In Linux, the kernel is for each Open files provide three data structures to maintain them. The relationship between them determines the possible impact of one process on another in file sharing.
- Process level file descriptor table
- System level open file table
- inode table of the system
I Open file descriptor table
1. What is an open file descriptor table?
As we know, for each process, there is a data structure describing the process attributes: process control block (PCB). The PCB in Linux is called task_struct. Some of its source codes are as follows:

Note task_ There is a file in struct that describes the information of the open file_ Struct structure pointer files, we jump to the definition of this structure:

Opening the file descriptor table is actually files_ Member struct file * FD in struct_ Array [nr_open_default] it is a pointer array. Each element of the array is a pointer to file type. It can be imagined that these pointers will point to an open file, and the data structure file is used to describe an open file.
Question 1: FD_ What does the subscript of array mean?
The subscript number here is actually a file descriptor. Every time the process opens a file, it will create a file type structure for the file and fill the address of the structure into FD_ In the array, the filling rule is the smallest and unused, file_ Next in struct structure_ FD saves the next allocated file descriptor, which will be adjusted when calling open and close, so that each open returns the smallest currently available file descriptor. It also stipulates that when the process starts, three files are opened by default: 0 is standard input, 1 is standard output, and 2 is standard error. This means that if you open a new file at this time, its file descriptor will be 3, and then open a file, the file descriptor will be 4
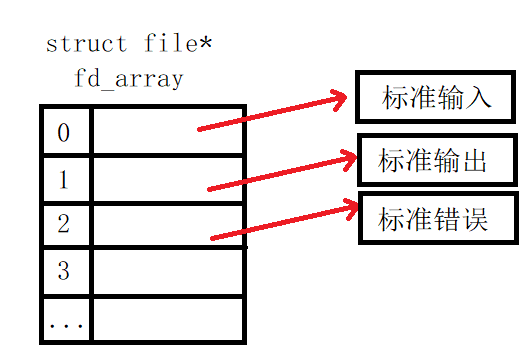
PS: the standard input, standard output and standard error here correspond to the keyboard, display and display, rather than stdin, stdout and stderr in C language. These three objects are FILE type objects defined in C language:

Question 2: how many file descriptors can each process open under Linux system configuration?
At the same time, in order to control the file resources consumed by each process, the kernel will also make a default limit on the maximum number of open files of a single process, that is, the user level limit. The default value of 32-bit system is 1024, and the default value of 64 bit system is 65535. You can use ulimit -n command to view.
I am the remote ECS that XShell logs in to. The maximum number of file descriptors of the process is set to 100001 by default.

There are also two ways to change user level restrictions: temporary change and permanent change:
- Temporary change: restore the original default value after restarting or disconnecting the XShell. Use the command ulimit -SHn xxxx to modify, where xxxx is the number to be set.
- Permanent changes: vim edit / etc / security / limits Conf file, modify hard nofile xxxx and soft nofile xxxx, where xxxx is the number to be set. Exit after saving.

Question 3: what is the method to view the open file descriptor table of the file process?
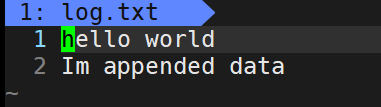
Execute the following procedure. After the process "mytest" starts, open a file log in the current directory Txt, and then the loop keeps the process in an open state.
//Executable name: mytest
void test()
{
int fd = open("log.txt", O_RDWR|O_CREAT, 0666);
while(1)
{}
}
Then copy the current shell, enter the command pidof mytest to obtain the pid number of the mytest process, and then ll /proc/pid/fd to view the list of file descriptors used by the "mytest" process.
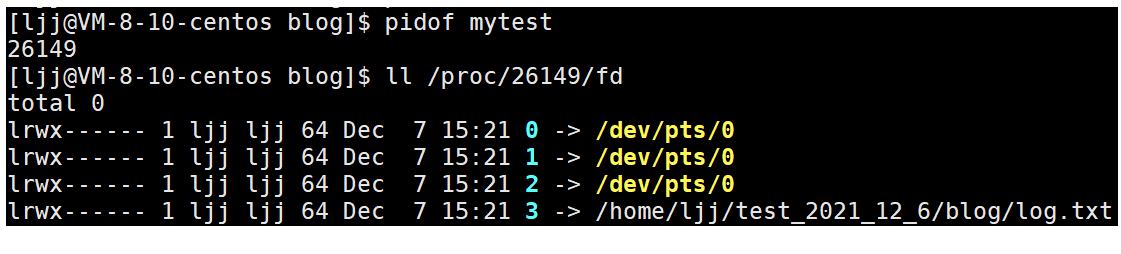
It is shown here that each entry in the open file descriptor table of the "mytest" process is a soft connection.
/dev/pts is the directory where the console device files created after remote login (telnet,ssh, etc.) are located. Because I log in remotely through Xshell, the file descriptors of standard input 0, standard output 1 and standard error 2 point to the virtual terminal console / dev/pts/6. And we opened the file log Txt refers to the absolute path where the file is located.
2. Why is there an open file descriptor table?
We know that in Linux system, everything can be regarded as files, and files can be divided into ordinary files, directory files, link files and device files. When operating these so-called files, we find the name every time, which will consume a lot of time and efficiency. Therefore, Linux stipulates that each file corresponds to an index, so when we want to operate the file, we can directly find the index and operate it. The file descriptor is the index created by the kernel to efficiently manage these opened files. It is a non negative integer used to refer to the opened files. All system calls executing I/O operations are implemented through the file descriptor.
3. Open the link between the file descriptor table and the process
Each process starts with a task assigned to it_ Struct structure, in task_ The struct structure contains a file_ Struct structure pointer to the files it points to_ The struct structure contains a pointer array FD whose element type is file *_ Array is the open file descriptor table, which stores the relationship between each file descriptor as an index and an open file. It is simply understood as an array in the following figure. The file descriptor (index) is the subscript of the array of file descriptor table, and the content of the array is the pointer to each open file.

