fork system call
#include <sys/types.h> #include <unistd.h> /* Clone the calling process, creating an exact copy. Return -1 for errors, 0 to the new process, and the process ID of the new process to the old process. */ extern __pid_t fork (void) __THROWNL;
Each call of this function returns twice. In the parent process, the PID of the child process is returned, and in the child process, 0 is returned. The return value is the basis for subsequent codes to judge whether the current process is a parent process or a child process. When the fork call fails, it returns - 1 and sets ermo.
The fork function copies the current process and creates a new process table entry in the kernel process table. The new schedule entry has many properties that are the same as the original process, such as the value of heap pointer, stack pointer and flag register. However, many attributes are given new values. For example, the PPID of the process is set to the PID of the original process, and the signal bitmap is cleared (the signal processing function set by the original process no longer works on the new process).
The code of the child process is exactly the same as that of the parent process, and it also copies the data of the parent process (heap data, stack data and static data). The so-called copy on write is used for data replication, that is, replication occurs only when any process (parent process or child process) performs a write operation on the data (first page loss interrupt, and then the operating system allocates memory to the child process and copies the data of the parent process). Even so, if we allocate a lot of memory in the program, we should be very careful when using fork to avoid unnecessary memory allocation and data replication.
In addition, after the child process is created, the file descriptor opened in the parent process is also open in the child process by default, and the reference count of the file descriptor is increased by 1. Moreover, the reference count of variables such as user root directory and current working directory of the parent process will be increased by 1.
exec series system calls
Sometimes we need to execute other programs in the sub process, that is, to replace the current process image, so we need to use the following exec
One of a series of functions:
#include <unistd.h>
/* Replace the current process, executing PATH with arguments ARGV and
environment ENVP. ARGV and ENVP are terminated by NULL pointers. */
extern int execve (const char *__path, char *const __argv[],
char *const __envp[]) __THROW __nonnull ((1, 2));
/* Execute PATH with arguments ARGV and environment from `environ'. */
extern int execv (const char *__path, char *const __argv[])
__THROW __nonnull ((1, 2));
/* Execute PATH with all arguments after PATH until a NULL pointer,
and the argument after that for environment. */
extern int execle (const char *__path, const char *__arg, ...)
__THROW __nonnull ((1, 2));
/* Execute PATH with all arguments after PATH until
a NULL pointer and environment from `environ'. */
extern int execl (const char *__path, const char *__arg, ...)
__THROW __nonnull ((1, 2));
/* Execute FILE, searching in the `PATH' environment variable if it contains
no slashes, with arguments ARGV and environment from `environ'. */
extern int execvp (const char *__file, char *const __argv[])
__THROW __nonnull ((1, 2));
/* Execute FILE, searching in the `PATH' environment variable if
it contains no slashes, with all arguments after FILE until a
NULL pointer and environment from `environ'. */
extern int execlp (const char *__file, const char *__arg, ...)
__THROW __nonnull ((1, 2));
The path parameter specifies the full path of the executable file. The file parameter can accept the file name. The specific location of the file is searched in the environment variable path. arg accepts variable parameters and argv accepts parameter arrays, both of which will be passed to the main two numbers of the new program (the program specified by path or file). The envp parameter is used to set the environment variable of the new program.
If it is not set, the new program will use the environment variable specified by the global variable environ. In general, the exec function does not return unless there is an error. If it returns - 1 when there is an error and the setting is no error, the code after the exec call in the original program will not be executed, because at this time, the original program has been completely replaced by the program specified by the exec parameters (including code and data).
The exec function does not close the file descriptor opened by the original program unless it is set to something like sock_ Attributes of cloexec.
Dealing with zombie processes
For multi process programs, the parent process generally needs to track the exit status of the child process. Therefore, when the child process ends running, the kernel will not immediately release the process table entries of the process to meet the subsequent query of the parent process for the exit information of the child process (if the parent process is still running). After the child process finishes running and before the parent process reads its exit state, we call the child process in zombie state. In addition - a case where a child process enters a zombie state is that the parent process ends or terminates abnormally, while the child process continues to run. At this time, the PPID of the child process will be set to 1 by the operating system, that is, the init process. The init process takes over the child process and waits for it to finish. After the parent process exits and before the child process exits, the child process is in zombie state. It can be seen that in either case, if the parent process does not correctly handle the return information of the child process, the child process will stay in the zombie state and occupy the kernel resources. This is absolutely unacceptable. After all, the kernel resources are limited. The following functions are invoked in the parent process to wait for the end of the child process and get the return information of the child process, thereby avoiding the emergence of the zombie process or the immediate end of the zombie state of the child process.
/* Wait for a child to die. When one does, put its status in *STAT_LOC and return its process ID. For errors, return (pid_t) -1. This function is a cancellation point and therefore not marked with __THROW. */ extern __pid_t wait (int *__stat_loc); /* Wait for a child matching PID to die. If PID is greater than 0, match any process whose process ID is PID. If PID is (pid_t) -1, match any process. If PID is (pid_t) 0, match any process with the same process group as the current process. If PID is less than -1, match any process whose process group is the absolute value of PID. If the WNOHANG bit is set in OPTIONS, and that child is not already dead, return (pid_t) 0. If successful, return PID and store the dead child's status in STAT_LOC. Return (pid_t) -1 for errors. If the WUNTRACED bit is set in OPTIONS, return status for stopped children; otherwise don't. This function is a cancellation point and therefore not marked with __THROW. */ extern __pid_t waitpid (__pid_t __pid, int *__stat_loc, int __options);
The wait function blocks the process until one of its child processes ends running. It returns the PID of the running subprocess and stores the exit status information of the subprocess in stat_ The LOC parameter points to memory. sys/wait. Several macros are defined in the H header file to help explain the exit status information of the child process, as shown in the table.

The blocking characteristic of the wait function is obviously not what the server program expects, and the waitpid function solves this problem. Waitpid only waits for the child process specified by the PID parameter. If the PID value is - 1, it is the same as the wait function, that is, waiting for any child process to end. The meaning of the statloc parameter is the same as that of the wait function. The options parameter controls the behavior of the waitpid function. The most commonly used value of this parameter is WNOHANG. When the value of options is WNOHANG, the waitpid call will be non blocking: if the target sub process specified by PID has not ended or terminated unexpectedly, waitpid will immediately return 0; If the target subprocess does exit normally, waitpid returns the PID of the subprocess. When the waitpid call fails, return - 1 and set errno.
The efficiency of the program can be improved by executing non blocking calls when the event has occurred. For the waitpid function, we'd better call it after a child process exits. So how does the parent process know that a child process has exited? This is the purpose of sigchld signal. When a process ends, it sends a sigchld signal to its parent process. Therefore, we can capture the SIGCHLD signal in the parent process and invoke the waitpid function in the signal processing function to "completely end" a sub process.
static void handle_child(int sig)
{
pid_t pid;
int stat;
while ((pid = waitpid(-1, &stat, WNOHANG)) > 0)
{
/*Deal with the aftermath of the finished subprocess*/
}
}
The Conduit
The pipeline can transfer data between parent and child processes. The use is that after the fork call, both pipeline file descriptors (fd[0] and fd[1]) remain open. A pair of such file descriptors can only ensure data transmission in one direction between parent and child processes. One of the parent and child processes must close fd[0] and the other must close fd[1]. For example, if we want to use the pipeline to write data from the parent process to the child process, we should operate as shown in the figure.
