I. Explanation
Kernel version for 4.4.10.
This article is just a simple note for me to read the source code. If you want to understand the implementation of epoll, I strongly recommend the following article:
The Implementation of epoll(1)
The Implementation of epoll(2)
The Implementation of epoll(3)
The Implementation of epoll(4)
2. epoll_create()
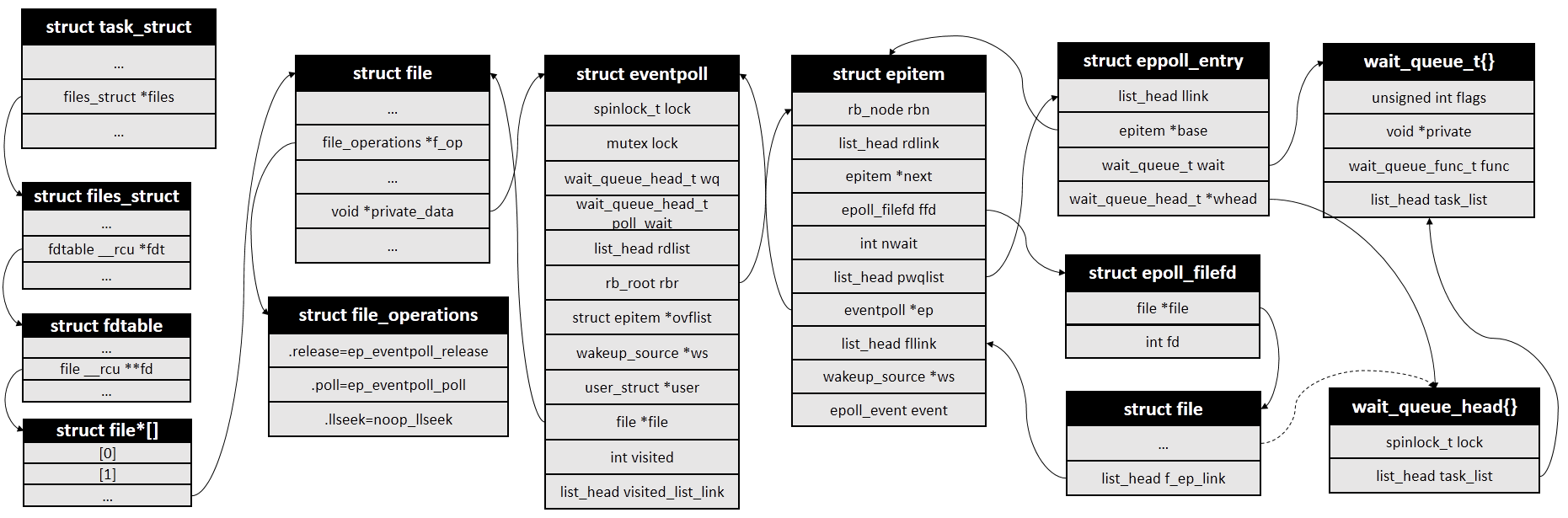
The system call epoll_create() creates an epoll instance and returns the corresponding file descriptor fd for that instance. In the kernel, each epoll instance corresponds to an object of struct event poll type, which is the core of epoll. statement In the fs/eventpoll.c file.
The interface of epoll_create is defined in Here The main source code analysis is as follows:
First, create a struct event poll object:
struct eventpoll *ep = NULL;
...
error = ep_alloc(&ep);
if (error < 0)
return error;
Then assign an unused file descriptor:
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
if (fd < 0) {
error = fd;
goto out_free_ep;
}
Then create a struct file object, set the struct file_operations*f_op in the file to the global variable eventpoll_fops, and point void*private to the newly created eventpoll object ep:
struct file *file;
...
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep, O_RDWR | (flags & O_CLOEXEC));
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto out_free_fd;
}
Then set the file pointer in eventpoll:
ep->file = file;
Finally, the file descriptor is added to the file descriptor table of the current process and returned to the user.
