This part is about Linux kernel timer.
Basic concepts
- System timer: a programmable hardware chip that can generate interrupts at a fixed frequency.
- Timer interrupt: the interrupt generated by the fixed time cycle of the system timer, in which the interrupt handler is responsible for updating the system time and executing periodic tasks.
- Dynamic timer: a tool used to delay the execution of a program. The kernel can dynamically create and destroy dynamic timers.
- tick rate: the frequency of the system timer. The system timer automatically triggers the clock interrupt at a certain frequency (also known as hitting or popping). This frequency can be set by programming.
- Tick: the pre programmed tick rate is known to the kernel, so the kernel knows the interval between two consecutive clock interrupts. This time is called the beat. Beat = 1 / beat rate. It is often used to calculate wall time and system running time.
- Wall clock time: actual time, which is very important for user space applications. Represents the elapsed time (hours) of the system clock from the beginning to the end of the process, including the time of process blocking. The number of ticks per second (beat rate) can be obtained through sysconf(_SC_CLK_TCK).
- System running time: the time elapsed since the start of the system, which is very useful for user space and kernel. Wall time = blocking time + ready time + running time, running time = user CPU actual + system CPU time.
The system timer interrupts the periodically executed tasks:
- Update system time.
- Update actual time.
- On the smp system, the running queues on each processor in the scheduler are balanced. If the load of running queues is unbalanced, try to balance them.
- Check whether the current process has exhausted its own time slice. If exhausted, reschedule.
- Dynamic timer for running timeout.
- Update statistics on resource consumption and processor time.
[======]
Beat rate: HZ
The system timer (beat rate) is defined by static preprocessing, and the hardware is set according to Hz value when the system is started. The Hz value depends on the architecture. For example, in i386 architecture, the Hz value is 1000 (Hz), representing 1000 beats per second
#include <asm/param.h> #define HZ 1000 / * core clock frequency*/
Other architecture beat rates:

Advantages and disadvantages of using high frequency for system timer
advantage:
- The kernel timer can run with higher frequency and accuracy.
- System calls that rely on timing values, such as select and poll, can run with higher accuracy.
- There will be fine resolution for measurements such as resource consumption and system running time.
- Improve the accuracy of process preemption.
Disadvantages:
- The higher the beat rate, the higher the interrupt frequency of the system clock, which means that the heavier the system burden, that is, the more processor time occupied by the interrupt processing program, which reduces the time for processing other work.
[======]
jiffies
The global variable jiffies is used to record the total number of beats generated since the system was started. When starting, the initial value is 0; After that, every time the clock interrupt handler makes jiffies+1.
jiffies definition:
#include <linux/jiffies.h> extern unsigned long volatile jiffies;
jiffies internal representation
On the 32bit architecture, jiffies is 32bit. If the clock frequency is 100Hz, it will overflow after 497 days; Frequency 1000Hz, overflow after 49.7 days.
On the 64bit architecture, it is almost impossible to see it overflow.
In addition to the previous definition, jiffies has a second variable definition:
#include <linux/jiffies.h> extern u64 jiffies_64;
The ld(1) script is used to connect to the primary kernel image, and then use jiffies_64 initial value overrides jiffies variable:
// x86, arch/i386/kernel/vmlinux.lds.S jiffies = jiffies_64;
That is, jiffies only takes jiffies_64 low 32bit. Because most codes only use jiffies to store the lost time, the second time management code uses the whole 64bit jiffies_64 to avoid overflow.
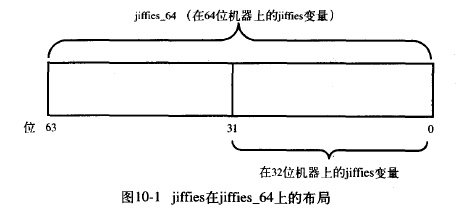
On the 32bit architecture, jiffies reads jiffies_64 low 32bit value; get_jiffies_64() read jiffies_64 whole 64bit value.
On the 64 bit architecture, jiffies is equivalent to get_jiffies_64(), and jiffies_64 is the same variable.
jiffies wrap
After jiffies overflow, it will wrap around to 0. The kernel provides four macro functions to compare beat counts to avoid looping problems.