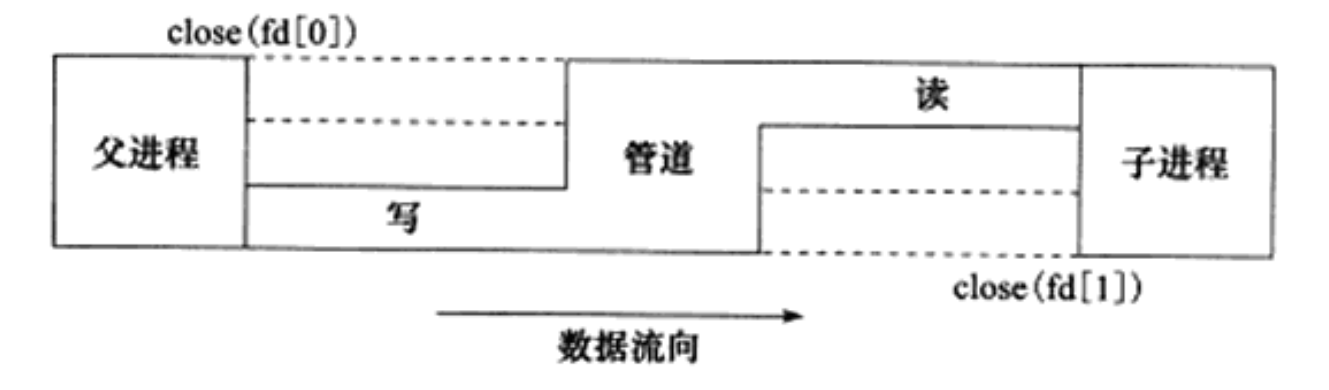
Obviously, if you want to realize the two-way data transmission between parent and child processes, you must use two pipelines. The socket programming interface provides a system call to create a full duplex pipeline: socketpair to transfer log information between the parent process and the log service child process.
Semaphore
When multiple processes access a resource on the system at the same time, such as writing a record of a database at the same time or modifying a file at the same time, the synchronization of processes needs to be considered to ensure that only one process can have exclusive access to resources at any time. Usually, the code of a program's access to shared resources is only a short section, but it is this section of code that triggers race conditions between processes. We call this code a critical code segment, or critical area. Process synchronization is to ensure that only one process can enter the key code segment at any time.
It is very difficult to write code with general purpose to ensure exclusive access to key code segments. There are two solutions called Dekker algorithm and Peterson algorithm, which try to solve the concurrency problem from the language itself (without kernel support). But they rely on busy waiting, that is, the process has to constantly wait for the state of a memory location to change. In this way, the CPU utilization is too low, which is obviously undesirable.
The concept of semaphore proposed by Dijkstra is an important step in the field of concurrent programming. Semaphore is a special variable. It can only take natural values and only supports two operations: wait and signal. However, in Linux/UNIX, "wait" and "signal" have special meanings, so the more common names for these two operations of semaphores are p and V operations. These two letters come from the Dutch words passeren (pass, like entering the critical area) and vrijgeven (release, like exiting the critical area). If there is a semaphore SV, operate its P and V
- P(SV). If the value of SV is greater than 0, it will be reduced by 1; If the value of SV is 0, the execution of the process is suspended.
- V(SV). If other processes hang because of waiting for SV, wake them up; If not, add SV by 1.
The value of semaphore can be any natural number. But the most commonly used and simplest semaphore is binary semaphore, which can only take two values: 0 and 1. This book only discusses binary semaphores. A typical example of using binary semaphores to synchronize two processes to ensure exclusive access to critical code segments is shown in figure.
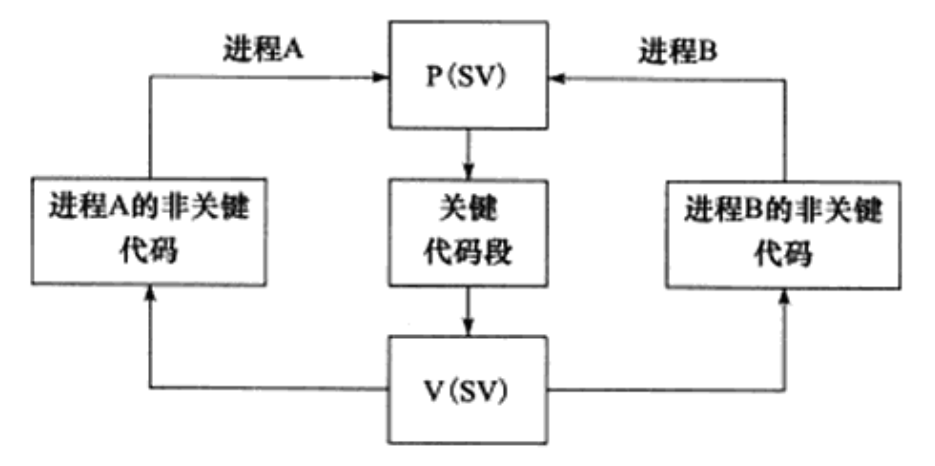
In the figure, when the key code segment is available, the value of binary semaphore SV is 1, and processes A and B have the opportunity to enter the key code segment. If process A executes the P(SV) operation at this time and reduces SV by 1, process B will be suspended if it executes the P(SV) operation again. It is not until process A leaves the critical code segment and performs the V(SV) operation to increase SV by 1 that the critical code segment becomes available again. If process B is suspended at this time because it is waiting for SV, it will wake up and enter the key code segment. Similarly, if process A performs P(SV) operation again, it can only be suspended by the operating system to wait for process B to exit the key code segment.
The API s of Linux semaphores are defined in sys / SEM The H header file mainly contains three system calls: semget, semop and semctl. They are all designed to operate on a set of semaphores, a set of semaphores, rather than a single semaphore, so these interfaces look a little more complex than we expected.
semget system call
The semget system call creates a new semaphore set or gets - an existing semaphore set. It is defined as follows:
#include <sys/sem.h> /* Get semaphore. */ extern int semget (key_t __key, int __nsems, int __semflg) __THROW;
The key parameter is a key value used to identify a globally unique semaphore set, just as the file name globally uniquely identifies a file. Processes that want to communicate through semaphores need to use the same key value to create / obtain the semaphore.
num_ The SEMS parameter specifies the number of semaphores in the semaphore set to be created / acquired. If the semaphore is created, the value must be specified; If you want to get the existing semaphore, you can set it to 0.
sem_ The flags parameter specifies a set of flags. The 9 bits at its low end are the permission of the semaphore, and its format and meaning are the same as the mode parameter of the system call open. In addition, it can communicate with IPC_ The creat flag performs a bitwise OR operation to create a new semaphore set. At this time, semget will not generate an error even if the semaphore already exists. We can also use IPC in combination_ Creat and IPC_ The excl flag to ensure that a new and unique set of semaphores is created. In this case, if the semaphore set already exists, semget returns an error and sets errno to EEXIST. This behavior of creating semaphores is similar to using O_CREAT and o_ The excl flag calls open to exclusively open a file.