fd_install(fd, file);
return fd;
After the operation, the main structure relations are as follows:
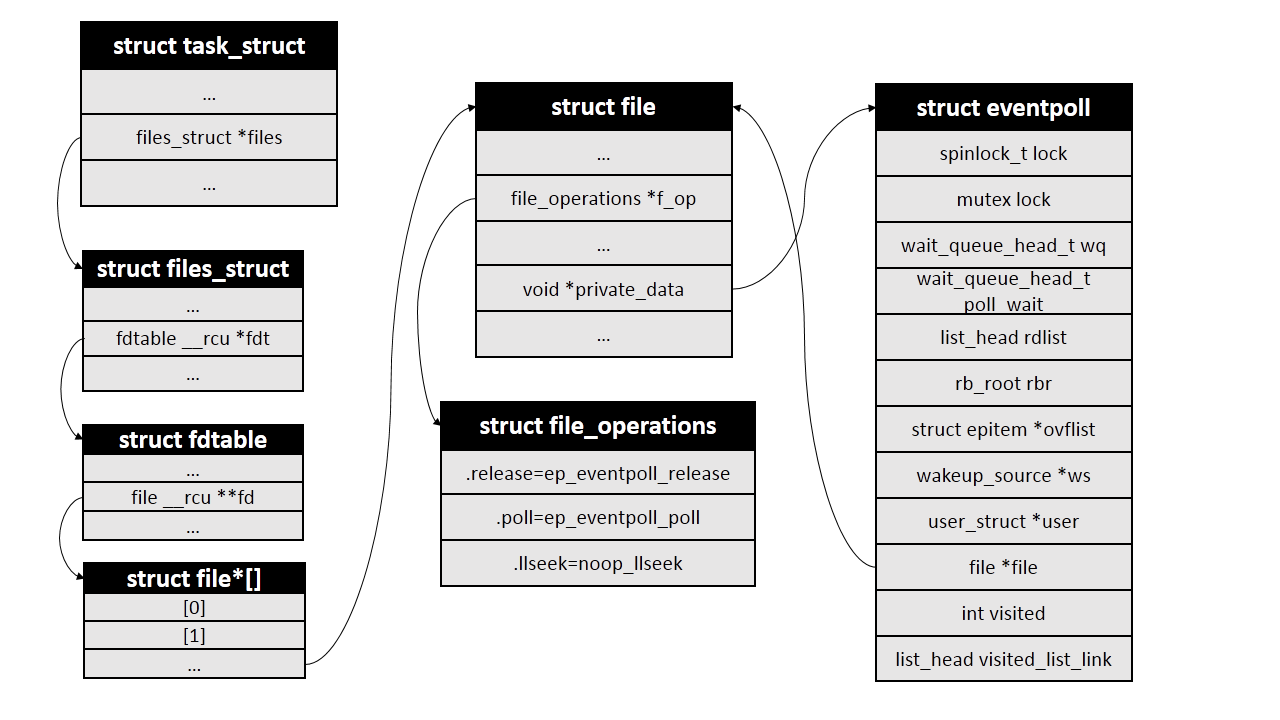
3. epoll_ctl()
The system call epoll_ctl() is defined in the kernel as follows. The meaning of each parameter can be found in the man Manual of epoll_ctl.
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd, struct epoll_event __user *, event)
epoll_ctl() first determines whether op is a deletion operation or not, and if not, copies the event parameter from user space to the kernel:
struct epoll_event epds;
...
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
ep_op_has_event() actually determines whether OP is a deletion operation:
static inline int ep_op_has_event(int op)
{
return op != EPOLL_CTL_DEL;
}
Next, we determine whether the user has set the EPOLLEXCLUSIVE flag, which is only available in the 4.5 version of the kernel. The main purpose is to solve the "shock" problem caused by adding the same file descriptor to multiple instances of epoll at the same time. Here . There are some restrictions on the setting of this flag, such as setting it only in the EPOLL_CTL_ADD operation, and the corresponding file descriptor itself cannot be an epoll instance. The following code checks these restrictions:
/*
*epoll adds to the wakeup queue at EPOLL_CTL_ADD time only,
* so EPOLLEXCLUSIVE is not allowed for a EPOLL_CTL_MOD operation.
* Also, we do not currently supported nested exclusive wakeups.
*/
if (epds.events & EPOLLEXCLUSIVE) {
if (op == EPOLL_CTL_MOD)
goto error_tgt_fput;
if (op == EPOLL_CTL_ADD && (is_file_epoll(tf.file) ||
(epds.events & ~EPOLLEXCLUSIVE_OK_BITS)))
goto error_tgt_fput;
}
Next, the struct file object is obtained step by step from the incoming file descriptor, and the struct event poll object is obtained from the private_data field in the struct file:
struct fd f, tf; struct eventpoll *ep; ... f = fdget(epfd); ... tf = fdget(fd); ... ep = f.file->private_data;
If the file descriptor itself represents an epoll instance, it may cause a dead loop, which is checked by the kernel and an error is returned if there is a dead loop. I haven't looked at this part of the code yet. It's not posted here anymore.
Next, the epollitem object corresponding to the monitored file is found in the red-black tree of the epoll instance. If it does not exist, that is, it has not been added before, it will return NULL.
struct epitem *epi; ... epi = ep_find(ep, tf.file, fd);
The essence of the ep_find() function is a red-black tree search process. The comparison function used in the search and insertion of the red-black tree is ep_cmp_ffd(), which first compares the address size of the struct file object, and then compares the file descriptor size in the same case. One case where the address of the struct file object is the same is when different file descriptors are pointed to the same struct file object through dup() system call.
static inline int ep_cmp_ffd(struct epoll_filefd *p1,
struct epoll_filefd *p2) { return (p1->file > p2->file ? +1: (p1->file < p2->file ? -1 : p1->fd - p2->fd)); }
Next, we will do different processing according to the operator op. Here we only look at the addition operation when op equals EPOLL_CTL_ADD. The first step is to determine whether the address of the epollitem object returned in the previous step is NULL, not NULL, which indicates that the file has been added and returns an error. Otherwise, the ep_insert() function is called to perform the real addition operation. The kernel automatically adds POLLERR and PLOLLHUP events to the file before adding it.
