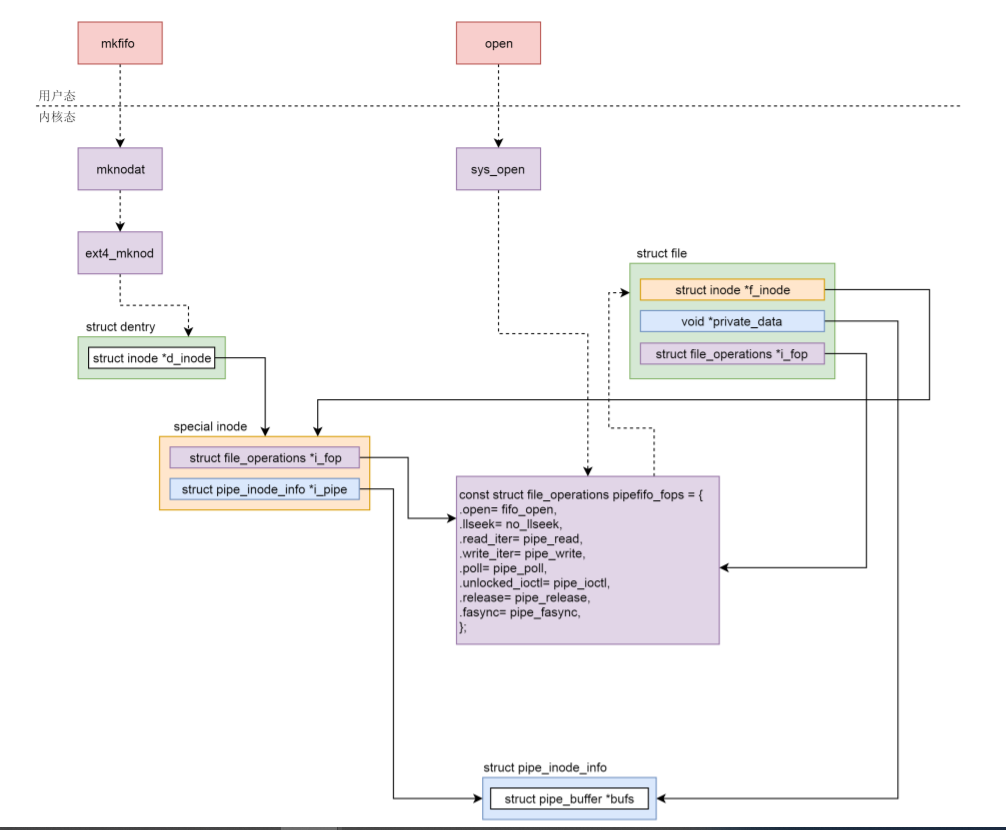
Principle of anonymous pipeline
The following system call is required to create a pipeline
int pipe(int fd[2])
Here, we create a pipe and return two file descriptors, which represent both ends of the pipe. One is the read descriptor fd[0] of the pipe and the other is the write descriptor fd[1] of the pipe
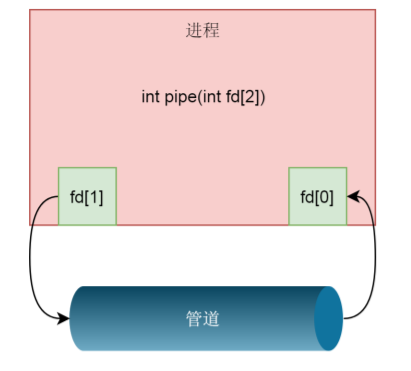
Let's look at how it is implemented in the kernel.
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{
return sys_pipe2(fildes, 0);
}
SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags)
{
struct file *files[2];
int fd[2];
int error;
error = __do_pipe_flags(fd, files, flags);
if (!error) {
if (unlikely(copy_to_user(fildes, fd, sizeof(fd)))) {
......
error = -EFAULT;
} else {
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
}
return error;
}
In the kernel, the main logic is in the pipe2 system call. An array file is created to store the open files at both ends of the pipeline, and another array fd stores the file descriptors at both ends of the pipeline. If called__ do_ pipe_ If there is no error in flags, call fd_install, associate two fd and two struct file s.
Let's see__ do_pipe_flags. Create is called here_ pipe_ Files, and then two fd are generated. It can be seen from here that fd[0] is used for reading and fd[1] is used for writing
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
int error;
int fdw, fdr;
......
error = create_pipe_files(files, flags);
......
error = get_unused_fd_flags(flags);
......
fdr = error;
error = get_unused_fd_flags(flags);
......
fdw = error;
fd[0] = fdr;
fd[1] = fdw;
return 0;
......
}
To create a pipeline, most of the logic is actually in create_ pipe_ Implemented in the files function. Named pipes are created on the file system. Anonymous pipeline is also created on the file system. It is just a special file system. Create a special file corresponding to a special inode, which is the get here_ pipe_ inode
int create_pipe_files(struct file **res, int flags)
{
int err;
struct inode *inode = get_pipe_inode();
struct file *f;
struct path path;
......
path.dentry = d_alloc_pseudo(pipe_mnt->mnt_sb, &empty_name);
......
path.mnt = mntget(pipe_mnt);
d_instantiate(path.dentry, inode);
f = alloc_file(&path, FMODE_WRITE, &pipefifo_fops);
......
f->f_flags = O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT));
f->private_data = inode->i_pipe;
res[0] = alloc_file(&path, FMODE_READ, &pipefifo_fops);
......
path_get(&path);
res[0]->private_data = inode->i_pipe;
res[0]->f_flags = O_RDONLY | (flags & O_NONBLOCK);
res[1] = f;
return 0;
......
}
From get_ pipe_ The implementation of inode shows that the anonymous pipeline comes from a special file system pipefs. After the file system is mounted, we get struct vfsmount *pipe_mnt. Then the superblock of the mounted file system becomes: pipe_ mnt->mnt_ sb.
static struct file_system_type pipe_fs_type = {
.name = "pipefs",
.mount = pipefs_mount,
.kill_sb = kill_anon_super,
};
static int __init init_pipe_fs(void)
{
int err = register_filesystem(&pipe_fs_type);
if (!err) {
pipe_mnt = kern_mount(&pipe_fs_type);
}
......
}
static struct inode * get_pipe_inode(void)
{
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
......
inode->i_ino = get_next_ino();
pipe = alloc_pipe_info();
......
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
inode->i_fop = &pipefifo_fops;
inode->i_state = I_DIRTY;
inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
return inode;
......
}
We're from New_ Inode_ The pseudo function creates an Inode. Start filling in Inode members, which is very similar to the file system. It is worth noting here that struct pipe_inode_info, a member of this structure is struct pipe_buffer *bufs. We can know that the so-called anonymous pipeline is actually a string of caches in the kernel.
Another thing to note is pipefifo_fops, in the future, our operations on file descriptors will correspond to these operations in the kernel.
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
};
Let's go back to create_pipe_files function. After creating inode, you need to create a dentry corresponding to it. Dentry corresponds to inode, and we are about to start creating struct file objects. First create a for writing, and the corresponding operation is pipefifo_fops; When the read is re created, the corresponding operation is pipefifo_fops. Then put private_ Set data to pipe_inode_info. In this way, from the level of struct file, you can directly operate the underlying read and write operations.
At this point, an anonymous pipeline is created successfully. For fd[1] writes, pipe is called_ Write to pipe_write data in the buffer; If the read in of fd[0] calls pipe_read, that is, from pipe_read data from the buffer.
But at this time, the two file descriptors are in the same process and do not play the role of inter process communication. How can the pipeline span two processes? When a process calls fork, the child process created will copy the struct file of the parent process_ Struct, the array of fd will copy one copy, but the struct file pointed to by fd is still only one copy for the same file. This is done. The two processes have two patterns in which fd points to the same struct file. The two processes can write and read the same pipeline file through their respective fd to realize cross process communication
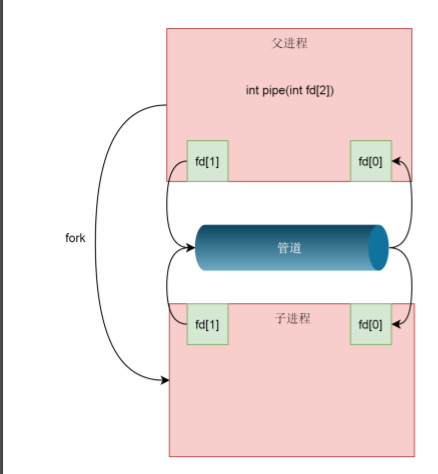
Since the pipeline can only be written at one end and read at the other end, the above mode will cause confusion, because both the parent process and the child process can write and read. The usual method is that the parent process closes the read fd and only keeps the written fd, while the child process closes the written fd and only keeps the read fd. If two-way traffic is required, two pipelines should be created.
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main(int argc, char *argv[])
{
int fds[2];
if (pipe(fds) == -1)
perror("pipe error");
pid_t pid;
pid = fork();
if (pid == -1)
perror("fork error");
if (pid == 0){
close(fds[0]);
char msg[] = "hello world";
write(fds[1], msg, strlen(msg) + 1);
close(fds[1]);
exit(0);
} else {
close(fds[1]);
char msg[128];
read(fds[0], msg, 128);
close(fds[0]);
printf("message : %s\n", msg);
return 0;
}
}
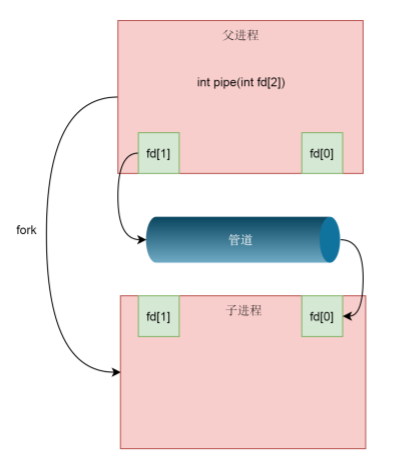
So far, we only analyzed the communication between parent and child processes using pipes, but this is not the case in the shell. When running A|B in the shell, process A and process B are child processes created by the shell. There is no parent-child relationship between A and B.
However, with the above pipeline between parent and child processes, it is much more convenient to implement the pipeline between A and B.
We first create sub process A from the shell, and then establish A pipeline between the shell and A, in which the shell retains the reading end, the A process retains the writing end, and then the shell creates sub process B. This is another fork. Therefore, the fd of the reading end reserved in the shell is also copied to sub process B. At this time, it is equivalent that both shell and B retain the reading end. As long as the shell actively closes the reading end, it becomes A pipeline. The writing end is in process A and the reading end is in process B.
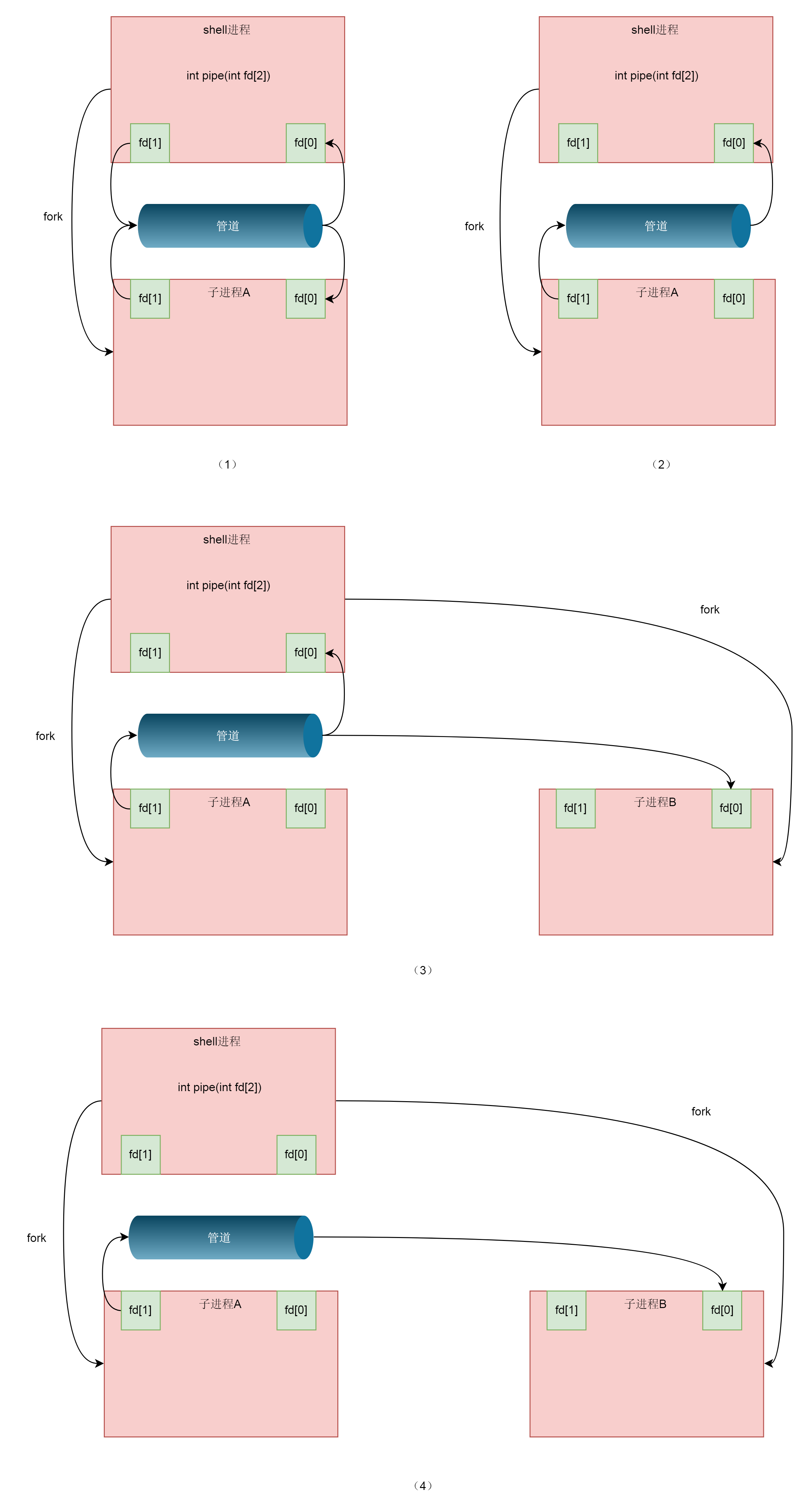
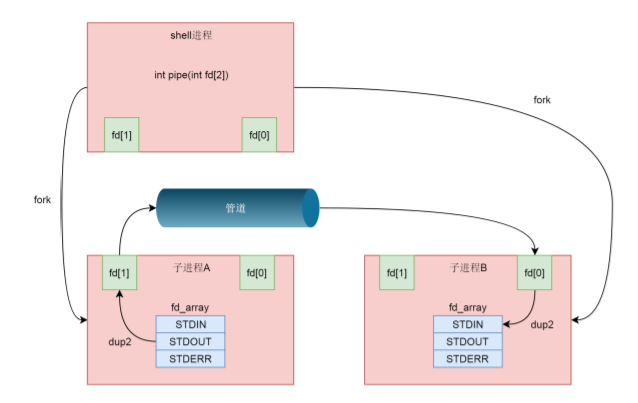
The next thing we need to do is associate the two ends of the pipeline with the input and output. This requires the dup2 system call.
int dup2(int oldfd, int newfd);
This system call assigns the old file descriptor to the new file descriptor so that the value of newfd is the same as that of oldfd.
In files_ In struct, there is such a table, the subscript is fd, and the content points to an open file, struct file.
struct files_struct {
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
}
In this table, the first three items are determined, and the zero item STDIN_FILENO indicates standard input, and the first item is STDOUT_FILENO indicates standard output, and the third item is STDERR_FILENO indicates error output.
In process A, the write side can do the following operations: dup2(fd[1], STDOUT_FILENO), stdout_ Fileno (the first item) no longer points to the standard output, but the pipeline file of the execution scenario. Anything written to the standard output in the future will be written to the pipeline file
In process A, the write side can do the following operations: dup2(fd[1],STDOUT_FILENO), stdout_ Fileno (that is, the first item) no longer points to the standard output, but to the created pipeline file. Anything written to the standard output in the future will be written to the pipeline file.
In process B, the reading end can do this operation, dup2(fd[0],STDIN_FILENO), and stdin_ Fileno, that is, the zero item no longer points to the standard input, but to the created pipeline file. Then anything read from the standard input in the future comes from the pipeline file.
So far, we have completed the function of A|B.
name pipes
Named pipes need to be created in advance through the command mkfifo process. If you create a named pipe through code, there is also a function, but this is not a system call, but a function provided by Glibc. It is defined as follows:
int
mkfifo (const char *path, mode_t mode)
{
dev_t dev = 0;
return __xmknod (_MKNOD_VER, path, mode | S_IFIFO, &dev);
}
int
__xmknod (int vers, const char *path, mode_t mode, dev_t *dev)
{
unsigned long long int k_dev;
......
/* We must convert the value to dev_t type used by the kernel. */
k_dev = (*dev) & ((1ULL << 32) - 1);
......
return INLINE_SYSCALL (mknodat, 4, AT_FDCWD, path, mode,
(unsigned int) k_dev);
}
Glibc's mkfifo function calls the mknodat system call (the named pipe is also a device, so mknod is also used)
SYSCALL_DEFINE4(mknodat, int, dfd, const char __user *, filename, umode_t, mode, unsigned, dev)
{
struct dentry *dentry;
struct path path;
unsigned int lookup_flags = 0;
......
retry:
dentry = user_path_create(dfd, filename, &path, lookup_flags);
......
switch (mode & S_IFMT) {
......
case S_IFIFO: case S_IFSOCK:
error = vfs_mknod(path.dentry->d_inode,dentry,mode,0);
break;
}
......
}
Mknod starts with user_path_create creates a dentry for the pipeline file, and then because it is s_ IFO, so call vfs_mknod. Since the pipeline file is created on an ordinary file system, it is assumed to be on the ext4 file, so vfs_mknod calls ext4_ dir_ inode_ Mknod of operations, that is, ext4 will be called_ mknod.
const struct inode_operations ext4_dir_inode_operations = {
......
.mknod = ext4_mknod,
......
};
static int ext4_mknod(struct inode *dir, struct dentry *dentry,
umode_t mode, dev_t rdev)
{
handle_t *handle;
struct inode *inode;
......
inode = ext4_new_inode_start_handle(dir, mode, &dentry->d_name, 0,
NULL, EXT4_HT_DIR, credits);
handle = ext4_journal_current_handle();
if (!IS_ERR(inode)) {
init_special_inode(inode, inode->i_mode, rdev);
inode->i_op = &ext4_special_inode_operations;
err = ext4_add_nondir(handle, dentry, inode);
if (!err && IS_DIRSYNC(dir))
ext4_handle_sync(handle);
}
if (handle)
ext4_journal_stop(handle);
......
}
#define ext4_new_inode_start_handle(dir, mode, qstr, goal, owner, \
type, nblocks) \
__ext4_new_inode(NULL, (dir), (mode), (qstr), (goal), (owner), \
0, (type), __LINE__, (nblocks))
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
else
......
}
In ext4_ In mknod, ext4_new_inode_start_handle will call__ ext4_new_inode, a file is really created on the ext4 file system, but init will be called_ special_ Inode, create a special inode in memory. We have also encountered this function in the character device file, but the I of inode at that time_ FOP points to def_chr_fops, this time it's changed to a pipeline file, inode's i_fop becomes pipefifo_fops, this is the same as anonymous pipeline.
The pipeline file is created.
Next, to open the pipeline file, we will still call the open function of the file system. Or call pipefifo all the way along the call mode of the file system_ FOPS' open function, that is, fifo_open.
static int fifo_open(struct inode *inode, struct file *filp)
{
struct pipe_inode_info *pipe;
bool is_pipe = inode->i_sb->s_magic == PIPEFS_MAGIC;
int ret;
filp->f_version = 0;
if (inode->i_pipe) {
pipe = inode->i_pipe;
pipe->files++;
} else {
pipe = alloc_pipe_info();
pipe->files = 1;
inode->i_pipe = pipe;
spin_unlock(&inode->i_lock);
}
filp->private_data = pipe;
filp->f_mode &= (FMODE_READ | FMODE_WRITE);
switch (filp->f_mode) {
case FMODE_READ:
pipe->r_counter++;
if (pipe->readers++ == 0)
wake_up_partner(pipe);
if (!is_pipe && !pipe->writers) {
if ((filp->f_flags & O_NONBLOCK)) {
filp->f_version = pipe->w_counter;
} else {
if (wait_for_partner(pipe, &pipe->w_counter))
goto err_rd;
}
}
break;
case FMODE_WRITE:
pipe->w_counter++;
if (!pipe->writers++)
wake_up_partner(pipe);
if (!is_pipe && !pipe->readers) {
if (wait_for_partner(pipe, &pipe->r_counter))
goto err_wr;
}
break;
case FMODE_READ | FMODE_WRITE:
pipe->readers++;
pipe->writers++;
pipe->r_counter++;
pipe->w_counter++;
if (pipe->readers == 1 || pipe->writers == 1)
wake_up_partner(pipe);
break;
......
}
......
}
In fifo_open, create a pipe_inode_info, which is the same as anonymous pipeline. One member of this structure is struct pipe_buffer *bufs. We can know that the so-called named pipeline is actually a string of caches in the kernel.
Next, for the writing of named pipes, we will still call pipefifo_ Pipe of FOPS_ Write function, to pipe_write data in the buffer. For the read in of named pipes, we will still call pipefifo_ Pipe of FOPS_ Read, that is, from pipe_read data from the buffer.
summary
Whether it is an anonymous pipe or a named pipe, it is a file in the kernel. As long as it is a file, there must be an inode. A special inode is used here. Character devices and block devices are all special inodes.
In this special inode, file_operations executes a special pipefifo_fops, this inode corresponds to the cache in memory
When we use the open function of the file to open the pipeline, pipefifo will be called for special files_ The method in FOPS creates a struct file structure. Its inode points to a special inode and also corresponds to the cache in memory, file_operations also point to the pipe specific pipefifo_fops.
Writing a pipe is to find the cache write from the struct file structure, and reading a pipe is to find the cache read from the struct file structure.