1, Introduction
LinkedHashMap inherits from HashMap. In addition to the features of HashMap, LinkedHashMap also provides the function of keeping the same traversal order and insertion order.
- LinkedHashMap maintains a two-way linked list to ensure the consistency of traversal and insertion order.
- LinkedHashMap can be understood as a combination of LinkedList + HashMap
- Most of the functions of LinkedHashMap (search, insert, delete, etc.) come directly from HashMap. Therefore, this paper mainly studies the maintenance of two-way linked list. If you don't know about HashMap, you can check the previous article: HashMap for JDK source code analysis
- Jdk1 Version 8 shall prevail
2, Underlying data structure
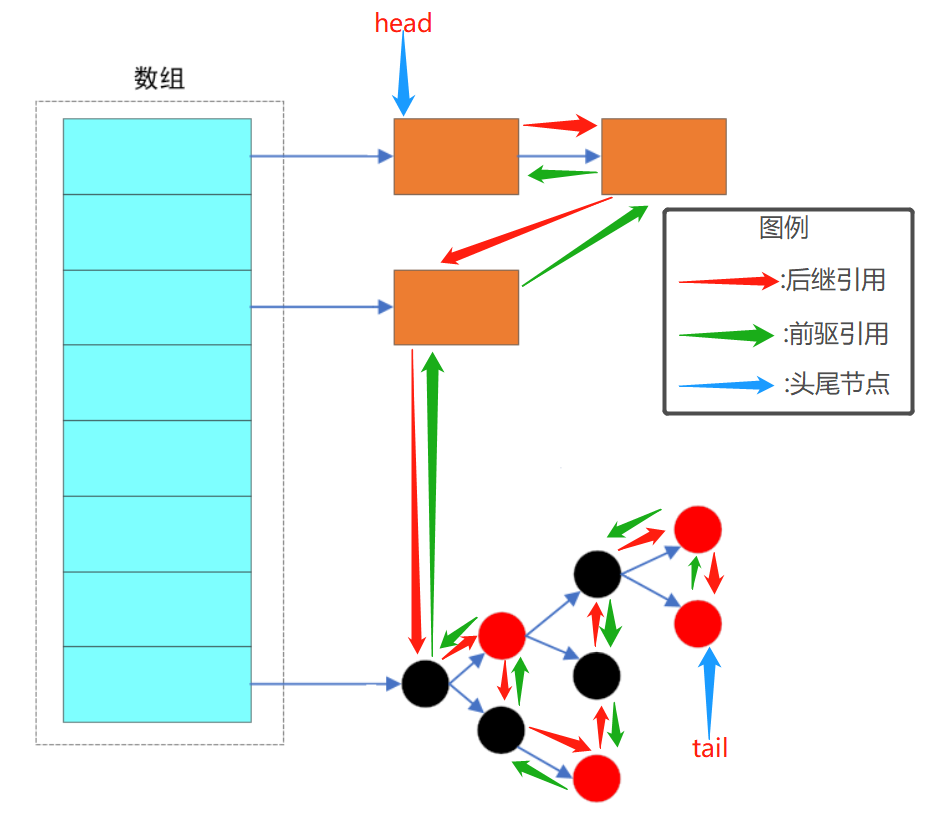
The underlying data structure is consistent with HashMap, but a two-way linked list is added to control its traversal order. The head and tail in the figure above are the head and tail nodes of the two-way linked list respectively, and each node has its predecessor and successor points.
3, Class diagram
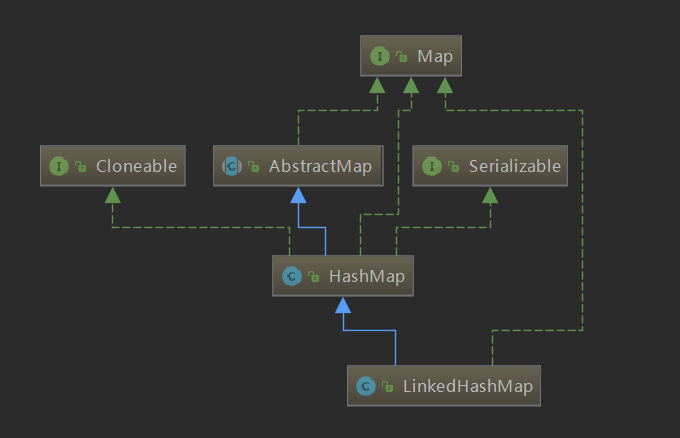
- Implement Java util. Map interface.
- Inherit Java util. HashMap class.
4, Properties and construction methods
1. Properties
//Serialization version number private static final long serialVersionUID = 3801124242820219131L; //Head node, pointing to the oldest node transient LinkedHashMap.Entry<K,V> head; //Tail node, pointing to the latest node transient LinkedHashMap.Entry<K,V> tail; //Whether to access according to the order. The default is false //true: access according to the access order of key value. //false: access according to the insertion order of key value (default) final boolean accessOrder;
It mainly includes two types of attributes
- Head and tail: they are the head and tail nodes of the two-way linked list respectively, which controls the access order, that is, head = > tail
- accessOrder: determines the order of LinkedHashMap
- false: when a node is added, it is placed at the end of the linked list and pointed by tail. If the node corresponding to the inserted key already exists, it will also be placed at the end.