When semget succeeds, it returns a positive integer value, which is the identifier of the semaphore set; When semget fails, it returns - 1 and sets errno. If semget is used to create a semaphore set, the kernel data structure semid associated with it_ DS will be created and initialized. semid_ds structure is defined as follows:
/* Data structure used to pass permission information to IPC operations.
It follows the kernel ipc64_perm size so the syscall can be made directly
without temporary buffer copy. However, since glibc defines the MODE
field as mode_t per POSIX definition (BZ#18231), it omits the __PAD1 field
(since glibc does not export mode_t as 16-bit for any architecture). */
struct ipc_perm
{
__key_t __key; /* Key. */
__uid_t uid; /* Owner's user ID. */
__gid_t gid; /* Owner's group ID. */
__uid_t cuid; /* Creator's user ID. */
__gid_t cgid; /* Creator's group ID. */
__mode_t mode; /* Read/write permission. */
unsigned short int __seq; /* Sequence number. */
unsigned short int __pad2;
__syscall_ulong_t __glibc_reserved1;
__syscall_ulong_t __glibc_reserved2;
};
/* Data structure describing a set of semaphores. */
struct semid_ds
{
struct ipc_perm sem_perm; /* operation permission struct */
__SEM_PAD_TIME (sem_otime, 1); /* last semop() time */
__SEM_PAD_TIME (sem_ctime, 2); /* last time changed by semctl() */
__syscall_ulong_t sem_nsems; /* number of semaphores in set */
__syscall_ulong_t __glibc_reserved3;
__syscall_ulong_t __glibc_reserved4;
};
semop system call
It is used to change the value of semaphore, i.e. perform P and V operations. The operation of semaphores is actually the operation of these kernel variables. semop is defined as follows:
/* Operate on semaphore. */ extern int semop (int __semid, struct sembuf *__sops, size_t __nsops) __THROW;
sem_ The ID parameter is the semaphore set identifier returned by semget call, which is used to specify the target semaphore set to be operated. sem_ The OPS parameter points to an array of sembuf structure types. The definition of sembuf structure is as follows:
struct sembuf
{
unsigned short int sem_num; /* semaphore number */
short int sem_op; /* semaphore operation */
short int sem_flg; /* operation flag */
};
Where, sem_num member is the number of semaphores in the semaphore set, and 0 represents the first semaphore in the semaphore set. sem_op member specifies the operation type, and its optional values are positive integers, 0, and negative integers. The behavior of each type of operation is also affected by SEM_ Influence of FLG members. sem_ The optional value of FLG is IPC_NOWAIT and SEM_UNDO. IPC_NOWAIT means that no matter whether the semaphore operation is successful or not, the semop call will return immediately, which is similar to a non blocking I/O operation. SEM_UNDO means to cancel the ongoing semop operation when the process exits.
The third parameter num of semop system call_ sem_ops specifies the number of operations to be performed, that is, SEM_ The number of elements in the OPS array. Semop pair array SEM_ Each member of OPS performs operations in sequence according to the array order, and the process is atomic operation, so as to avoid race conditions caused by other processes performing semop operations on the semaphores in the signal set in different order at the same time.
When semop succeeds, it returns 0. If it fails, it returns - 1 and sets ermo. When failed, sem__ All operations specified in the OPS array are not performed.
semctl system call
semctl system calls allow callers to have direct control over semaphores. It is defined as follows:
/* Semaphore control operation. */ extern int semctl (int __semid, int __semnum, int __cmd, ...) __THROW;
sem_ The ID parameter is the semaphore set identifier returned by semget call to specify the semaphore set to be operated. Parameter specifies the number of the semaphore being operated in the semaphore set. The command parameter specifies the command to execute. Some commands require the caller to pass the fourth parameter. The type of the fourth parameter is defined by the user, but sys / SEM H header file gives its recommended format, as follows:
/* The user should define a union like the following to use it for arguments
for `semctl'.
union semun
{
int val; <= value for SETVAL
struct semid_ds *buf; <= buffer for IPC_STAT & IPC_SET
unsigned short int *array; <= array for GETALL & SETALL
struct seminfo *__buf; <= buffer for IPC_INFO
};
Previous versions of this file used to define this union but this is
incorrect. One can test the macro _SEM_SEMUN_UNDEFINED to see whether
one must define the union or not. */
struct seminfo
{
int semmap; /* Linux Kernel not used*/
int semmni; /*The maximum number of semaphore sets the system can have*/
int semmns; /*The maximum number of semaphores the system can have*/
int semmnu; /* Linux Kernel not used*/
int semmsl; /*The maximum number of semaphores allowed in a semaphore set*/
int semopm; /* semop SEM that can be executed at most once_ Number of OP operations*/
int semume; /* Linux Kernel not used*/
int semusz; /* sem undo Size of structure*/
int semvmx; /*Maximum allowable semaphore value*/
int semaem; /*Maximum number of UNDO operations allowed (number of semop operations with SEM _undoflag) */
};
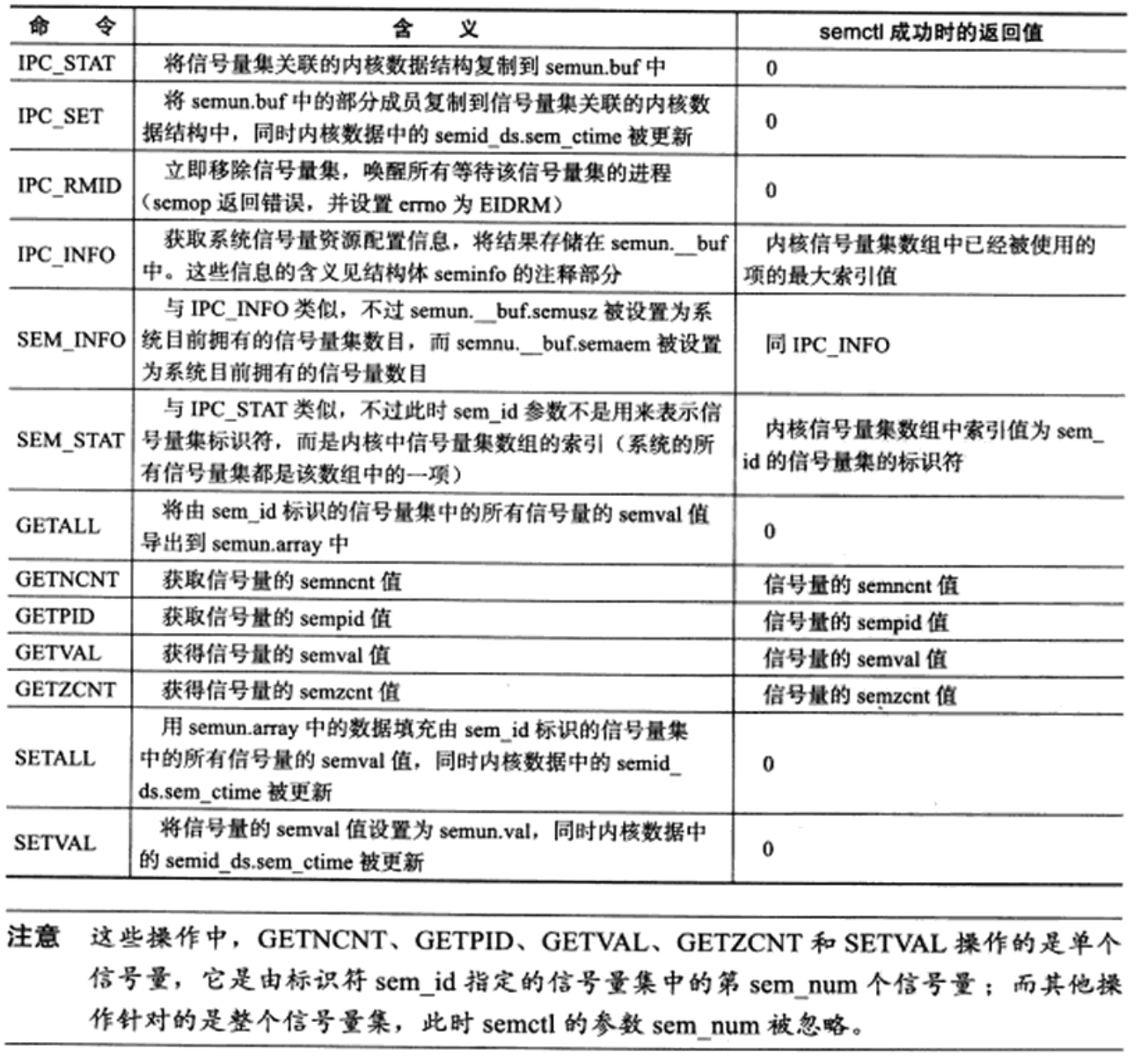
Depends on the value returned by the semctl parameter, as shown in the table. When semctl fails, it returns - 1 and sets errmo.
