This paper records the receiving and contracting processing of vxlan interface kernel.
VXLAN(Virtual Extensible LAN) is a network virtualization technology, a large two-layer tunnel technology, which encapsulates the two-layer package in UDP to build a virtual two-layer network.
The configuration and application scenarios of vxlan of equipment manufacturers, especially large manufacturers, are much richer and more complex. linux is relatively simple. It is often used in some SDN networks, such as cloud computing and container virtualization networks. There are also some supporting features on vxlan, such as arp proxy, l2mis, l3miss, router, etc.
#####Let's first introduce some important data structures:
struct vxlan_net structure, one for each network namespace (net), which stores vxlan related information in this namespace. It is used for global search of vxlan and stored in net - > Gen.
struct vxlan_net {
struct list_head vxlan_list; // Vxlan device information, vxlan mounted when creating vxlan dev (vxlan_newlink)_ dev
struct hlist_head sock_list[PORT_HASH_SIZE]; // vxlan socket information, vxlan_open the vxlan that is mounted when the socket is created_ sock
spinlock_t sock_lock;
};
struct vxlan_dev is the private data structure of vxlan device, which stores all vxlan configuration information, the fdb table entry of vxlan, and the udp sock information used by vxlan.
/* Pseudo network device */
struct vxlan_dev {
struct vxlan_dev_node hlist4; /* vni hash table for IPv4 socket */
#if IS_ENABLED(CONFIG_IPV6)
struct vxlan_dev_node hlist6; /* vni hash table for IPv6 socket */
#endif
struct list_head next; /* vxlan's per namespace list */
struct vxlan_sock __rcu *vn4_sock; /* listening socket for IPv4 */
#if IS_ENABLED(CONFIG_IPV6)
struct vxlan_sock __rcu *vn6_sock; /* listening socket for IPv6 */
#endif
struct net_device *dev;
struct net *net; /* netns for packet i/o */
struct vxlan_rdst default_dst; /* default destination */
u32 flags; /* VXLAN_F_* in vxlan.h */
struct timer_list age_timer;
spinlock_t hash_lock;
unsigned int addrcnt;
struct gro_cells gro_cells;
struct vxlan_config cfg; // vxlan all configuration data
struct hlist_head fdb_head[FDB_HASH_SIZE]; // vxlan special fdb table entry
};
The fdb table of linux is the layer-2 forwarding table used by linux. The general fdb table expresses the interface from which the message of a mac address is sent. The fdb table specially designed by linux for vxlan has more expression of vxlan and its udp tunnel encapsulation.
As shown in the figure below, the man bridge command can see that the bridge fdb add command is specifically for the configuration items of vxlan interface, which is clearly explained.
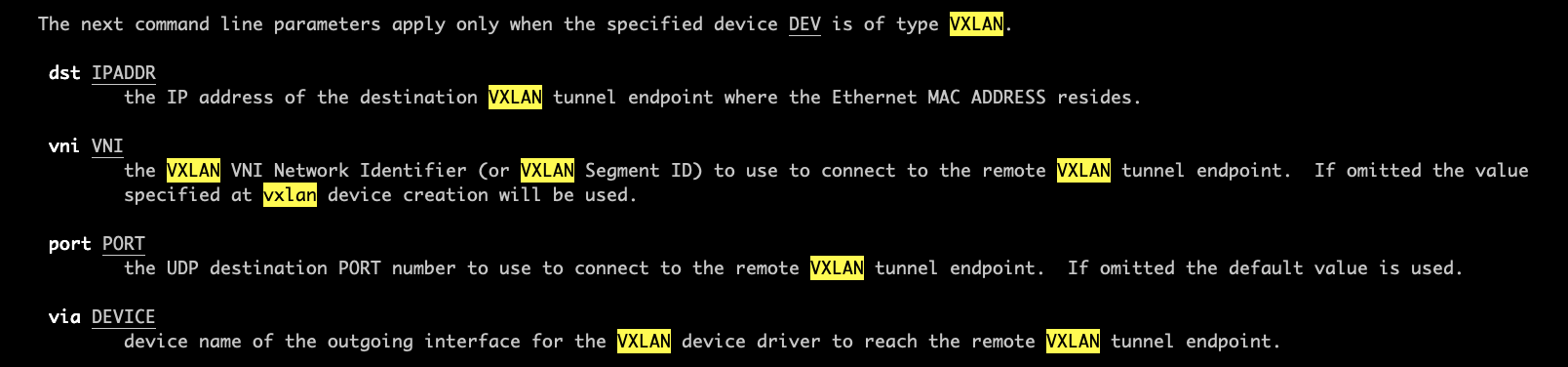
As follows, we configure a vxlan 100, specify the default dstport and vni, and then configure two fdb tables on vxlan. We can see that the real tunnel encapsulation mode (different opposite ends) of vxlan can be specified for the mac address. It can be encapsulated with static configuration only when there is no fdb table entry, which is very practical in SDN network.
In addition to the statically configured fdb table entries, like bridge, vxlan can also learn to produce fdb tables by doing src mac.