#include <linux/jiffies.h> // unknown is jiffies, and known is the value to be compared #define timer_after(unknown, known) ((long)(known) - (long)(unknown) < 0) #define timer_before(unknown, known) ((long)(unknown) - (long)(known) < 0) #define timer_after_eq(unknown, known) ((long)(unknown) - (long)(known) >= 0) #define timer_after(unknown, known) ((long)(known) - (long)(unknown) >= 0)
User space and HZ
Before Linux kernel 2.6, changing the HZ value in the kernel will cause abnormal results to some programs in user space, because the application has relied on this specific HZ value.
To avoid the above error, the kernel needs to change all exported jiffies values. Therefore, the kernel defines USER_HZ represents the HZ value seen in user space.
For example, in x86 architecture, the HZ value has always been 100, so user_ The HZ value is defined as 100.
The kernel uses macro jiffies_to_clock_t() converts a beat count represented by HZ into a beat count represented by USER_HZ indicates the number of beats.
When user_ When HZ is an integral multiple of HZ,
#define jiffies_to_clock_t(x) ((x) / (HZ/USER_HZ))
In addition, jiffies_64_to_clock_t() converts the 64 bit jiffies value unit from Hz to USER_HZ.
[======]
Hard clock and timer
The architecture provides three kinds of hard clocks for timing: real-time clock, timestamp counting and programmable interrupt timer.
Real Time Clock RTC
RTC is a device used to store the system time for a long time. Even if the PC turns off the power, RTC can still rely on the motherboard battery to continue timing.
Main functions:
1) When the system starts, the kernel initializes the time on the wall by reading RTC, which is stored in the xtime variable.
2) Linux only uses RTC to get the current time and date.
Timestamp count TSC
x86 includes a 64 bit timestamp counter (register) that counts each clock signal. For example, if the clock beat is 400MHz, TSC counts + 1 every 2.5ns. The clock signal frequency is not specified during precompiling and must be determined during Linux initialization. Via calibrate_tsc(), complete the clock signal frequency calculation in the system initialization stage.
Programmable interrupt timer PIT
In x86 architecture, programmable interrupt clock (PIT) is mainly used as system timer.
In Linux, if PIT sends timing interrupt to IRQ0 at 100Hz frequency, it will generate timing interrupt every 10ms. This 10ms interval is a tick, which is stored in the tick variable in subtle units.
TSC has higher accuracy than PIT. PIT is more flexible for writing software.
[======]
Clock interrupt handler
The clock interrupt handler can be divided into two parts: architecture related part and architecture independent part.
The routines related to the architecture are registered to the kernel as the interrupt handler of the system timer (PIT), so that they can run when a clock interrupt is generated.
The processing program mainly performs the following work:
- Get xtime_lock lock, access jiffies_64 and wall time for protection.
- Answer or reset the system clock when necessary.
- Periodically update the real-time clock with wall time.
- Call architecture independent clock routine: do_timer().
The interrupt service program mainly calls do which has nothing to do with the architecture_ Timer() performs the following tasks:
- To jiffies_64 + 1.
- Update the statistics of resource consumption, such as system time and user time consumed by the current process.
- Execute the expired dynamic timer.
- Update the wall time, which is stored in the xtime variable.
- Calculate the average load value.
do_timer() looks like:
void do_timer(struct pt_regs* regs)
{
jiffies_64++;
update_process_times(user_mode(regs)); // Time update for users or systems
update_times(); // Update wall clock
}
user_ The mode() macro queries the status of the processor register regs. If the clock interrupt occurs in user space, it returns 1; Returns 0 if it occurs in the kernel. update_ process_ The times() function updates the time of the user or the system according to the location of the clock interrupt (user state or kernel state).
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id();
int system = user_tick ^ 1; // user_tick and system will only have one variable of 1 and the other must be 0
update_one_process(p, user_tick, system, cpu); // Update process time
run_local_timers(); // Mark a soft interrupt to handle all expired timers
scheduler_tick(user_tick, system); // Reduce the time slice count value of the current running process and set need when necessary_ Resched flag
}
update_one_process() determines the branch and sets the user_tick and system are added to the corresponding count of the process:
/* Update the appropriate time counter and add a jiffy to it */
p->utime += user;
p->stime += system;
update_times()Responsible for updating the wall clock:
void update_times(void)
{
unsigned long ticks; // Record the number of new beats generated after the last update
ticks = jiffies - wall_jiffies;
if (ticks) {
wall_jiffies += ticks;
update_wall_time(ticks); // Update xtime to store time
}
last_time_offset = 0;
calc_load(ticks); // Update load average
}
Ticks records the number of new beats generated after the last update. Generally, ticks should be 1, but clock interruption may be lost, resulting in the loss of beat. This happens when interrupts are prohibited for a long time (although it is likely to be a bug).
cal_load(0) updates the average load value. At this point, update_times() is completed. do_timer() also completes the execution and returns the interrupt handler related to the architecture. Continue to perform the following work and release xtime_lock and exit.