Special key IPC_ PRIVATE
The caller of semget can pass a special key value IPC to its key parameter_ Private (its value is 0), so semget will create a new semaphore whether the semaphore already exists or not. The semaphore created with this key value is not process private as its name claims. Other processes, especially child processes, also have methods to access this semaphore. So the BUGS section of semget's man manual says that the name IPC is used_ Private is somewhat misleading (for historical reasons) and should be called IPC_NEW, for example, the following code uses an IPC between the parent and child processes_ Private semaphore to synchronize.
#include <sys/sem.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
union semun
{
int val;
struct semid_ds *buf;
unsigned short int *array;
struct seminfo *__buf;
};
void pv(int sem_id, int op)
{
struct sembuf sem_b;
sem_b.sem_num = 0;
sem_b.sem_op = op;
sem_b.sem_flg = SEM_UNDO;
semop(sem_id, &sem_b, 1);
}
int main(int argc, char *argv[])
{
int sem_id = semget(IPC_PRIVATE, 1, 0666);
union semun sem_un;
sem_un.val = 1;
semctl(sem_id, 0, SETVAL, sem_un);
pid_t id = fork();
if (id < 0)
{
return 1;
}
else if (id == 0)
{
printf("child try to get binary sem\n");
pv(sem_id, -1);
printf("child get the sem and would release it after 5 seconds\n");
sleep(5);
pv(sem_id, 1);
exit(0);
}
else
{
printf("parent try to get binary sem\n");
pv(sem_id, -1);
printf("parent get the sem and would release it after 5 seconds\n");
sleep(5);
pv(sem_id, 1);
}
waitpid(id, NULL, 0);
semctl(sem_id, 0, IPC_RMID, sem_un);
return 0;
}
Shared memory
Shared memory is the most efficient IPC mechanism because it does not involve any data transfer between processes. The problem with this high efficiency is that we must use other auxiliary means to synchronize the process's access to shared memory, otherwise race conditions will occur. Therefore, shared memory is usually used with other means of interprocess communication. Linux shared memory API s are defined in sys / SHM H header file, including four system calls: shmget, shmat, shmdt and shmctl.
shmget
shmget system calls to create a new shared memory or get an existing shared memory. It is defined as follows:
#include <sys/shm.h> /* Get shared memory segment. */ extern int shmget (key_t __key, size_t __size, int __shmflg) __THROW;
Like semget system call, the key parameter is a key value used to identify the globally unique shared memory. The size parameter specifies the size of the shared memory in bytes. If you are creating a new shared memory, the size value must be specified. If you want to get the existing shared memory, you can set the size to 0.
The use and meaning of shmflg parameter are the same as SEM of semget system call_ The fags parameter is the same. However, shmget supports two additional flags, SHM_HUGETLB and SHM_NORESERVE. Their meanings are as follows:
- SHM_HUGETLB, similar to map of mmap_ Hugetlb flag, the system will use "large page" to allocate space for shared memory.
- SHM_NORESERVE, similar to the map of mmap_ The NoReserve flag does not reserve swap space for shared memory. In this way, when the physical memory is insufficient, writing to the shared memory will trigger the SIGSEGV signal.
Shmget returns - a positive integer value when successful, which is the identifier of shared memory. When shmget fails, it returns - 1 and sets errmo.
If shmget is used to create shared memory, all bytes of this shared memory are initialized to 0, and the kernel data structure shmid associated with it_ DS will be created and initialized. shmid_ds structure is defined as follows:
/* Data structure describing a shared memory segment. */
struct shmid_ds
{
struct ipc_perm shm_perm; /* operation permission struct */
#if !__SHM_SEGSZ_AFTER_TIME
size_t shm_segsz; /* size of segment in bytes */
#endif
__SHM_PAD_TIME (shm_atime, 1); /* time of last shmat() */
__SHM_PAD_TIME (shm_dtime, 2); /* time of last shmdt() */
__SHM_PAD_TIME (shm_ctime, 3); /* time of last change by shmctl() */
#if __SHM_PAD_BETWEEN_TIME_AND_SEGSZ
unsigned long int __glibc_reserved4;
#endif
#if __SHM_SEGSZ_AFTER_TIME
size_t shm_segsz; /* size of segment in bytes */
#endif
__pid_t shm_cpid; /* pid of creator */
__pid_t shm_lpid; /* pid of last shmop */
shmatt_t shm_nattch; /* number of current attaches */
__syscall_ulong_t __glibc_reserved5;
__syscall_ulong_t __glibc_reserved6;
};
shmat and shmdt
After the shared memory is created / acquired, we can't access it immediately. Instead, we need to associate it with the address space of the process first. After using the shared memory, we also need to separate it from the process address space. These two tasks are realized by the following two system calls:
/* Attach shared memory segment. */
extern void *shmat (int __shmid, const void *__shmaddr, int __shmflg)
__THROW;
/* Detach shared memory segment. */
extern int shmdt (const void *__shmaddr) __THROW;
Where, SHM_ The ID parameter is the shared memory identifier returned by the shmget call. shm_ The addr parameter specifies which address space to associate the shared memory with the process. The final effect is also affected by the optional flag SHM of the shmfg parameter_ Impact of RND:
- If SHM_ If addr is NUll, the associated address is selected by the operating system. This is the recommended practice to ensure code portability.
