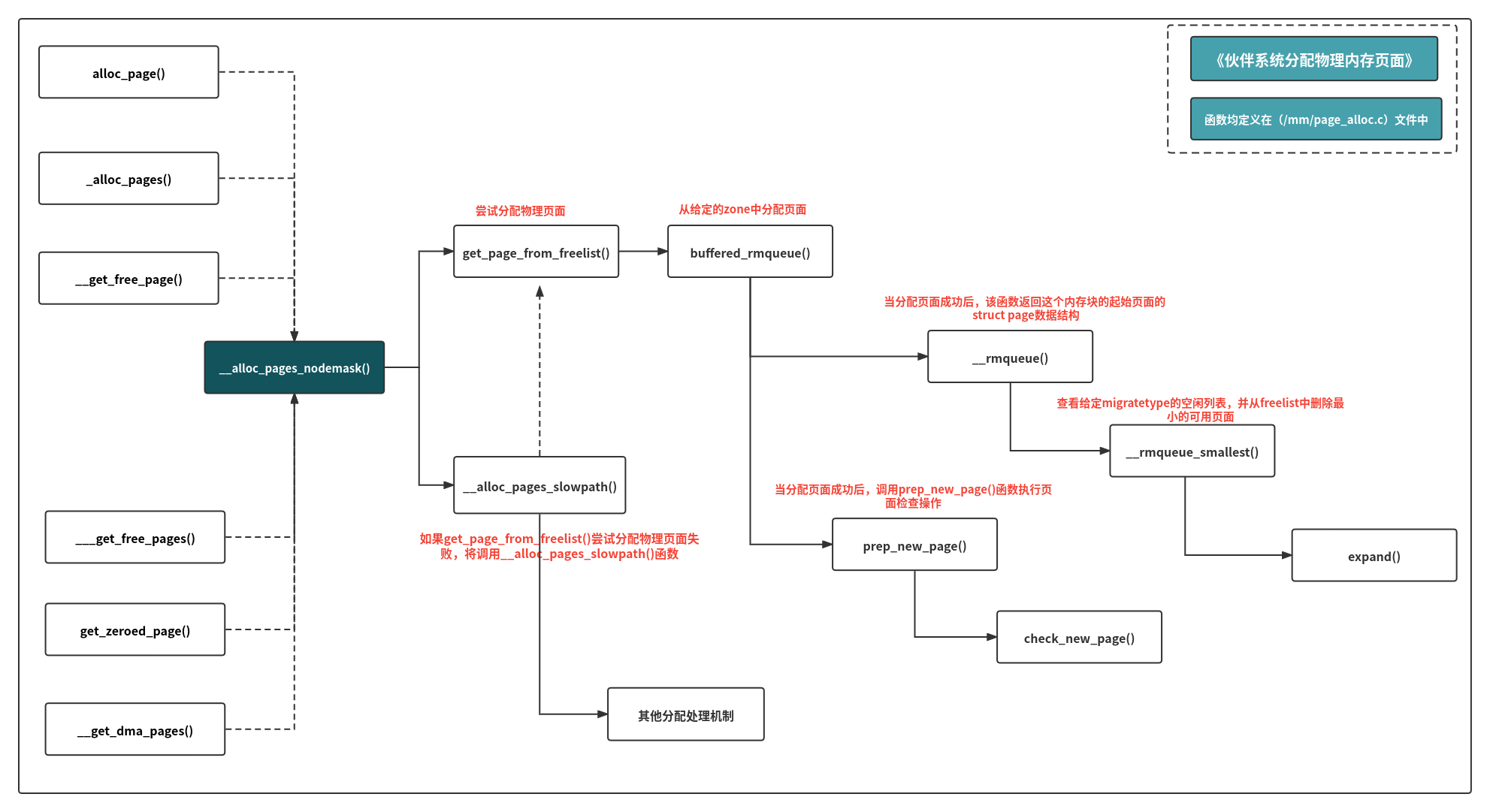
linux allocate physical memory page
1, Physical memory allocation overview
In the linux kernel, the page allocator can allocate one or more consecutive physical pages. The number of allocated pages can only be an integer power of 2; Allocating continuous physical pages is more beneficial to alleviate the memory fragmentation of the system than allocating discrete physical pages.