Wall time (actual time)
Wall time is defined in kernel / timer C medium
struct timespec xtime;
timespec structure definition:
#include <linux/time.h>
struct timespec {
time_t tv_sec; /* second */
long tv_nsec; /* nanosecond */
};
xtime.tv_sec stores the time elapsed since July 1, 1970 (UTC). July 1, 1970 is called the era, and Unix wall time is based on this era.
xtime.ntv_sec records the number of nanoseconds that have elapsed since the last second.
Xtime is required to read and write xtime variables_ Lock lock, this is a seqlock lock.
Update xtime:
write_seqlock(&xtime_lock); /* Update xtime */ write_sequnlock(&time_lock);
Read xtime:
/* The xtime is updated cyclically until it is confirmed that no clock interrupt handler updates the xtime during the cycle */
do {
unsigned long lost;
seq = read_seqbegin(&xtime_lock);
usec = timer->get_offset();
lost = jiffies->wall_jiffies;
if (lost)
usec += lost * (1000000/HZ);
sec = xtime.tv_sec;
usec += (xtime.tv_nsec/1000);
} while(read_seqretry(&xtime_lock, seq));
If there is a clock interrupt during the cycle, the handler updates xtime, read_seqretry() will return an invalid serial number and continue to wait in a loop.
The main interface for obtaining wall time from user space: gettimeofday(), the corresponding system call sys in the kernel_ gettimeofday():
asmlinkage long sys_gettimeofday(struct timeval* tv, struct timezone* tz)
{
if (likely(tv)) { // <=> if (tv)
struct timeval ktv;
do_gettimeofday(&ktv); // Loop read xtime operation
}
if (copy_to_user(tv, &ktv, sizeof(ktv))) // Copy the time or time zone on the wall to the user space
return -EFAULT; // An error occurred while copying
if (unlikely(tz)) { // <=> if (!tz)
if (copy_to_user(tz, &sys_tz, sizeof(sys_tz))) return -EFAULT;
}
return 0;
}
/* Macros like and unlikey are defined in the kernel to facilitate compiler optimization to improve performance */
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
time, ftime, gettimeofday relationship
The kernel also implements the system call of time(), ftime(), but they are all replaced by gettimeofday(). To maintain backward compatibility, Linux still retains.
- time() returns the number of seconds elapsed since midnight on January 1, 1970.
- ftime() returns a data structure of type timeb, which contains the number of seconds elapsed since midnight on January 1, 1970; The number of milliseconds passed in the last second; The time zone and the current state of daylight saving time.
- The value returned by gettimeofday() is stored in two data structures, timeval and timezone, which contain the same information as ftime.
[======]
timer
Timer is called dynamic timer or kernel timer, which is the basis of managing kernel time.
Timer use
Idea: first do some initialization work, set a timeout, specify the function to be executed after timeout, and then activate the timer. The specified function will execute automatically when the timer expires.
The timer will not run periodically and will be destroyed after timeout. This is one reason why this timer is called a dynamic timer. Therefore, dynamic timers are constantly created and destroyed, and the number of runs is unlimited. It is widely used in the kernel.
Timer structure timer_list, defined in < Linux / timer h>
struct timer_list {
struct list_head entry; /* Timer linked list entry */
unsigned long expires; /* Timing value in jiffies */
spinlock_t lock; /* Lock for protecting timer */
void (*function)(unsigned long); /* Timer processing function */
unsigned long data; /* The long integer parameter passed to the handler */
struct tvec_t_base_s *base; /* Timer internal value, users do not use */
};
You don't need to know more about timer when using timer_list structure. The kernel provides a set of interfaces to simplify the operation of managing timers.