- If shm_addr is not empty and SHM_ If the RND flag is not set, the shared memory is associated to the address specified by addr.
- If SHM_ Addr is not empty and SHM is set_ Rnd flag, the associated address is [shm_addr-(shm_addr%SHMLBA)]. SHMLBA means "segment low boundary address multiple", which must be an integral multiple of the memory page_size. In the current Linux kernel, it is equal to the size of a memory page. SHM_RND means round, that is, the address associated with shared memory is rounded down to SHM_ Addr is at the integer multiple address of the nearest SHMLBA.
Except SHM_ In addition to the RND flag, the shmflg parameter also supports the following flags:
- SHM_RDONLY. The process can only read the contents of shared memory. If this flag is not specified, the process can read and write the shared memory at the same time (of course, it needs to specify its read and write permissions when creating the shared memory).
- SHM_REMAP if the address shmaddr has been associated with a piece of shared memory, it will be re associated.
- SHM EXEC, which specifies execution permissions on shared memory segments. For shared memory, the execution permission is actually the same as the read permission.
Shmat returns the address to which the shared memory is associated when it succeeds. If it fails, it returns (void*)-1 and sets ermo. When shmat succeeds, the kernel data structure shmid will be modified_ Some fields of DS are as follows:
- Set shm_nattach plus 1.
- Set shm_lpid is set to the PID of the calling process.
- Set shm_atime is set to the current time.
The shmdt function associates to SHM_ The shared memory at addr is detached from the process. It returns 0 on success and - 1 on failure and sets errno. Shmdt will modify the kernel data structure shmid when called successfully_ Some fields of DS are as follows:
- Set shm_nattach minus 1.
- Set shm_lpid is set to the PID of the calling process.
- Set shm_dtime is set to the current time.
shmctl
The shmctl system call controls certain properties of shared memory. It is defined as follows:
/* Shared memory control operation. */ extern int shmctl (int __shmid, int __cmd, struct shmid_ds *__buf) __THROW;
Where, SHM_ The ID parameter is the shared memory identifier returned by the shmget call. The command parameter specifies the command to execute. All commands supported by shmctl are shown in the table.
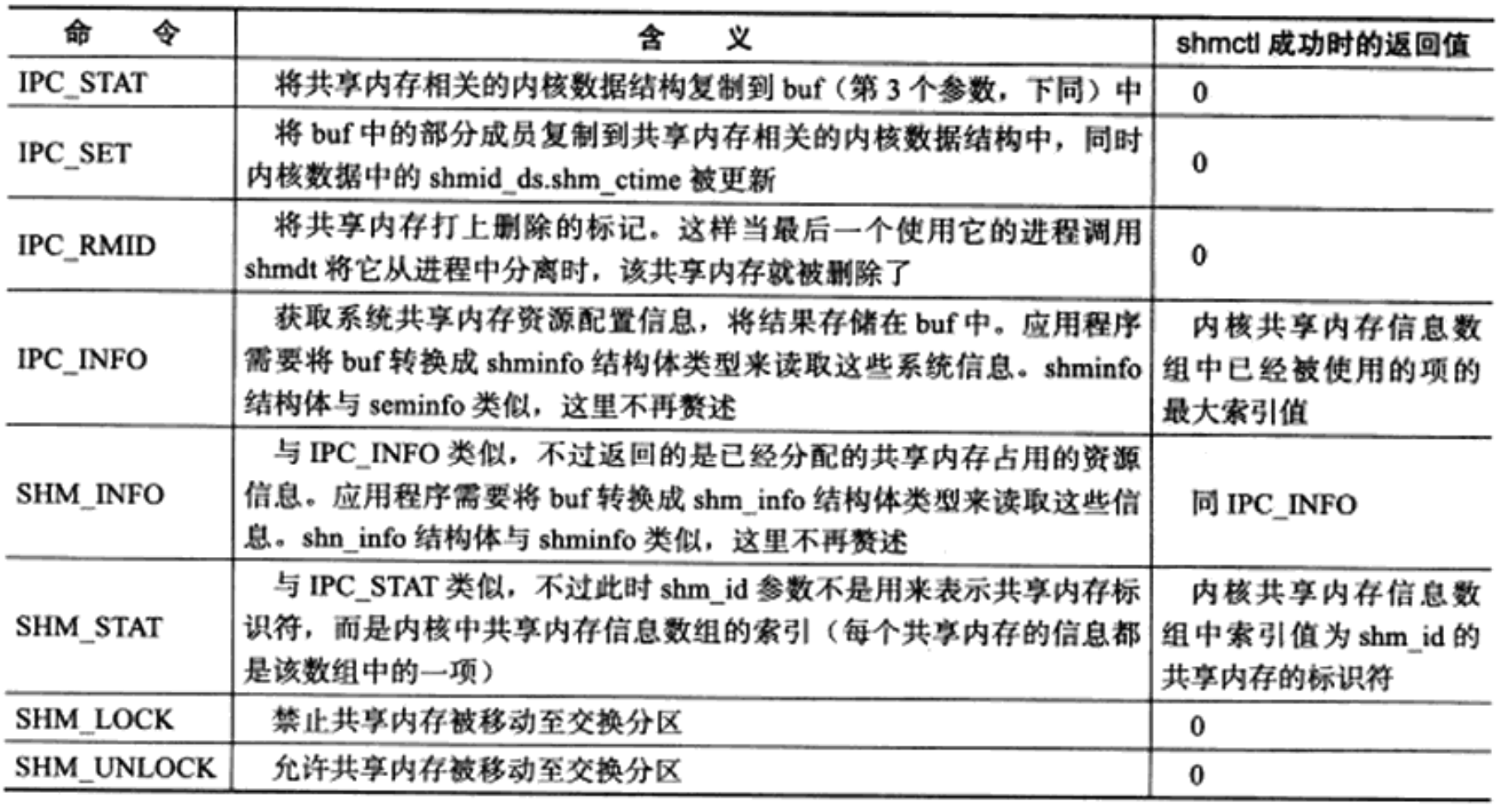
The return value when shmctl succeeds depends on the command parameter, as shown in table 13-3. Return - 1 when shmetl fails and set errno.
Shared memory POSIX method
Linux provides another way to share memory between unrelated processes using mmap. In this way, no responsibility is required
What file is supported, but it needs to first use the following function to create or open a POSIX shared memory object:
#include <sys/mman.h> #include <sys/stat.h> #include <fcntl.h> /* Open shared memory segment. */ extern int shm_open (const char *__name, int __oflag, mode_t __mode);
shm_ The use method of open is exactly the same as that of open system call.
