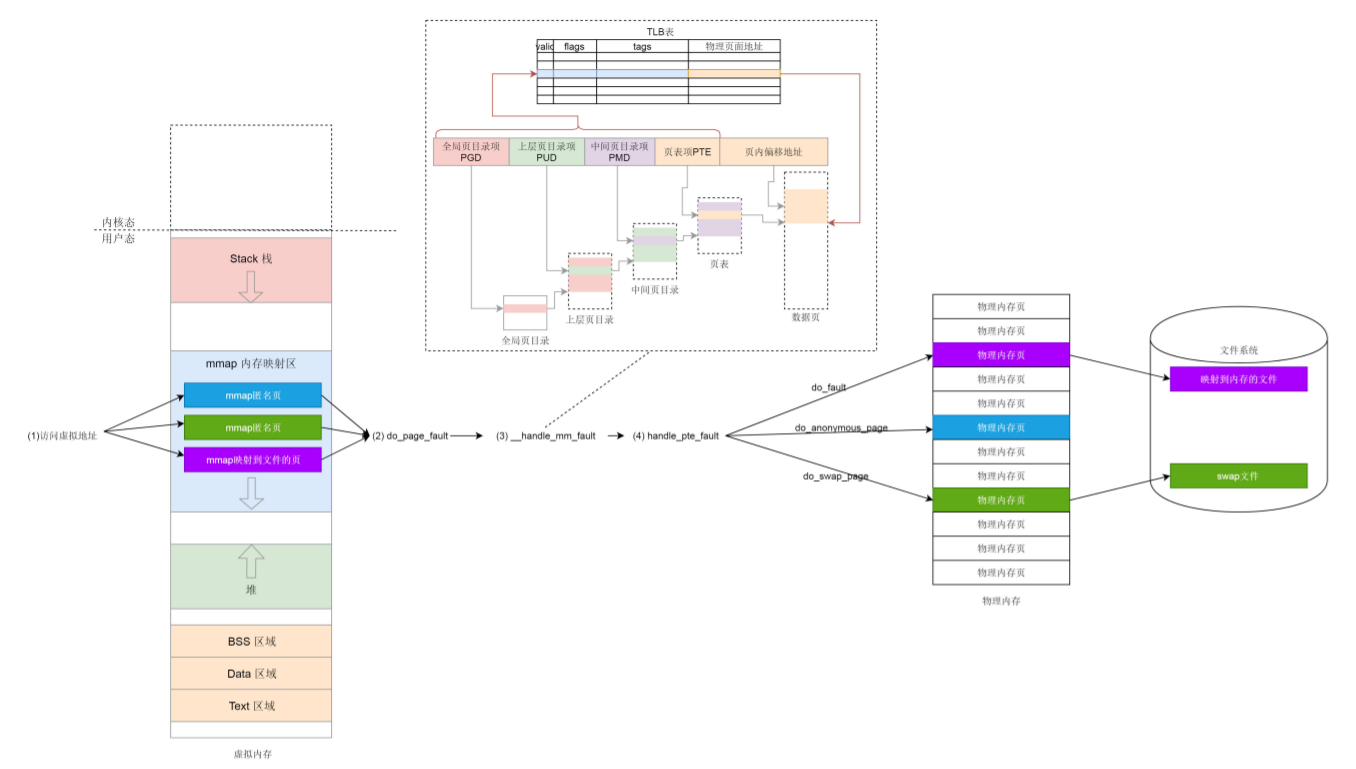
In the previous sections, we learned how to organize virtual memory space and how to manage physical pages. Limitation we need some data structures to manage the two
mmap principle
Each process has a list vm_area_struct, which points to different memory blocks in the virtual address space. This code is called mmap
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
......
}
struct vm_area_struct {
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
In fact, memory mapping is not only the mapping between physical memory and virtual memory, but also includes mapping the contents of files to virtual memory space. At this time, you can access the data in the file by accessing the memory space. The mapping of only physical memory and virtual memory is a special case.
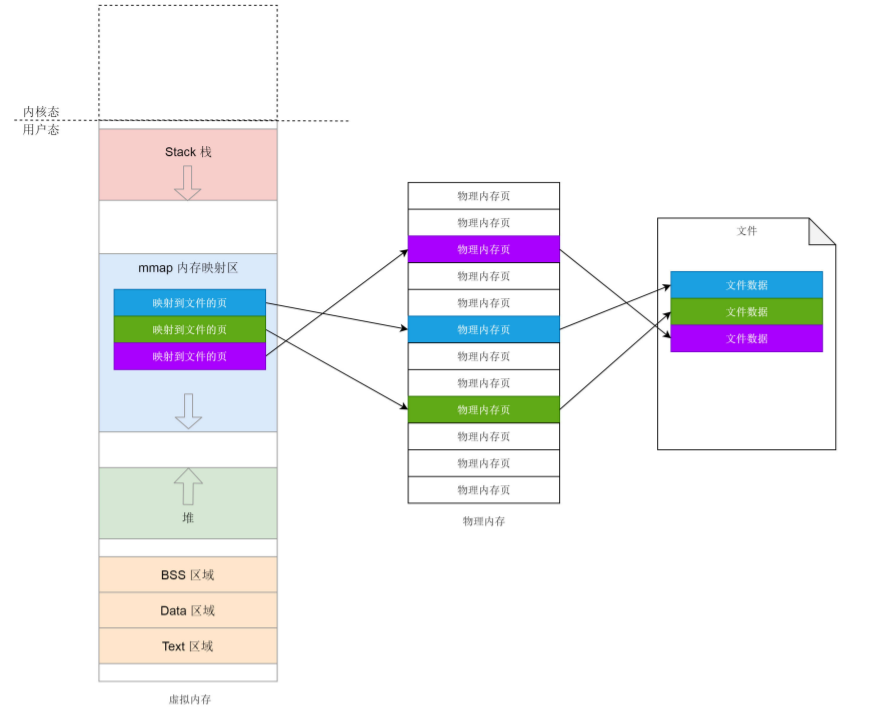
- If we want to apply for small heap memory, we use brk.
- If we want to apply for large heap memory, we use mmap. mmap here is to map memory space to physical memory
- If a process wants to map a file to its own virtual memory space, it can also use the mmap system call. At this time, mmap maps memory space to physical memory and then to files.
What does the mmap system call do?
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
......
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
......
}
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
......
file = fget(fd);
......
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
return retval;
}
If you want to map to a file, fd will pass a file descriptor and mmap_pgoff uses the fget function to generate a good struct file according to the file descriptor. Struct file represents an open file.
The next call chain is VM_ mmap_ pgoff->do_ mmap_ pgoff->do_ mmap. There are two main things to do:
- Call get_unmapped_area found an area without mapping
- Call mmap_region maps this region
Let's see_ unmapped_ Area function
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
......
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
}
......
}
- If this is an anonymous mapping, mm is called_ Get in struct_ unmapped_ Area function. This function is actually arch_get_unmapped_area. It calls find_vma_prev, in the VM representing the virtual memory area_ area_ Struct finds the corresponding location on the red black tree. The reason why it is called prev is that the virtual memory area has not been established at this time, and the previous VM is found_ area_ struct
- If it is mapped to a file instead of anonymous mapping, in Linux, each open file has a struct file structure with a file_operations, used to represent operations related to this file. If we are familiar with ext4 file system, we call thp_get_unmapped_area. If we look closely at this function, we will eventually call mm_ Get in struct_ unmapped_ Area function. All roads lead to Rome.
const struct file_operations ext4_file_operations = {
......
.mmap = ext4_file_mmap
.get_unmapped_area = thp_get_unmapped_area,
};
unsigned long __thp_get_unmapped_area(struct file *filp, unsigned long len,
loff_t off, unsigned long flags, unsigned long size)
{
unsigned long addr;
loff_t off_end = off + len;
loff_t off_align = round_up(off, size);
unsigned long len_pad;
len_pad = len + size;
......
addr = current->mm->get_unmapped_area(filp, 0, len_pad,
off >> PAGE_SHIFT, flags);
addr += (off - addr) & (size - 1);
return addr;
}
Let's look at MMAP again_ Region to see how it maps this virtual memory area:
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
}
......
vma_link(mm, vma, prev, rb_link, rb_parent);
return addr;
.....
- Remember we just found the previous VM of the virtual memory area_ area_ Struct, we first need to see whether we can extend the process based on it, that is, call vma_merge, and the previous vm_area_struct merged together.
- If not, you need to call kmem_cache_zalloc, create a new VM in Slub_ area_ Struct object, set the start and end positions, and add it to the queue.
- If it is mapped to a file, set vm_flie is the target file and call_mmap. It's actually calling file_ MMAP function of operations. For the ext4 file system, ext4 is called_ file_ mmap. From the parameters of the political function, we can see that at this moment, the relationship between file and memory began to occur. Here we will VM_ area_ The memory operation of struct is set as file system operation, that is, reading and writing memory is reading and writing file system
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
return file->f_op->mmap(file, vma);
}
static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma)
{
......
vma->vm_ops = &ext4_file_vm_ops;
......
}
- Let's go back to mmap_region function. Finally, VMA_ The link function will the newly created vm_area_struct hanging in mm_ On the red and black tree in struct
At this time, the mapping relationship from memory to file should be established at least at the logical level. What about the mapping from file to memory? vma_link also did another thing, that is__ vma_link_file. This thing requires users to establish this layer of mapping relationship.
The open file will be represented by a structure struct file. It has a member pointing to struct address_space structure, in which there is a variable named I_ Red black tree of MMAP, vm_area_struct is hanging on this tree.
struct address_space {
struct inode *host; /* owner: inode, block_device */
......
struct rb_root i_mmap; /* tree of private and shared mappings */
......
const struct address_space_operations *a_ops; /* methods */
......
}
static void __vma_link_file(struct vm_area_struct *vma)
{
struct file *file;
file = vma->vm_file;
if (file) {
struct address_space *mapping = file->f_mapping;
vma_interval_tree_insert(vma, &mapping->i_mmap);
}
At this point, the content of memory mapping will come to an end. But now there is no relationship with physical memory, or tossing in virtual memory?
Yes, because so far, we haven't really started accessing memory. At this time, memory management does not directly allocate physical memory, because physical memory is too valuable relative to virtual address space. It will not be allocated until it is actually used
Page missing exception in user status
Once you start accessing an address of the virtual memory, if you find that there is no corresponding physical page, you will trigger a page missing interrupt and call do_page_fault
dotraplinkage void notrace
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address = read_cr2(); /* Get the faulting address */
......
__do_page_fault(regs, error_code, address);
......
}
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
......
vma = find_vma(mm, address);
......
fault = handle_mm_fault(vma, address, flags);
......
- In__ do_ page_ In fault, first judge whether the page missing interrupt occurs in the kernel.
- If it happens in the kernel, call vmalloc_fault, in the kernel, the vmalloc area needs to map the kernel page table to the physical page
- If it happens in the user space, find the region VM where the address you visit is located_ area_ Struct, and then call handle_. mm_ Fault to map this area
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}
Here, we see the familiar PGD, P4G, PUD, PMD and PTE, which is the concept of four level page table in the page table (because the five level page table is not considered for the time being, we ignore P4G for the time being.)
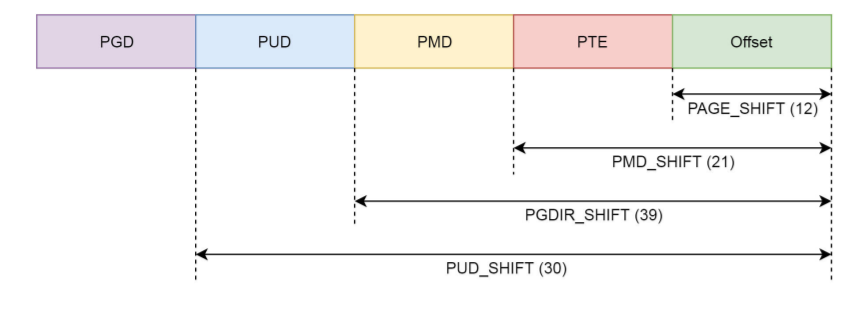
pgd_t for global page directory entries, pud_t is used for the upper page directory item, pmd_t for middle page directory entry, pte_t is used for direct page table entries.
Each process has an independent address space. In order for this process to complete the mapping independently, each process has an independent process page table, and the pgd at the top of this page table is stored in task_ Mm in struct_ In the pgd variable of struct.
When a process is newly created, fork will be called, and copy will be called for the memory part_ Mm, call DUP inside_ mm
/*
* Allocate a new mm structure and copy contents from the
* mm structure of the passed in task structure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
return mm;
}
Here, in addition to creating a new mm_struct, and as like as two peas in memcpy, it is necessary to call mm_. Init to initialize. Next, mm_init call mm_alloc_pgd, assign global page directory page, assign value to MM_ pdg member variable of struct
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
mm->pgd = pgd_alloc(mm);
return 0;
}
pgd_ In addition to allocating PDG, alloc also does a very important thing, that is, calling pgd_ctor.
static void pgd_ctor(struct mm_struct *mm, pgd_t *pgd)
{
/* If the pgd points to a shared pagetable level (either the
ptes in non-PAE, or shared PMD in PAE), then just copy the
references from swapper_pg_dir. */
if (CONFIG_PGTABLE_LEVELS == 2 ||
(CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) ||
CONFIG_PGTABLE_LEVELS >= 4) {
clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY,
swapper_pg_dir + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
}
......
}
pgd_ What did ctor do? Let's take a look at the comment inside, which copies the_ pg_ Dir reference, swapper_pg_dir is the top-level global page directory of the kernel page table.
The virtual address space of a process contains two parts: user state and kernel state. In order to map from virtual address space to physical pages, the page table is also divided into user address space page table and kernel page table, which is related to vmalloc above. In the kernel, the mapping depends on the kernel page table, where the kernel page table will copy a page table to the process.
So far, after a process fork s, it has a kernel page table and its own top-level pgd, but it has not been mapped for the user address space at all. This needs to wait for the moment when the process runs on a CPU and accesses memory.
When the process is called to run on a CPU, context is called_ Switch performs context switching. For memory switching, switch will be called_ mm_ irqs_ Off, load will be called here_ new_ mm_ cr3.
cr3 is a CPU register that points to the top pgd of the current process. If the CPU instruction wants to access the virtual memory of the process, it will automatically get the address of pgd in the physical memory from cr3, and then parse the address of the virtual memory into the physical memory according to the page table, so as to access the data on the real physical memory.
Here we should pay attention to two points.
- First, cr3 stores the top-level pgd of the current process, which is a hardware requirement. The address of pgd stored in physical memory in cr3 cannot be a virtual address. So load_new_mm_cr3 will be used inside__ pa, mm_ The member variable pdg in struct (mm_struct contains virtual addresses) can be loaded into cr3 only after it is changed into a physical address
- Second point:
- In the process of running, the user process accesses the data in the virtual memory and will be converted into the physical address by the page table pointed to in cr3 before accessing the data in the physical memory. This process is in the user state process, and the address conversion process does not need to enter the kernel state
- The page missing exception is triggered only when the virtual memory is accessed and the physical memory is not mapped and the page table has not been created. Enter the kernel and call do_page_fault, called until__ handle_mm_fault, this is the ground we saw when we analyzed this function above. Since you haven't created a page table before, you have to make up this lesson. So__ handle_mm_fault calls pud_alloc and pmd_alloc, to create the corresponding page directory entry, and finally call handle_pte_fault to create page table entries.
After a big circle, we finally connected all parts of the whole mechanism of the page table. But we haven't finished our story, and the physical memory hasn't been found yet. We have to continue to analyze the handle_ pte_ Implementation of fault.
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
......
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
......
}
In general, there are three situations.
If the PTE, that is, the page table entry, has never appeared, it is the newly mapped page. If it is an anonymous page, it is the first case. It should be mapped to a physical memory page, where do is called_ anonymous_ page. If it is mapped to a file, do is called_ Fault, this is the second case. If the PTE originally appeared, it means that the original page was in physical memory and later changed out to the hard disk. Now it should be changed back, and the call is do_swap_page
Let's look at the first case, do_anonymous_page.
- For anonymous page elements, we need to get through PTE first_ Alloc allocates a page table entry
- Then through alloc_zeroed_user_highpage_movable allocates a page. Then it calls alloc_pages_vma, and finally call__ alloc_pages_nodemask, which is the core function of the partner system, is specially used to allocate physical pages.
- do_anonymous_page next calls mk_pte, point the page table entry to the newly allocated physical page, set_pte_at will insert page table entries into the page table
static int do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
The second case maps to the file do_fault, eventually we will call__ do_fault.
static int __do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
......
ret = vma->vm_ops->fault(vmf);
......
return ret;
}
- Struct VM is called here_ operations_ struct vm_ Fault function of OPS. Remember when we used mmap to map files above, for ext4 file system, vm_ops points to ext4_file_vm_ops, that is, ext4 is called_ filemap_ fault.
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};
int ext4_filemap_fault(struct vm_fault *vmf)
{
struct inode *inode = file_inode(vmf->vma->vm_file);
......
err = filemap_fault(vmf);
......
return err;
}
- ext4_ filemap_ In fault, vm_file is the file mapped in mmap, and then we need to call filemap_fault:
- For file mapping, generally, the file will have a page table in physical memory as its cache, find_get_page is looking for that page
- If found, call do_async_mmap_readahead, pre read some data into memory
- If not, tune to no_cached_page
int filemap_fault(struct vm_fault *vmf)
{
int error;
struct file *file = vmf->vma->vm_file;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
pgoff_t offset = vmf->pgoff;
struct page *page;
int ret = 0;
......
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
} else if (!page) {
goto no_cached_page;
}
......
vmf->page = page;
return ret | VM_FAULT_LOCKED;
no_cached_page:
error = page_cache_read(file, offset, vmf->gfp_mask);
......
}
- If there is no cached page in physical memory, we call page_cache_read. Here, a cache page is allocated, added to the lru table, and then displayed in address_ Calling address_ in space space_ The readpage function of operations reads the contents of the file into memory.
static int page_cache_read(struct file *file, pgoff_t offset, gfp_t gfp_mask)
{
struct address_space *mapping = file->f_mapping;
struct page *page;
......
page = __page_cache_alloc(gfp_mask|__GFP_COLD);
......
ret = add_to_page_cache_lru(page, mapping, offset, gfp_mask & GFP_KERNEL);
......
ret = mapping->a_ops->readpage(file, page);
......
}
- struct address_space_operations defines the ext4 file system as follows. So, the readpage above actually calls ext4_readpage. Finally, ext4 is called_ read_ inline_ Page, which has some logic related to memory mapping
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
......
};
static int ext4_read_inline_page(struct inode *inode, struct page *page)
{
void *kaddr;
......
kaddr = kmap_atomic(page);
ret = ext4_read_inline_data(inode, kaddr, len, &iloc);
flush_dcache_page(page);
kunmap_atomic(kaddr);
......
}
- In ext4_ read_ inline_ In the page function, we need to call Kmap first_ Atomic maps the physical memory to the virtual address space of the kernel to get the address kaddr in the kernel.
- kmap_atomic is used for temporary kernel mapping. Originally, the physical memory is mapped to the user virtual address space, and there is no need to map one in the kernel. However, because we need to read data from the file and write to the physical page, we can't use the physical address. We can only use the virtual address, which requires a temporary mapping in the kernel.
- After temporary mapping, ext4_read_inline_data reads the file to this virtual address. After reading, we cancel the temporary mapping kunmap_atomic will do
Next, let's look at the third case, do_swap_page
- If the physical memory is not used for a long time, it must be replaced to the hard disk, that is, swap. But now this part of the data will be accessed again, and we have to find a way to read it into memory again
int do_swap_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
......
entry = pte_to_swp_entry(vmf->orig_pte);
......
page = lookup_swap_cache(entry);
if (!page) {
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE, vma,
vmf->address);
......
}
......
swapcache = page;
......
pte = mk_pte(page, vma->vm_page_prot);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
vmf->orig_pte = pte;
......
swap_free(entry);
......
}
- do_ swap_ The page function first looks for cached pages in the swap file.
- If not, swap in is called_ Readahead, read the swap file into memory to form a memory page, and use mk_pte generates page table entries. set_pte_at inserts a page table entry into the page table
- swap_free cleans up the swap file because the memory will be reloaded and the swap file is no longer needed
swapin_readahead will eventually call swap_readpage. Here, we see the familiar readpage function, that is, the process of reading ordinary files is the same as that of reading swap files. Kmap is also required_ Atomic makes temporary mapping.
int swap_readpage(struct page *page, bool do_poll)
{
struct bio *bio;
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
blk_qc_t qc;
struct block_device *bdev;
......
if (sis->flags & SWP_FILE) {
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
ret = mapping->a_ops->readpage(swap_file, page);
return ret;
}
......
}
Through the above complex process, the page missing exception in user status is handled. There are pages in physical memory, and the page table is mapped. Next, in the virtual memory space, the user program can smoothly access the data on the physical page through the page table mapping through the virtual address.
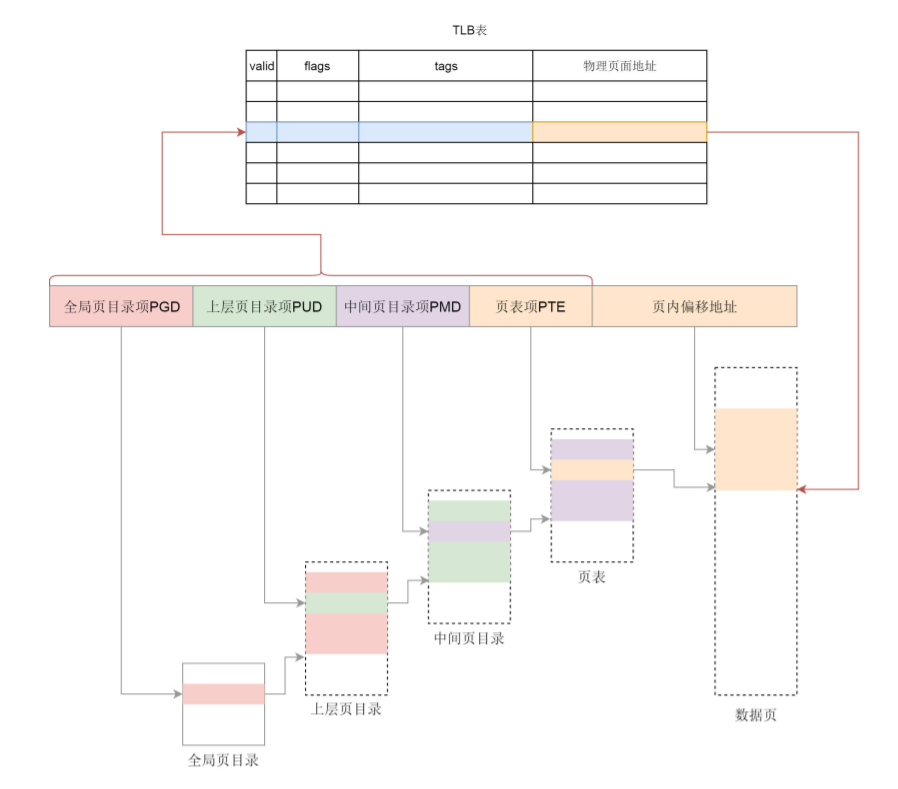
Page tables are generally large and can only be stored in memory. Each time the operating system accesses the memory, it has to toss two steps. First, it obtains the physical address by querying the page table, and then accesses the physical address to read instructions and data.
In order to improve the mapping speed, we introduce TLB (Translation Lookaside Buffer), which is a hardware device specially used for address mapping. It is no longer in memory and can store less data, but faster than memory. Therefore, we can see that the TLB is the cache of the page table, which stores the most likely page table items to be accessed at present, and its content is a copy of the page table.
With TLB, the process of address mapping is like that in the figure. We first look up the block table. There is a mapping relationship in the block table, and then directly convert it to a physical address. If the mapping relationship cannot be found in the TLB, the page table will be queried in memory.
summary
The memory mapping mechanism in user mode includes the following parts:
- User mode memory mapping function mmap can do anonymous mapping and file mapping
- The page table structure in user status is stored in mm_ In struct
- Accessing unmapped memory in user mode will cause page missing exceptions. Allocate physical page tables and supplement page tables. If it is an anonymous mapping, allocate physical memory; If it is swap, read in the swap file; If it is a file mapping, the file is read in.,