1) Define timer
struct timer_list my_timer;
2) Initialization timer
init_timer(&my_timer);
3) Fill in the required values in the timer structure
my_timer.expires = jiffies + delay; /* Timer timeout */ my_timer.data = 0; /* Pass the value 0 to the timer handler */ my_timer.function = my_function; /* Handler function called by timer timeout */
The timeout handler must be this prototype:
void my_timer_function(unsigned long data);
4) Activate timer
add_timer(&my_timer);
Timer working conditions: current beat count jiffies > = my_ timer. expires
The timer will execute immediately after timeout, but it may also be delayed to the next clock beat, so it cannot be used for hard real-time tasks.
5) Modify timer
Change timeout
mod_timer(&my_timer, jiffies + new_delay); /* new expiration */
mod_timer can be used for timers that have been initialized but not activated; If the timer is not activated, mod_timer will activate it.
If the timer is not activated when calling, the function returns 0; Otherwise, return 1
6) Delete timer
Customize the timer before the timer times out
del_timer(&my_timer);
This function can be used for active or inactive timers. If it is not activated, the function returns 0; Otherwise, return 1.
Timers that have timed out do not need to call this function because they are automatically deleted.
del_timer can only guarantee that the timer will not be activated in the future and will not stop when it is currently running on other processors. At this point, you need to use del_timer_sync, waiting for the timeout handler running on other processors to exit.
del_timer_sync(&my_timer); /* If there is the possibility of concurrent access, it is recommended to use it first */ del_timer_sync() Cannot be used in interrupt context because it will block.
Timer race condition
The timer is asynchronous with the code currently executing (setting the timer), so there may be potential competition conditions. Therefore, mod cannot be replaced in the following way_ Timer() to change the timeout of the timer, because it is unsafe on Multiprocessors:
/* Replace mod with the following code_ Timer, it is wrong to modify the timer timeout */ del_timer(&my_timer); my_timer->expires = jiffies + new_delay; add_timer(&my_timer);
Usually, del is used_ timer_ Sync() replaces del_timer() deletes the timer to avoid the problem of concurrent access, because it is impossible to determine whether it runs on other processors when deleting the timer.
Implement timer
The timer is executed as a soft interrupt in the lower context.
The clock interrupt handler executes update_process_timers(), which calls run immediately_ local_ timers().
void run_local_timers(void)
{
raise_softirq(TIMER_SOFTIRQ);
}
run_timer_softirq() process software interrupt TIMER_SOFTIRQ to run all timeout timers on the current processor.
The kernel timer is stored in the form of linked list, but it does not traverse the linked list to find the timeout timer, nor does it insert and delete the timer in the linked list.
Instead, the timers are divided into five groups according to the timeout time. When the timer timeout approaches, the timer will move down with the group. The method of using packet timer can ensure that the kernel can reduce the burden of search timeout timer as much as possible in most cases of executing soft interrupt.
[======]
Delayed execution
The kernel code (especially the driver) needs other methods to postpone the execution of tasks in addition to the timer or the lower half mechanism.
It is often used to wait for the hardware to complete some work for a short time, such as redesigning the Ethernet mode (2ms) of the network card.
The kernel provides a variety of delay methods to deal with various delay requirements:
1) Busy waiting
2) Short delay
3)schedule_timeout()
4) Set the timeout to sleep on the waiting queue
Busy waiting
Busy wait (or busy loop) is the simplest and least ideal delay method.
This method is only applicable when the time to be delayed is an integral multiple of the beat, or when the accuracy requirement is not high.
Busy cycle usage example: rotate continuously in the cycle until the desired number of clock beats is exhausted
unsigned long delay = jiffies + 10; /* 10 A beat */
while (time_before(jiffies, delay)) /* CPU Loop waiting jiffies > delay */
;
The upper cycle rotates continuously and waits for 10 beats. On the x86 architecture with HZ value of 1000, each beat is 1ms, and 10 beats take a total of 10ms.
unsigned long delay = jiffies + 2 * HZ; /* 2 second */
while (time_before(jiffies, delay))
;
When the above cycle spins, the CPU will not be abandoned. Next cond_resched() will schedule a new program to run, but only after setting need_ It can take effect only after the resched flag. Because cond_ The resched method calls the scheduler, so it cannot be used in the interrupt context, but only in the process context.
unsigned long delay = jiffies + 5 * HZ;
while (time_before(jiffies, delay))
cond_resched(); /* Schedule a new program to run */
be careful:
1) All delay methods can only be used in the process context, not in the interrupt context. Because the processing procedure should be executed as soon as possible.