The name parameter specifies the shared memory object to create / open. From the perspective of portability, this parameter should use the format of "/ somename": start with "/", followed by multiple characters, and these characters are not "/"; end with "\ 0", and the length does not exceed NAME_MAX (usually 255).
The ofag parameter specifies how it is created. It can be bitwise or of one or more of the following flags:
- O_RDONLY. Open the shared memory object as read-only.
- O_RDWR. Open the shared memory object in a readable and writable manner.
- O_CREAT. If the shared memory object does not exist, it is created. At this time, the lowest 9 bits of the mode parameter will specify the access rights of the shared memory object. When a shared memory object is created, its initial length is 0.
- O_EXCL. And o_ Used with creat. If the shared memory object specified by name already exists, SHM_ The open call returns an error, otherwise a new shared memory object is created.
- O_TRUNC. If the shared memory object already exists, truncate it to a length of 0
shm_ A file descriptor is returned when the open call is successful. This file descriptor can be used for subsequent mmap calls to associate shared memory with the calling process. shm_ Return - 1 when open fails and set ermo.
As the open file needs to be closed at last, SHM_ The shared memory object created by open also needs to be deleted after it is used up. This process is realized by the following functions:
/* Remove shared memory segment. */ extern int shm_unlink (const char *__name);
This function marks the shared memory object specified by the name parameter as waiting to be deleted. When all processes that use the shared memory object use ummap to separate it from the process, the system will destroy the resources occupied by the shared memory object. If the above POSIX shared memory function is used in the code, the link option - Irt needs to be specified during compilation.
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <signal.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#define USER_LIMIT 5
#define BUFFER_SIZE 1024
#define FD_LIMIT 65535
#define MAX_EVENT_NUMBER 1024
#define PROCESS_LIMIT 65536
struct client_data
{
sockaddr_in address;
int connfd;
pid_t pid;
int pipefd[2];
};
static const char *shm_name = "/my_shm";
int sig_pipefd[2];
int epollfd;
int listenfd;
int shmfd;
char *share_mem = 0;
client_data *users = 0;
int *sub_process = 0;
int user_count = 0;
bool stop_child = false;
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd)
{
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
void sig_handler(int sig)
{
int save_errno = errno;
int msg = sig;
send(sig_pipefd[1], (char *)&msg, 1, 0);
errno = save_errno;
}
void addsig(int sig, void (*handler)(int), bool restart = true)
{
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = handler;
if (restart)
{
sa.sa_flags |= SA_RESTART;
}
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL) != -1);
}
void del_resource()
{
close(sig_pipefd[0]);
close(sig_pipefd[1]);
close(listenfd);
close(epollfd);
shm_unlink(shm_name);
delete[] users;
delete[] sub_process;
}
void child_term_handler(int sig)
{
stop_child = true;
}
int run_child(int idx, client_data *users, char *share_mem)
{
epoll_event events[MAX_EVENT_NUMBER];
int child_epollfd = epoll_create(5);
assert(child_epollfd != -1);
int connfd = users[idx].connfd;
addfd(child_epollfd, connfd);
int pipefd = users[idx].pipefd[1];
addfd(child_epollfd, pipefd);
int ret;
addsig(SIGTERM, child_term_handler, false);
while (!stop_child)
{
int number = epoll_wait(child_epollfd, events, MAX_EVENT_NUMBER, -1);
if ((number < 0) && (errno != EINTR))
{
printf("epoll failure\n");
break;
}
for (int i = 0; i < number; i++)
{
int sockfd = events[i].data.fd;
if ((sockfd == connfd) && (events[i].events & EPOLLIN))
{
memset(share_mem + idx * BUFFER_SIZE, '\0', BUFFER_SIZE);
ret = recv(connfd, share_mem + idx * BUFFER_SIZE, BUFFER_SIZE - 1, 0);
if (ret < 0)
{
if (errno != EAGAIN)
{
stop_child = true;
}
}
else if (ret == 0)
{
stop_child = true;
}
else
{
send(pipefd, (char *)&idx, sizeof(idx), 0);
}
}
else if ((sockfd == pipefd) && (events[i].events & EPOLLIN))
{
int client = 0;
ret = recv(sockfd, (char *)&client, sizeof(client), 0);
if (ret < 0)
{
if (errno != EAGAIN)
{
stop_child = true;
}
}
else if (ret == 0)
{
stop_child = true;
}
else
{
send(connfd, share_mem + client * BUFFER_SIZE, BUFFER_SIZE, 0);
}
}
else
{
continue;
}
}
}
close(connfd);
close(pipefd);
close(child_epollfd);
return 0;
}
int main(int argc, char *argv[])
{
if (argc <= 2)
{
printf("usage: %s ip_address port_number\n", basename(argv[0]));
return 1;
}
const char *ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton(AF_INET, ip, &address.sin_addr);
address.sin_port = htons(port);
listenfd = socket(PF_INET, SOCK_STREAM, 0);
assert(listenfd >= 0);
ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd, 5);
assert(ret != -1);
user_count = 0;
users = new client_data[USER_LIMIT + 1];
sub_process = new int[PROCESS_LIMIT];
for (int i = 0; i < PROCESS_LIMIT; ++i)
{
sub_process[i] = -1;
}
epoll_event events[MAX_EVENT_NUMBER];
epollfd = epoll_create(5);
assert(epollfd != -1);
addfd(epollfd, listenfd);
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, sig_pipefd);
assert(ret != -1);
setnonblocking(sig_pipefd[1]);
addfd(epollfd, sig_pipefd[0]);
addsig(SIGCHLD, sig_handler);
addsig(SIGTERM, sig_handler);
addsig(SIGINT, sig_handler);
addsig(SIGPIPE, SIG_IGN);
bool stop_server = false;
bool terminate = false;
shmfd = shm_open(shm_name, O_CREAT | O_RDWR, 0666);
assert(shmfd != -1);
ret = ftruncate(shmfd, USER_LIMIT * BUFFER_SIZE);
assert(ret != -1);
share_mem = (char *)mmap(NULL, USER_LIMIT * BUFFER_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shmfd, 0);
assert(share_mem != MAP_FAILED);
close(shmfd);
while (!stop_server)
{
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if ((number < 0) && (errno != EINTR))
{
printf("epoll failure\n");
break;
}
for (int i = 0; i < number; i++)
{
int sockfd = events[i].data.fd;
if (sockfd == listenfd)
{
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);
if (connfd < 0)
{
printf("errno is: %d\n", errno);
continue;
}
if (user_count >= USER_LIMIT)
{
const char *info = "too many users\n";
printf("%s", info);
send(connfd, info, strlen(info), 0);
close(connfd);
continue;
}
users[user_count].address = client_address;
users[user_count].connfd = connfd;
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, users[user_count].pipefd);
assert(ret != -1);
pid_t pid = fork();
if (pid < 0)
{
close(connfd);
continue;
}
else if (pid == 0)
{
close(epollfd);
close(listenfd);
close(users[user_count].pipefd[0]);
close(sig_pipefd[0]);
close(sig_pipefd[1]);
run_child(user_count, users, share_mem);
munmap((void *)share_mem, USER_LIMIT * BUFFER_SIZE);
