Basic Usage
The text of log.txt is as follows:
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongoUsage 1: awk '{[pattern] action}' {filenames}
# Each line is divided by space or TAB, and 1 or 4 items in the text are output
[root@peipei3514 usr]# awk '{print $1,$4}' log.txt
2 a
3 like
This's
10 orange,apple,mongo
# Format output
[root@peipei3514 usr]# awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
2 a
3 like
This's
10 orange,apple,mongoUsage 2: awk-f, - F is equivalent to the built-in variable FS, specifying the split character
# Use "," split
[root@peipei3514 usr]# awk -F , '{print $1,$2}' log.txt
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
# Or use built-in variables
[root@peipei3514 usr]# awk 'BEGIN{FS=","} {print $1,$2}' log.txt
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
# Use multiple delimiters. First use space to split, then use "," to split the result
[root@peipei3514 usr]# awk -F '[ ,]' '{print $1,$2,$5}' log.txt
2 this test
3 Are awk
This's a
10 There appleUsage 3: awk-v, set variable
[root@peipei3514 usr]# awk -v a=1 '{print $1,$1+a}' log.txt
2 3
3 4
This's 1
10 11
[root@peipei3514 usr]# awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
2 3 2s
3 4 3s
This's 1 This'ss
10 11 10sUsage 4: awk -f {awk script} {filename}
[root@peipei3514 usr]# awk -f cal.awk log.txtoperator
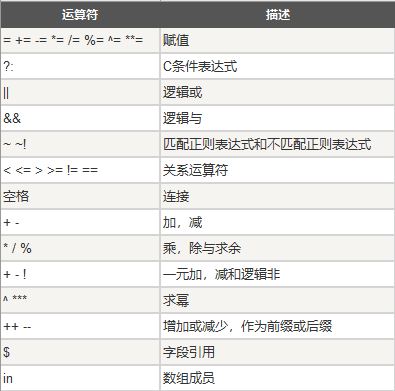
# Filter rows with first column greater than 2
[root@peipei3514 usr]# awk '$1>2' log.txt
3 Are you like awk
This's a test
10 There are orange,apple,mongo
# Filter rows with first column equal to 2
[root@peipei3514 usr]# awk '$1==2 {print $1,$3}' log.txt
2 is
# Filter that the first column is greater than 2 and the second column is equal to 'Are'Row
[root@peipei3514 usr]# awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt
3 Are youBuilt in variables

[root@peipei3514 usr]# awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt
FILENAME ARGC FNR FS NF NR OFS ORS RS
---------------------------------------------
log.txt 2 1 5 1
log.txt 2 2 5 2
log.txt 2 3 3 3
log.txt 2 4 4 4
[root@peipei3514 usr]# awk -F\' 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt
FILENAME ARGC FNR FS NF NR OFS ORS RS
---------------------------------------------
log.txt 2 1 ' 1 1
log.txt 2 2 ' 1 2
log.txt 2 3 ' 2 3
log.txt 2 4 ' 1 4
[root@peipei3514 usr]# awk '{print NR,FNR,$1,$2,$3}' log.txt
1 1 2 this is
2 2 3 Are you
3 3 This's a test
4 4 10 There are
[root@peipei3514 usr]# awk '{print $1,$2,$5}' OFS=" $ " log.txt
2 $ this $ test
3 $ Are $ awk
This's $ a $
10 $ There $ Using regular, string matching
# The second output column contains "th",And print the second and fourth columns
# ~ Indicates the start of the mode.// Mode in.
[root@peipei3514 usr]# awk '$2 ~ /th/ {print $2,$4}' log.txt
this a
# Output includes"re" Row
[root@peipei3514 usr]# awk '/re/ ' log.txt
3 Are you like awk
10 There are orange,apple,mongoignore case
[root@peipei3514 usr]# awk 'BEGIN{IGNORECASE=1} /this/' log.txt
2 this is a test
This's a testPattern inversion
[root@peipei3514 usr]# awk '$2 !~ /th/ {print $2,$4}' log.txt
Are like
a
There orange,apple,mongo
[root@peipei3514 usr]# awk '!/th/ {print $2,$4}' log.txt
Are like
a
There orange,apple,mongoawk script
For awk scripts, we need to pay attention to two keywords: BEGIN and END.
- BEGIN {this is the statement before execution}
- {this is the statement to be executed when processing each line}
- END {this is the statement to be executed after all the lines are processed}
Suppose there is a document (student transcript):
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62Our awk script is as follows:
#!/bin/awk -f
#Before running
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#In operation
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#After operation
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}Let's look at the implementation results:
[root@peipei3514 usr]# awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
---------------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
Tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
---------------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.00Other examples
AWK's hello world program is:
BEGIN { print "Hello, world!" }Calculate file size
$ ls -l *.txt | awk '{sum+=$6} END {print sum}'
--------------------------------------------------
666581Find lines greater than 80 in the file
awk 'length>80' log.txtPrint multiplication table
[root@peipei3514 usr]# seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
1x1=1
1x2=2 2x2=4
1x3=3 2x3=6 3x3=9
1x4=4 2x4=8 3x4=12 4x4=16
1x5=5 2x5=10 3x5=15 4x5=20 5x5=25
1x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=36
1x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=49
1x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=64
1x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81