The API functions for allocating memory commonly used in linux kernel are as follows:
//Allocate only one page and return the pointer to the first page structure alloc_page() //Allocate 2^order pages and return the pointer to the first page structure alloc_pages() //Allocate only one page and return the pointer of the virtual address where the page is located __get_free_page() //With 2^order pages, return the pointer to the virtual address of the first page structure __get_free_pages() //Allocate only one page, fill its contents with 0, and return the pointer of the virtual address where the page is located get_zeroed_page() __get_dma_pages()
All the above functions will be called to a common function:__ alloc_pages_nodemask(). This function is the core function to handle the memory allocation of linux.
2, Allocate core function [_alloc_pages_nodemask]
Function prototype:
struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,struct zonelist *zonelist, nodemask_t *nodemask)
- gfp_mask: assign mask
- Order: allocation order
- zone list: zone linked list
- nodemask: node mask
Function definition (/ mm/page_alloc.c):
struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
struct zoneref *preferred_zoneref;
struct page *page = NULL;
unsigned int cpuset_mems_cookie;
int alloc_flags = ALLOC_WMARK_LOW|ALLOC_CPUSET|ALLOC_FAIR;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
//struct alloc_ The context data structure is used to save allocation related parameters.
struct alloc_context ac = {
//gfp_ The zone() function will calculate zoneidx from the allocation mask and store it in high_zoneidx structure member.
.high_zoneidx = gfp_zone(gfp_mask),
//Save nodemask to ac
.nodemask = nodemask,
//Put gfp_mask mask to MIGRATE_TYPES and stored in the migratetype structure member.
.migratetype = gfpflags_to_migratetype(gfp_mask),
};
gfp_mask &= gfp_allowed_mask;
lockdep_trace_alloc(gfp_mask);
might_sleep_if(gfp_mask & __GFP_WAIT);
if (should_fail_alloc_page(gfp_mask, order))
return NULL;
/*
* Check the zones suitable for the gfp_mask contain at least one
* valid zone. It's possible to have an empty zonelist as a result
* of __GFP_THISNODE and a memoryless node
*/
if (unlikely(!zonelist->_zonerefs->zone))
return NULL;
if (IS_ENABLED(CONFIG_CMA) && ac.migratetype == MIGRATE_MOVABLE)
alloc_flags |= ALLOC_CMA;
retry_cpuset:
cpuset_mems_cookie = read_mems_allowed_begin();
//Save zonelist to ac because in__ alloc_pages_slowpath may change zonelist
ac.zonelist = zonelist;
/* The preferred zone is used for statistics later */
preferred_zoneref = first_zones_zonelist(ac.zonelist, ac.high_zoneidx,
ac.nodemask ? : &cpuset_current_mems_allowed,
&ac.preferred_zone);
if (!ac.preferred_zone)
goto out;
ac.classzone_idx = zonelist_zone_idx(preferred_zoneref);
//Set allocation mask
alloc_mask = gfp_mask|__GFP_HARDWALL;
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (unlikely(!page)) {
//Set the allocation mask to the noio flag. Because the I/O on the device may not be completed, the runtime PM, block IO and their error handling paths may cause deadlock.
alloc_mask = memalloc_noio_flags(gfp_mask);
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
}
if (kmemcheck_enabled && page)
kmemcheck_pagealloc_alloc(page, order, gfp_mask);
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
out:
/*
* When updating a task's mems_allowed, it is possible to race with
* parallel threads in such a way that an allocation can fail while
* the mask is being updated. If a page allocation is about to fail,
* check if the cpuset changed during allocation and if so, retry.
*/
if (unlikely(!page && read_mems_allowed_retry(cpuset_mems_cookie)))
goto retry_cpuset;
return page;
}
Call get_ in the above function page_ from_ freelist(alloc_mask, order, alloc_flags, &ac); Try to allocate physical pages.
When the function fails to successfully allocate the page, the following code snippet will be entered:
alloc_mask = memalloc_noio_flags(gfp_mask); page = __alloc_pages_slowpath(alloc_mask, order, &ac);
In__ alloc_ pages_ The slowpath () function will handle many special scenarios, and this function is also complex.