#ip link add vxlan100 type vxlan dstport 8899 vni 100 // The endpoint of the host with a mac of 52:54:00:f7:b4:22 is 172.16.20.12 #bridge fdb add 52:54:00:f7:b4:22 dev vxlan100 dst 172.16.20.12 // The endpoint of the host with mac 52:54:00:f7:b4:33 is 172.16.20.13, and the port and vni are 9999 and 200 respectively #bridge fdb add 52:54:00:f7:b4:33 dev vxlan100 dst 172.16.20.13 port 9999 vni 200
If the vxlan port is added in the bridge through addif, and the FDB table is configured, the FDB table will be generated in the bridge and vxlan at the same time, that is to say, when the message in the bridge looks up the FDB table of the bridge, confirms the vxlan port and enters the vxlan port_ Xmit sends, and looks up the FDB table of vxlan again to confirm the tunnel encapsulation. See rtnl_fdb_add function.
struct vxlan_fdb {
struct hlist_node hlist; /* linked list of entries */
struct rcu_head rcu;
unsigned long updated; /* jiffies */
unsigned long used;
struct list_head remotes; // Inserted vxlan_rdst, representing a peer (user)
u8 eth_addr[ETH_ALEN]; // mac address of table entry
u16 state; /* see ndm_state */
u8 flags; /* see ndm_flags */
};
// Represents a vxlan peer (user)
struct vxlan_rdst {
union vxlan_addr remote_ip;
__be16 remote_port;
__be32 remote_vni;
u32 remote_ifindex;
struct list_head list;
struct rcu_head rcu;
struct dst_cache dst_cache;
};
vxlan interface creation process, similar to various types of virtual interfaces, mainly completes the creation of net_ vxlan of device and its private structure_ Initialization of dev.
static int vxlan_newlink(struct net *src_net, struct net_device *dev,
struct nlattr *tb[], struct nlattr *data[])
{
// vxlan_config contains all the configurations supported by vxlan in linux. Of course, the configuration of ip link add type vxlan also includes
struct vxlan_config conf;
memset(&conf, 0, sizeof(conf));
......
// Create vxlan virtual interface device according to configuration
return vxlan_dev_configure(src_net, dev, &conf);
}
static int vxlan_dev_configure(struct net *src_net, struct net_device *dev,
struct vxlan_config *conf)
{
struct vxlan_net *vn = net_generic(src_net, vxlan_net_id);
struct vxlan_dev *vxlan = netdev_priv(dev), *tmp;
struct vxlan_rdst *dst = &vxlan->default_dst;
unsigned short needed_headroom = ETH_HLEN;
int err;
bool use_ipv6 = false;
__be16 default_port = vxlan->cfg.dst_port;
struct net_device *lowerdev = NULL;
if (conf->flags & VXLAN_F_GPE) {
/* For now, allow GPE only together with COLLECT_METADATA.
* This can be relaxed later; in such case, the other side
* of the PtP link will have to be provided.
*/
if ((conf->flags & ~VXLAN_F_ALLOWED_GPE) ||
!(conf->flags & VXLAN_F_COLLECT_METADATA)) {
pr_info("unsupported combination of extensions\n");
return -EINVAL;
}
vxlan_raw_setup(dev);
} else {
// Mount netdev_ops, specify the device sending function, open function and other device processing functions
vxlan_ether_setup(dev);
}
// According to the configuration, the vxlan configuration and default_dst assignment
vxlan->net = src_net;
dst->remote_vni = conf->vni;
memcpy(&dst->remote_ip, &conf->remote_ip, sizeof(conf->remote_ip));
/* Unless IPv6 is explicitly requested, assume IPv4 */
if (!dst->remote_ip.sa.sa_family)
dst->remote_ip.sa.sa_family = AF_INET;
if (dst->remote_ip.sa.sa_family == AF_INET6 ||
vxlan->cfg.saddr.sa.sa_family == AF_INET6) {
if (!IS_ENABLED(CONFIG_IPV6))
return -EPFNOSUPPORT;
use_ipv6 = true;
vxlan->flags |= VXLAN_F_IPV6;
}
if (conf->label && !use_ipv6) {
pr_info("label only supported in use with IPv6\n");
return -EINVAL;
}
// Verification of local binding interface
if (conf->remote_ifindex) {
lowerdev = __dev_get_by_index(src_net, conf->remote_ifindex);
dst->remote_ifindex = conf->remote_ifindex;
if (!lowerdev) {
pr_info("ifindex %d does not exist\n", dst->remote_ifindex);
return -ENODEV;
}
. . . . .
