linked list is already O (1). Why is the two-way linked list still more efficient?)
Delete operation:
- Delete the node with 'value equal to a given value' in the node
- Deletes the node pointed to by the given pointer
In the first case, it needs to be traversed, and the time complexity is O(n). In the second case, the node in the two-way linked list has saved the pointer of the precursor node, so it does not need to be traversed like the single linked list. Therefore, in the second case, the single linked list deletion operation needs O(n) time complexity, while the two-way linked list only needs to be completed within O(1) time complexity!
This is why in the actual software development, although the two-way linked list costs more memory, it is still more widely used than the single linked list. In Java, LinkedList and LinkedHashMap use the data structure of two-way linked list. Design idea of exchanging space for time
Linked list VS array performance competition
Array and linked list are two distinct ways of memory organization. Because of the difference of memory storage, the time complexity of their insert, delete and random access operations is just the opposite.
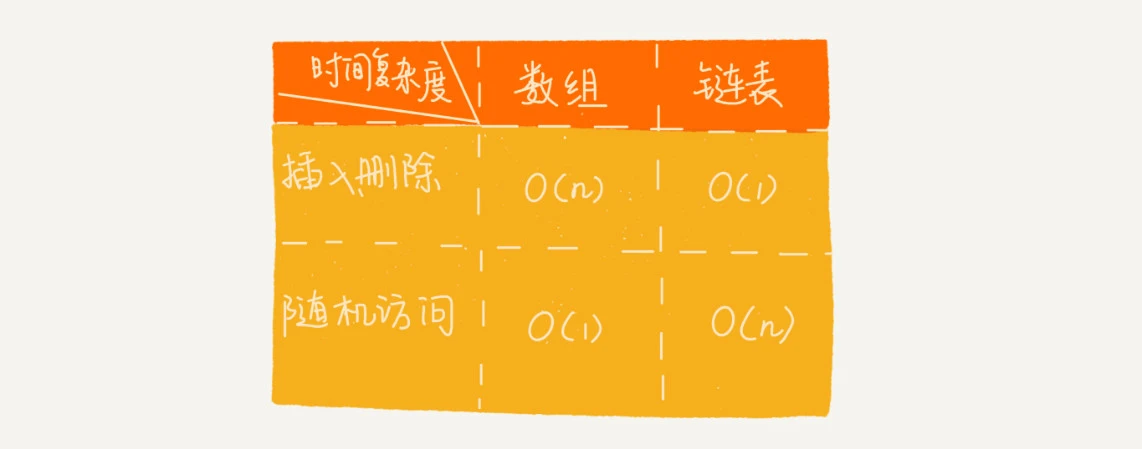
However, the comparison between arrays and linked lists cannot be limited to time complexity. Moreover, in the actual software development, we can not just use complexity analysis to decide which data structure to use to store data.
The array is simple and easy to use. It uses continuous memory space in the implementation. The data in the array can be read in advance with the help of the CPU cache mechanism, so the access efficiency is higher. The linked list is not stored continuously in memory, so it is not friendly to CPU cache and can not be read effectively.
The disadvantage of arrays is that they are fixed in size, and once declared, they will occupy the whole block of continuous memory space. If the declared array is too large, the system may not have enough contiguous memory space allocated to it, This leads to "out of memory". If the declared array is too small, it may not be enough. At this time, you can only apply for a larger memory space and copy the original array, which is very time-consuming. The linked list itself has no size limit and naturally supports dynamic expansion, which is also the biggest difference between it and the array.
Can the ArrayList container in Java also support dynamic capacity expansion? When inserting a data into an array that supports dynamic expansion, if there is no free space in the array, it will apply for a larger space to copy the data, and the data copy operation is very time-consuming. ArrayList stores 1GB of data. There is no free space at this time. When we insert data again, ArrayList will apply for a storage space of 1.5GB and copy the original 1GB of data to the newly applied space. Does that sound time-consuming? In addition, if your code is very memory intensive, arrays are better for you. Because each node in the linked list needs to consume additional storage space to store a pointer to the next node, the memory consumption will double. Moreover, frequent insertion and deletion of linked lists will also lead to frequent memory application and release, which is easy to cause memory fragmentation. If it is java language, It may lead to frequent GC (Garbage Collection). Therefore, in our actual development, for different types of projects, we should weigh whether to choose array or linked list according to the specific situation.