(2-1) important function 1: [get_page_from_freelist()]
get_ page_ from_ The freelist() function is defined as follows (/ mm/page_alloc.c):
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zonelist *zonelist = ac->zonelist;
struct zoneref *z;
struct page *page = NULL;
struct zone *zone;
nodemask_t *allowednodes = NULL;/* zonelist_cache approximation */
int zlc_active = 0; /* set if using zonelist_cache */
int did_zlc_setup = 0; /* just call zlc_setup() one time */
bool consider_zone_dirty = (alloc_flags & ALLOC_WMARK_LOW) &&
(gfp_mask & __GFP_WRITE);
int nr_fair_skipped = 0;
bool zonelist_rescan;
zonelist_scan:
zonelist_rescan = false;
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
for_each_zone_zonelist_nodemask(zone, z, zonelist, ac->high_zoneidx,
ac->nodemask) {
unsigned long mark;
if (IS_ENABLED(CONFIG_NUMA) && zlc_active &&
!zlc_zone_worth_trying(zonelist, z, allowednodes))
continue;
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* Distribute pages in proportion to the individual
* zone size to ensure fair page aging. The zone a
* page was allocated in should have no effect on the
* time the page has in memory before being reclaimed.
*/
if (alloc_flags & ALLOC_FAIR) {
if (!zone_local(ac->preferred_zone, zone))
break;
if (test_bit(ZONE_FAIR_DEPLETED, &zone->flags)) {
nr_fair_skipped++;
continue;
}
}
/*
* When allocating a page cache page for writing, we
* want to get it from a zone that is within its dirty
* limit, such that no single zone holds more than its
* proportional share of globally allowed dirty pages.
* The dirty limits take into account the zone's
* lowmem reserves and high watermark so that kswapd
* should be able to balance it without having to
* write pages from its LRU list.
*
* This may look like it could increase pressure on
* lower zones by failing allocations in higher zones
* before they are full. But the pages that do spill
* over are limited as the lower zones are protected
* by this very same mechanism. It should not become
* a practical burden to them.
*
* XXX: For now, allow allocations to potentially
* exceed the per-zone dirty limit in the slowpath
* (ALLOC_WMARK_LOW unset) before going into reclaim,
* which is important when on a NUMA setup the allowed
* zones are together not big enough to reach the
* global limit. The proper fix for these situations
* will require awareness of zones in the
* dirty-throttling and the flusher threads.
*/
if (consider_zone_dirty && !zone_dirty_ok(zone))
continue;
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (!zone_watermark_ok(zone, order, mark,
ac->classzone_idx, alloc_flags)) {
int ret;
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (IS_ENABLED(CONFIG_NUMA) &&
!did_zlc_setup && nr_online_nodes > 1) {
/*
* we do zlc_setup if there are multiple nodes
* and before considering the first zone allowed
* by the cpuset.
*/
allowednodes = zlc_setup(zonelist, alloc_flags);
zlc_active = 1;
did_zlc_setup = 1;
}
if (zone_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zone, zone))
goto this_zone_full;
/*
* As we may have just activated ZLC, check if the first
* eligible zone has failed zone_reclaim recently.
*/
if (IS_ENABLED(CONFIG_NUMA) && zlc_active &&
!zlc_zone_worth_trying(zonelist, z, allowednodes))
continue;
ret = zone_reclaim(zone, gfp_mask, order);
switch (ret) {
case ZONE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case ZONE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac->classzone_idx, alloc_flags))
goto try_this_zone;
/*
* Failed to reclaim enough to meet watermark.
* Only mark the zone full if checking the min
* watermark or if we failed to reclaim just
* 1<<order pages or else the page allocator
* fastpath will prematurely mark zones full
* when the watermark is between the low and
* min watermarks.
*/
if (((alloc_flags & ALLOC_WMARK_MASK) == ALLOC_WMARK_MIN) ||
ret == ZONE_RECLAIM_SOME)
goto this_zone_full;
continue;
}
}
try_this_zone:
page = buffered_rmqueue(ac->preferred_zone, zone, order,
gfp_mask, ac->migratetype);
if (page) {
if (prep_new_page(page, order, gfp_mask, alloc_flags))
goto try_this_zone;
return page;
}
this_zone_full:
if (IS_ENABLED(CONFIG_NUMA) && zlc_active)
zlc_mark_zone_full(zonelist, z);
}
/**************************for_each_zone_zonelist_nodemask [End]*************************/
/*
* The first pass makes sure allocations are spread fairly within the
* local node. However, the local node might have free pages left
* after the fairness batches are exhausted, and remote zones haven't
* even been considered yet. Try once more without fairness, and
* include remote zones now, before entering the slowpath and waking
* kswapd: prefer spilling to a remote zone over swapping locally.