if (!conf->mtu)
dev->mtu = lowerdev->mtu - (use_ipv6 ? VXLAN6_HEADROOM : VXLAN_HEADROOM);
needed_headroom = lowerdev->hard_header_len;
} else if (vxlan_addr_multicast(&dst->remote_ip)) {
pr_info("multicast destination requires interface to be specified\n");
return -EINVAL;
}
if (conf->mtu) {
err = __vxlan_change_mtu(dev, lowerdev, dst, conf->mtu, false);
if (err)
return err;
}
if (use_ipv6 || conf->flags & VXLAN_F_COLLECT_METADATA)
needed_headroom += VXLAN6_HEADROOM;
else
needed_headroom += VXLAN_HEADROOM;
dev->needed_headroom = needed_headroom;
memcpy(&vxlan->cfg, conf, sizeof(*conf));
if (!vxlan->cfg.dst_port) {
if (conf->flags & VXLAN_F_GPE)
vxlan->cfg.dst_port = htons(4790); /* IANA VXLAN-GPE port */
else
vxlan->cfg.dst_port = default_port;
}
vxlan->flags |= conf->flags;
if (!vxlan->cfg.age_interval)
vxlan->cfg.age_interval = FDB_AGE_DEFAULT;
// vxlan repeatability judgment, only dstport+vni+flag, so even if different remote ip, the same dstport+vni cannot be configured
list_for_each_entry(tmp, &vn->vxlan_list, next) {
if (tmp->cfg.vni == conf->vni &&
(tmp->default_dst.remote_ip.sa.sa_family == AF_INET6 ||
tmp->cfg.saddr.sa.sa_family == AF_INET6) == use_ipv6 &&
tmp->cfg.dst_port == vxlan->cfg.dst_port &&
(tmp->flags & VXLAN_F_RCV_FLAGS) ==
(vxlan->flags & VXLAN_F_RCV_FLAGS)) {
pr_info("duplicate VNI %u\n", be32_to_cpu(conf->vni));
return -EEXIST;
}
}
dev->ethtool_ops = &vxlan_ethtool_ops;
/* create an fdb entry for a valid default destination */
// If a valid remote ip is configured, the fdb table of one hop all 0mac will be generated by default
if (!vxlan_addr_any(&vxlan->default_dst.remote_ip)) {
err = vxlan_fdb_create(vxlan, all_zeros_mac,
&vxlan->default_dst.remote_ip,
NUD_REACHABLE|NUD_PERMANENT,
NLM_F_EXCL|NLM_F_CREATE,
vxlan->cfg.dst_port,
vxlan->default_dst.remote_vni,
vxlan->default_dst.remote_ifindex,
NTF_SELF);
if (err)
return err;
}
/* Register device, involving net_ Some initialization of device structure, inserting it into the global list and hash table of this namespace
And generate a broadcast message to notify other components of this device registration event.
*/
err = register_netdevice(dev);
if (err) {
vxlan_fdb_delete_default(vxlan);
return err;
}
/* namespace Global vxlan information structure_ Net contains a vxlan device information list and a vxlan socket information accumulation table,
The vxlan device is inserted here_ Dev structure and vxlan sock structure are inserted in the vxlan open function later
*/
list_add(&vxlan->next, &vn->vxlan_list);
return 0;
}
vxlan open process is mainly used to create vxlan udp socket and mount the packet receiving and processing function of last udp protocol (vxlan).
/* Start ageing timer and join group when device is brought up */
static int vxlan_open(struct net_device *dev)
{
struct vxlan_dev *vxlan = netdev_priv(dev);
int ret;
ret = vxlan_sock_add(vxlan);
if (ret < 0)
return ret;
if (vxlan_addr_multicast(&vxlan->default_dst.remote_ip)) {
ret = vxlan_igmp_join(vxlan);
if (ret == -EADDRINUSE)
ret = 0;
if (ret) {
vxlan_sock_release(vxlan);
return ret;
}
}
if (vxlan->cfg.age_interval)
mod_timer(&vxlan->age_timer, jiffies + FDB_AGE_INTERVAL);
return ret;
}
The process of creating vxlan udp socket mainly focuses on the assignment of some data structures. In particular, encap is attached to udp socket (struct sock et)_ rcv=vxlan_ rcv,sk_user_data = vs is used for vxlan packet receiving processing after udp parses into vxlan message.