exit(0);
}
else
{
close(connfd);
close(users[user_count].pipefd[1]);
addfd(epollfd, users[user_count].pipefd[0]);
users[user_count].pid = pid;
sub_process[pid] = user_count;
user_count++;
}
}
else if ((sockfd == sig_pipefd[0]) && (events[i].events & EPOLLIN))
{
int sig;
char signals[1024];
ret = recv(sig_pipefd[0], signals, sizeof(signals), 0);
if (ret == -1)
{
continue;
}
else if (ret == 0)
{
continue;
}
else
{
for (int i = 0; i < ret; ++i)
{
switch (signals[i])
{
case SIGCHLD:
{
pid_t pid;
int stat;
while ((pid = waitpid(-1, &stat, WNOHANG)) > 0)
{
int del_user = sub_process[pid];
sub_process[pid] = -1;
if ((del_user < 0) || (del_user > USER_LIMIT))
{
printf("the deleted user was not change\n");
continue;
}
epoll_ctl(epollfd, EPOLL_CTL_DEL, users[del_user].pipefd[0], 0);
close(users[del_user].pipefd[0]);
users[del_user] = users[--user_count];
sub_process[users[del_user].pid] = del_user;
printf("child %d exit, now we have %d users\n", del_user, user_count);
}
if (terminate && user_count == 0)
{
stop_server = true;
}
break;
}
case SIGTERM:
case SIGINT:
{
printf("kill all the clild now\n");
//addsig( SIGTERM, SIG_IGN );
//addsig( SIGINT, SIG_IGN );
if (user_count == 0)
{
stop_server = true;
break;
}
for (int i = 0; i < user_count; ++i)
{
int pid = users[i].pid;
kill(pid, SIGTERM);
}
terminate = true;
break;
}
default:
{
break;
}
}
}
}
}
else if (events[i].events & EPOLLIN)
{
int child = 0;
ret = recv(sockfd, (char *)&child, sizeof(child), 0);
printf("read data from child accross pipe\n");
if (ret == -1)
{
continue;
}
else if (ret == 0)
{
continue;
}
else
{
for (int j = 0; j < user_count; ++j)
{
if (users[j].pipefd[0] != sockfd)
{
printf("send data to child accross pipe\n");
send(users[j].pipefd[0], (char *)&child, sizeof(child), 0);
}
}
}
}
}
}
del_resource();
return 0;
}
Message queue
msgget system calls to create a message queue or get - an existing message queue. It is defined as follows:
#include <sys/msg.h> /* Get messages queue. */ extern int msgget (key_t __key, int __msgflg) __THROW;
Like semget system call, the key parameter is a key value used to identify a globally unique message queue. The use and meaning of msgflg parameter are the same as SEM of semget system call_ The flags parameter is the same. Msgget returns a positive integer value when successful, which is the identifier of the message queue. Return - 1 when msgget fails and set errno.
If msgget is used to create a message queue, the kernel data structure msqid associated with it_ DS will be created and initialized. msqid_ds structure is defined as follows:
/* Structure of record for one message inside the kernel.
The type `struct msg' is opaque. */
struct msqid_ds
{
struct ipc_perm msg_perm; /* structure describing operation permission */
__MSQ_PAD_TIME (msg_stime, 1); /* time of last msgsnd command */
__MSQ_PAD_TIME (msg_rtime, 2); /* time of last msgrcv command */
__MSQ_PAD_TIME (msg_ctime, 3); /* time of last change */
__syscall_ulong_t __msg_cbytes; /* current number of bytes on queue */
msgqnum_t msg_qnum; /* number of messages currently on queue */
msglen_t msg_qbytes; /* max number of bytes allowed on queue */
__pid_t msg_lspid; /* pid of last msgsnd() */
__pid_t msg_lrpid; /* pid of last msgrcv() */
__syscall_ulong_t __glibc_reserved4;
__syscall_ulong_t __glibc_reserved5;
};
msgsnd
The msgsnd system call adds -- messages to the message queue. It is defined as follows:
/* Send message to message queue. This function is a cancellation point and therefore not marked with __THROW. */ extern int msgsnd (int __msqid, const void *__msgp, size_t __msgsz, int __msgflg);
The msqid parameter is the message queue identifier returned by the msgget call.
msg_ The PTR parameter points to -- a message to be sent. The message must be defined as the following types:
/* Template for struct to be used as argument for `msgsnd' and `msgrcv'. */
struct msgbuf
{
__syscall_slong_t mtype; /* type of received/sent message */
char mtext[1]; /* text of the message */
};
The mtype member specifies the type of message, which must be a positive integer. mtext is message data. msg_ The SZ parameter is the length of the data part (mtext) of the message. This length can be 0, indicating that there is no message data.
The msgfg parameter controls the behavior of msgsnd. It usually only supports IPC_NOWAIT flag, that is, send messages in a non blocking manner. By default, when sending a message, msgsnd will block if the message queue is full. If IPC_ If the nowait flag is specified, msgsnd will immediately return and set ermno to EAGAIN.
msgsnd calls in a blocked state may be interrupted by the following two exceptions:
- The message queue was removed. At this point, the msgsnd call will immediately return and set ermo to EIDRM.
- The program received a signal. At this point, the msgsnd call will immediately return and set ermo to EINTR.
Msgsnd returns 0 on success, and - 1 on failure, and sets errmo. When msgsnd succeeds, the kernel data structure msqid will be modified_ Some fields of DS are as follows:
- Set msg_qnum plus 1.
- Set msg_lspid is set to the PID of the calling process.
- Set msg_stime is set to the current time.
msgrcv
The msgrcv system call gets the message from the message queue. It is defined as follows:
/* Receive message from message queue. This function is a cancellation point and therefore not marked with __THROW. */ extern ssize_t msgrcv (int __msqid, void *__msgp, size_t __msgsz, long int __msgtyp, int __msgflg);
The msqid parameter is the message queue identifier returned by the msgget call.
msg_ ptr parameter is used to store the received message, MSG_ The SZ parameter refers to the length of the message data part.
The msgtype parameter specifies what type of message to receive. We can specify the message type in the following ways:
- msgtype equals 0. Read the - first message in the message queue.
- Msgtype is greater than 0. Read the first message of type msgtype in the message queue (unless the flag msg_; except is specified).
- Msgtype is less than 0. Read the - first message in the message queue whose type value is smaller than the absolute value of msgtype.
The parameter msgfg controls the behavior of the msgrev function. It can be bitwise or of one of the following signs:
- IPC_NOWAIT. If there is no message in the message queue, the msgrcv call returns immediately and sets ermno to ENOMSG.
- MSG_EXCEPT. If msgtype is greater than 0, the - th non msgtype message in the message queue will be received.
- MSG_NOERROR. If the length of the message data part exceeds msg_sz, cut it off.
msgrcv calls that are blocked may also be interrupted by the following two exceptions:
- The message queue was removed. At this point, the msgrcv call will immediately return and set errmo to EIDRM.