*/
if (alloc_flags & ALLOC_FAIR) {
alloc_flags &= ~ALLOC_FAIR;
if (nr_fair_skipped) {
zonelist_rescan = true;
reset_alloc_batches(ac->preferred_zone);
}
if (nr_online_nodes > 1)
zonelist_rescan = true;
}
if (unlikely(IS_ENABLED(CONFIG_NUMA) && zlc_active)) {
/* Disable zlc cache for second zonelist scan */
zlc_active = 0;
zonelist_rescan = true;
}
if (zonelist_rescan)
goto zonelist_scan;
return NULL;
}
The above code is relatively long and is mainly divided into two parts:
(1)for_each_zone_zonelist_nodemask{}
(2) Operation after allocation
[2-2-1]for_each_zone_zonelist_nodemask{}
for_each_zone_zonelist_nodemask is essentially a macro definition:
#define for_each_zone_zonelist_nodemask(zone, z, zlist, highidx, nodemask) \ for (z = first_zones_zonelist(zlist, highidx, nodemask, &zone); \ zone; \ z = next_zones_zonelist(++z, highidx, nodemask), \ zone = zonelist_zone(z)) \
[macro parameter meaning]
- Zone: the current zone in the iterator
- z: The current pointer in the iterating zonelist - > zone
- zlist: zonelist being iterated
- highidx: the zone index of the highest zone
- Nodemask: nodemask allowed by the allocator
The function of this macro definition is to act as an iterator to iterate over valid zones in a given zone index or a zone elist below a given zone index and node mask.
-
first_ zones_ The function of zonelist () is to return the highest zoneid X or the first zoneref pointer lower than the highest zoneid X in the nodemask allowed in zonelist (the zoneref structure contains a zone and a zoneid x).
-
next_ zones_ The function of zonelist is to return the next zone located at or below the highest zoneidx in zonelist
When for_each_zone_zonelist_nodemask finds the zone. Next, it will check whether the water level in the zone is sufficient. This part is controlled by the zone_watermark_ok() function implementation.
If it is detected that the water level in the zone is sufficient, it is called buffered_ The rmqueue() function allocates physical pages from the partner system. buffered_ The function of rmqueue () is to allocate a page from a given zone. When order is 0, the allocation will use pcplist (if it is pcplist, allow subsequent analysis!).
(2-2) important function 2: [_alloc_pages_slowpath()]
__ alloc_ pages_ The slowpath() function is long, which is in get_page_from_freelist() is not called until an attempt to allocate a physical page fails. After being processed by this function, there are two results:
1. If the physical page is reassigned successfully, the corresponding page will be returned.
2,warn_ alloc_ The failed() function prompts that the allocation of the physical page has failed and will print out:
%s: page allocation failure: order:%d
Similar information.
3, Assign mask
(3-1) macro definition of allocation mask
Allocation mask is an important parameter that the linux kernel needs to execute or pass when allocating memory. It is used to control the page allocation behavior and state of the allocator. It is defined in the file (/ include/linux/gfp.h):
#define ___GFP_DMA 0x01u #define ___GFP_HIGHMEM 0x02u #define ___GFP_DMA32 0x04u #define ___GFP_MOVABLE 0x08u #define ___GFP_WAIT 0x10u #define ___GFP_HIGH 0x20u #define ___GFP_IO 0x40u #define ___GFP_FS 0x80u #define ___GFP_COLD 0x100u #define ___GFP_NOWARN 0x200u #define ___GFP_REPEAT 0x400u #define ___GFP_NOFAIL 0x800u #define ___GFP_NORETRY 0x1000u #define ___GFP_MEMALLOC 0x2000u #define ___GFP_COMP 0x4000u #define ___GFP_ZERO 0x8000u #define ___GFP_NOMEMALLOC 0x10000u #define ___GFP_HARDWALL 0x20000u #define ___GFP_THISNODE 0x40000u #define ___GFP_RECLAIMABLE 0x80000u #define ___GFP_NOACCOUNT 0x100000u #define ___GFP_NOTRACK 0x200000u #define ___GFP_NO_KSWAPD 0x400000u #define ___GFP_OTHER_NODE 0x800000u #define ___GFP_WRITE 0x1000000u