static int __vxlan_sock_add(struct vxlan_dev *vxlan, bool ipv6)
{
struct vxlan_net *vn = net_generic(vxlan->net, vxlan_net_id);
struct vxlan_sock *vs = NULL;
struct vxlan_dev_node *node;
// In the case of non sharing, multiple vxlan s may share a port. Here we will check whether the socket of this port has been created
if (!vxlan->cfg.no_share) {
spin_lock(&vn->sock_lock);
vs = vxlan_find_sock(vxlan->net, ipv6 ? AF_INET6 : AF_INET,
vxlan->cfg.dst_port, vxlan->flags);
if (vs && !atomic_add_unless(&vs->refcnt, 1, 0)) {
spin_unlock(&vn->sock_lock);
return -EBUSY;
}
spin_unlock(&vn->sock_lock);
}
if (!vs)
// Create a new vxlan socket
vs = vxlan_socket_create(vxlan->net, ipv6,
vxlan->cfg.dst_port, vxlan->flags);
if (IS_ERR(vs))
return PTR_ERR(vs);
#if IS_ENABLED(CONFIG_IPV6)
if (ipv6) {
rcu_assign_pointer(vxlan->vn6_sock, vs);
node = &vxlan->hlist6;
} else
#endif
{
rcu_assign_pointer(vxlan->vn4_sock, vs);
node = &vxlan->hlist4;
}
/* vxlan->cfg.no_share When configured for sharing, a socket will be shared by multiple vxlan s,
Here, the vxlan private structure will be vxlan_ Connect dev to vxlan_ sock->vni_ List */
vxlan_vs_add_dev(vs, vxlan, node);
return 0;
}
/* Create new listen socket if needed */
static struct vxlan_sock *vxlan_socket_create(struct net *net, bool ipv6,
__be16 port, u32 flags)
{
struct vxlan_net *vn = net_generic(net, vxlan_net_id);
struct vxlan_sock *vs;
struct socket *sock;
unsigned int h;
struct udp_tunnel_sock_cfg tunnel_cfg;
vs = kzalloc(sizeof(*vs), GFP_KERNEL);
if (!vs)
return ERR_PTR(-ENOMEM);
for (h = 0; h < VNI_HASH_SIZE; ++h)
INIT_HLIST_HEAD(&vs->vni_list[h]);
// Create socket structure, only port
sock = vxlan_create_sock(net, ipv6, port, flags);
if (IS_ERR(sock)) {
pr_info("Cannot bind port %d, err=%ld\n", ntohs(port),
PTR_ERR(sock));
kfree(vs);
return ERR_CAST(sock);
}
vs->sock = sock;
atomic_set(&vs->refcnt, 1);
vs->flags = (flags & VXLAN_F_RCV_FLAGS);
spin_lock(&vn->sock_lock);
hlist_add_head_rcu(&vs->hlist, vs_head(net, port));
udp_tunnel_notify_add_rx_port(sock,
(vs->flags & VXLAN_F_GPE) ?
UDP_TUNNEL_TYPE_VXLAN_GPE :
UDP_TUNNEL_TYPE_VXLAN);
spin_unlock(&vn->sock_lock);
/* Mark socket as an encapsulation socket. */
// Packet receiving and processing function of udp vxlan protocol_ RCV, associated data vs
memset(&tunnel_cfg, 0, sizeof(tunnel_cfg));
tunnel_cfg.sk_user_data = vs;
tunnel_cfg.encap_type = 1;
tunnel_cfg.encap_rcv = vxlan_rcv;
tunnel_cfg.encap_destroy = NULL;
tunnel_cfg.gro_receive = vxlan_gro_receive;
tunnel_cfg.gro_complete = vxlan_gro_complete;
setup_udp_tunnel_sock(net, sock, &tunnel_cfg);
return vs;
}
#####vxlan sending process:
vxlan_ The main logic of Xmit function (all ipv6 logic is ignored), and the incoming package is already a layer-2 eth package:
1. If vxlan is set to VXLAN_F_COLLECT_METADATA tag. If the IP command creates vxlan with external tag, the tunnel information set in the route is used to encapsulate vxlan transmission. This is a lightweight tunnel configuration method based on flow. For example, the following configuration method will directly use the encap information encap vxlan tunnel in the route. It can be seen that this dynamic vxlan encapsulation method is very different from the mac based encapsulation method of bridge command configuration fdb table mentioned at the beginning of this paper. It is based on IP. Remember this function:
ip link add vxlan1 type vxlan dstport 4789 external
ip route add 10.1.1.1 encap ip id 30001 dst 20.1.1.2 dev vxlan1
Normally SKB - >_ skb_ Refdst is set as rtable structure to save routing information. This light weight tunnel is set with metadata_dst, which saves the key parameters of tunnel.
struct metadata_dst {
struct dst_entry dst;
union {
struct ip_tunnel_info tun_info;
} u;
};
2. arp proxy function processing, if vxlan is set to VXLAN_F_PROXY, and the message is arp request, will query the local arp table item and answer arp reply. If there is no lookup table item, it will involve another function point, L3MIS, if the IFLA of vxlan_ VXLAN_ L3miss has been set and RTM will be sent through Netlink message_ Getfaith [l3miss notification] notifies Linux user status. The user status process can listen to this message and issue the kernel arp table entry. The next time it can answer successfully;
Here, let me recall the arp answering process of bridge. It requires that the mac address in the arp table entry must have an fdb table entry in the bridge, that is, the mac address is reachable before arp reply, while vxlan does not.
3. Query the fdb table according to the mac of the message. If it is found, it will check whether route short circuit processing is performed. The fdb table entry is marked as router (NTF_ROUTER), and vxlan has set the function IFLA_ VXLAN_ In case of RSC (route short circuit), the ARP table entry of the IP address of the message will be searched:
– if found, update the dmac of the message with the mac address of the arp table entry, and update the smac with the dmac of the message; In this way, you will actually regard yourself as a router. It is a hop from the source end to yourself and a hop from yourself to the destination end. The dmac address of the received message is for yourself, so the smac sent by yourself needs to be changed to the dmac of the message.
