brief introduction
Awk, grep and sed are the three sharp tools of linux operating text, collectively known as the three swordsmen of text. They are also one of the linux commands that must be mastered. The functions of the three are text processing, but the focus is different. Awk is the most powerful but also the most complex. Grep is more suitable for simply finding or matching text, sed is more suitable for editing matched text, awk is more suitable for formatting text and processing text in more complex formats.
1,grep
grep command is a powerful text search tool in Linux system. It can use regular expressions to search text and print the matching lines (the matching lines are marked in red). grep's full name is Global Regular Expression Print, which indicates the global regular expression version. Its permission is for all users.
grep works by searching for string templates in one or more files. If the template includes spaces, it must be referenced, and all strings after the template are regarded as file names. The search results are sent to the standard output without affecting the content of the original file.
Grep can be used in shell scripts because grep describes the search status by returning a status value. If the template search is successful, it returns 0, if the search is unsuccessful, it returns 1, and if the searched file does not exist, it returns 2. We can use these return values to do some automatic text processing.
egrep = grep -E: extended regular expression (except * * <, >, \ b * * other regular expressions can be removed \)
grep use
Specific characters used for filtering / searching. Regular expressions can be used. They can be used with a variety of commands, which is very flexible.
Command format: grep [option] pattern file
Detailed explanation of command parameters
- -A<Display rows>: In addition to the column that conforms to the template style, the content after the row is displayed. - -B<Display rows>: In addition to the line that matches the style, the content before the line is displayed. - -C<Display rows>: In addition to the line that matches the style, the contents before and after the line are displayed.
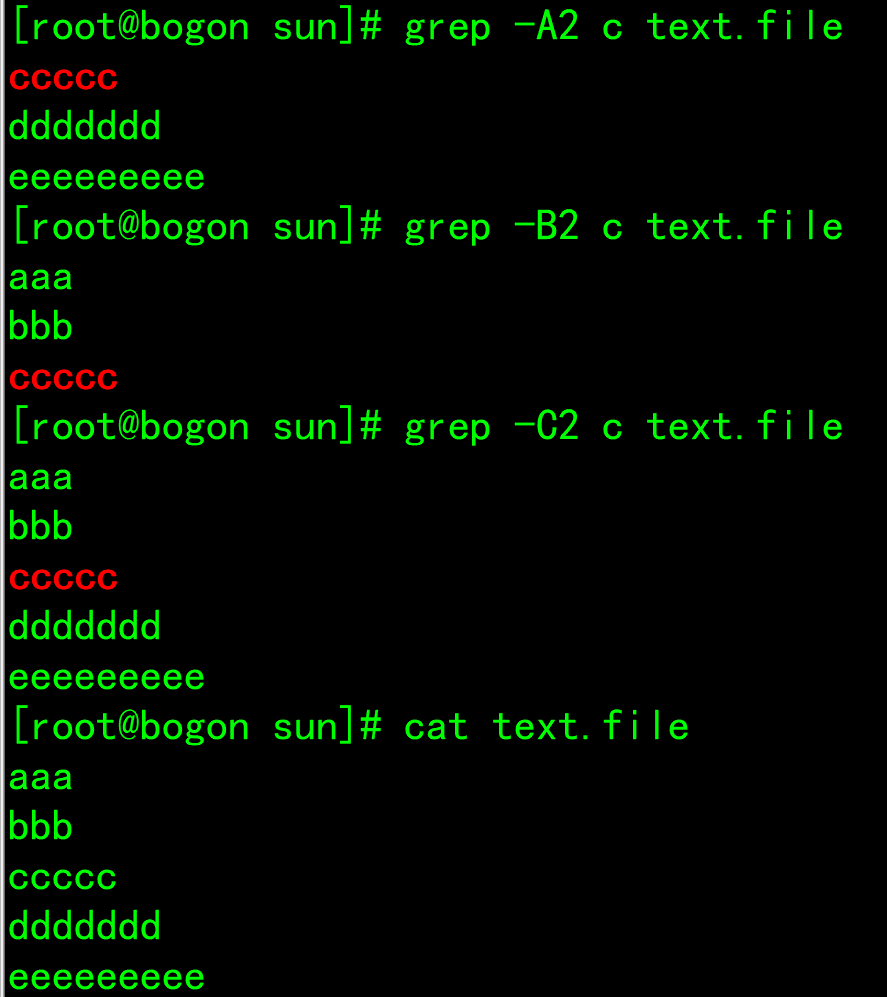
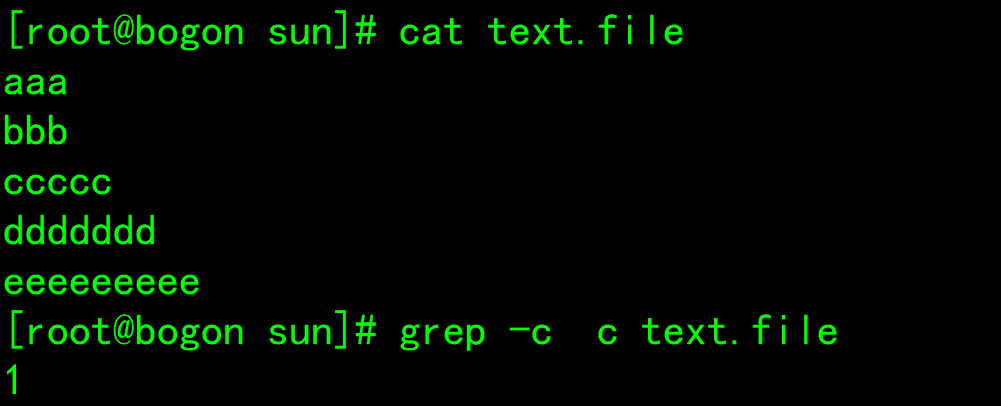
- -c: Count the number of matched rows
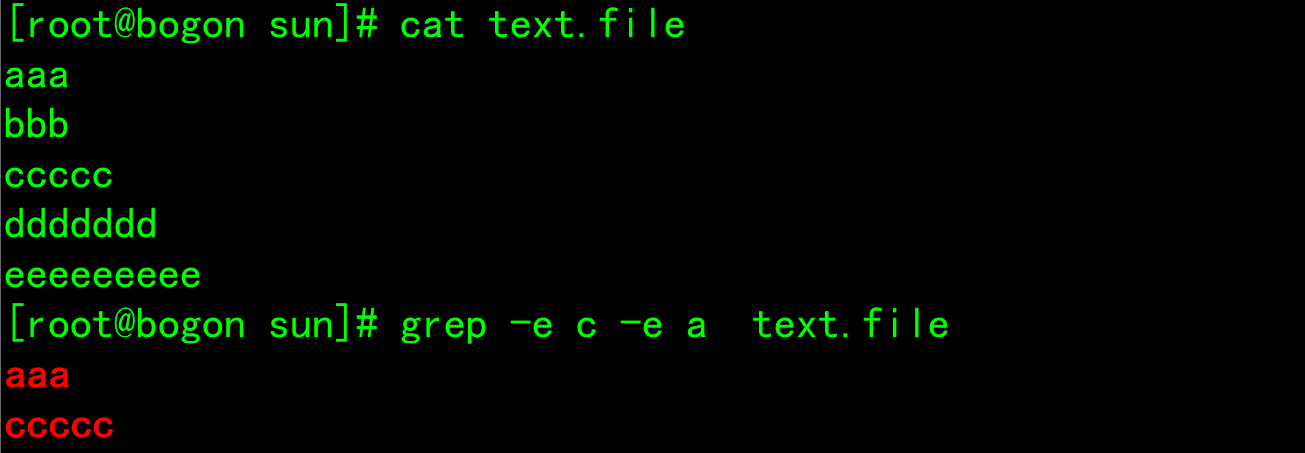
- -e : Implement logic between multiple options or relationship
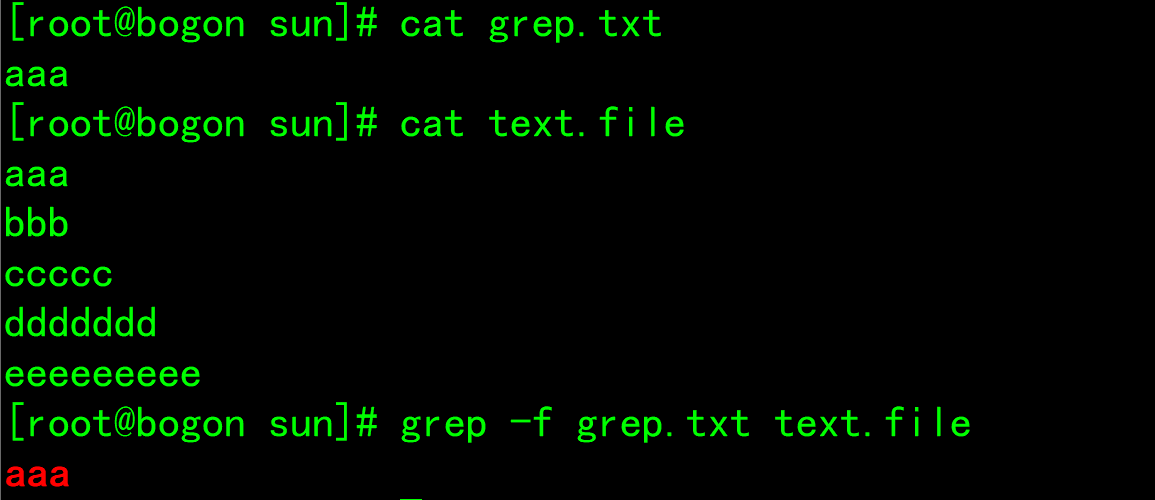
- -f FILE: from FILE obtain PATTERN matching
- -i --ignore-case #Ignore differences in case of characters.
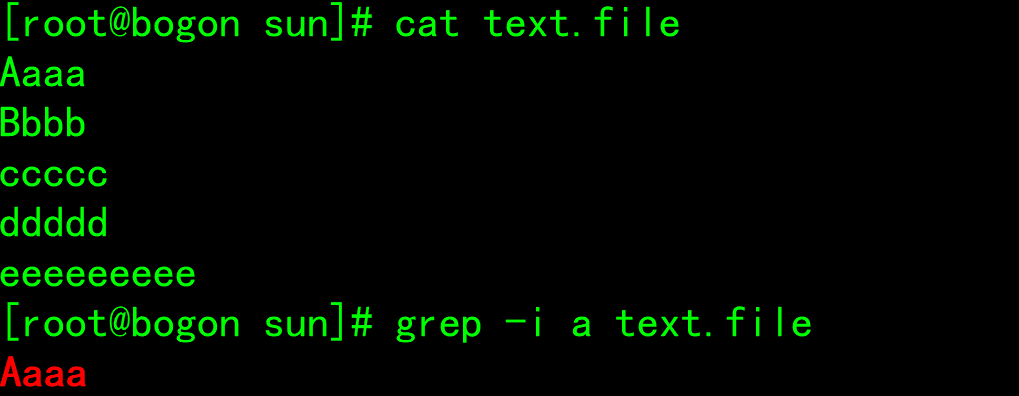
- -n: Show matching line numbers
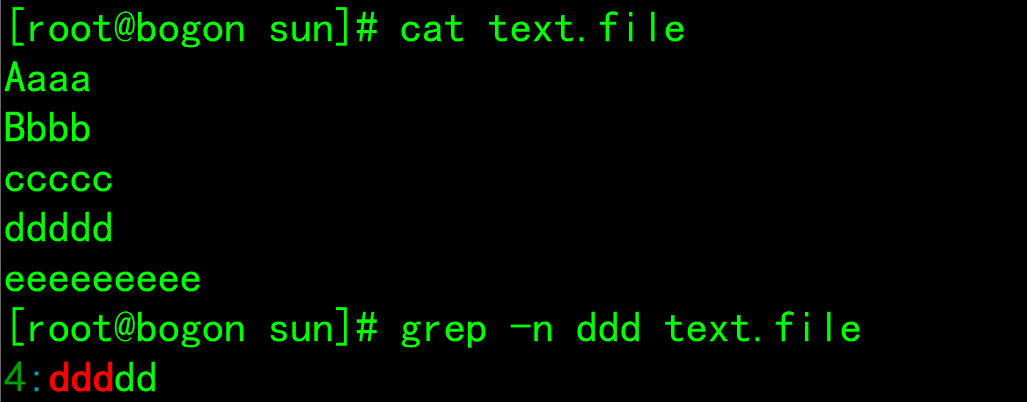
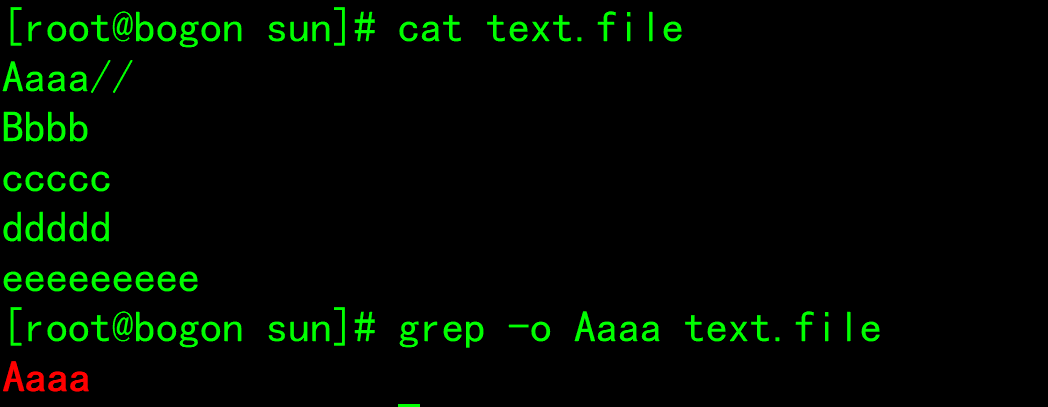
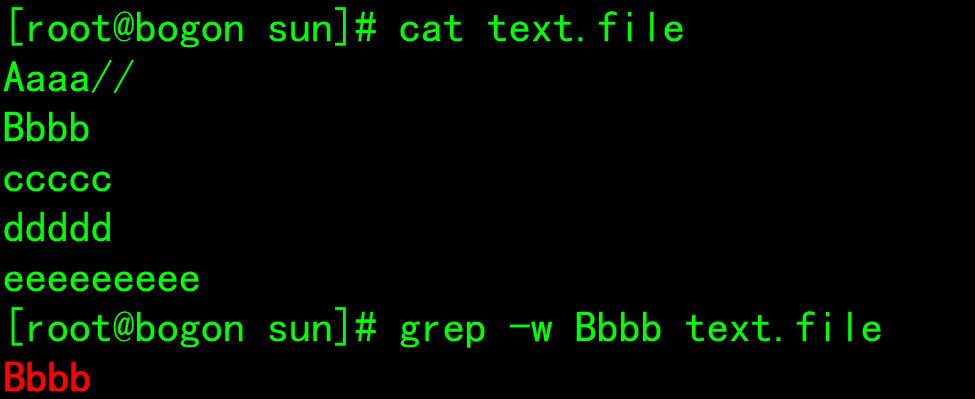
-o: Show only matching strings
-q: Silent mode, no information output Nothing is output to the screen

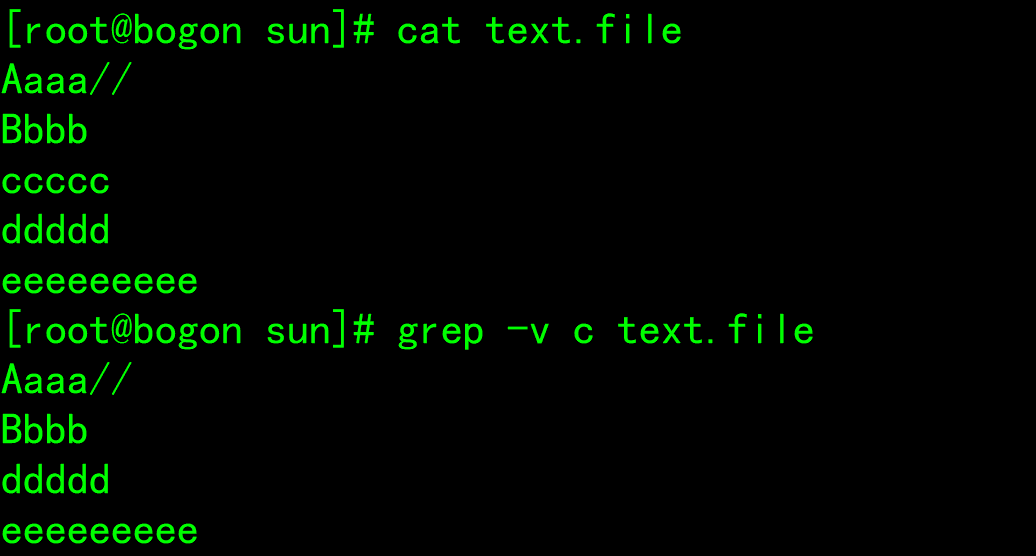
-v: Display not pattern The matched row is equivalent to[^] Reverse matching
-w : Match entire word It means that you must write exactly the words you need to match, otherwise you can't match the skin
Regular expression:
Match character
- . Match any single character, cannot match blank line
- [] Matches any single character within the specified range
- [^] Reverse
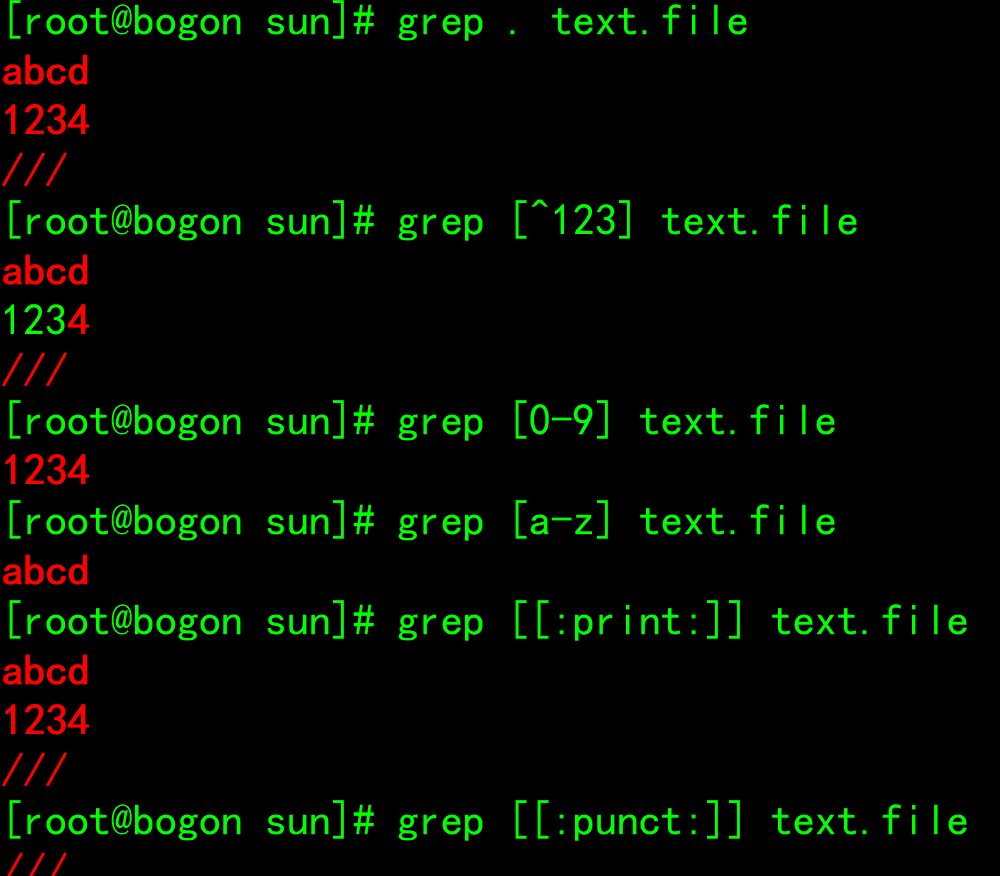
- [:alnum:] or [0-9a-zA-Z]
- [:alpha:] or [a-zA-Z]
- [:upper:] or [A-Z]
- [:lower:] or [a-z]
- [:blank:] White space characters (spaces and tabs)
- [:space:] Horizontal and vertical white space characters (ratio[:blank:](wide range)
- [:cntrl:] Non printable control characters (backspace, delete, alarm)...)
- [:digit:] Decimal digit or[0-9]
- [:xdigit:]Hexadecimal digit
- [:graph:] Printable non white space characters
- [:print:] Printable character
- [:punct:] punctuation
Matching times
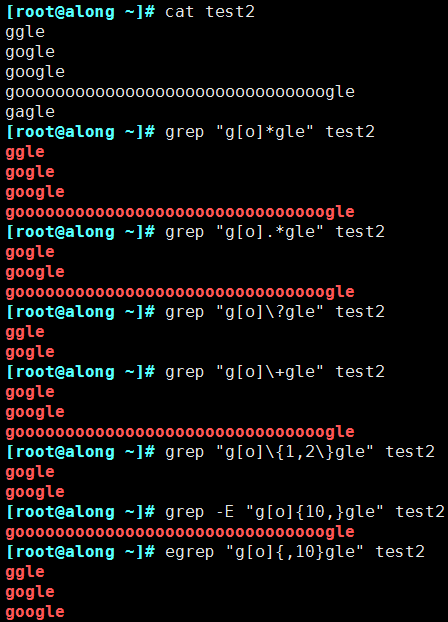
- * Match the previous characters any time, including 0 times. Greedy mode: match as long as possible
- .\ Any character of any preceding length, excluding 0 times
- \? Matches the character before it 0 or 1 times
- \+Match the character before it at least once
- \{n\} Match previous characters n second
- \{m,n\} Match previous characters at least m Times, at most n second
- \{,n\} Match previous characters at most n second
- \{n,\} Match previous characters at least n second
Position anchor: locate the position where it appears
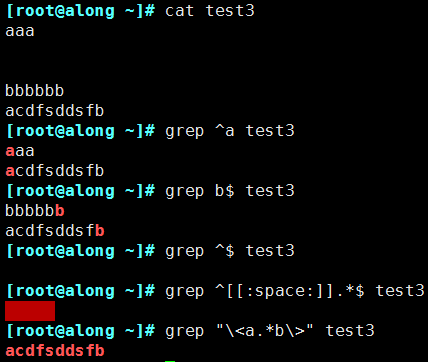
- ^ Row head anchor for the leftmost side of the pattern
- $ End of line anchor for the rightmost side of the pattern
- ^PATTERN$,For pattern matching entire line
- ^$ Blank line
- ^[[:space:]].*$ Blank line
- \< or \b Initial anchor for the left side of the word pattern
- \> or \b Ending anchor; For the right side of word mode
- \<PATTERN\>
demonstration:
sed
Sed is a stream editor that processes one line at a time. During processing, the currently processed lines are stored in a temporary buffer called "pattern space", and then the contents in the buffer are processed with sed command. After processing, the contents of the buffer are sent to the screen. Then read the downlink and execute the next cycle. If there is no special command such as'D ', the mode space will be cleared between two loops, but the reserved space will not be cleared. This is repeated until the end of the file. The contents of the file do not change unless you use redirection to store the output or - i.
Function: it is mainly used to automatically edit one or more files to simplify the repeated operation of files.
Command format: sed [options] [Address delimitation]/command file(s)
Detailed explanation of command parameters
Common options
--n: The mode space content is not output to the screen, that is, it is not automatically printed, and only the matched lines are printed --e: For multi-point editing, there can be multiple points for each line Script --f: hold Script Write to the file and execute sed Time-f Specify the file path, if more than one Script,Line feed. --r: Support extended regular expressions --i: Write the processing results directly to the file --i.bak: Back up a copy before writing the processing results to the file.
demonstration:

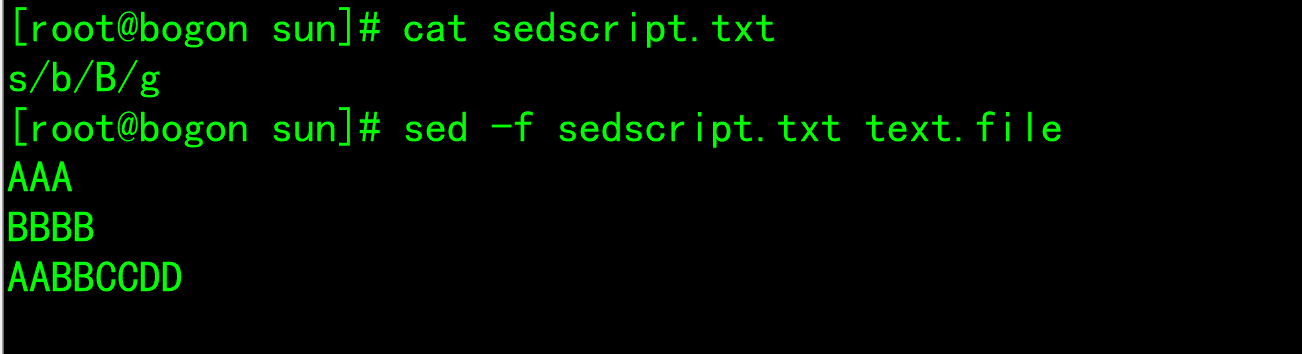
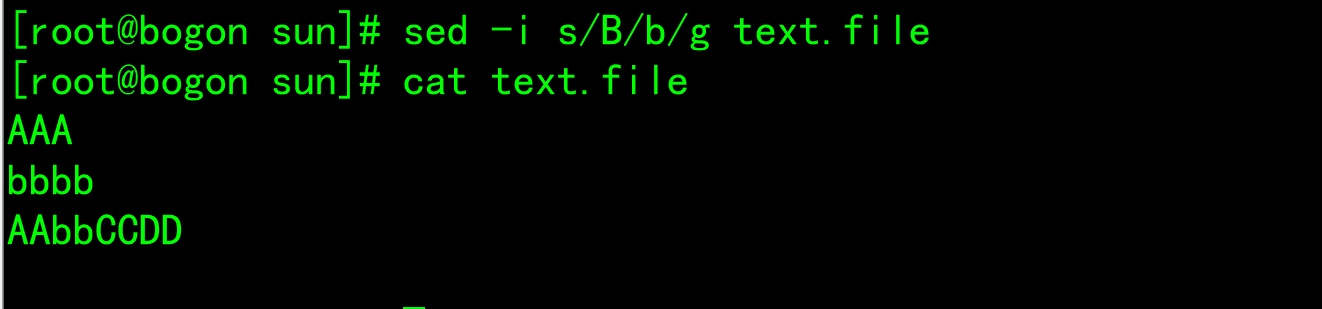
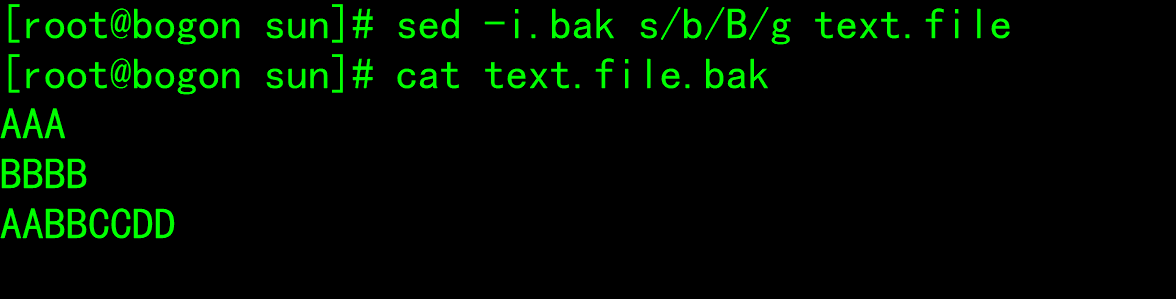
Address delimitation
- Do not give address: process the full text - Single address: - \#: specified row - /pattern/: Every line that can be matched by the pattern here - Address range: - \#,# - \#,+# - /pat1/,/pat2/ - \#,/pat1/ - ~: Stepping - sed -n '1~2s'Print only odd lines (1)~2 From line 1, add 2 lines at a time) - sed -n '2~2s'Print only even lines
demonstration:
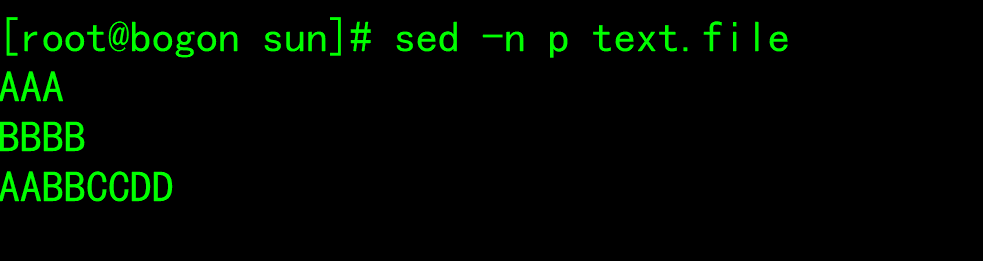
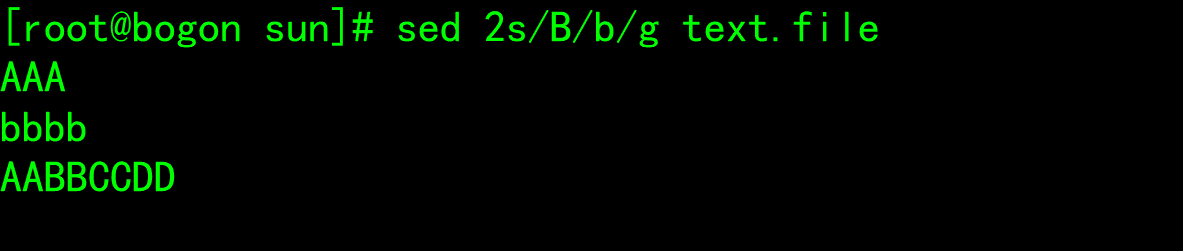
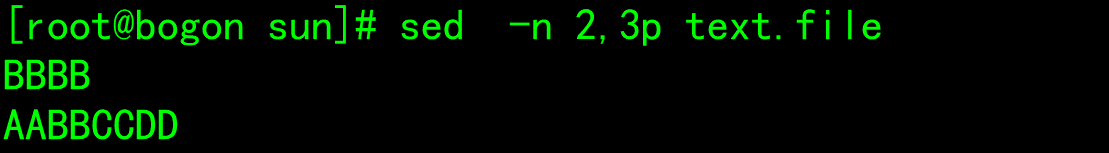


Edit command
- d: Delete rows that match the pattern space and immediately enable the next cycle - p: Print the current mode space content and append it to the default output - a: Append text after the specified line to support the use of\n Implement multi line append - i: Insert text in front of the line and support the use of\n Implement multi line append - c: Replace single line or multiple lines of text, and support the use of\n Implement multi line append - w: Save pattern matching lines to the specified file - r: After reading the text of the specified file to the matching line in the pattern space - =: Print line numbers for lines in pattern space - !: Inverse processing of matching rows in pattern space - s/// Find and replace. Other separators are supported, such as: s@@@ s### - plus g Indicates intra line global replacement; - - When replacing, you can add a command to realize case conversion - \l: Converts the next character to lowercase. - \L: hold replacement Convert letters to lowercase until\U or\E appear. - \u: Convert the next character to uppercase. - \U: hold replacement Convert letters to uppercase until\L or\E appear. - \E: Stop with\L or\U Start case conversion
demonstration: [root@along ~]# cat demo aaa bbbb AABBCCDD [root@along ~]# sed "2d" demo #Delete line 2 aaa AABBCCDD [root@along ~]# sed -n "2p" demo #Print line 2 bbbb [root@along ~]# sed "2a123" demo #Add 123 after line 2 aaa bbbb 123 AABBCCDD [root@along ~]# sed "1i123" demo #Add 123 Before line 1 123 aaa bbbb AABBCCDD [root@along ~]# sed "3c123\n456" demo #Replace line 3 aaa bbbb 123 456 [root@along ~]# sed -n "3w/root/demo3" demo #Save the contents of line 3 to the demo3 file [root@along ~]# cat demo3 AABBCCDD [root@along ~]# sed "1r/root/demo3" demo #Read the contents of demo3 to line 1 aaa AABBCCDD bbbb AABBCCDD [root@along ~]# sed -n "=" demo #=Print line number 1 2 3 [root@along ~]# sed -n '2!p' demo #Print except line 2 aaa AABBCCDD [root@along ~]# sed 's@[a-z]@\u&@g' demo #Replace lowercase letters with uppercase letters for the full text AAA BBBB AABBCCDD
3.4 sed advanced editing commands
(1) Format
- h: Overwrite the contents of the pattern space into the holding space
- H: Append the contents of the mode space to the holding space
- g: Take the data out of the holding space and overwrite it into the mode space
- G: Take out the contents from the holding space and append them to the mode space
- x: Swap the content in the pattern space with the content in the hold space
- n: Read the next row of the matched row and overwrite it into the pattern space
- N: The next row of the read matched row is appended to the pattern space
- d: Delete rows in schema space
- D: Delete the contents from the beginning of the current mode space to \ n (no longer transmitted to standard output), abandon the subsequent commands, but re execute sed for the remaining mode space
(2) One case + schematic demonstration
① Case: output text content in reverse order
[root@along ~]# cat num.txt One Two Three [root@along ~]# sed '1!G;h;$!d' num.txt Three Two One 1!G The first line is not executed G Command, starting from the second line $!d The last line is not deleted
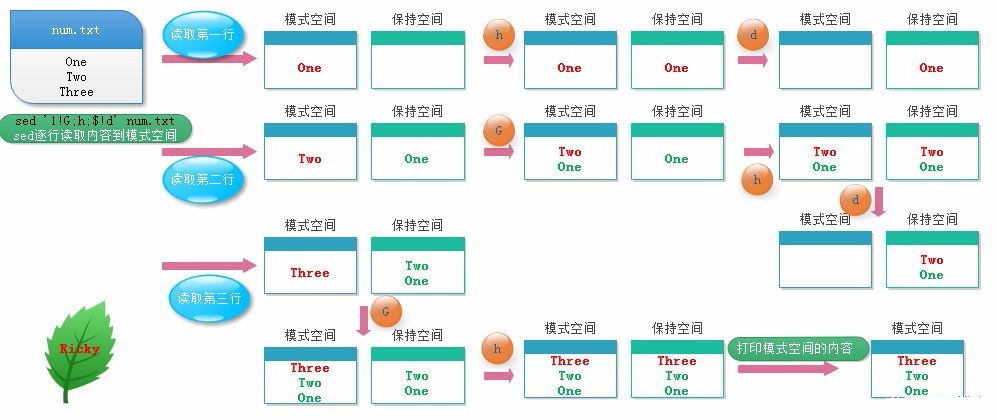
③ Summarize the relationship between mode space and maintain space:
The holding space is a buffer for temporarily storing data in the mode space to assist in data processing in the mode space
(3) Demonstration
① Show even rows
[root@along ~]# seq 9 |sed -n 'n;p' 2 4 6 8
② Reverse order display
[root@along ~]# seq 9 |sed '1!G;h;$!d' 9 8 7 6 5 4 3 2 1
③ Show odd rows
[root@along ~]# seq 9 |sed 'H;n;d' 1 3 5 7 9
④ Show last line
[root@along ~]# seq 9| sed 'N;D' 9
⑤ Add a blank line between each line
[root@along ~]# seq 9 |sed 'G' 1 2 3 4 5 6 7 8 9 ---
⑥ Replace each line with a blank line
[root@along ~]# seq 9 |sed "g" ---
⑦ Make sure there is a blank line below each line
[root@along ~]# seq 9 |sed '/^$/d;G' 1 2 3 4 5 6 7 8 9
awk
Awk is a programming language used to process text and data under linux/unix. The data can come from standard input (stdin), one or more files, or the output of other commands. It supports advanced functions such as user-defined functions and dynamic regular expressions. It is a powerful programming tool under linux/unix. It is used on the command line, but more as a script. Awk has many built-in functions, such as arrays and functions, which is the same as C language. Flexibility is the biggest advantage of awk.
awk is not only a tool software, but also a programming language. However, this article only introduces its command-line usage, which should be sufficient for most occasions.
Command syntax demonstration
Common command options:
Common command options: - -F fs: fs Specify the input separator, fs It can be a string or a regular expression, such as-F: - -v var=value: Assign a user-defined variable and pass the external variable to awk - -f scripfile: Read from script file awk command Built in variables: - FS : Enter the field separator, which defaults to blank characters - OFS : The output field separator is blank by default - RS : Enter the record separator and specify the line feed character when entering. The original line feed character is still valid - ORS : The output record separator replaces the newline character with the specified symbol - NF : Number of fields, total number of fields, $NF Reference the last column, $(NF-1)Reference the penultimate column - NR : The line number can be followed by multiple files, and the line number of the second file continues to start from the last line number of the first file - FNR : Each file is counted separately, Line number followed by a file and NR Like multiple files, the second file line starts with 1 - FILENAME : Current file name - ARGC : Number of command line parameters - ARGV : Array, which saves the parameters given by the command line. View the parameters
[root@along ~]# cat awkdemo
hello:world
linux:redhat:lalala:hahaha
along:love:youou
[root@along ~]# awk -v FS=':' '{print $1,$2}' awkdemo #FS specifies the input separator
hello world
linux redhat
along love
[root@along ~]# awk -v FS=':' -v OFS='---' '{print $1,$2}' awkdemo #OFS specifies the output separator
hello---world
linux---redhat
along---love
[root@along ~]# awk -v RS=':' '{print $1,$2}' awkdemo
hello
world linux
redhat
lalala
hahaha along
love
you
[root@along ~]# awk -v FS=':' -v ORS='---' '{print $1,$2}' awkdemo
hello world---linux redhat---along love---
[root@along ~]# awk -F: '{print NF}' awkdemo
2
4
3
[root@along ~]# awk -F: '{print $(NF-1)}' awkdemo #Display the penultimate column
hello
lalala
love
[root@along ~]# awk '{print NR}' awkdemo awkdemo1
1
2
3
4
5
[root@along ~]# awk END'{print NR}' awkdemo awkdemo1
5
[root@along ~]# awk '{print FNR}' awkdemo awkdemo1
1
2
3
1
2
[root@along ~]# awk '{print FILENAME}' awkdemo
awkdemo
awkdemo
awkdemo
[root@along ~]# awk 'BEGIN {print ARGC}' awkdemo awkdemo1
3
[root@along ~]# awk 'BEGIN {print ARGV[0]}' awkdemo awkdemo1
awk
[root@along ~]# awk 'BEGIN {print ARGV[1]}' awkdemo awkdemo1
awkdemo
[root@along ~]# awk 'BEGIN {print ARGV[2]}' awkdemo awkdemo1
awkdemo1