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tf.file, fd, full_check);
} else
error = -EEXIST;
if (full_check)
clear_tfile_check_list();
When ep_insert() returns, the full_check flag is judged, which is related to the dead cycle detection mentioned above, and is omitted here.
IV. ep_insert()
In the ep_insert() function, we first determine whether the number of files monitored in the epoll instance has exceeded the limit. No problem, we create an epollitem object for the file to be added:
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
user_watches = atomic_long_read(&ep->user->epoll_watches);
if (unlikely(user_watches >= max_user_watches))
return -ENOSPC;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
Next is the initialization of epollitem:
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
if (epi->event.events & EPOLLWAKEUP) {
error = ep_create_wakeup_source(epi);
if (error)
goto error_create_wakeup_source;
} else {
RCU_INIT_POINTER(epi->ws, NULL);
}
Next comes the more important operation: add the epollitem object to the waiting queue of the monitored file. The waiting queue is actually a list of callback functions defined in /include/linux/wait.h Document. Because different file systems have different implementations, it is impossible to get the waiting queue directly through the struct file object, so we use the poll operation of struct file to return the waiting queue of the object in the way of callback. The callback function set here is ep_ptable_queue_proc:
struct ep_pqueue epq; ... /* Initialize the poll table using the queue callback */ epq.epi = epi; init_poll_funcptr(&epq.pt, ep_ptable_queue_proc); /* * Attach the item to the poll hooks and get current event bits. * We can safely use the file* here because its usage count has * been increased by the caller of this function. Note that after * this operation completes, the poll callback can start hitting * the new item. */ revents = ep_item_poll(epi, &epq.pt);
The function of the structure ep_queue in the above code is to get the corresponding epollitem object in the poll callback function, which is very common in the Linux kernel.
In the callback function ep_ptable_queue_proc, the kernel creates a struct EP poll_entry object, and then sets the callback function in the waiting queue to ep_poll_callback(). That is to say, ep_poll_callback() is called back when an event occurs in the monitored file, such as when socker receives data. ep_ptable_queue_proc() code is as follows:
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
The structural relationships of eppoll_entry and epitem are as follows:
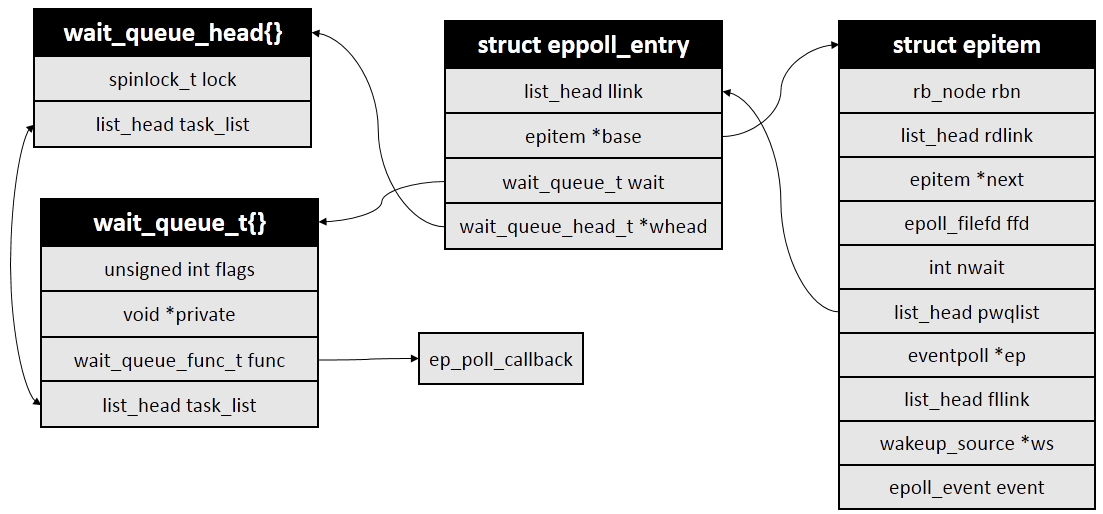
Back to the ep_insert() function. After the ep_item_poll() call is completed, the fllink field in the epitem is added to the f_ep_links list in the struct file, so that all the corresponding struct epollitem objects can be found through the struct file, and then the struct event poll corresponding to all the epoll instances can be found through the struct epollitem.
spin_lock(&tfile->f_lock); list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links); spin_unlock(&tfile->f_lock);
Then epollitem is inserted into the red-black tree:
ep_rbtree_insert(ep, epi)
Finally, the state is returned after the update, and the insertion operation is completed.
Before returning, you will also determine whether the file you just added is ready for the current event. If so, add it to the ready list of epoll. As for the ready list in the next section, I will skip it here.
Finally, I drew a structural diagram between several structures.