– if not found and the function IFLA is set_ VXLAN_ L3MISS, the Linux kernel notifies RTM of Netlink_ Getright [L3MISS notification] is sent to the user status. The user mode process can listen to this [L3MISS notification] and update the Linux kernel ARP. It's ok to return the message next time;
4. If the fdb table is not found according to the mac of the message, and the fdb table of all 0 Macs is queried for encapsulation and forwarding, it is natural to think that this is equivalent to the default route of three layers, which is very similar. Remember where this table item was added? When creating vxlan, if remote ip is configured, the fdb table with all mac zeros will be created;
5. If the fdb table of all mac zeros is not found, and if the l2mis feature is configured in vxlan, the l2mis processing will be performed most frequently. Then RTM_ Getfaith [l2mis notification] is sent to the user, and the user area process can listen to this [l2mis notification] and update the Linux kernel forwarding database. This is a very common feature. The old version of the container network scheme calico has been used;
6. In any case, find the fdb table and call vxlan_xmit_one encapsulates and sends vxlan message, otherwise the message will be discarded.
/* Transmit local packets over Vxlan
*
* Outer IP header inherits ECN and DF from inner header.
* Outer UDP destination is the VXLAN assigned port.
* source port is based on hash of flow
*/
static netdev_tx_t vxlan_xmit(struct sk_buff *skb, struct net_device *dev)
{
struct vxlan_dev *vxlan = netdev_priv(dev);
const struct ip_tunnel_info *info;
struct ethhdr *eth;
bool did_rsc = false;
struct vxlan_rdst *rdst, *fdst = NULL;
struct vxlan_fdb *f;
info = skb_tunnel_info(skb);
skb_reset_mac_header(skb);
// vxlan lightweight tunnel implementation, based on flow.
if (vxlan->flags & VXLAN_F_COLLECT_METADATA) {
if (info && info->mode & IP_TUNNEL_INFO_TX)
vxlan_xmit_one(skb, dev, NULL, false);
else
kfree_skb(skb);
return NETDEV_TX_OK;
}
// arp proxy function processing, if vxlan is set to VXLAN_F_PROXY, and the message is arp request, will query the local arp table item and answer arp reply on behalf of,
// If there is no lookup table item, another function point, L3MIS, will be involved. If vxlan IFLA_VXLAN_L3MISS is set,
// RTM via Netlink message_ Getright [l3miss notification] notifies Linux user status. User status processes can listen to this message,
// And issue the kernel arp table item, and you can answer it successfully next time.
if (vxlan->flags & VXLAN_F_PROXY) {
eth = eth_hdr(skb);
if (ntohs(eth->h_proto) == ETH_P_ARP)
return arp_reduce(dev, skb);
#if IS_ENABLED(CONFIG_IPV6)
......
#endif
}
eth = eth_hdr(skb);
// Find fdb table entries according to mac
f = vxlan_find_mac(vxlan, eth->h_dest);
did_rsc = false;
/* The function point here is called route short circuit. If the fdb table entry is marked as router (NTF_ROUTER),
And vxlan has set the function IFLA_VXLAN_RSC (routing short circuit), the ARP table entry of the IP address of the message will be checked:
--If found, update the dmac of the message with the mac address of the arp table entry, and update the smac with the dmac of the message; Doing so actually
Think of yourself as a router. It's a hop from the source to the destination.
--If not found and feature IFLA is set_ VXLAN_ L3miss, the Linux kernel notifies RTM of Netlink_ GETNEIGH [L3MISS NOTIFICATION]
Send to user status. The user mode process can listen to this [L3MISS notification] and update the Linux kernel ARP. It's ok to return the message next time
*/
if (f && (f->flags & NTF_ROUTER) && (vxlan->flags & VXLAN_F_RSC) &&
(ntohs(eth->h_proto) == ETH_P_IP ||
ntohs(eth->h_proto) == ETH_P_IPV6)) {
did_rsc = route_shortcircuit(dev, skb);
if (did_rsc)
f = vxlan_find_mac(vxlan, eth->h_dest);
}
if (f == NULL) {
// The fdb table of the target MAC of the packet is not found. Query the fdb table of all 0 MACs for encapsulation and forwarding. It is natural to think that this is equivalent to the default route of layer 3,
// Remember where this table item was added? When creating vxlan, if remote ip is configured, this fdb table will be created.
f = vxlan_find_mac(vxlan, all_zeros_mac);
if (f == NULL) {
/* This is a very common feature, which has been used in the old version of calico,
If the forwarded fdb table entry cannot be found and the L2MIS feature is configured, the RTM_ Getfaith [L2MIS notification] is sent to the user,
The user area process can listen to this [l2mis notification] and update the Linux kernel forwarding database.*/
if ((vxlan->flags & VXLAN_F_L2MISS) &&
!is_multicast_ether_addr(eth->h_dest))
vxlan_fdb_miss(vxlan, eth->h_dest);
dev->stats.tx_dropped++;
kfree_skb(skb);
return NETDEV_TX_OK;
}
}
// When the forwarding address is found, call vxlan_ xmit_ The one function encapsulates and sends.