- true: when the node is accessed, it is placed at the end of the linked list and pointed by tail.
Next, let's focus on LinkedHashMap For the class entry, let's first look at the inheritance system of key values to nodes
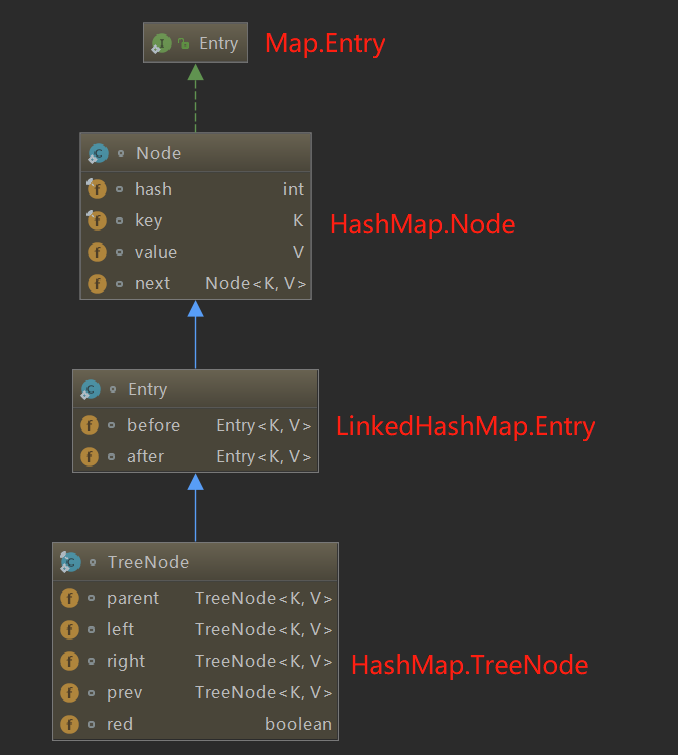
It can be seen that the LinkedHashMap internal class Entry inherits from the HashMap internal class Node. On the basis of inheriting the original attributes, two references are added, before and after, representing the precursor and successor of the Node respectively.
static class Entry<K,V> extends HashMap.Node<K,V> {
//Predecessor and successor nodes
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
2. Construction method
LinkedHashMap has five construction methods, of which four are basically the same as that of HashMap.
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
The only difference between these four construction methods and HashMap is that accessOrder is set to false by default, that is, it is sorted according to the insertion order by default.
Therefore, the fifth constructor is naturally customizable. The parameter of accessOrder is true or false
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
//Custom accessOrder parameter
this.accessOrder = accessOrder;
}
5, Node creation
The creation of a two-way linked list starts when a key value pair is inserted. Initially, let the head and tail references of LinkedHashMap point to the new node at the same time, and the linked list will be established. Then new nodes are inserted continuously. The linked list can be updated by connecting the new node to the back of the tail reference pointing node.
The new node still calls the put method of the original HashMap, but the newNode method called when creating the node is a method rewritten by LinkedHashMap.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//Node creation
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
//Insert the new node into the tail of the bidirectional linked list
linkNodeLast(p);
return p;
}
//Insert the new node into the tail of the bidirectional linked list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
//Save original tail node
LinkedHashMap.Entry<K,V> last = tail;
//Assign the new node to the tail node
tail = p;
//If the tail node is empty, the data is inserted for the first time
if (last == null)
//The new node is also assigned to the head node
head = p;
//Otherwise, after connecting the new node to the original tail node
else {
p.before = last;
last.after = p;
}
}
The creation logic of nodes is very simple, that is, create nodes and link nodes to the end of the queue.
6, Node operation callback
The reading, adding and deleting of HashMap will affect the nodes. Therefore, after performing the corresponding operations, HashMap will call the following callback methods respectively to synchronize the state of the two-way linked list.
- Afternodeaccess (node < K, V > e): triggered when a node is accessed (when accessOrder is true)
- After node insertion (Boolean evict): triggered when a node is added
- Afternoderemoval (node < K, V > e): triggered when a node is removed
Next, let's analyze these three callback methods.
1. afterNodeAccess
On the premise that the accessOrder property is set to true, when the node is accessed, it will be placed at the end of the linked list.
//Move node to end
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//Only when accessOrder is true and e is not a final node, you need to migrate to the end
if (accessOrder && (last = tail) != e) {
//p save the current node; b is the precursor node; a is the successor node
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//The successor of p is null
p.after = null;
//If b is null, p is the head node
if (b == null)
//The successor of p is updated to the header node
head = a;
//b is not null, indicating that p is not the head node and p is in the middle of the linked list
else
//The successor of the precursor of p points to the successor of p, that is, disconnect p
b.after = a;
//If a is not null, it means a is not the tail node
if (a != null)
//The precursor of a points to b
a.before = b;
//The else here will not be executed, because it has been guaranteed that e is not the tail node, so the here don't understand why to make if else judgment
else
last = b;
//After processing nodes b and a, you need to connect p to the tail of the linked list
//Logically, last should not be empty. I don't understand why I make judgments here
if (last == null)
head = p;
//Connect p to the end of the linked list
else {
p.before = last;
last.after = p;
}
//Update the tail node to the current node
tail = p;
//Modification times + 1
++modCount;
}
}
To sum up, the operation process is to move the target node from the current position to the end of the linked list. The logic is relatively simple.