2) Delayed execution should not occur when a lock is held or an interrupt is prohibited.
Short delay
Sometimes the driver not only needs a very short delay (shorter than the clock beat typ. Of 1ms), but also requires a very accurate delay time. It is not possible to use jiffies beats with an accuracy of 1ms for delay.
At this point, you can use the other two functions provided by the kernel to deal with subtle and millisecond delays.
Header file: < Linux / delay h>
void udelay(unsigned long usecs); void mdelay(unsigned long msecs);
mdelay is implemented through udelay.
For example, the delay is 150 microseconds and 200 milliseconds
udelay(150); /* Delay 150us */ mdelay(200); /* Delay 200ms */
be careful:
1) When the delay exceeds 1ms, do not use udelay, but mdelay.
2) Don't use mdelay if you can. Use it as little as possible.
3) Do not use busy wait when holding a lock or prohibiting interruption, because it is similar to busy wait, which will greatly reduce the response speed and performance of the system.
schedule_timeout() sleep to the specified delay time
This method will make the tasks that need to be delayed sleep until the specified delay time is exhausted, and then run again. It cannot be guaranteed that the sleep time is just equal to the specified delay time, but can only be as close as possible. When the specified time expires, the kernel wakes up the delayed task and puts it back in the run queue.
Typical usage:
/* Set the task to an interruptible sleep state */ set_current_state(TASK_INTERRUPTIBLE); unsigned long S = 10; /* Take a nap and wake up in S seconds */ schedule_timeout(s * HZ);
The only parameter is the relative time of delay, in jiffies.
If you want to receive signals during sleep, you can set the task status to TASK_INTERRUPTIBLE; If you don't want to, you can set the task status to TASK_UNINTERRUPTIBLE.
Note: call schedule_ Before timeout (), the task must be set to one of the above two states, otherwise the task will not sleep.
schedule_ Simple implementation of timeout:
signed long schedule_timeout(singed long timeout)
{
timer_t timer;
unsigned long expire;
switch(timeout)
{ /* Handling special situations */
case MAX_SCHEDULE_TIMEOUT: /* Indefinite sleep */
schedule(); /* Scheduling process: select a process with the highest priority from the ready queue to replace the current process */
goto out;
default:
if (timeout < 0) {
printk(KERN_ERR"schedule_timeout: wrong timeout value %lx from %p\n", timeout, __builtin_return_address(0));
goto out;
}
}
expire = timeout + jiffies;
init_timer(&timer); /* Initialize dynamic timer */
timer.expires = expire;
timer.data = (unsigned long)current;
timer.funtion = process_timeout;
add_timer(&timer); /* Activate timer */
schedule();
del_timer_sync(&timer); /* Synchronous deletion timer */
timeout = expire - jiffies;
out:
return timeout < 0 ? 0 : timeout;
}
/* Timer timeout processing function */
void process_timeout(unsigned long data)
{
wake_up_progress((task_t *)data); /* Wake up the process and set the task to TASK_RUNNING */
}
Because the task is identified as task_ Intermittent or TASK_UNINTERRUPTIBLE (before calling schedule_timeout), so the scheduler will no longer select this task to run, but will select other new tasks to run.
Set the timeout to sleep on the waiting queue
In order to wait for a specific event to happen, the process context places itself in the waiting queue, and then calls the dispatcher to execute the new task. Once an event occurs, the kernel can call wake_up() wakes up the task on the sleep queue and puts it back into operation.
schedule_ Where is timeout used?
When a task on the waiting queue may be waiting for a specific event to arrive and a specific time to expire, it depends on who comes first. In this case, you can use schedule_timeout replaces schedule(), because schedule() simply blocks waiting for wake-up events, while schedule_timeout can not only wait for IO events, but also wait for timeout.
[======]
Summary
1) Describes the basic concepts of time, such as wall time, clock interrupt, clock beat, HZ, jiffies, etc.
2) Implementation of timer, application method, etc.
3) Developer methods for delay: busy wait, short delay, schedule_timeout.
[======]
reference resources
[1] Robert love, love, Chen Lijun, et al Design and implementation of Linux kernel [M] China Machine Press, 2006