2, Open file table
1. What is an open file table?
Next, let's take a look at the declaration of the file structure:
struct file {
// Record header node
union {
struct list_head fu_list;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;// File path, including directory entries and i-node
#define f_dentry f_path.dentry
#define f_vfsmnt f_path.mnt
const struct file_operations *f_op;// Holds a series of function pointers about file operations
spinlock_t f_lock;
#ifdef CONFIG_SMP
int f_sb_list_cpu;
#endif
atomic_long_t f_count;// File open times
unsigned int f_flags;// The flag when the file is opened corresponds to the flag parameter of the open function
fmode_t f_mode;// The mode when the file is opened corresponds to the mode parameter of the open function
loff_t f_pos;// File offset
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
#ifdef CONFIG_DEBUG_WRITECOUNT
unsigned long f_mnt_write_state;
#endif
};
Open the structure of the file table
Through the source code, it is found that there is a union f that defines a record header node in the file structure_ u:

It can be inferred that the file structures are connected through a linked list. Each file structure is called a file table item. The linked list formed by their combination is called the open file table. This table is system level and shared by all processes.

A structure that holds function pointers related to file operations
In the file structure, there is a struct file_operations *f_op object. The declaration of this structure stores a series of function pointers related to file read and write operations:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
};
The following describes the functions related to these system level file operations:
1.1 open file - Open
Function: when a file is opened in a specific way, the system will create a file table entry of its own file type for the open file, fill the address of the file table entry into the process level open file description table, and return the subscript, that is, the file descriptor.
Header file
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>
Function prototype (there are two forms, and we will mainly introduce the second form below)

Function parameters:
- Pathname: the pathname of the open file
- flags: used to control how files are opened
- mode: used to set the permission to create a file (rwx). It is valid only when there is o_create in flags.
Return value: if it is opened successfully, the file descriptor is returned; otherwise, - 1 is returned.
Detailed explanation of flags parameters:
- O_RDONLY: read only mode
- O_WRONLY: write only mode
- O_RDWR: read / write mode
The above three modes cannot appear in the flags parameter at the same time, but one must appear. The following parameters are optional.
- O_APPEND: the current file offset will be set to the end of the file every time the file is written, but it will not be affected when the file is read
- O_CREAT: if the file does not exist, you need to use the mode option to create it. To indicate access to the new file
- O_EXCL: if the file to be opened exists, there will be an error. You must and o_ Use o with the creat parameter_ TRUNC: clear the contents of the file while opening the file
- O_NOCTTY: if the open file is a terminal device, this device will not be set as the control terminal of the process
- O_NONBLOCK: if the open file is a pipe, a block device file or a character device file, subsequent I/O operations are set to non blocking mode
- O_SYNC: enables each write to wait until the physical I/O operation is completed, including the I/O required for file attribute update caused by the write operation.
Use examples:
int test1()
{
umask(0);
int fd = open("log.txt", O_RDWR|O_CREAT, 0666);
cout<<"fd:"<<fd<<endl;// fd:3
return 0;
}
Description 1: what is the current path
We know that when open opens a file by writing, if the file does not exist, the file will be automatically created in the current path. What does the current path refer to here?
void test1()
{
umask(0);
int fd = open("log.txt", O_RDWR, 0666);
cout<<"fd:"<<fd<<endl;
}
Still the program above, we are in the current directory cur_ Execute it under direct, and a file log is indeed generated in the current directory txt