2. afterNodeInsertion
This method will be called when inserting elements, but the callback method does not insert nodes into the two-way linked list (the previous nodes have been inserted into the two-way linked list when they were created), but judges whether to remove elements according to conditions, which can be used to realize the caching of LRU policies, which will be explained in detail later.
//The parameter evict indicates whether to allow the element to be removed. The default value is false
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//The removeEldestEntry method is used to determine whether to delete the team head element
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
//Delete node
removeNode(hash(key), key, null, false, true);
}
}
//Judge whether to delete the queue head element. This method returns false by default, that is, it does not delete. Subclasses can override this method to define their own deletion policy
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
The above code will not be executed under normal circumstances. Later, this feature will be used to implement a LRU policy cache
3. afterNodeRemoval
This method is called when the element is deleted
//Delete the node from the bidirectional linked list
void afterNodeRemoval(Node<K,V> e) { // unlink
//P save the current node; b save the precursor node of p; a saves the successor node of P
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//Empty the predecessor and successor of this node
p.before = p.after = null;
//If b is empty, it means that p is the head node, and a needs to be set as the head node
if (b == null)
//Set a as the head node
head = a;
//Otherwise, b is not empty, which means that p is not the head node and directly points the successor of b to a
else
b.after = a;
//If a is empty, it means that p is the tail node, and b needs to be set as the tail node
if (a == null)
//Set b as tail node
tail = b;
//If a is not empty, it means that p is not the tail node. Direct the precursor of a to b
else
a.before = b;
}
The above logic is relatively simple. To sum up, it is to remove the target node from the two-way linked list.
7, Other operations
1. Find
The search method of the corresponding part in LinkedHashMap has been rewritten, mainly for the above callback operation
-
get(Object key)
Find the value corresponding to the specified key. If it does not exist, null will be returned
public V get(Object key) { Node<K,V> e; //Normal find operation if ((e = getNode(hash(key), key)) == null) return null; //If accessOrder is true, the two-way linked list needs to be updated if (accessOrder) afterNodeAccess(e); return e.value; }On the basis of the original search, the operation of updating the two-way linked list is added.
-
getOrDefault(Object key, V defaultValue)
Get the value corresponding to the key. If it does not exist, the default value will be returned
public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; //Normal find operation if ((e = getNode(hash(key), key)) == null) return defaultValue; //If accessOrder is true, the two-way linked list needs to be updated if (accessOrder) afterNodeAccess(e); return e.value; }The logic is the same as above
-
containsValue(Object value)
public boolean containsValue(Object value) { //Traversal through head and tail nodes for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) { V v = e.value; if (v == value || (value != null && value.equals(v))) return true; } return false; }In HashMap, two for loops are used for searching. Here, one traversal is performed according to the head and tail nodes
2. Empty
public void clear() {
//Call the method of the parent class to clear the node information
super.clear();
//Head and tail nodes are empty
head = tail = null;
}
8, Implementation of LRU policy caching based on LinkedHashMap
According to the maintenance order of LinkedHashMap, you can easily implement a LRU policy cache. When we introduced the callback method afterNodeInsertion earlier, we said that this method controls under what circumstances the least recently accessed node can be removed. Therefore, we can create a subclass of LinkedHashMap and override the removeEldestEntry method to implement the LRU policy. The code is as follows
package com.jicl;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* Customized LRU policy cache
*
* @author : xianzilei
* @date : 2020/3/22 22:51
*/
public class MyLRUCache<K, V> extends LinkedHashMap<K, V> {
//Default maximum capacity
private static final Integer DEFAULT_MAXIMUM_CAPACITY = 100;
//Default load factor
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
//Maximum capacity
private Integer maxCapacity;
public Integer getMaxCapacity() {
return maxCapacity;
}
public void setMaxCapacity(Integer maxCapacity) {
this.maxCapacity = maxCapacity;
}
//Parameterless constructor. The maximum capacity is 100 by default
public MyLRUCache() {
this(DEFAULT_MAXIMUM_CAPACITY);
}
//With parameter constructor, the maximum capacity can be customized
public MyLRUCache(Integer maxCapacity) {
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
}
//Add element
public V save(K key, V val) {
return put(key, val);
}
//Find element
public V find(K key) {
return get(key);
}
//Determine whether the key exists
public boolean existsKey(K key) {
return containsKey(key);
}
//Determine whether value exists
public boolean existsValue(V value) {
return containsValue(value);
}
//Override the parent class method to determine under what circumstances to delete the least recently accessed element
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
//Delete the least recently accessed element when the maximum capacity is greater than 100
return size() > maxCapacity;
}
}
The specific test code will not be repeated.