LRU cache elimination algorithm based on linked list
Maintain an ordered single linked list. The nodes closer to the end of the linked list are accessed earlier. When a new data is accessed, we traverse the linked list sequentially from the chain header.
- If this data has been cached in the linked list before, we traverse the node corresponding to this data, delete it from its original position, and then insert it into the head of the linked list.
- If this data is not in the cache linked list, it can be divided into two cases:
- If the cache is not full at this time, insert this node directly into the head of the linked list;
- If the cache is full at this time, the tail node of the linked list will be deleted and the new data node will be inserted into the head of the linked list.
Leetcode 146. LRU caching mechanism
class LRUCache {
/**
Analysis: This is a design problem with great difficulty.
Add, delete and modify the data, and the time complexity is O (1) = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = =
Perform a lookup operation on the data, and the time complexity is O (1) = = = = = = = = hash table
Finally, the selected data structure is hash table + bidirectional linked list (pseudo header and pseudo tail method), which has great power
The main business logic is described in the code comments
*/
// The data structure is a two-way linked list, including key value pairs, predecessor and follower nodes, and constructors
class DLinkedNode{
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
DLinkedNode(){
}
DLinkedNode(int _key,int _value){
key = _key;
value = _value;
}
}
// The data structure is a hash table, which is used to find
HashMap<Integer,DLinkedNode> cache = new HashMap<>();
// Define the length of the linked list, pseudo head and pseudo tail
private int size;
private DLinkedNode head,tail;
// Define the capacity of LRUCache (there is no need to set the capacity in the hash table, just the overall setting)
private int capacity;
// Constructor for LRUCache
public LRUCache(int capacity) {
// When initializing, let the length of the linked list be 0
this.size = 0;
// Initialize capacity
this.capacity = capacity;
// Initialize pseudo header and pseudo tail information
head = new DLinkedNode();
tail = new DLinkedNode();
// Pseudo head and pseudo tail are connected
head.next = tail;
tail.prev = head;
}
/**
Core idea:
Search in the hash table and return the corresponding node value if found (and move the node to the head of the linked list). If not found, return - 1
*/
public int get(int key) {
// Call the lookup function of the hash table
DLinkedNode res = cache.get(key);
if(res==null){
// Node not found
return -1;
}
// Call the function of the internal class to move to the header (write it yourself and return void). Note: the original node should also be deleted
moveToHead(res);
// Return node value
return res.key;
}
public void put(int key, int value) {
/**
Core idea:
Search in the hash table and update the corresponding node value when it is found (at the same time, move the node to the head of the linked list)
Create a new node if it is not found (and move the node to the head of the linked list)
If the cache capacity reaches the upper limit, the tail hash node (corresponding to the linked list node) is deleted
*/
// Call the lookup function of the hash table (write it yourself and return to the node)
DLinkedNode res = cache.get(key);
if(res!=null){
// Find the node, update the node information, and move the node to the head
res.value = value;
moveToHead(res);
}else{
// If no node is found, create a new one
DLinkedNode newNode= new DLinkedNode(key,value);
// Linked list length + 1
size++;
// Add to header
addToHead(newNode);
// Add to hash table
cache.put(key,newNode);
// Judge the relationship between size and capacity
if(size>capacity){
// Remove tail node information
DLinkedNode tailNode = moveTailNode();
// Delete entries in hash table
cache.remove(tailNode.key);
// size-1
size--;
}
}
}
// Internal add to header function
public void addToHead(DLinkedNode node){
// Move node to head
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// Internal move to header function
public void moveToHead(DLinkedNode node){
// Delete the original node first
node.prev.next = node.next;
node.next.prev = node.prev;
// Then move the node to the head
addToHead(node);
}
// Internally remove the tail node information
public DLinkedNode moveTailNode(){
DLinkedNode node = tail.prev;
node.prev.next = node.next;
node.next.prev = node.prev;
return node;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/