Return to the parent directory, execute the executable program in the subdirectory in the parent directory, and find that the file is generated in the parent directory. It can be inferred that the so-called "if the file does not exist when opening the file, this file is in the current directory by default". The current path here refers to the path where the program is executed, not the path where the program itself is located.
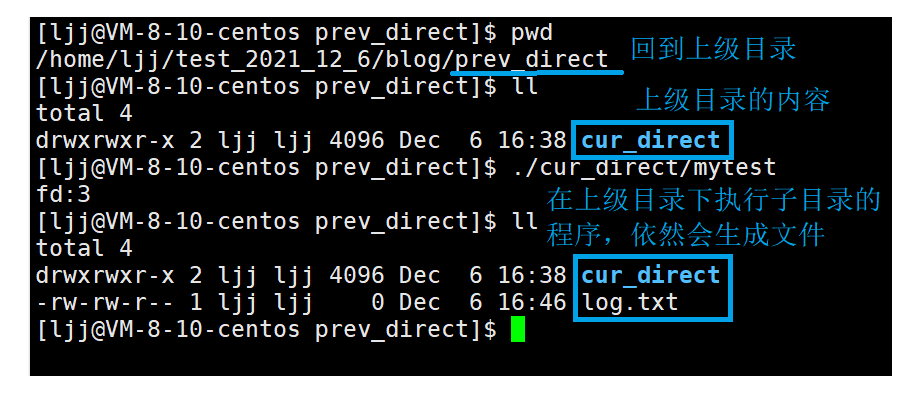
When the executable program runs and becomes a process, we can obtain the PID of the process, and then view the information of the process under the proc directory under the root directory according to the PID.

We can see two soft link files cwd and exe. cwd is the path where we are when the process is executed, and exe is the path where the executable program is located.
Note 2: specific meaning of the second parameter flags
This parameter corresponds to many options. These options can be used by bit or in combination. Why? In fact, these parameters are system defined macros.
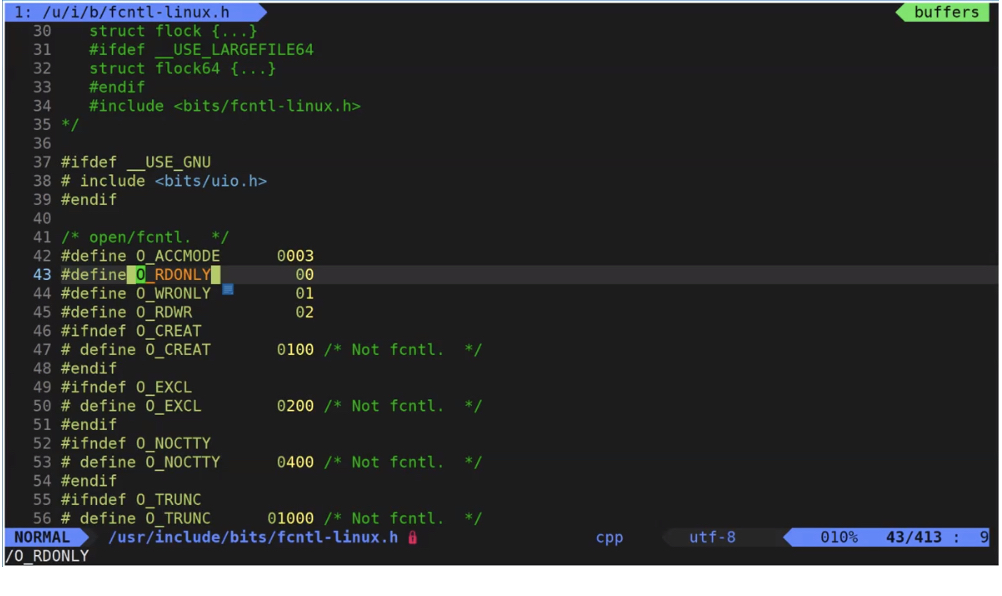
These parameters are integers with only one bit of 1, so theoretically there can be 32 parameters, so they can also be distinguished by bit or after. Which option is used.
F in PS: file structure_ Flags is the second parameter passed in when we open the file.

Note 3: usage scenario of the third parameter mode
The third parameter has o in the second parameter_ Use only when creat. If not, the third parameter can be ignored (corresponding to the first writing method of open(), there is no third parameter).
When creating a new file, we can specify the file permission mask. If we do not specify the new folder default permission mask=0666, i.e. - RW RW RW -, and the new directory default permission mask=0777, i.e. drwxrwxrwx, whether specified or not, the permission of the final actually created file = Mask & (~ umask). Umask here is the permission mask, The permission mask (umask) of ordinary users is 0002 by default, and that of super users is 0022 by default.
When the mode parameter is given by octal digits, such as 0777, an error should be corrected, that is, I think the 0 in front of the permission number represents the meaning of octal. In fact, this is not the case. The previous 0 represents the permission modification bit, that is, the permissions of set user ID bit, set group ID bit and sticky bit, so the first 0 must be written, Otherwise, an error will occur.
Generally speaking, the operation principle of umask is to compare the default permissions of new files. If the corresponding bit of umask is 1, the permissions on the corresponding bit of file permissions will be removed (if any).