- The program received a signal. At this point, call msermo and set it back to NTR immediately.
Msgrcv returns 0 on success, and - 1 on failure, and sets errmo. When msgrcv succeeds, the kernel data structure msqid will be modified_ Some fields of DS are as follows:
- Set msg_qnum minus 1.
- Set msg_lrpid is set to the PID of the calling process.
- msg_rtime is set to the current time.
msgctl
The msqid parameter is the shared memory identifier returned by the msgget call__ The cmd parameter specifies the command to execute.
All commands supported by msgctl are shown in the table.
/* Message queue control operation. */ extern int msgctl (int __msqid, int __cmd, struct msqid_ds *__buf) __THROW;
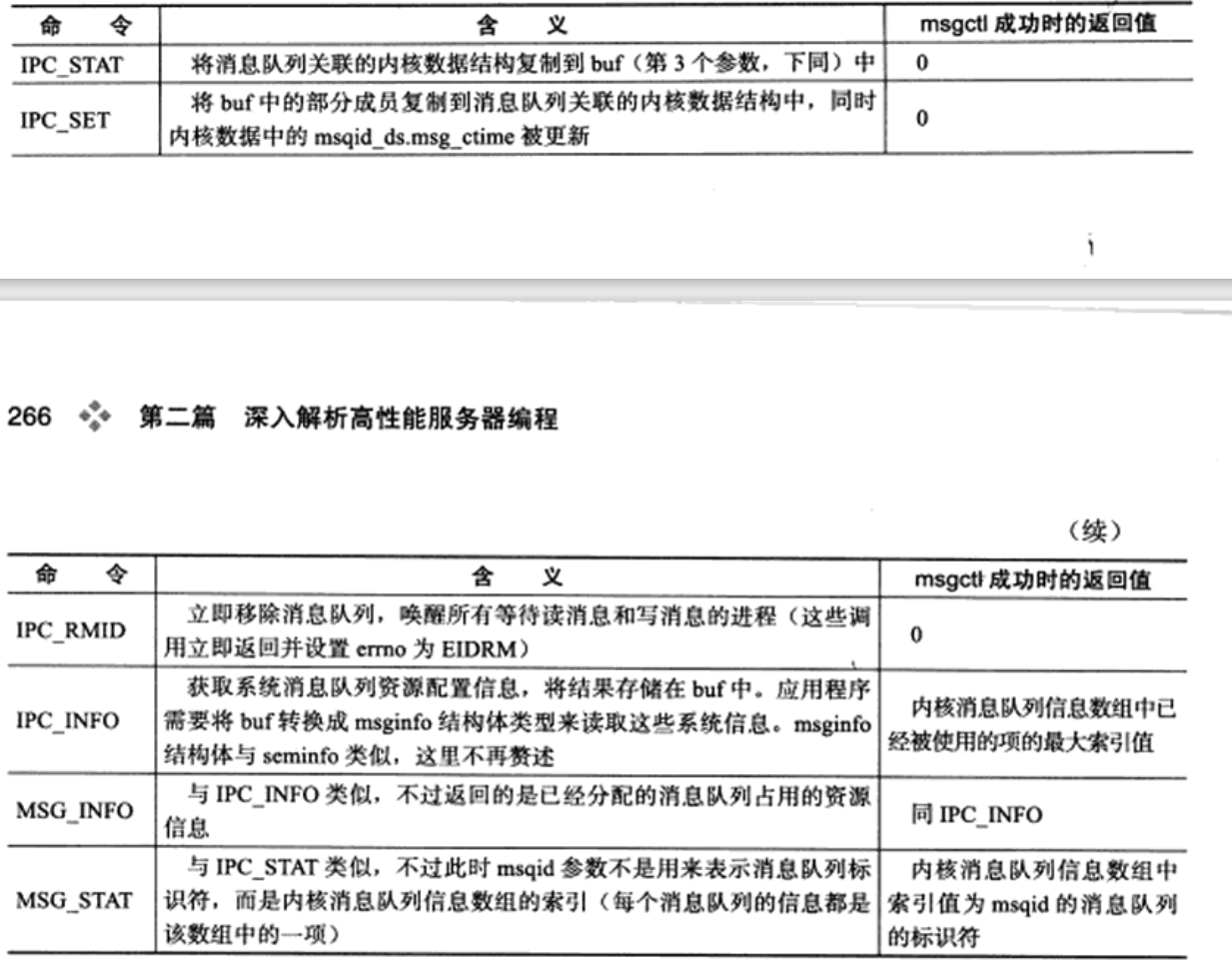
The return value when msgctl succeeds depends on__ cmd parameter, as shown in the table. The msgctl function returns - 1 when it fails
And set ermo.
Passing file descriptors between processes
Since the file descriptor opened in the parent process remains open in the child process after the fork call, the file descriptor can be easily passed from the parent process to the child process. It should be noted that passing a file descriptor does not pass the value of a file descriptor, but creates a new file descriptor in the receiving process, and the file descriptor and the file descriptor passed in the sending process point to the same file table item in the kernel.
#include <sys/socket.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <assert.h>
#include <string.h>
static const int CONTROL_LEN = CMSG_LEN(sizeof(int));
void send_fd(int fd, int fd_to_send)
{
struct iovec iov[1];
struct msghdr msg;
char buf[0];
iov[0].iov_base = buf;
iov[0].iov_len = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
cmsghdr cm;
cm.cmsg_len = CONTROL_LEN;
cm.cmsg_level = SOL_SOCKET;
cm.cmsg_type = SCM_RIGHTS;
*(int *)CMSG_DATA(&cm) = fd_to_send;
msg.msg_control = &cm;
msg.msg_controllen = CONTROL_LEN;
sendmsg(fd, &msg, 0);
}
int recv_fd(int fd)
{
struct iovec iov[1];
struct msghdr msg;
char buf[0];
iov[0].iov_base = buf;
iov[0].iov_len = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
cmsghdr cm;
msg.msg_control = &cm;
msg.msg_controllen = CONTROL_LEN;
recvmsg(fd, &msg, 0);
int fd_to_read = *(int *)CMSG_DATA(&cm);
return fd_to_read;
}
int main()
{
int pipefd[2];
int fd_to_pass = 0;
int ret = socketpair(PF_UNIX, SOCK_DGRAM, 0, pipefd);
assert(ret != -1);
pid_t pid = fork();
assert(pid >= 0);
if (pid == 0)
{
close(pipefd[0]);
fd_to_pass = open("test.txt", O_RDWR, 0666);
send_fd(pipefd[1], (fd_to_pass > 0) ? fd_to_pass : 0);
close(fd_to_pass);
exit(0);
}
close(pipefd[1]);
fd_to_pass = recv_fd(pipefd[0]);
char buf[1024];
memset(buf, '\0', 1024);
read(fd_to_pass, buf, 1024);
printf("I got fd %d and data %s\n", fd_to_pass, buf);
close(fd_to_pass);
}