list_for_each_entry_rcu(rdst, &f->remotes, list) {
struct sk_buff *skb1;
if (!fdst) {
fdst = rdst;
continue;
}
skb1 = skb_clone(skb, GFP_ATOMIC);
if (skb1)
vxlan_xmit_one(skb1, dev, rdst, did_rsc);
}
if (fdst)
vxlan_xmit_one(skb, dev, fdst, did_rsc);
else
kfree_skb(skb);
return NETDEV_TX_OK;
}
Find the fdb table, with all the encapsulated data, vxlan_xmit_one according to vxlan_rdst encapsulates vxlan header and UDP Tunnel and sends messages. sport is allocated according to the range configured by vxlan or the default range of the system. Before encapsulating the outer header, you will query whether the route of remote ip exists. If it does not exist, you will lose packets. If local ip is not configured, you will also use the sip of route as the outer sip.
After encapsulation, go ip_local_out the local sending process, and then enter the protocol stack.
static void vxlan_xmit_one(struct sk_buff *skb, struct net_device *dev,
struct vxlan_rdst *rdst, bool did_rsc)
{
struct dst_cache *dst_cache;
struct ip_tunnel_info *info;
struct vxlan_dev *vxlan = netdev_priv(dev);
struct sock *sk;
struct rtable *rt = NULL;
const struct iphdr *old_iph;
union vxlan_addr *dst;
union vxlan_addr remote_ip, local_ip;
struct vxlan_metadata _md;
struct vxlan_metadata *md = &_md;
__be16 src_port = 0, dst_port;
__be32 vni, label;
__be16 df = 0;
__u8 tos, ttl;
int err;
u32 flags = vxlan->flags;
bool udp_sum = false;
bool xnet = !net_eq(vxlan->net, dev_net(vxlan->dev));
info = skb_tunnel_info(skb);
rcu_read_lock();
if (rdst) {
dst_port = rdst->remote_port ? rdst->remote_port : vxlan->cfg.dst_port;
vni = rdst->remote_vni;
dst = &rdst->remote_ip;
local_ip = vxlan->cfg.saddr;
dst_cache = &rdst->dst_cache;
} else {
......
}
if (vxlan_addr_any(dst)) {
if (did_rsc) {
/* short-circuited back to local bridge */
vxlan_encap_bypass(skb, vxlan, vxlan);
goto out_unlock;
}
goto drop;
}
old_iph = ip_hdr(skb);
ttl = vxlan->cfg.ttl;
if (!ttl && vxlan_addr_multicast(dst))
ttl = 1;
tos = vxlan->cfg.tos;
if (tos == 1)
// The external ip header will inherit the Tos of the internal ip header. This is only done when tos==1 (generally, the lowest bit of Tos is 0).
// Curiosity specifically verified it. I don't know whether there is any stress or black technology.
tos = ip_tunnel_get_dsfield(old_iph, skb);
label = vxlan->cfg.label;
// Select the source port of UDP, which can be configured and specified, or use the system default range
src_port = udp_flow_src_port(dev_net(dev), skb, vxlan->cfg.port_min,
vxlan->cfg.port_max, true);
if (info) {
ttl = info->key.ttl;
tos = info->key.tos;
label = info->key.label;
udp_sum = !!(info->key.tun_flags & TUNNEL_CSUM);
if (info->options_len)
md = ip_tunnel_info_opts(info);
} else {
md->gbp = skb->mark;
}
if (dst->sa.sa_family == AF_INET) {
struct vxlan_sock *sock4 = rcu_dereference(vxlan->vn4_sock);
if (!sock4)
goto drop;
sk = sock4->sock->sk;
// Check the route here to check whether the remote ip address is reachable. By the way, find the source address through the route. In particular, we usually do not specify the local ip when configuring vxlan, so we do the assignment here
rt = vxlan_get_route(vxlan, skb,
rdst ? rdst->remote_ifindex : 0, tos,
dst->sin.sin_addr.s_addr,
&local_ip.sin.sin_addr.s_addr,
dst_cache, info);
if (IS_ERR(rt)) {
netdev_dbg(dev, "no route to %pI4\n",
&dst->sin.sin_addr.s_addr);
dev->stats.tx_carrier_errors++;
goto tx_error;
}
if (rt->dst.dev == dev) {
netdev_dbg(dev, "circular route to %pI4\n",
&dst->sin.sin_addr.s_addr);
dev->stats.collisions++;
goto rt_tx_error;
}
/* Bypass encapsulation if the destination is local */
if (!info && rt->rt_flags & RTCF_LOCAL &&
// bypass, ignore
. . .
}
if (!info)
udp_sum = !(flags & VXLAN_F_UDP_ZERO_CSUM_TX);
else if (info->key.tun_flags & TUNNEL_DONT_FRAGMENT)
df = htons(IP_DF);
// ECN packaging, a feature of flow control, has been used in work. If you do not inherit to, you have to inherit CE mark
tos = ip_tunnel_ecn_encap(tos, old_iph, skb);
ttl = ttl ? : ip4_dst_hoplimit(&rt->dst);
// Package vxlan head
err = vxlan_build_skb(skb, &rt->dst, sizeof(struct iphdr),
vni, md, flags, udp_sum);
if (err < 0)
goto xmit_tx_error;
// Encapsulate UDP header and external IP header, and finally go to ip_local_out, follow the local three-tier sending process
udp_tunnel_xmit_skb(rt, sk, skb, local_ip.sin.sin_addr.s_addr,
dst->sin.sin_addr.s_addr, tos, ttl, df,
src_port, dst_port, xnet, !udp_sum);
#if IS_ENABLED(CONFIG_IPV6)
// ipv6 support, ignored
......
