LinkedList source code analysis
LinkedList is applicable to the scenarios of first in first out and last out of set elements, and is frequently used in the queue source code.
Overall architecture
The underlying data structure of LinkedList is a two-way linked list. The overall structure is shown in the figure below:
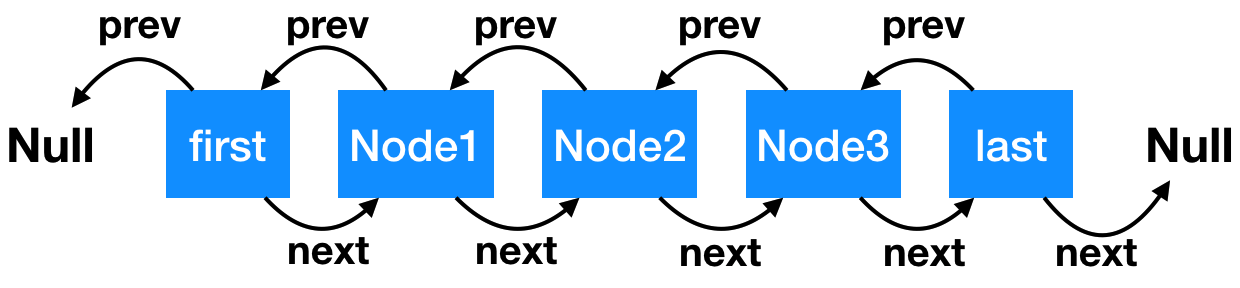
The figure above represents a two-way linked list structure. Each node in the linked list can be traced forward or backward
- Each Node in the linked list is called a Node,
- Node has prev attribute, which represents the position of the previous node
- The next attribute represents the location of the next node
- first is the head node of the bidirectional linked list, and its previous node is null
- Last is the tail node of the bidirectional linked list, and its last node is null
- When there is no data in the linked list, first and last are the same node, and the front and back points are null
- Because it is a two-way linked list, there is no size limit as long as there is enough memory
The elements in the linked list are called nodes. The code is as follows
private static class Node<E> {
// Node value
E item;
// Point to next node
Node<E> next;
// Point to next node
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Source code analysis
Add (add)
When adding nodes, we can choose whether to add to the head of the linked list or to the tail of the linked list. The add method starts from the tail by default, and addFirst is to add to the head
Append from tail (add)
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
// Save the tail node temporarily
final Node<E> l = last;
// Create a new Node,
// l: Point the previous node to the old tail node
// next points to null,
final Node<E> newNode = new Node<>(l, e, null);
// The tail node is assigned as a new node
last = newNode;
// If the tail node is null, the linked list is empty
if (l == null)
// Head node = tail node = new node
first = newNode;
else
// Point the next of the original tail node to the new node
l.next = newNode;
// Linked list size + + version++
size++;
modCount++;
}
Append from header (addFirst)
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
// Temporarily store the header node
final Node<E> f = first;
// Initialize a new node. The next of the new node points to the original header node
final Node<E> newNode = new Node<>(null, e, f);
// Assign the header node to the new and press
first = newNode;
// If the header node is empty, the linked list is empty
if (f == null)
// Head node = tail node = new node
last = newNode;
else
// Point the prev of the original header node to the new node
f.prev = newNode;
// Linked list size + + version++
size++;
modCount++;
}
The head append node is very similar to the tail append node, except that the former is the prev point of the mobile head node and the latter is the next point of the mobile tail node.
Node deletion
Node deletion is similar to node append. You can choose to delete from the head or from the tail. Deletion will point the value, prev and next of the node to null to help GC recycle
Delete from header
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
// Take out the node value and return after deletion
final E element = f.item;
// Take out the next of the head node, which will become the new head node
final Node<E> next = f.next;
// Set null to help GC
f.item = null;
f.next = null; // help GC
// The next of the original header node becomes the new header node
first = next;
// If next is null, the linked list is empty
if (next == null)
// Head node = tail node = null
last = null;
else
// The linked list is not null. Set the new head node prev to null
next.prev = null;
// Linked list size --, version++
size--;
modCount++;
// Returns the value of the deleted node
return element;
}
Delete from tail
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
// Take out the value of the tail node
final E element = l.item;
// Take out the previous node of the tail node
final Node<E> prev = l.prev;
// Assign the value of the tail node and the previous node of the tail node to be null to help GC recycle
l.item = null;
l.prev = null; // help GC
// The previous node prev of the original tail node is the new tail node
last = prev;
// If prev is null, the linked list is empty
if (prev == null)
first = null;
else
// The linked list is not empty. Set the next node of the new tail node to null
prev.next = null;
// Size and version changes
size--;
modCount++;
// Returns the value of the deleted node
return element;
}
From the source code, we can see that the addition and deletion of nodes in the linked list structure are very simple, and only the direction of the front and rear nodes is modified, so the addition and deletion speed of LinkedList is very fast.
Node query
It is slow to query a node in the linked list, so you need to traverse the linked list
/**
* Query nodes according to the index position of the linked list
*/
Node<E> node(int index) {
// assert isElementIndex(index);
// If the index is in the first half of the linked list, look it up from the beginning. Size > > 1 means size/2
if (index < (size >> 1)) {
Node<E> x = first;
// Cycle to the previous node of index and stop
for (int i = 0; i < index; i++)
x = x.next;
return x;
}
// In the second half of the linked list, search from the tail
else {
Node<E> x = last;
// Cycle to the next node of the index and stop
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
From the source code, we find that LinkedList does not cycle from beginning to end, but adopts a simple dichotomy. First, see whether the index is in the first half or the second half of the linked list. If it's the first half, start from scratch and vice versa. In this way, the number of cycles is reduced by at least half, and the search performance is improved.