In the development of the above macro definitions, kernel developers suggest not to use them directly, but to use them in combination:
There are two types of allocation masks in linux kernel macros:
(1)zone_modifiers: specifies which zone to allocate pages from
There are the following macro definition options (/ include/linux/gfp.h):
#define __GFP_DMA ((__force gfp_t)___GFP_DMA) #define __GFP_HIGHMEM ((__force gfp_t)___GFP_HIGHMEM) #define __GFP_DMA32 ((__force gfp_t)___GFP_DMA32) #define __GFP_MOVABLE ((__force gfp_t)___GFP_MOVABLE) /* Page is movable */ #define GFP_ZONEMASK (__GFP_DMA|__GFP_HIGHMEM|__GFP_DMA32|__GFP_MOVABLE)
(2)action_modifiers: defined by the lowest 4 bits of the allocation mask, which are__ GFP_DMA,__ GFP_HIGHMEM,__ GFP_DMA32,__ GFP_MOVABLE. There are the following macro definition options (/ include/linux/gfp.h):
#define __GFP_WAIT ((__force gfp_t)___GFP_WAIT) /* Can wait and reschedule? */ #define __GFP_HIGH ((__force gfp_t)___GFP_HIGH) /* Should access emergency pools? */ #define __GFP_IO ((__force gfp_t)___GFP_IO) /* Can start physical IO? */ #define __GFP_FS ((__force gfp_t)___GFP_FS) /* Can call down to low-level FS? */ #define __GFP_COLD ((__force gfp_t)___GFP_COLD) /* Cache-cold page required */ #define __GFP_NOWARN ((__force gfp_t)___GFP_NOWARN) /* Suppress page allocation failure warning */ #define __GFP_REPEAT ((__force gfp_t)___GFP_REPEAT) /* See above */ #define __GFP_NOFAIL ((__force gfp_t)___GFP_NOFAIL) /* See above */ #define __GFP_NORETRY ((__force gfp_t)___GFP_NORETRY) /* See above */ #define __GFP_MEMALLOC ((__force gfp_t)___GFP_MEMALLOC)/* Allow access to emergency reserves */ #define __GFP_COMP ((__force gfp_t)___GFP_COMP) /* Add compound page metadata */ #define __GFP_ZERO ((__force gfp_t)___GFP_ZERO) /* Return zeroed page on success */ #define __GFP_NOMEMALLOC ((__force gfp_t)___GFP_NOMEMALLOC) /* Don't use emergency reserves.*/ #define __GFP_HARDWALL ((__force gfp_t)___GFP_HARDWALL) /* Enforce hardwall cpuset memory allocs */ #define __GFP_THISNODE ((__force gfp_t)___GFP_THISNODE)/* No fallback, no policies */ #define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE) /* Page is reclaimable */ #define __GFP_NOACCOUNT ((__force gfp_t)___GFP_NOACCOUNT) /* Don't account to kmemcg */ #define __GFP_NOTRACK ((__force gfp_t)___GFP_NOTRACK) /* Don't track with kmemcheck */ #define __GFP_NO_KSWAPD ((__force gfp_t)___GFP_NO_KSWAPD) #define __GFP_OTHER_NODE ((__force gfp_t)___GFP_OTHER_NODE) /* On behalf of other node */ #define __GFP_WRITE ((__force gfp_t)___GFP_WRITE) /* Allocator intends to dirty page */
(3-2) macro definition combination
Macro definition combination is to combine two or more of the above allocation mask macro definitions into one macro definition, so as to realize multiple function mask marks. Common macro definition combinations are as follows (/ include/linux/gfp.h):
#define GFP_ATOMIC (__GFP_HIGH) #define GFP_NOIO (__GFP_WAIT) #define GFP_NOFS (__GFP_WAIT | __GFP_IO) #define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS) #define GFP_TEMPORARY (__GFP_WAIT | __GFP_IO | __GFP_FS | \ __GFP_RECLAIMABLE) #define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL) #define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM) #define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE) #define GFP_IOFS (__GFP_IO | __GFP_FS) #define GFP_TRANSHUGE (GFP_HIGHUSER_MOVABLE | __GFP_COMP | \ __GFP_NOMEMALLOC | __GFP_NORETRY | __GFP_NOWARN | \ __GFP_NO_KSWAPD)
(Note: the code has not been pasted, please refer to the source code for details)
4, Summary
The process of allocating physical pages in linux is complex. Here is a diagram to summarize: