regular expression
preface
The reason why regular expressions are introduced is that the grep command will use regular expressions, so they are explained at the beginning
1. What is a regular expression?
A regular expression is a way of describing a collection of strings. The representation of regular expressions is the combination of some special symbols, and each symbol represents some specific meaning. Matching combination defines a set of rules and methods, whose main function is to match qualified lines from a large number of text.
2. Usage scenarios of regular expressions
In Linux, the main use scenario of regular expressions is the three swordsmen of text processing. grep,sed,awk . In addition, the vi instruction also supports regular expressions.
3. Regular expression character representation
Regular expressions can be divided into basic regular expressions and extended regular expressions. The main differences are:
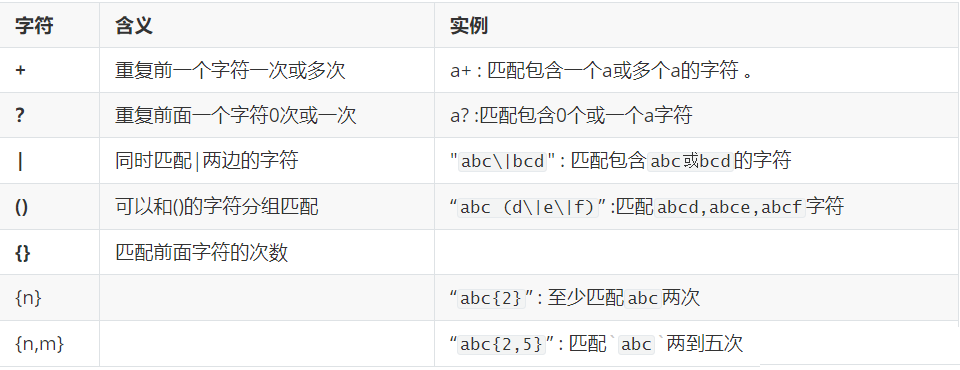
- Basic regular expressions only recognize metacharacters, which mainly include: ^ $ [] *, see the table below for specific meanings
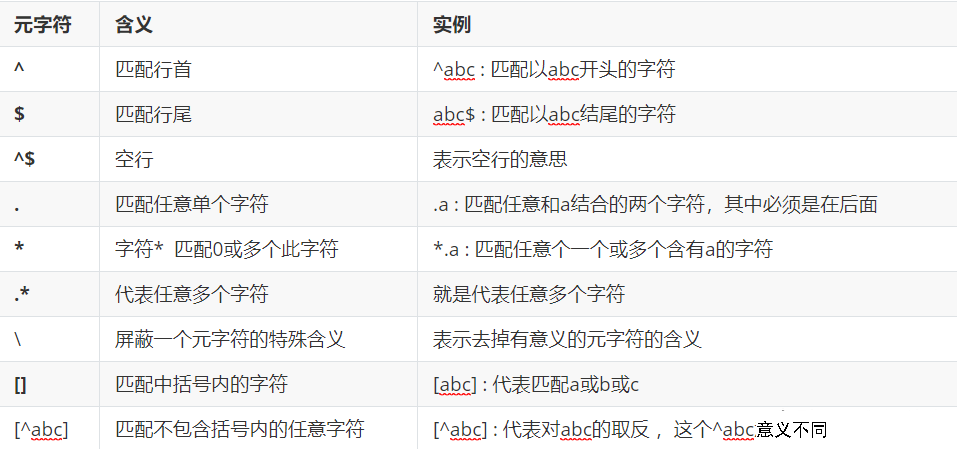
- The extended regular expression adds () {}? +| Equal symbol
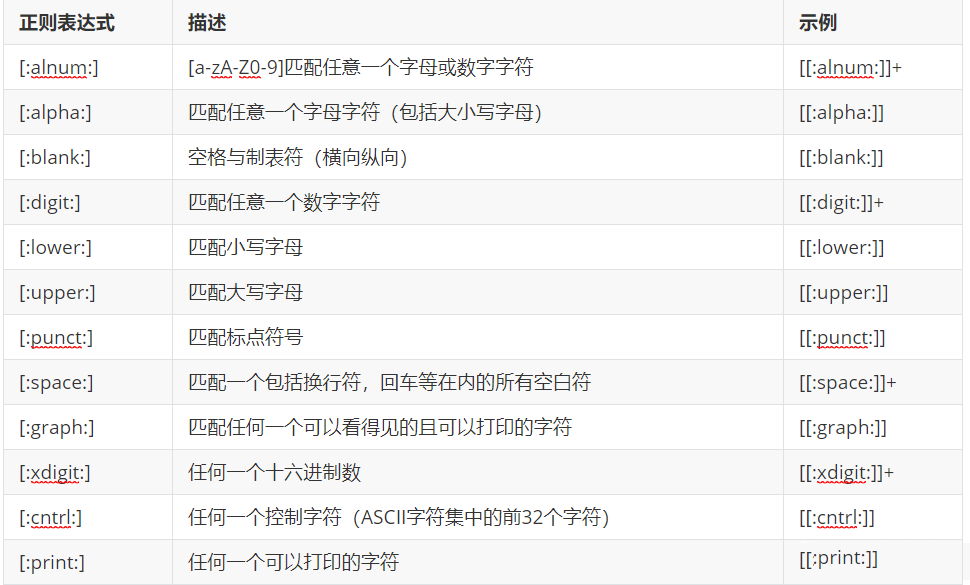
The following are the meanings of each metacharacter
Characters supported in extended regular
predefined character classes
4. Differences between them
We mentioned above that regularity includes basic regularity and extended regularity, but what is the difference between them? Where is it used? Next, we will mainly explain the differences among the three Linux swordsmen (grep,sed,awk)
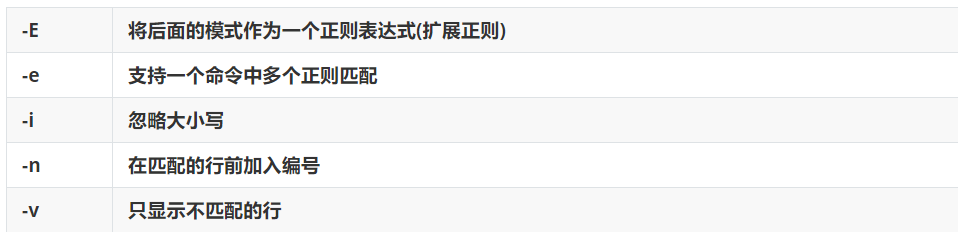
- Grep: in grep, if you only use the grep command, you can use the regular or predefined character class of the original character. If you want to use the characters contained in the extended regular, you must add the parameter - E after grep.
grep command
effect:
- Used to print lines that match a given pattern
Syntax:
grep [options] PATTERN [FILE...]
grep [options] [-e PATTERN | -f FILE] [FILE...]
explain:
The grep instruction is used to search the contents of the FILE file of the given PATTERN (PATTERN). If the FILE content of the PATTERN is found from the FILE content, grep will display the matching line. If you do not specify any FILE, or if you give a FILE name of -, grep reads from standard input.
Alternatively, two variants can be used egrep and fgrep . Egrep And grep -E Same. Fgrep And grep -F Same.
options: options
Note: the following NUM It represents a number and the number of rows -A NUM perhaps --after-context=NUM In addition to the line that meets the criteria, and after the line is displayed NUM Content of line -a perhaps--text Treat a binary file as a text file; It and--binary-files=text Options are equivalent. -B NUM perhaps--before-context=NUM In addition to the line that meets the criteria, and before the line is displayed NUM The contents of the line. -C NUM perhaps--context=NUM In addition to the line that meets the criteria, the lines before and after the line are displayed NUM Content of line -b perhaps--byte-offset The byte offset of the current line in the input file is printed in front of each line of the output at the same time. --colour[=WHEN] perhaps --color[=WHEN] In the matched lines, the matched string is shaded. WHEN Can be never,always,or auto. -c perhaps--count Calculate the number of eligible rows -d ACTION perhaps --directories=ACTION If the input file is a directory, use the action ACTION To deal with it. By default, actions ACTION yes read,This means that the directory will be read as an ordinary file. If action ACTION yes skip ,The directory will be skipped without processing. If action ACTION yes recurse,grep All files in each directory will be read recursively. Doing so and-r Options are equivalent. -E perhaps --extended-regexp take E The latter pattern is used as a regular expression. -e PATTERN perhaps --regexp=PATTERN use PATTERN As a pattern for finding file contents(Support regular),However, multiple commands can be used in a single command-e option -F perhaps --fixed-strings Will mode PATTERN Treat the list as a fixed string with a new line (newlines) Separate, just match one of them. -f FILE perhaps--file=FILE From file FILE Get the mode in, one for each line. The empty file contains 0 patterns, so it doesn't match anything. -G perhaps--basic-regexp Will mode PATTERN As a basic regular expression, this is the default. -H perhaps --with-filename Print the file name for each match. -h perhaps --no-filename When searching for multiple files, it is forbidden to prefix the output with the file name. -i perhaps --ignore-case Ignore case differences -L perhaps --files-without-match The matching file name cannot be found in the print file content -l perhaps --files-with-matches Print out the file name after finding a match in the file content -m NUM perhaps --max-count=NUM Find in NUM After a matching line, the file is no longer read. -n perhaps --line-number Precede each line of output with its line number in the file it is in. -o perhaps --only-matching Show only matching rows with PATTERN Matching parts. --label=LABEL Treat matching output from standard input as if it were from an input file LABEL Value of --line-buffering Using line buffering, it can be a performance penality. -q, --quiet, --silent No information is displayed. -R, -r, --recursive Recursively read all files in each directory. Doing so and -d recurse Options are equivalent. --include=PATTERN Just search for matches PATTERN Search recursively in the directory when searching for files. --exclude=PATTERN Search recursively in the directory, but skip matching PATTERN File. -s perhaps --no-messages Disable the output of error messages about files that do not exist or are unreadable. -u perhaps --unix-byte-offsets report Unix Byte offset of style. This switch makes grep When reporting byte offsets, treat files as Unix Style of text file, that is to say, will CR Character removal. This will be produced with in one machine Unix Run on host grep Exactly the same result. Unless used at the same time-b Option, otherwise this option is invalid. This option is in MS-DOS and MS-Windows Invalid in system other than. -V perhaps --version Print to standard error output grep Version number of the. -v perhaps invert-match Displays all rows that do not contain matching patterns. -w perhaps --word-regexp Select only rows that contain matches that make up a complete word. The judgment method is that the matching substring must be the beginning of a line, or in an impossible -x perhaps --line-regexp Exactly. -Z, --null Show all file contents,Different fonts are marked by color
a key
Although we can see from the above that there are many options in grep, most of them are unavailable in work. Let's focus here.
Common parameters
example
The file info is used and filtered through grep. The file contents of info are as follows:
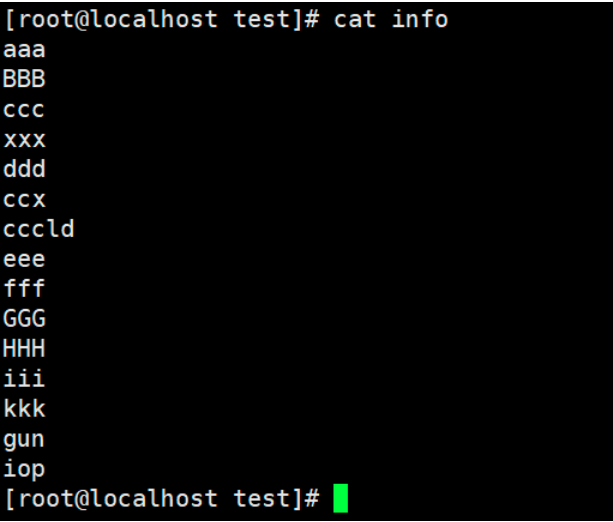
1. Find the contents of ccc in the file info and print the number of lines
grep -n "ccc" info

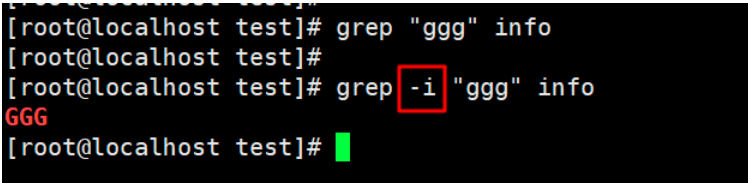
2. Find and print the characters that contain ggg and ignore case in the file info,
grep -i "ggg" info
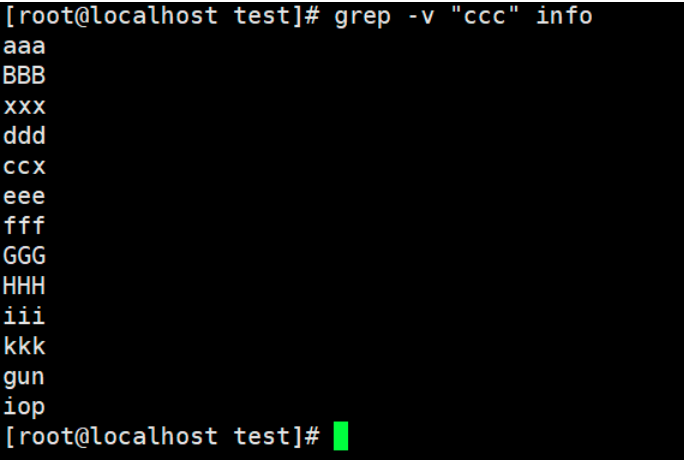
3. Filter out rows containing ccc
grep -v "ccc" info
4. Find the row containing DDD, EEE and FFF (Note: the following matching uses regular)
grep -E "ddd|eee|fff" info
5. Find lines starting with c
grep ^c info
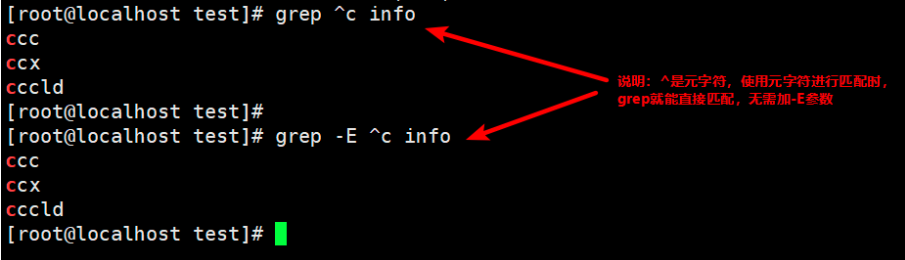
6. Find lines that begin and end with ccx
grep ^ccx$ info
7. Find a line that can be any character before the d character
grep .d info
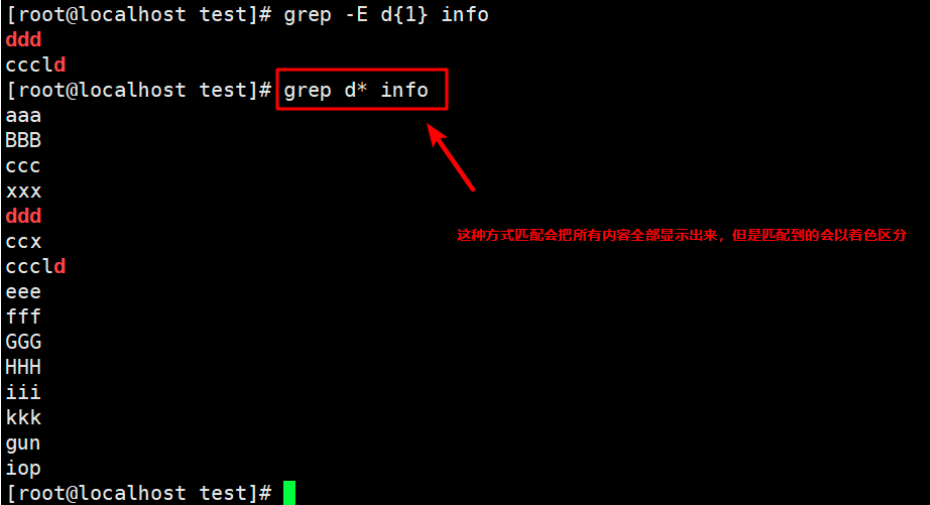
8. Find a line that contains one or more d characters
grep -E d{1} info
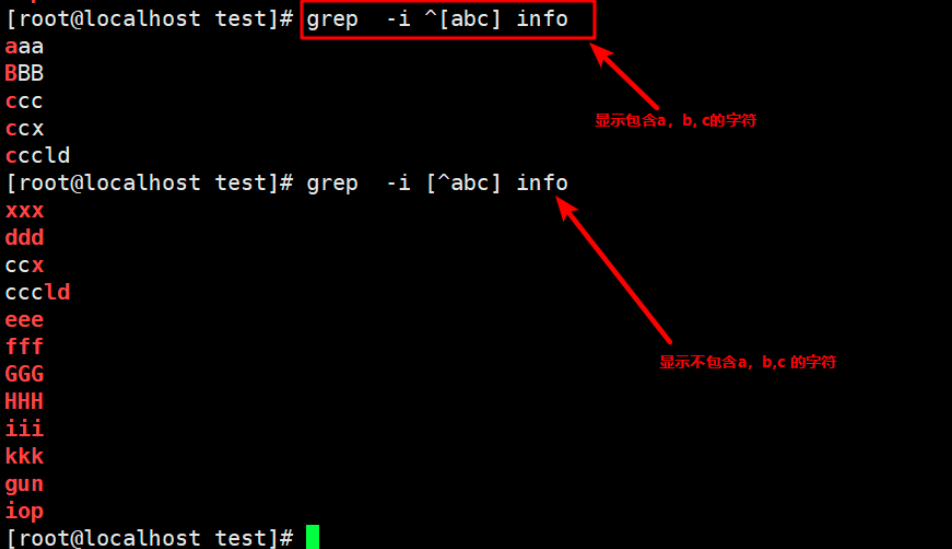
9. Display lines containing characters a, B and C; Displays lines that do not contain a,b,c characters
contain: grep -i ^[abc] info Excluding: grep -i [^abc] info (Yes, all characters are excluded a or b or c)
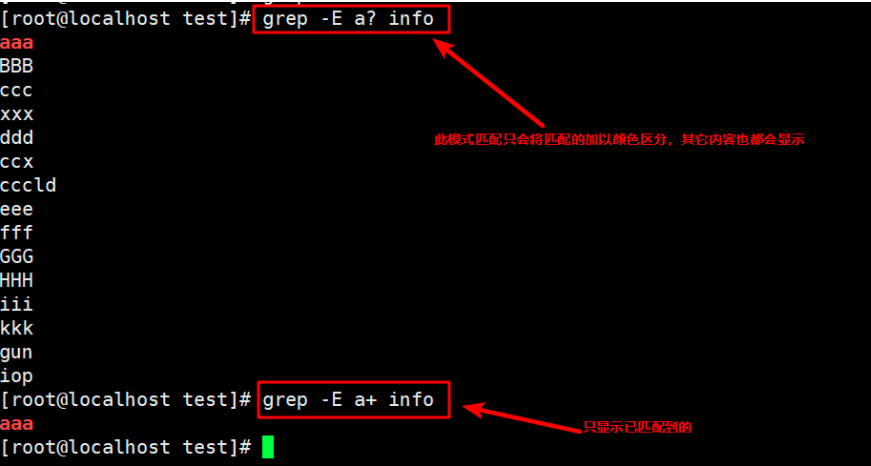
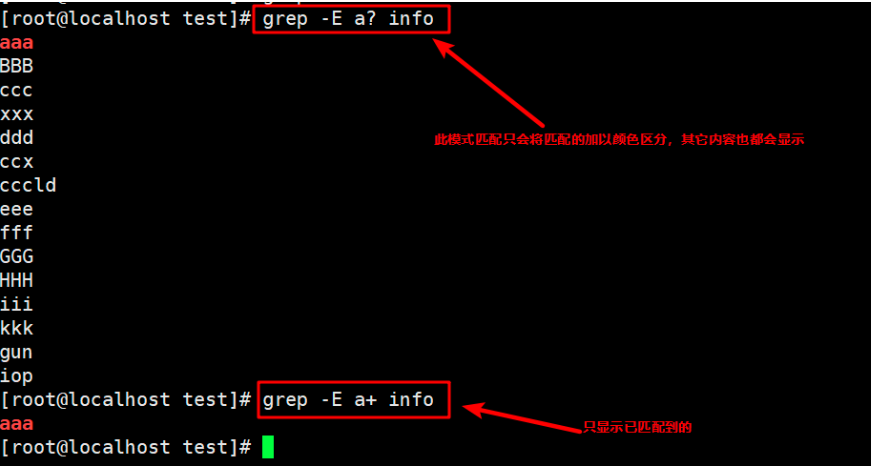
10. Display one or more lines containing the a character
grep -E a+ info
11. Find a line that starts with cc and contains c,x,ld characters
grep -E "cc(c|x|ld)" info
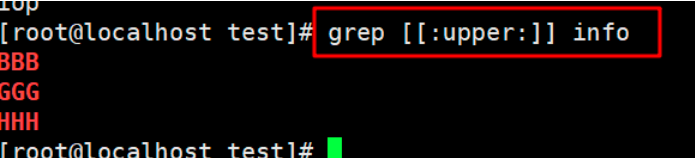
12. Find all uppercase characters in the file
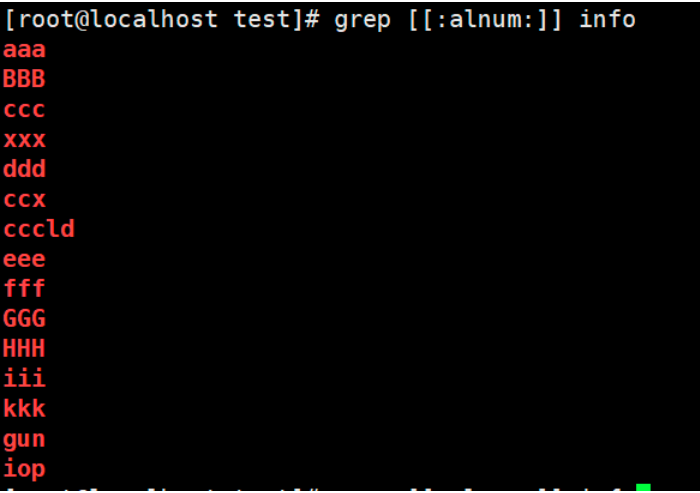
grep [[:upper:]] info
13. Match any alphanumeric character
grep [[:alnum:]] info