Sometimes, in order to avoid the interference of umask, we can set the value of umask through the umask() function

The same mode value is also saved in the file structure:

1.2 close file - close
Function prototype: int close(int fildes);
Header file: #include < unistd h>
Function: strip the contents of the corresponding subscript (file table item address) of the process file descriptor table, and may also clear the corresponding file table item, that is, the file structure.
Return value: 0 is returned if the file is closed successfully, and - 1 is returned if the file is not closed successfully.
Question: do you want to delete the file structure of the corresponding file when closing the file?
As mentioned earlier, file table entries are system level, so it is possible that the open file descriptor tables of multiple processes point to the same file table entry. For example, this happens when a child process inherits the file descriptor table of the parent process; Or multiple file descriptors of the open file descriptor table of a process store the address of the same file table item, for example, through dup2 redirection, so whether a file table item is cleared or not depends on whether it is still used.
There is a member f in the file structure of the file table entry_ Count is used to record the number of times the file is opened. When each process executes close(), it will strip the file * address corresponding to the fd subscript in the open file descriptor table and make the F of the file_ Count minus one, if f_ When the count is reduced by one and becomes 0, the system will delete the file structure of the file.

1.3 read file - read() & & write file - write()
read
Function prototype: ssize_t read(int fd, void *buf, size_t count);
Header file: #include < unistd h>
Function: read count data from the file pointed to by fd to buf.
Return value: the number of bytes read is returned successfully. If there is an error, it returns - 1. If the end of the file has been reached before calling read, it returns 0 this time.
Description 1: about file offset location
There is a member f in the file structure_ POS, which records the current reading and writing position of the file. Each time you read and write, the corresponding offset will occur according to the incoming count.

Description 2: about return value
The return value type is ssize_t. Represents a signed size_t. In this way, the number of positive bytes can be returned 0 (indicating reaching the end of the file) can also return a negative value of - 1 (indicating an error). For example, when reading a regular file, it has reached the end of the file before reading count bytes. For example, if there are 30 bytes left from the end of the file and 100 bytes are requested to be read, read returns 30. At the same time, the current read-write position f_pos of the file moves to the last, and the next read will return 0.
write
Function prototype: ssize_t write(int fd, const void *buf, size_t count);
Header file: #include < unistd h>
Function: write count data from buf to the file pointed to by fd.
Return value: the number of bytes written is returned successfully, and - 1 is returned in case of error.
Use examples:
int test2()
{
// 1. Write to file
umask(0);
int fd = open("log.txt", O_WRONLY|O_CREAT, 0664);
const char* source = "I Can See You\n";
write(fd, source, strlen(source));
close(fd);
// 2. Read file contents to display
fd = open("log.txt", O_RDONLY);
char ch;
while(1)
{
ssize_t s = read(fd, &ch, 1);
if(s <= 0)
break;
write(1, &ch, 1);// File descriptor No. 1 corresponds to standard output
}
close(fd);
return 0;
}

1.4 encapsulation of Linux system call interface by C language
Different operating systems have different system call interfaces for files. For languages, in order to ensure that the same set of methods can be executed on different operating systems, it is necessary to encapsulate the interfaces of other operating systems. The following is an example of encapsulating Linux system call interface with the user operation interface of C language.

The data structure corresponding to FILE table entries in Linux is struct FILE, while the structure describing FILE information in C language is struct FILE. We can use / usr / include / stdio The following code can be seen in the H header FILE, which means that FILE is actually struct_ IO_ An alias for the FILE structure:
typedef struct _IO_FILE FILE;
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//Buffer correlation
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //File descriptor
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
Note that there are a lot of information about the IO buffer, which will be described later. In addition, there is an important member called_ fileno, this is the FILE descriptor, that is, a FILE descriptor is saved in each FILE structure.
C language also specifically declares three structure objects of FILE type: stdin, stdout and stderr. His own_ The values corresponding to fileno are 0, 1 and 2

Low level implementation of file operation function in C language
In C language, we use fopen function to open a FILE. When calling this function, the system will generate a FILE structure corresponding to the FILE, including allocation_ The value of fileno (the allocation rule is the smallest and unused), and then return the pointer of the FILE structure. The subsequent operations of reading, writing and closing files are completed through the pointer of the FILE structure. How to complete it? Get the value of member _filenoand call the system call interface, such as open, read, write, close, etc. in Linux.
Header file:#include <stdio.h> FILE *fopen(const char *path, const char *mode); size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); size_t fwrite(const void *ptr, size_t size, size_t nmemb,FILE *stream); int fclose(FILE *fp);
Low level implementation of input and output functions in C language
The input and output functions here refer to printf, fprintf, scanf, fscnaf, etc.
#include <stdio.h> int printf(const char *format, ...); int fprintf(FILE *stream, const char *format, ...); int scanf(const char *format, ...); int fscanf(FILE *stream, const char *format, ...);
We often use printf and scanf without directly seeing the parameters related to the file. Let's take a look at the example of fprintf:
void test()
{
fprintf(stdout, "hello world\n");//hello world
}
Here, the first parameter we pass in is stdout. After running, the results will be printed directly on the screen. Why? Because in stdout_ fileno is 1. As mentioned earlier, after a process runs, three file type file table items will be opened by default: standard input (keyboard), standard output (display) and standard error (display), and their addresses will be filled in the process level open file descriptor table with subscripts 0, 1 and 2:

When fprintf executes, first find the FILE in the FILE structure_ Fileno, then invoke the system call interface write to write the contents of the following parameters to the In the FILE corresponding to fileno FILE descriptor, in stdout_ The fileno value is 1. The corresponding open FILE descriptor table points to the standard output, so the content is written to the standard output. In fact, the bottom layer of printf is to call fprintf to fix the first parameter and pass it into stdout for implementation. The same is true for fscanf and scanf, but the first parameter passed in is stdin.
1.5 implementation principle of redirection
The essence of redirection is to modify the content of struct file * corresponding to the subscript of the file descriptor. There are two modification methods:
- Indirect modification: close the file descriptor you want to redirect to before opening the file, so that the later opened file will be assigned to the file descriptor you just closed.
- Direct modification: directly modify the value corresponding to the subscript of the file descriptor through the dup2 function.
PS: the following examples implement redirection by indirect modification.
Output redirection
Output redirection is to output what we should have output to one file to another file.
For example, the content that should be output to the display is finally output to the file log Txt: at the beginning, we close the file (i.e. standard output) pointed to by the No. 1 file descriptor, and then open a new file log.txt, so that the file descriptor assigned to log.txt is 1, and then use write to write to the file pointed to by the No. 1 file descriptor, so that the content will not be written to the display, but will be written to log and TXT.
void test()
{
close(1);
umask(0);
int fd = open("log.txt", O_WRONLY|O_CREAT, 0664);
// Call the write function of the c interface
printf("hello world");
}
After running the program, nothing is output on the screen. Let's take a look at log Txt found content written:

Append redirection
The only difference between append redirection and output redirection is that output redirection is overlay output data, while append redirection is append output data.
For example, we want to output the file log created by redirection just now Txt, just change the incoming option to: O_WRONLY|O_APPEND:
void test()
{
close(1);
int fd = open("log.txt", O_WRONLY|O_APPEND);
printf("Im appended data");
}
After executing the program, it is found that the content that should have been output to the display is redirected to log in an additional way Txt:
input redirection
Input redirection is to redirect the data we should have read from one file to read from another file.
For example, we want to change the scanf function that should read data from "standard input" to log Txt file. Then we can open log Close the file with file descriptor 0 before TXT file, that is, close "standard input". In this way, when we subsequently open log Txt file, the file descriptor assigned is 0, and scanf is from log Txt.
void test()
{
close(0);
int fd = open("log.txt", O_RDONLY);
char str[40];
while (scanf("%s", str) != EOF)
{
printf("%s\n", str);
}
close(fd);
}
Execute the program and directly output from log Txt:

2. What is the function of opening the file table?
The open file table is composed of file table entries. These file table entries contain function pointers for file read-write operations and member variables related to read-write operations: F of record offset_ POS, F of record permission_ Mode, F of the operation mode of the record file_ Flag, etc. In the process of reading and writing files, the corresponding file table items are found in the file descriptor table according to the imported file descriptors. Finally, the read and write functions in the file table items are called.
3. Open the connection between the file table and the process
Different file descriptors of the same process can point to the same file table entry. For example, change the contents of the file descriptor through the dup function:

When a child process is created, it copies the open file descriptor table of the parent process. Therefore, when a child process is just created, the parent and child processes share file table entries, as shown in the figure:

III inode table
1. What is inode?
There is an F in the file structure of the file table entry_ Path member, which is a variable of struct path type. This type is defined as follows:
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
};
Continue to look at the definition of struct dentry:
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
unsigned int d_count; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
};
Note in particular that there is a member D in this structure_ Inode, whose type struct inode is defined as follows:
struct inode {
umode_t i_mode;// file right
uid_t i_uid; // Owner id
gid_t i_gid; // Group id
const struct inode_operations *i_op;// Directory operation function
struct super_block *i_sb;// Pointer to super fast
spinlock_t i_lock;// File lock
unsigned int i_flags;// File opening method
struct mutex i_mutex;
unsigned long i_state;
unsigned long dirtied_when;
// Header of inode table
struct hlist_node i_hash;
struct list_head i_wb_list;
struct list_head i_lru;
struct list_head i_sb_list;
union {
struct list_head i_dentry;
struct rcu_head i_rcu;
};
unsigned long i_ino;// inode number
atomic_t i_count;// inode open times
unsigned int i_nlink;// Number of file hard links
dev_t i_rdev;
unsigned int i_blkbits;
u64 i_version;
loff_t i_size;// file size
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
struct timespec i_atime;// The time when the file was last accessed
struct timespec i_mtime;// Last modification time of file content
struct timespec i_ctime;// Last modification time of file attribute
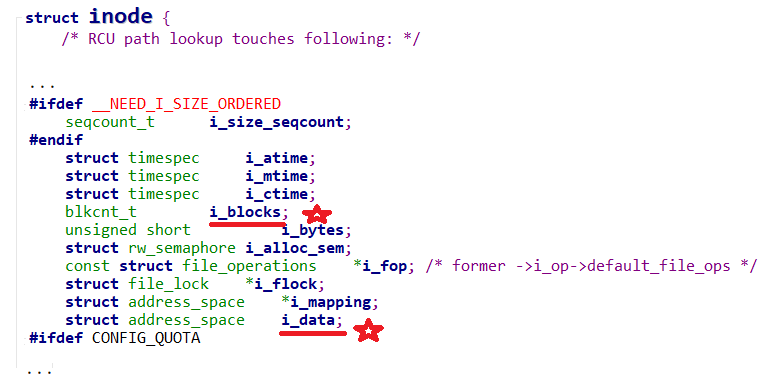
blkcnt_t i_blocks;// Number of blocks
unsigned short i_bytes;
struct rw_semaphore i_alloc_sem;
const struct file_operations *i_fop; // File operation function / * former - > I_ op->default_ file_ ops */
struct file_lock *i_flock;
struct address_space *i_mapping;// Block address mapping
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];
#endif
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
};
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct hlist_head i_fsnotify_marks;
#endif
#ifdef CONFIG_IMA
atomic_t i_readcount; /* struct files open RO */
#endif
atomic_t i_writecount;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
void *i_private; /* fs or device private pointer */
};
The inode here is the component of the inode table. Each inode is organized in the form of a double linked list, which is the so-called inode table
So what does inode describe?
1.1 understanding inode from content
Any resource in the Linux operating system is managed as a file. Such as directory, optical drive, terminal device, etc., are regarded as a kind of file. In this regard, all directories and hardware devices in the Linux operating system have the same properties as ordinary files. These attributes are stored in inode blocks.
Attributes are also called meta information, such as creation and modification time. These basic attributes can be viewed through the: ls -l command. However, it should be noted that one attribute is not included in the inode node, that is, the file name. Why do you explain it later when you talk about the directory.
Let's explain the members in several struct inode s:
1. Array of function pointers for directory operations
Member I in inode_ OP, type const struct inode_operations *, defined as follows:
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
void * (*follow_link) (struct dentry *, struct nameidata *);
int (*permission) (struct inode *, int, unsigned int);
int (*check_acl)(struct inode *, int, unsigned int);
int (*readlink) (struct dentry *, char __user *,int);
void (*put_link) (struct dentry *, struct nameidata *, void *);
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,int,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
void (*truncate) (struct inode *);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start,
u64 len);
} ____cacheline_aligned;
It can be seen that the data structure pointed to by the member variable contains many function pointers, most of which are directed to the directory file. Of course, inode also has a data structure for ordinary file operation: struct file_ An object of type operations also has one in the file structure.
2. inode number
Member i_ino represents the inode number of the file. Each file has its own inode number after it is created. The inode number is the unique identification of the file.
Command to view file inode number: ls -i

3. inode open times
The previous file structure has a member called f_count records the number of times the file table entry is put into the open file descriptor table, and the file table entry is returned every close f_count corresponds to minus one. The file structure will not be deleted until it is finally reduced to 0. The inode corresponding here also has a member called i_count has the same function, but note that inodes are stored in the file structure.
4. Soft and hard links
Hard link
Generally, the file name and inode number are "one-to-one correspondence", and each inode number corresponds to a file name. However, the Linux system allows multiple file names to point to the same inode number.
This means that the same content can be accessed with different file names; Modifying the file content will affect all file names; However, deleting one file name does not affect access to another file name. This situation is called "hard link".
Commands for creating hard links: ln source files destination files
After running the above command, the inode numbers of the source file and the target file are the same, pointing to the same inode. There is an item called "number of links" in the inode information, which records the total number of file names pointing to the inode. At this time, it will increase by 1.
Conversely, deleting a file name will reduce the "number of links" in the inode node by 1. When this value is reduced to 0, it indicates that there is no file name pointing to the inode, and the system will recycle the inode number and its corresponding block area.
After we create a new directory, we can directly view the number of hard links in the new directory:

This data is stored in I in the inode structure_ Nlink members, so why is the number of hard links in the newly created directory 2 at the beginning?
When creating a directory, the new directory will generate two directory items by default: "." and "...". The inode number of the former is the inode number of the current directory, which is equivalent to the "hard link" of the current directory; The inode number of the latter is the inode number of the parent directory of the current directory, which is equivalent to the "hard link" of the parent directory. The directory itself plus "." under the directory All point to the same inode, so the number of connections is 2. The total number of "hard links" of any last directory is always equal to 2 plus the total number of its subdirectories (including hidden directories).
Soft connection
In addition to hard links, there is a special case.
Although the inode numbers of file A and file B are different, the content of file A is the path of file B. When reading file A, the system will automatically direct visitors to file B. Therefore, no matter which file is opened, the final read is file B. At this time, file A is called "soft link" or "symbolic link" of file B.
This means that file A depends on file B. if file B is deleted, opening file A will report an error: "No such file or directory". This is the biggest difference between soft links and hard links: file A points to the file name of file B instead of the inode number of file B, and the inode "number of links" of file B will not change.
Command to create a hard link: ln -s source file or directory target file or directory
1.2 understanding inode from ext2 file system
Disk structure

- The hard disk is composed of layers of disks, and the structure is similar to several layers of circular houses
- Each layer of disk (the three layers of yellow edged blue disk in the figure) has two sides (disk surface) for reading and writing.
- There are several concentric circular tracks on each side (which can be understood as some circular tracks on the disk).
- The sector (a sector in the figure) is an arc on the track (see the track as a circle).
- For each track on different disks, coplanar tracks can be found on other disks, and their common surface is called cylinder (the orange dotted line in the figure is a dotted line on the surface).
- The reading and writing of magnetic disk is completed by the track finding, sector turning, data reading and writing of magnetic head. Its physical principle is related to the hysteresis of ferrite.
Disk partition
Disk partition is to tell the operating system that "the accessible area of my disk in this partition is the block between cylinder a and cylinder B", so that the operating system knows that it can read, write and find file data in the specified block. Disk partition is the starting and ending cylinder of the specified partition. A disk can be divided into multiple partitions. Each partition must be formatted into a file system of a certain format with formatting tools (such as mkfs command) before storing files. During the formatting process, some information managing the storage layout will be written on the disk. A partition can only be formatted into a file system.
Reasons for partition formatting: the file attributes / permissions configured by each operating system are different. In order to store the data required by these files, the partition needs to be formatted to become the "file system format" that the operating system can use.
In Windows, disks are usually divided into C disk, D disk, E disk, etc

In Linux system, you can view the usage of disk space through df command:
- a: Displays the disk usage of all file systems and partitions
- i: Displays the usage of i -nodes
- k: The size is expressed in K (the default)
- h: To display all file system details and usage in gigabytes or gigabytes
- x: Displays the disk usage of all partitions that are not part of a file system
- T: Displays the name of the file system to which each partition belongs

ext2 file system
ext2 second-generation extended file system (ext2) is the file system used by Linux kernel. It was added to Linux core support in January 1993.
How does the file system work? This is related to the file data of the operating system. In addition to the actual content of the file, the file data of newer operating systems usually contain many attributes, such as file permissions (rwx) and file attributes (owner, group, time parameters, etc.) of Linux operating system. The file system usually stores the data of these two parts in different blocks. The permissions and attributes are placed in inode, and the actual data is placed in data block. In addition, there is a superblock that records the overall information of the entire file system, including the total amount, usage and remaining amount of inodes and blocks.


The partition introduced at the beginning is the first layer structure in the figure above. Next, we introduce the second layer structure: group structure, including startup block and block group. Boot block is used to store disk partition information and boot information. No file system can modify the boot block. The ext2 file system starts after starting blocks, which divides the entire partition into several block groups of the same size.
Composition of each block group
1. Super block describes the file system information of the entire partition, such as the size, total amount, usage and remaining amount of inode/block, as well as the format and related information of the file system. A superblock has a copy at the beginning of each block group (the first block group must exist, and the following block groups may not). In order to ensure that the file system can work normally in case of physical problems in some sectors of the disk, it is necessary to ensure that the super block information of the file system can be accessed normally in this case. Therefore, the super block of a file system will be backed up in multiple block groups, and these super block areas The data are consistent.
The information recorded by the super block includes:
- Saves the size of the file system and the size of the blocks and inode s used
- Total number of block s and inode s of the entire file system
- Number of unused and used inodes / blocks;
- File system mounting time, time of last data writing, time of last disk verification (fsck) and other file system related information;
- A valid bit value. If the file system is mounted, the valid bit is 0. If it is not mounted, the valid bit is 1.
PS: the information of each section and superblock can be queried with the command dump2fs

Super fast effect
When the operating system starts, the system kernel will copy the contents of the super block into memory, and periodically use the latest contents in memory to update the contents of the super block on the hard disk. Because there is a time difference in this update, the super block information in the memory and the super block information in the hard disk are often synchronized only at a specific time of power on and power off; It is out of sync at other times. Suppose that when the operating system crashes unexpectedly or an accident caused by power failure, the super block information in the memory is not saved to the hard disk in time, and the integrity of the file system will be damaged. If it is light, it will lead to the loss of the newly established file system. If it is serious, it will lead to the paralysis of the file system. In this case, system engineers often need to use the sync command provided by the system to copy the contents of memory to disk at the moment of system failure. This process is often completed automatically by the operating system, which is an important reason why the Unix operating system is more stable than the Windows operating system. When the operating system restarts, the system kernel compares the two and labels the file system clean or dirty according to the differences between them. This information is also stored in the super block of the file system.
It can be seen that if the super block is damaged, it will be very destructive to the file system. If it is light, a file system cannot be mounted, and if it is serious, the entire operating system will crash. In the Linux operating system, in addition to using the sync command to ensure that the content on the hard disk will never be updated slower than that in the memory, the operating system will save the super block content to different block groups. When there is a problem with one of the superblocks, the operating system will automatically adopt the other superblock. When the system runs normally, the system content will replace the failed superblock with the available superblock, and the file system and operating system can be mounted and started normally. Otherwise, as long as one super block is available, the whole file system will be broken. This mechanism greatly improves the security of super block and the stability of Linux operating system.
Super fast location in inode source code
There will be a pointer to super fast in inode:

2. The block Group Descriptor Table (GDT) stores the description information of the block group. The whole partition is divided into multiple block groups, which corresponds to how many block group descriptors there are.
Each block group descriptor stores the description information of a block group, such as where to start with inode Table, where to start with Data Blocks, how many idle inodes and Data Blocks in this block group, and so on. The block group descriptor has a copy at the beginning of each block group.
3. Block bitmap is used to describe which blocks in the whole block group have been used and which blocks are free. The block bitmap itself occupies a block, in which each bit represents a block of the block group. This bit is 1, indicating that the block is used, and 0, indicating that it is idle and available. Assuming that the block size is 1KB during formatting, a block bitmap of this size can represent the occupation of 1024 * 8 blocks. Therefore, a block group can have 10248 blocks at most.
4. Like a block bitmap, an inode bitmap occupies a block, and each bit indicates whether an inode is free and available. Inode bitmap is used to record the usage of inode area in the block group.
5. An inode table consists of all inodes in a block group. In addition to data storage, some description information of a file also needs to be stored, such as file type, permission, file size, creation, modification, access time, etc. these information is stored in inode rather than data block. The number of blocks in the inode table must be written into the block group descriptor when formatting. In the ext2 file system, the location of each file on the disk is indexed by an inode pointer in the file system block group. Inode will point to some blocks that actually record file data. It should be noted that these blocks may belong to the same block group as inode or different block groups. We call these blocks that actually record file data on the file system Data blocks.
6. A data block is a place where file content data is placed. According to different file types, there are the following situations:
- For ordinary files, the data of the file is stored in data blocks.
- For directory files, the file names and inode numbers of all files in the directory are stored, so that we can access the contents and data of the file by getting the file names in the directory and finding the corresponding inode numbers. Therefore, the file names are not stored in the inode, but are stored in the data block of the directory.
- For compliant links, if the target pathname is short, it will be saved directly in inode. If it is long, a data block will be allocated to save.
- Special files such as device files, FIFO and socket have no data blocks.
Data block in inode source code
The correspondence between the data blocks used by a file and the inode structure is maintained through an array. The array can generally store 15 elements, of which the first 12 elements correspond to the 12 data blocks used by the file, and the remaining three elements are the primary index, secondary index and tertiary index. When the number of data blocks used by the file exceeds 12, These three indexes can be used for data block expansion. This array corresponds to the member I in the inode_ In addition, inode has a member I that records the number of blocks_ blocks.
2. Why is there an inode table?
Due to the separation of inode number and file name, this mechanism leads to some unique phenomena of Unix/Linux system.
-
Sometimes, the file name contains special characters and cannot be deleted normally. At this time, deleting the inode node directly can play the role of deleting files.
-
Moving or renaming a file only changes the file name without affecting the inode number.
-
After opening a file, the system identifies the file with the inode number, regardless of the file name. Therefore, generally speaking, the system cannot know the file name from the inode number.
The third point makes the software update simple. It can be updated without shutting down the software without restarting. Because the system identifies the running file by inode number, not by file name. When updating, the new version of the file will generate a new inode with the same file name, which will not affect the running file. The next time you run the software, the file name will automatically point to the new file, and the inode of the old file will be recycled.
3. Relationship between inode table and process
Each file in the disk corresponds to an inode, and each file table entry points to an inode of A file, However, the inode of the same file can correspond to multiple file table entries (this happens when open is called multiple times to open the same file, whether the same process opens the same existing file multiple times (as shown in the figure, the file descriptors 0 and 2 of process A correspond to two file table entries, but ultimately point to the same inode, that is, the same file), or do different processes open the same existing file multiple times (as shown in the figure, the file descriptor 3 of process A and the file descriptor 3 of process B)).