#endif
}
......
}
#####Then the receiving process:
Vxlan message, first UDP message, such as vxlan above_ As seen in the open function, when creating a vxlan UDP socket, encap is attached to it_ rcv==vxlan_rcv, so after vxlan's UDP message, call vxlan_. RCV processing.
vxlan_ The whole process of RCV is relatively simple. According to the packet received by socket and socket, find the information related to vxlan, including vxlan_dev,vxlan_sock, take off the vxlan header, send a complete layer-2 package into the protocol stack, and go through the layer-2, 3 and 4 protocol stack again.
/* Callback from net/ipv4/udp.c to receive packets */
static int vxlan_rcv(struct sock *sk, struct sk_buff *skb)
{
struct pcpu_sw_netstats *stats;
struct vxlan_dev *vxlan;
struct vxlan_sock *vs;
struct vxlanhdr unparsed;
struct vxlan_metadata _md;
struct vxlan_metadata *md = &_md;
__be16 protocol = htons(ETH_P_TEB);
bool raw_proto = false;
void *oiph;
/* Need UDP and VXLAN header to be present */
if (!pskb_may_pull(skb, VXLAN_HLEN))
goto drop;
// vxlan header, vni+flag
unparsed = *vxlan_hdr(skb);
/* VNI flag always required to be set */
if (!(unparsed.vx_flags & VXLAN_HF_VNI)) {
netdev_dbg(skb->dev, "invalid vxlan flags=%#x vni=%#x\n",
ntohl(vxlan_hdr(skb)->vx_flags),
ntohl(vxlan_hdr(skb)->vx_vni));
/* Return non vxlan pkt */
goto drop;
}
unparsed.vx_flags &= ~VXLAN_HF_VNI;
unparsed.vx_vni &= ~VXLAN_VNI_MASK;
// Such as vxlan_ As mentioned in the open process, vxlan is mounted in the sock_ RCV (encap_rcv) and vxlan_sock(sk_user_data) is extracted here
vs = rcu_dereference_sk_user_data(sk);
if (!vs)
goto drop;
// A port(sock) may associate multiple vxlans according to vni_ Dev, vxlan is found here_ dev
vxlan = vxlan_vs_find_vni(vs, vxlan_vni(vxlan_hdr(skb)->vx_vni));
if (!vxlan)
goto drop;
/* For backwards compatibility, only allow reserved fields to be
* used by VXLAN extensions if explicitly requested.
*/
if (vs->flags & VXLAN_F_GPE) {
if (!vxlan_parse_gpe_hdr(&unparsed, &protocol, skb, vs->flags))
goto drop;
raw_proto = true;
}
// Remove the vxlan header and parse the upper layer protocol type from the eth message
if (__iptunnel_pull_header(skb, VXLAN_HLEN, protocol, raw_proto,
!net_eq(vxlan->net, dev_net(vxlan->dev))))
goto drop;
if (vxlan_collect_metadata(vs)) {
__be32 vni = vxlan_vni(vxlan_hdr(skb)->vx_vni);
struct metadata_dst *tun_dst;
tun_dst = udp_tun_rx_dst(skb, vxlan_get_sk_family(vs), TUNNEL_KEY,
key32_to_tunnel_id(vni), sizeof(*md));
if (!tun_dst)
goto drop;
md = ip_tunnel_info_opts(&tun_dst->u.tun_info);
skb_dst_set(skb, (struct dst_entry *)tun_dst);
} else {
memset(md, 0, sizeof(*md));
}
if (vs->flags & VXLAN_F_REMCSUM_RX)
if (!vxlan_remcsum(&unparsed, skb, vs->flags))
goto drop;
if (vs->flags & VXLAN_F_GBP)
vxlan_parse_gbp_hdr(&unparsed, skb, vs->flags, md);
/* Note that GBP and GPE can never be active together. This is
* ensured in vxlan_dev_configure.
*/
if (unparsed.vx_flags || unparsed.vx_vni) {
/* If there are any unprocessed flags remaining treat
* this as a malformed packet. This behavior diverges from
* VXLAN RFC (RFC7348) which stipulates that bits in reserved
* in reserved fields are to be ignored. The approach here
* maintains compatibility with previous stack code, and also
* is more robust and provides a little more security in
* adding extensions to VXLAN.
*/
goto drop;
}
if (!raw_proto) {
// Vxlan is configured with VXLAN_F_LEARN, then do fdb learning according to eth smac
if (!vxlan_set_mac(vxlan, vs, skb))
goto drop;
} else {
skb_reset_mac_header(skb);
skb->dev = vxlan->dev;
skb->pkt_type = PACKET_HOST;
}
oiph = skb_network_header(skb);
skb_reset_network_header(skb);
if (!vxlan_ecn_decapsulate(vs, oiph, skb)) {
++vxlan->dev->stats.rx_frame_errors;
++vxlan->dev->stats.rx_errors;
goto drop;
}
stats = this_cpu_ptr(vxlan->dev->tstats);
u64_stats_update_begin(&stats->syncp);
stats->rx_packets++;
stats->rx_bytes += skb->len;
u64_stats_update_end(&stats->syncp);
// This function sends the eth message inside vxlan to the protocol stack, and the eth packet receiving ends
gro_cells_receive(&vxlan->gro_cells, skb);
return 0;
drop:
/* Consume bad packet */
kfree_skb(skb);
return 0;
}
static inline int gro_cells_receive(struct gro_cells *gcells, struct sk_buff *skb)
{
struct gro_cell *cell;
struct net_device *dev = skb->dev;
if (!gcells->cells || skb_cloned(skb) || !(dev->features & NETIF_F_GRO))
// For non NAPI packet receiving processing and virtual port receiving, this is generally done if soft interrupt trigger processing is required.
return netif_rx(skb);
cell = this_cpu_ptr(gcells->cells);
if (skb_queue_len(&cell->napi_skbs) > netdev_max_backlog) {
atomic_long_inc(&dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;
}
__skb_queue_tail(&cell->napi_skbs, skb);
if (skb_queue_len(&cell->napi_skbs) == 1)
napi_schedule(&cell->napi);
return NET_RX_SUCCESS;
}
And add an fdb side learning
static bool vxlan_set_mac(struct vxlan_dev *vxlan,
struct vxlan_sock *vs,
struct sk_buff *skb)
{
union vxlan_addr saddr;
__be16 sport = udp_hdr(skb)->source;
__be32 vni = vxlan_vni(vxlan_hdr(skb)->vx_vni)
// Layer 2 header updated to internal layer 2 header
skb_reset_mac_header(skb);
skb->protocol = eth_type_trans(skb, vxlan->dev);
skb_postpull_rcsum(skb, eth_hdr(skb), ETH_HLEN);
/* Ignore packet loops (and multicast echo) */
if (ether_addr_equal(eth_hdr(skb)->h_source, vxlan->dev->dev_addr))
return false;
/* vxlan_rcv When entering this function, the network header is still the out ip header,
Get address from the outer IP header */
if (vxlan_get_sk_family(vs) == AF_INET) {
saddr.sin.sin_addr.s_addr = ip_hdr(skb)->saddr;
saddr.sa.sa_family = AF_INET;
#if IS_ENABLED(CONFIG_IPV6)
} else {
saddr.sin6.sin6_addr = ipv6_hdr(skb)->saddr;
saddr.sa.sa_family = AF_INET6;
#endif
}
// Vxlan has vxlan by default_ F_ Learn flag. The above process extracts dst mac, tunnel remote ip, dstport and vni required by fdb
// vxlan_snoop uses this information to learn an fdb table
if ((vxlan->flags & VXLAN_F_LEARN) &&
vxlan_snoop(skb->dev, &saddr, sport, vni, eth_hdr(skb)->h_source))
return false;
return true;
}
static bool vxlan_snoop(struct net_device *dev,
union vxlan_addr *src_ip, __be16 src_port, __be32 vni, const u8 *src_mac)
{
struct vxlan_dev *vxlan = netdev_priv(dev);
struct vxlan_fdb *f;
// Find out whether the fdb table of this smac exists
f = vxlan_find_mac(vxlan, src_mac);
if (likely(f)) {
struct vxlan_rdst *rdst = first_remote_rcu(f);
// In case of existence, a mac can only belong to one peer. If remote_ip is different, update table entries
// In theory, vni judgment needs to be added. vni distinguishes users, and mac of different users can be repeated
if (likely(vxlan_addr_equal(&rdst->remote_ip, src_ip)))
return false;
/* Don't migrate static entries, drop packets */
if (f->state & NUD_NOARP)
return true;
if (net_ratelimit())
netdev_info(dev,
"%pM migrated from %pIS to %pIS\n",
src_mac, &rdst->remote_ip.sa, &src_ip->sa);
rdst->remote_ip = *src_ip;
rdst->remote_port = src_port;
rdst->remote_vni = vni;
f->updated = jiffies;
vxlan_fdb_notify(vxlan, f, rdst, RTM_NEWNEIGH);
} else {
/* learned new entry */
spin_lock(&vxlan->hash_lock);
// Create a new fdb table entry
/* close off race between vxlan_flush and incoming packets */
if (netif_running(dev))
vxlan_fdb_create(vxlan, src_mac, src_ip,
NUD_REACHABLE,
NLM_F_EXCL|NLM_F_CREATE,
vxlan->dst_port,
vxlan->default_dst.remote_vni,
0, NTF_SELF);
spin_unlock(&vxlan->hash_lock);
}
return false;
}